
Maison >Périphériques technologiques >IA >Inférence LLM sur plusieurs GPU à l'aide de la bibliothèque Accelerate
Inférence LLM sur plusieurs GPU à l'aide de la bibliothèque Accelerate

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-30 17:14:391457parcourir
Les modèles linguistiques à grande échelle (llm) ont révolutionné le domaine du traitement du langage naturel. À mesure que ces modèles augmentent en taille et en complexité, les exigences informatiques d’inférence augmentent également de manière significative. Pour relever ce défi, il devient essentiel d’exploiter plusieurs GPU.

Par conséquent, cet article effectuera une inférence sur plusieurs GPU simultanément. Le contenu comprend principalement : une introduction à la bibliothèque Accelerate, des méthodes simples et des exemples de code de travail, ainsi qu'une analyse comparative des performances à l'aide de plusieurs GPU
Cet article va. mettre à l'échelle l'inférence de lama2-7b sur plusieurs GPU en utilisant plusieurs 3090
Exemple de base
Nous introduisons d'abord un exemple simple pour démontrer le "passage de messages" multi-GPU à l'aide d'Accelerate .
from accelerate import Accelerator from accelerate.utils import gather_object accelerator = Accelerator() # each GPU creates a string message=[ f"Hello this is GPU {accelerator.process_index}" ] # collect the messages from all GPUs messages=gather_object(message) # output the messages only on the main process with accelerator.print() accelerator.print(messages)
Le résultat est le suivant :
['Hello this is GPU 0', 'Hello this is GPU 1', 'Hello this is GPU 2', 'Hello this is GPU 3', 'Hello this is GPU 4']
Inférence multi-GPU
Voici une méthode d'inférence simple et sans lot. Le code est très simple, car la bibliothèque Accelerate a déjà fait beaucoup de travail pour nous, nous pouvons l'utiliser directement :
from accelerate import Accelerator from accelerate.utils import gather_object from transformers import AutoModelForCausalLM, AutoTokenizer from statistics import mean import torch, time, json accelerator = Accelerator() # 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books prompts_all=["The King is dead. Long live the Queen.","Once there were four children whose names were Peter, Susan, Edmund, and Lucy.","The story so far: in the beginning, the universe was created.","It was a bright cold day in April, and the clocks were striking thirteen.","It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.","The sweat wis lashing oafay Sick Boy; he wis trembling.","124 was spiteful. Full of Baby's venom.","As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.","I write this sitting in the kitchen sink.","We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.", ] * 10 # load a base model and tokenizer model_path="models/llama2-7b" model = AutoModelForCausalLM.from_pretrained(model_path,device_map={"": accelerator.process_index},torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained(model_path) # sync GPUs and start the timer accelerator.wait_for_everyone() start=time.time() # divide the prompt list onto the available GPUs with accelerator.split_between_processes(prompts_all) as prompts:# store output of generations in dictresults=dict(outputs=[], num_tokens=0) # have each GPU do inference, prompt by promptfor prompt in prompts:prompt_tokenized=tokenizer(prompt, return_tensors="pt").to("cuda")output_tokenized = model.generate(**prompt_tokenized, max_new_tokens=100)[0] # remove prompt from output output_tokenized=output_tokenized[len(prompt_tokenized["input_ids"][0]):] # store outputs and number of tokens in result{}results["outputs"].append( tokenizer.decode(output_tokenized) )results["num_tokens"] += len(output_tokenized) results=[ results ] # transform to list, otherwise gather_object() will not collect correctly # collect results from all the GPUs results_gathered=gather_object(results) if accelerator.is_main_process:timediff=time.time()-startnum_tokens=sum([r["num_tokens"] for r in results_gathered ]) print(f"tokens/sec: {num_tokens//timediff}, time {timediff}, total tokens {num_tokens}, total prompts {len(prompts_all)}")
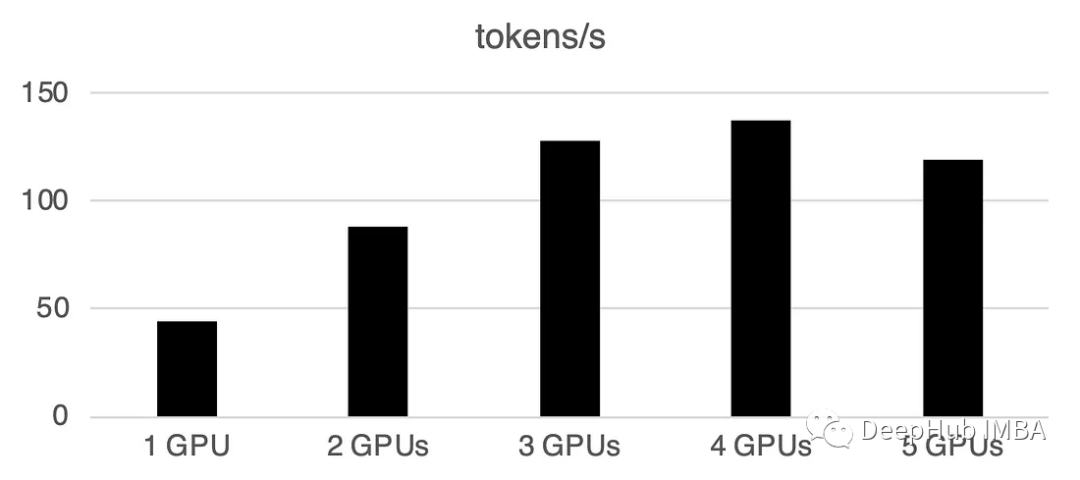
L'utilisation de plusieurs GPU entraînera une certaine surcharge de communication : les performances augmentent linéairement à 4 GPU, puis dans cela a tendance à être stable dans certains contextes. Bien sûr, les performances ici dépendent de nombreux paramètres tels que la taille et la quantification du modèle, la longueur des indices, le nombre de jetons générés et la stratégie d'échantillonnage, nous ne discutons donc que du cas général
1 GPU : 44 jetons/sec, temps : 225,5 s
2 GPU : Traitement de 88 jetons par seconde, un temps total de 112,9 secondes
3 GPU : Traitement de 128 jetons par seconde, un temps total de 77,6 secondes
4 GPU : 137 jetons/seconde, temps : 72,7 s
5 GPU : 119 jetons traités par seconde, temps total pris 83,8 secondes
Traitement par lots sur plusieurs GPU
Dans le monde réel, nous pouvons utiliser l'inférence par lots pour accélérer les choses en haut. Cela réduit la communication entre les GPU et accélère l'inférence. Il suffit d'ajouter la fonction prepare_prompts pour saisir un lot de données dans le modèle au lieu d'une seule donnée :
from accelerate import Accelerator from accelerate.utils import gather_object from transformers import AutoModelForCausalLM, AutoTokenizer from statistics import mean import torch, time, json accelerator = Accelerator() def write_pretty_json(file_path, data):import jsonwith open(file_path, "w") as write_file:json.dump(data, write_file, indent=4) # 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books prompts_all=["The King is dead. Long live the Queen.","Once there were four children whose names were Peter, Susan, Edmund, and Lucy.","The story so far: in the beginning, the universe was created.","It was a bright cold day in April, and the clocks were striking thirteen.","It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.","The sweat wis lashing oafay Sick Boy; he wis trembling.","124 was spiteful. Full of Baby's venom.","As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.","I write this sitting in the kitchen sink.","We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.", ] * 10 # load a base model and tokenizer model_path="models/llama2-7b" model = AutoModelForCausalLM.from_pretrained(model_path,device_map={"": accelerator.process_index},torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained(model_path) tokenizer.pad_token = tokenizer.eos_token # batch, left pad (for inference), and tokenize def prepare_prompts(prompts, tokenizer, batch_size=16):batches=[prompts[i:i + batch_size] for i in range(0, len(prompts), batch_size)]batches_tok=[]tokenizer.padding_side="left" for prompt_batch in batches:batches_tok.append(tokenizer(prompt_batch, return_tensors="pt", padding='longest', truncatinotallow=False, pad_to_multiple_of=8,add_special_tokens=False).to("cuda") )tokenizer.padding_side="right"return batches_tok # sync GPUs and start the timer accelerator.wait_for_everyone() start=time.time() # divide the prompt list onto the available GPUs with accelerator.split_between_processes(prompts_all) as prompts:results=dict(outputs=[], num_tokens=0) # have each GPU do inference in batchesprompt_batches=prepare_prompts(prompts, tokenizer, batch_size=16) for prompts_tokenized in prompt_batches:outputs_tokenized=model.generate(**prompts_tokenized, max_new_tokens=100) # remove prompt from gen. tokensoutputs_tokenized=[ tok_out[len(tok_in):] for tok_in, tok_out in zip(prompts_tokenized["input_ids"], outputs_tokenized) ] # count and decode gen. tokens num_tokens=sum([ len(t) for t in outputs_tokenized ])outputs=tokenizer.batch_decode(outputs_tokenized) # store in results{} to be gathered by accelerateresults["outputs"].extend(outputs)results["num_tokens"] += num_tokens results=[ results ] # transform to list, otherwise gather_object() will not collect correctly # collect results from all the GPUs results_gathered=gather_object(results) if accelerator.is_main_process:timediff=time.time()-startnum_tokens=sum([r["num_tokens"] for r in results_gathered ]) print(f"tokens/sec: {num_tokens//timediff}, time elapsed: {timediff}, num_tokens {num_tokens}")
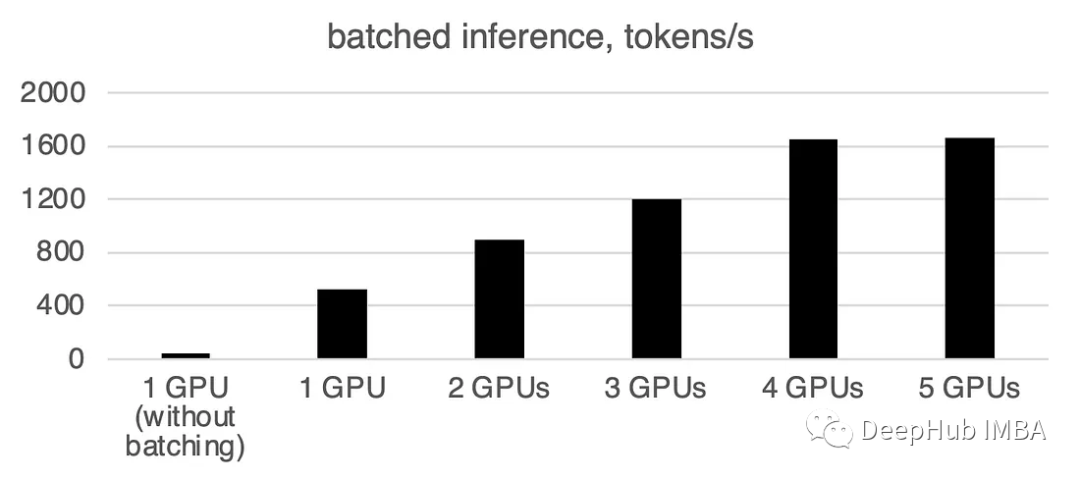
Vous pouvez voir que le traitement par lots accélérera considérablement la vitesse.
Ce qui doit être réécrit est : 1 GPU : 520 jetons/seconde, temps : 19,2 secondes
Deux GPU ont une puissance de calcul de 900 jetons par seconde, et le temps de calcul est de 11,1 secondes
3 GPU : 1205 jetons/seconde, temps : 8,2 s
Quatre GPU : 1655 jetons/seconde, temps requis : 6,0 secondes
5 GPU : 1658 jetons par seconde Carte, temps : 6,0 secondes
Résumé
À partir de cet article, llama.cpp et ctransformer ne prennent pas en charge l'inférence multi-GPU. Il semble que llama.cpp ait une fusion multi-GPU en juin, mais je n'ai pas vu de mise à jour officielle. , je suis donc sûr que plusieurs GPU ne sont pas pris en charge ici pour le moment. Si quelqu'un confirme qu'il peut prendre en charge plusieurs GPU, veuillez laisser un message. Le package Accelerate de
huggingface nous offre une option très pratique pour utiliser plusieurs GPU. L'utilisation de plusieurs GPU pour l'inférence peut améliorer considérablement les performances, mais le coût de la communication entre les GPU augmente considérablement à mesure que le nombre de GPU augmente.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment connaître et comprendre l'intelligence artificielle
- L'essence de l'intelligence artificielle est de simuler, voire de surpasser l'intelligence humaine, n'est-ce pas ?
- L'auteur d'un article est populaire. Quand les grands modèles de langage tels que ChatGPT peuvent-ils devenir co-auteur de l'article ?
- Open Interpreter : un outil open source qui permet à de grands modèles de langage d'exécuter du code localement
- Créez rapidement une grande base de connaissances sur l'IA en matière de modèles de langage en seulement trois minutes