
Maison >Périphériques technologiques >IA >Vous pouvez apprendre « sans faire correspondre les données » ! L'Université du Zhejiang et d'autres ont proposé de connecter la représentation de contraste multimodale C-MCR
Vous pouvez apprendre « sans faire correspondre les données » ! L'Université du Zhejiang et d'autres ont proposé de connecter la représentation de contraste multimodale C-MCR

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-20 11:54:151273parcourir
La représentation contrastive multimodale (MCR) vise à encoder les entrées de différentes modalités dans un espace partagé sémantiquement aligné
Avec le grand succès des modèles CLIP dans le domaine visuo-linguistique, de plus en plus de représentations contrastées modales commencent à émerger et obtenir des améliorations significatives sur de nombreuses tâches en aval, mais ces méthodes s'appuient fortement sur des données appariées à grande échelle et de haute qualité
Pour résoudre ce problème, des chercheurs de l'Université du Zhejiang et d'autres institutions ont proposé la représentation contrastive multimodale concaténée (C-MCR) une méthode d'apprentissage de représentation contrastive multimodale qui ne nécessite pas de données appariées et est extrêmement efficace en formation.

Veuillez cliquer sur le lien suivant pour consulter l'article : https://arxiv.org/abs/2305.14381
Lien de la page d'accueil du projet C-MCR : https://c-mcr.github.io /C- MCR/
Adresse du modèle et du code : https://github.com/MCR-PEFT/C-MCR
Cette méthode connecte différents préréglages via le hub modal sans utiliser de données appariées. Par formation. représentations contrastées, nous avons appris de puissantes représentations audiovisuelles et de nuages de points 3D-texte, et obtenu des résultats SOTA sur plusieurs tâches telles que la récupération audiovisuelle, la localisation de sources sonores et la classification d'objets 3D.
Introduction
La représentation contrastive multimodale (MCR) vise à mapper des données de différentes modalités dans un espace sémantique unifié. Avec le grand succès de CLIP dans le domaine visuo-linguistique, l’apprentissage de représentations contrastées entre des combinaisons plus modales est devenu un sujet de recherche brûlant, attirant de plus en plus d’attention.
Cependant, la capacité de généralisation des représentations contrastives multimodales existantes bénéficie principalement d'un grand nombre de paires de données de haute qualité. Cela limite considérablement le développement de représentations contrastées sur des modalités dépourvues de données à grande échelle et de haute qualité. Par exemple, la corrélation sémantique entre les paires de données audio et visuelles est souvent ambiguë, et les données appariées entre les nuages de points 3D et le texte sont rares et difficiles à obtenir.
Cependant, nous avons observé que ces combinaisons modales dépourvues de données appariées ont souvent une grande quantité de données appariées de haute qualité avec le même mode intermédiaire. Par exemple, dans le domaine audiovisuel, bien que la qualité des données audiovisuelles ne soit pas fiable, il existe une grande quantité de données appariées de haute qualité entre l'audio-texte et le texte-visuel.
De même, bien que la disponibilité des données d'appariement nuage de points 3D-texte soit limitée, les données nuage de points 3D-image et image-texte sont abondantes. Ces modes hub peuvent établir des liens supplémentaires entre les modes.
Considérant que les modalités avec une grande quantité de données appariées ont souvent déjà des représentations contrastives pré-entraînées, cet article tente directement de connecter les représentations contrastives entre différentes modalités via la modalité hub, fournissant ainsi une meilleure représentation pour les modalités qui manquent d'appariement. Les combinaisons construisent de nouveaux espaces de représentation contrastés.
En utilisant la représentation contrastée multimodale concaténée (C-MCR), vous pouvez établir des connexions avec un grand nombre de représentations contrastives multimodales existantes à travers des modes qui se chevauchent, apprenant ainsi les relations d'alignement entre un plus large éventail de modalités. Ce processus d'apprentissage ne nécessite aucune donnée appariée et est extrêmement efficace
C-MCR présente deux avantages clés :
L'accent est mis sur la flexibilité :
La capacité de C-MCR est de fournir des modalités d'apprentissage des représentations contrastées qui manquent d’appariements directs. D'un autre point de vue, C-MCR traite chaque espace de représentation de contraste multimodal existant comme un nœud et traite les modalités qui se chevauchent comme des modalités clés du centre
en connectant des espaces de représentation de contraste multimodaux isolés individuels, ce que nous pouvons. pour élargir de manière flexible les connaissances d'alignement multimodal obtenues et exploiter une gamme plus large de représentations de contraste intermodales
2. Efficacité :
Depuis C-MCR uniquement Il est nécessaire d'établir des connexions pour la représentation existante espace, donc seuls deux mappeurs simples doivent être appris, et leurs paramètres de formation et leurs coûts de formation sont extrêmement faibles.
Dans cette expérience, nous avons utilisé le texte comme plaque tournante pour comparer les espaces de représentation visuel-texte (CLIP) et texte-audio (CLAP), et avons finalement obtenu une représentation visuel-audio de haute qualité
De même, en En comparant l'image-texte-visuel connecté (CLIP) et le nuage de points visuel-3D (ULIP) pour représenter l'espace, un ensemble de représentations contrastées nuage de points-texte 3D peut également être obtenu
Méthode
Figure 1 ( a) Le flux algorithmique de C-MCR est introduit (en prenant comme exemple l'utilisation de texte pour connecter CLIP et CLAP).
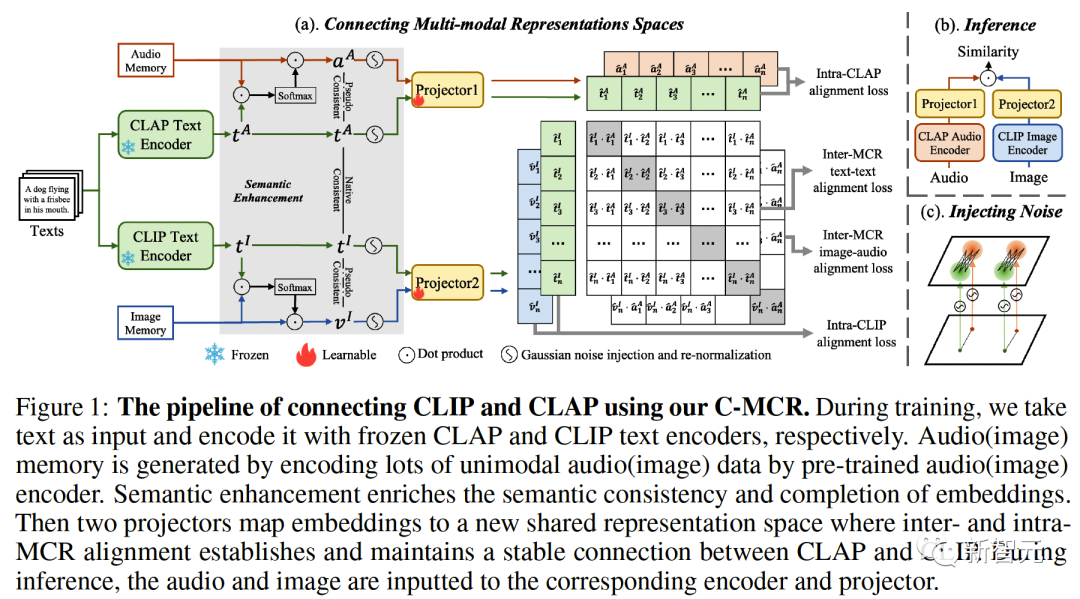
Les données du texte (modalités qui se chevauchent) sont codées en caractéristiques de texte par les encodeurs de texte de CLIP et CLAP respectivement :,.
Dans le même temps, une grande quantité de données monomodales non appariées est codée respectivement dans les espaces CLIP et CLAP, formant une mémoire d'image et une mémoire audio
L'amélioration sémantique des fonctionnalités fait référence à l'amélioration et à l'optimisation des fonctionnalités, afin pour améliorer sa capacité d'expression sémantique. En ajustant correctement les caractéristiques, il peut refléter plus précisément le sens à exprimer, améliorant ainsi l'effet de l'expression du langage. La technologie d'amélioration sémantique des fonctionnalités a une valeur d'application importante dans le domaine du traitement du langage naturel. Elle peut aider les machines à comprendre et à traiter les informations textuelles, et à améliorer les capacités des machines en matière de compréhension sémantique et de génération sémantique. représentation, pour améliorer la robustesse et l’exhaustivité des connexions spatiales. À cet égard, nous explorons d'abord sous les deux angles de la cohérence sémantique et de l'exhaustivité sémantique
Cohérence sémantique intermodale
CLIP et CLAP ont appris une représentation image-texte et texte-audio alignée et fiable.
Nous exploitons cet alignement de modalité intrinsèque dans CLIP et CLAP pour générer des caractéristiques d'image et audio sémantiquement cohérentes avec le i-ième texte, permettant une meilleure quantification de l'écart de modalité dans l'espace de représentation contrastive et une exploration plus directe de la corrélation entre non -modalités qui se chevauchent :
Intégrité sémantique au sein de la modalité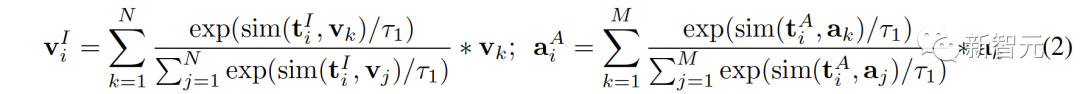
Différents espaces de représentation auront des tendances différentes pour l'expression sémantique des données, donc la même dans différents espaces Il y aura inévitablement des déviations sémantiques et pertes dans le texte. Ce biais sémantique s’accumule et s’amplifie lors de la connexion des espaces de représentation.
Pour améliorer la complétude sémantique de chaque représentation, nous proposons d'ajouter du bruit gaussien de moyenne nulle aux représentations et de les renormaliser sur l'hypersphère unitaire :
comme le montre la figure 1 (comme le montre c ), dans l'espace de représentation contrastive, chaque représentation peut être considérée comme représentant un point sur l'hypersphère unitaire. L'ajout de bruit gaussien et la renormalisation permettent à la représentation de représenter un cercle sur la sphère unité.
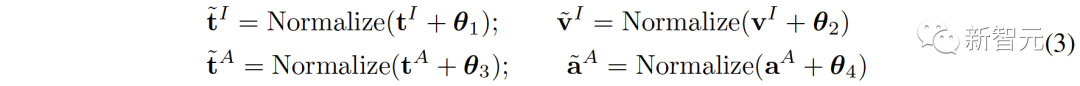
Lorsque la distance spatiale entre deux entités est plus proche, leur similarité sémantique est plus élevée. Par conséquent, les caractéristiques à l'intérieur du cercle ont une sémantique similaire, et le cercle peut représenter la sémantique plus complètement
2 Alignement d'Inter-MCR
Après avoir caractérisé l'amélioration sémantique, nous utilisons deux mappeurs et pour remapper CLIP. et représentations CLAP vers un nouvel espace partagé
Le nouvel espace nécessite de s'assurer que les représentations sémantiquement similaires provenant de différents espaces sont proches les unes des autres.
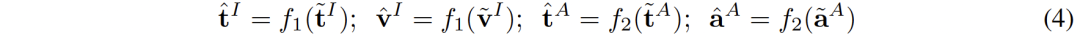
( ,
, ) provenant d'un même texte sont naturellement sémantiquement cohérents et peuvent être considérés comme de véritables paires de balises, tandis que (,) provenant de (
) provenant d'un même texte sont naturellement sémantiquement cohérents et peuvent être considérés comme de véritables paires de balises, tandis que (,) provenant de ( ,
, )
)  ) peuvent être considérés comme des paires de pseudo-étiquettes. La sémantique entre
) peuvent être considérés comme des paires de pseudo-étiquettes. La sémantique entre
( ,
, ) est très cohérente, mais les connexions qui en sont tirées sont indirectes pour l'audiovisuel. Bien que la cohérence sémantique du couple (
) est très cohérente, mais les connexions qui en sont tirées sont indirectes pour l'audiovisuel. Bien que la cohérence sémantique du couple ( ,
, ) soit moins fiable, elle profite plus directement à la représentation audiovisuelle.
) soit moins fiable, elle profite plus directement à la représentation audiovisuelle.
Pour connecter les deux espaces de représentation contrastés de manière plus complète, nous alignons simultanément ( ,
, ) et (
) et ( ,
, ) :
) :
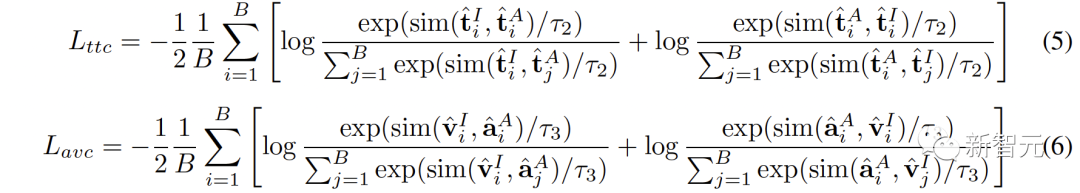
3.
En plus de la connexion entre les espaces, il existe également un phénomène d'écart de modalité au sein de l'espace de représentation contrastée. Autrement dit, dans l’espace de représentation contrastive, bien que les représentations de différentes modalités soient sémantiquement alignées, elles sont distribuées dans des sous-espaces complètement différents. Cela signifie que les connexions plus stables apprises de (,) peuvent ne pas être bien héritées par l'audiovisuel.
Pour résoudre ce problème, nous proposons de réaligner les différentes représentations modales de chaque espace de représentation contrastive. Plus précisément, nous supprimons la structure d'exclusion des exemples négatifs dans la fonction de perte de contraste pour dériver une fonction de perte permettant de réduire l'écart de modalité. Une fonction de perte contrastive typique peut être exprimée comme suit :
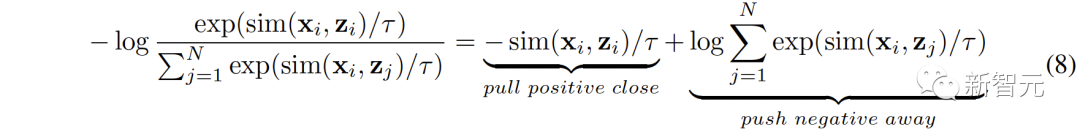
Après avoir éliminé le terme de répulsion de paire négatif, la formule finale peut être simplifiée comme suit :
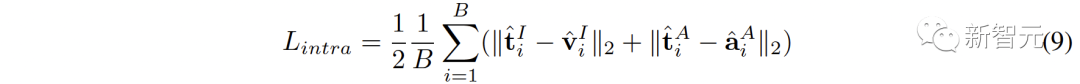
Expérience
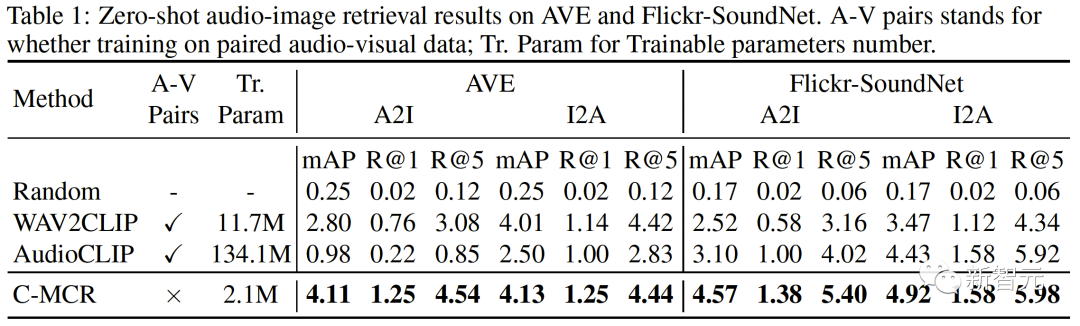
Expérimentalement, nous utilisons le texte Concaténer espace audio-texte (CLAP) et espace texte-visuel (CLIP) pour obtenir des représentations audiovisuelles, utiliser des images pour concaténer un espace nuage de points-image 3D (ULIP) et un espace image-texte (CLIP) pour obtenir un nuage de points-texte 3D représentation.
Les résultats de la récupération d'images audio à échantillon nul sur AVE et Flickr-SoundNet sont les suivants :
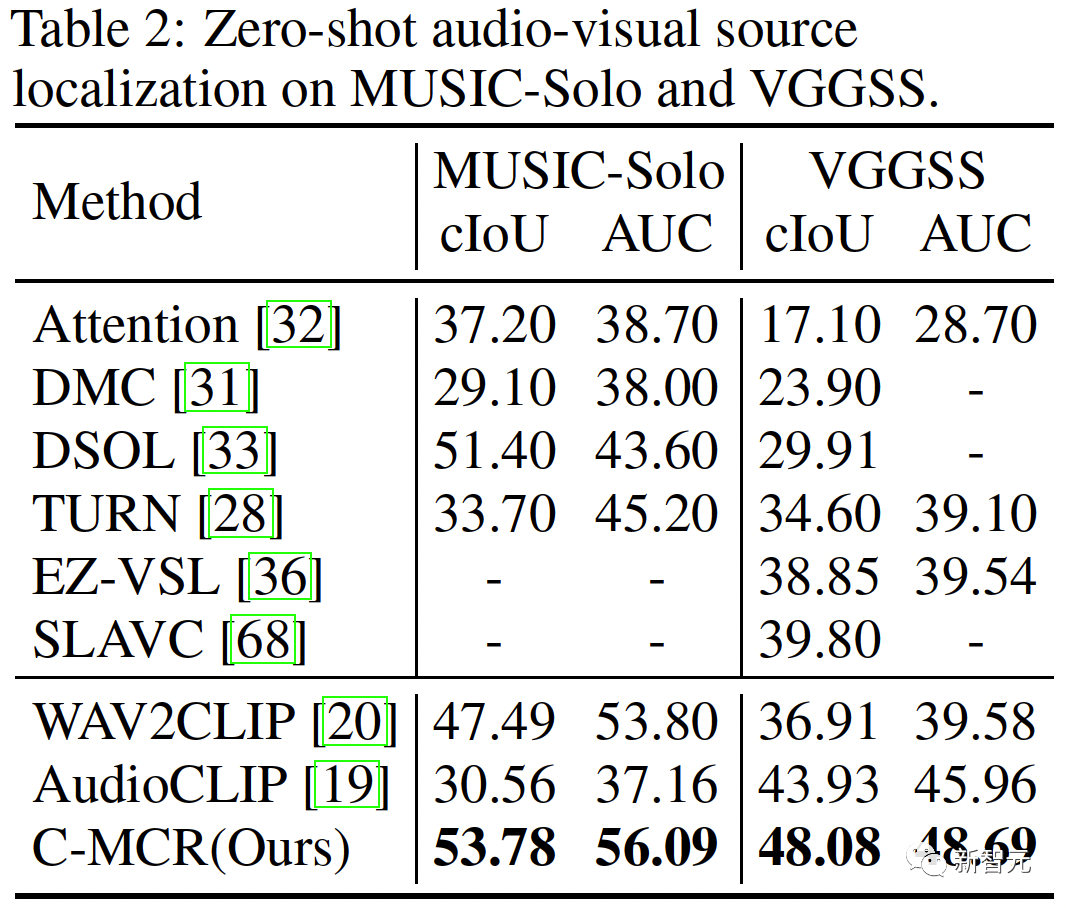
Les résultats de localisation de source sonore à échantillon nul sur MUSIC-Solo et VGGSS sont les suivants :
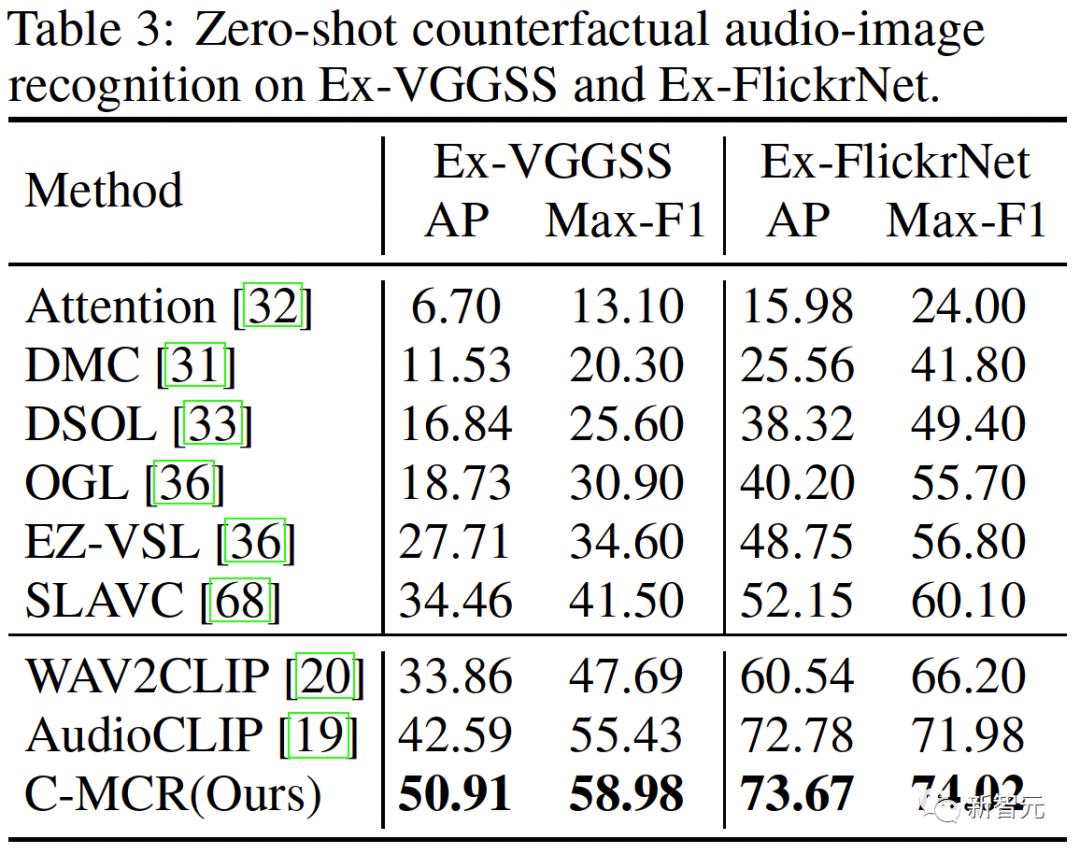
Les résultats de reconnaissance d'image audio contrefactuelle à échantillon nul sur Ex-VGGSS et Ex-FlickrNet sont les suivants :
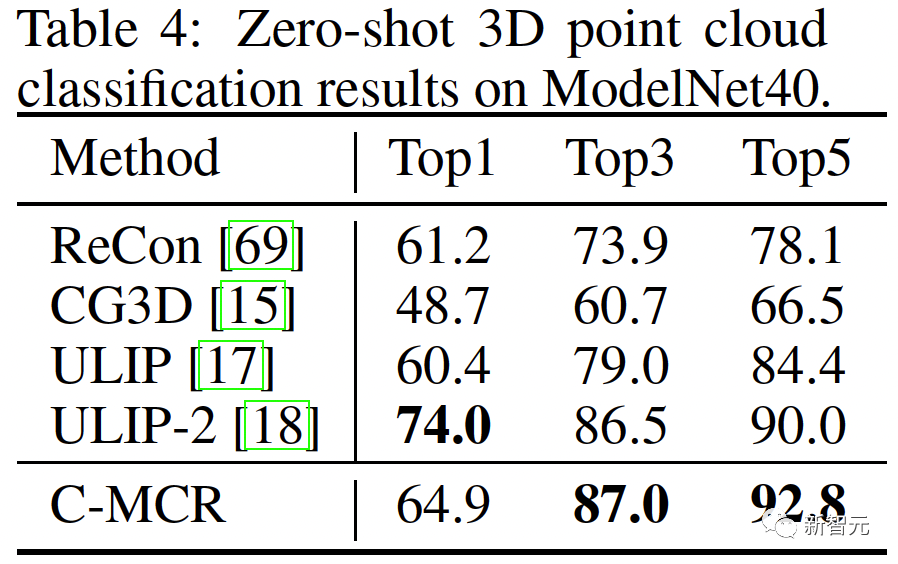
Les résultats de la classification des nuages de points 3D Zero-shot sur ModelNet40 sont les suivants :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles sont les couches du modèle de référence TCP/IP ?
- Le routage est la fonction principale de quelle couche dans le modèle osi
- Combien de types de modèles de boîtes CSS existe-t-il ?
- Meta lance continuellement l'IA pour accélérer le mouvement ultime ! La première puce d'inférence IA, supercalculateur IA spécialement conçu pour la formation de grands modèles
- Utiliser de grands modèles pour créer un nouveau paradigme pour la formation aux résumés de texte