
Maison >Périphériques technologiques >IA >Utiliser de grands modèles pour créer un nouveau paradigme pour la formation aux résumés de texte
Utiliser de grands modèles pour créer un nouveau paradigme pour la formation aux résumés de texte

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-10 09:43:382593parcourir
1. Tâche de texte
Le contenu principal de cet article est une discussion sur les méthodes de synthèse de texte générative, en se concentrant sur le dernier paradigme de formation utilisant l'apprentissage contrastif et les grands modèles. Il s'agit principalement de deux articles, l'un est BRIO : Bringing Order to Abstractive Summarization (2022), qui utilise l'apprentissage contrastif pour introduire des tâches de classement dans les modèles génératifs ; l'autre est On Learning to Summarize with Large Language Models as References (2023), dans Based sur BRIO, de grands modèles sont en outre introduits pour générer des données de formation de haute qualité.
2. Méthodes et problèmes de formation de résumé de texte génératif
La formation de résumé de texte génératif utilise généralement une estimation de similarité maximale. Tout d'abord, un encodeur est utilisé pour encoder le document, puis un décodeur est utilisé pour prédire de manière récursive chaque texte du résumé. La cible d'ajustement est une réponse standard de résumé construite artificiellement. L'objectif de rendre la probabilité de générer du texte à chaque position la plus proche de la réponse standard est représenté par une fonction d'optimisation :
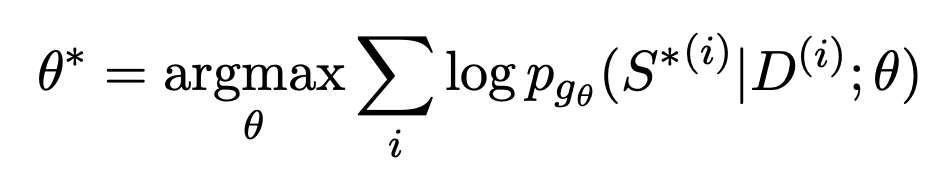
Le problème avec cette approche est que la formation et les tâches réelles en aval ne sont pas cohérentes. Plusieurs résumés peuvent être générés pour un document, et ils peuvent être de bonne ou de mauvaise qualité. MLE exige que la cible d’ajustement soit la seule réponse standard. Cet écart rend également difficile pour les modèles de résumé de texte de comparer efficacement les avantages et les inconvénients de deux résumés de qualité différente. Par exemple, une expérience a été menée dans l'article BRIO. Le modèle général de résumé de texte donne de très mauvais résultats lorsqu'il s'agit de juger l'ordre relatif de deux résumés de qualités différentes.
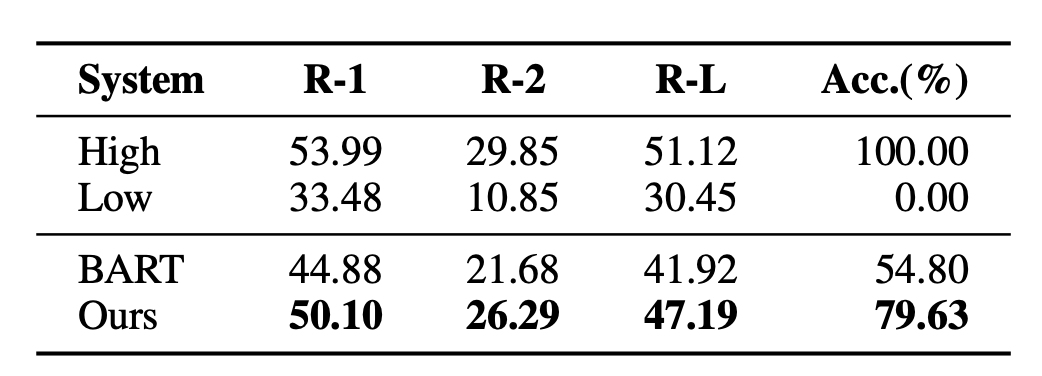
3. Le modèle génératif introduit l'apprentissage contrastif ordonné
Afin de résoudre les problèmes existants dans le modèle de résumé de texte génératif traditionnel, BRIO : Bringing Order to Abstractive Summarization (2022) a proposé d'introduire davantage de tâches d'apprentissage contrastées. dans le modèle génératif, Améliorer la capacité du modèle à classer les résumés de différentes qualités.
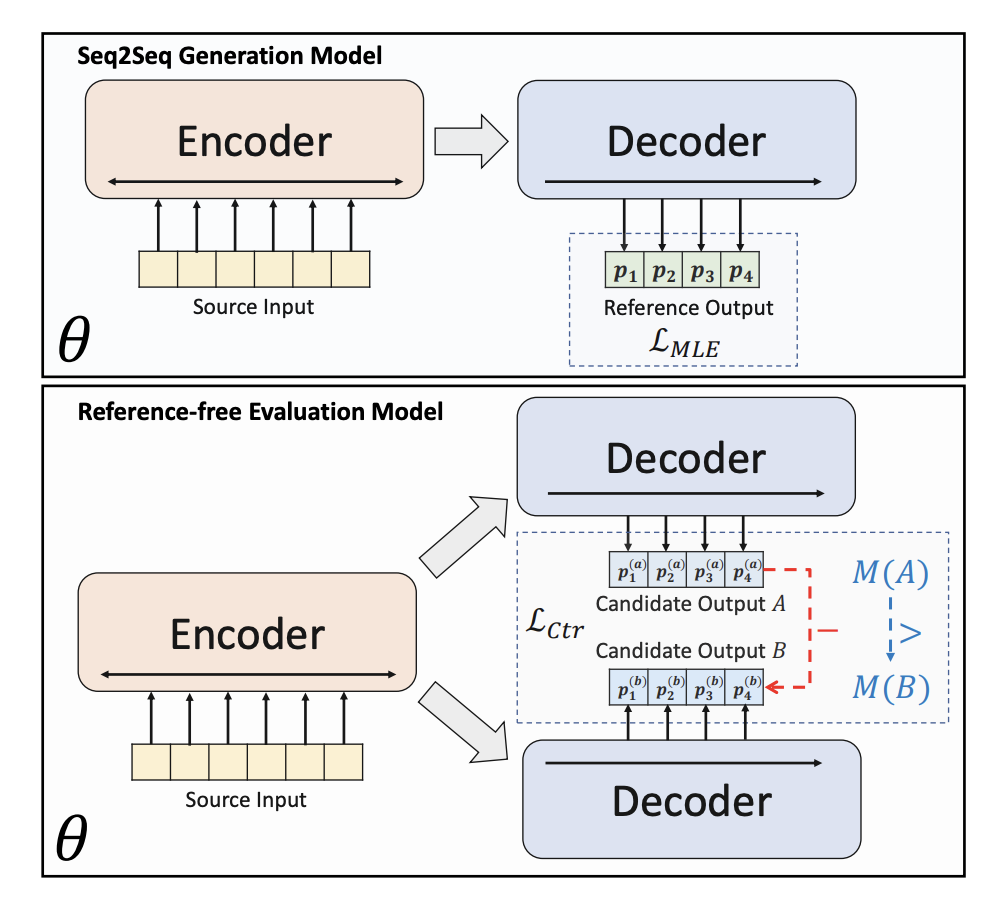
BRIO utilise la formation multi-tâches. La première tâche adopte la même méthode que les modèles génératifs traditionnels, c'est-à-dire l'ajustement de réponses standard via MLE. La deuxième tâche est une tâche d'apprentissage contrastive, dans laquelle un modèle de résumé de texte pré-entraîné utilise la recherche de faisceaux pour générer deux résultats différents, et ROUGE est utilisé pour évaluer lequel est le meilleur entre les deux résultats générés et la réponse standard pour déterminer lequel des deux résultats. deux Tri des résumés. Les deux résultats récapitulatifs sont entrés dans le décodeur pour obtenir les probabilités des deux résumés. Grâce à une perte d'apprentissage comparative, le modèle peut attribuer des scores plus élevés aux résumés de haute qualité. La méthode de calcul de cette partie de la perte d'apprentissage comparative est la suivante :
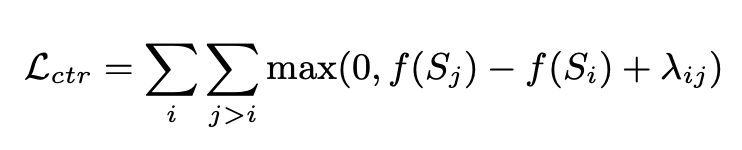
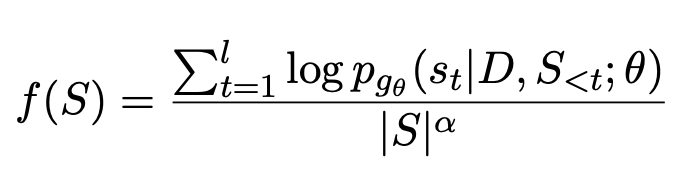
4 Résumé du texte d'optimisation de grand modèle
Il a été constaté que la qualité des résumés générés à l'aide de grands modèles tels que GPT est encore meilleur que ceux générés manuellement , c'est pourquoi ces grands modèles deviennent de plus en plus populaires. Dans ce cas, l’utilisation de réponses standard générées artificiellement limite le plafond d’efficacité du modèle. Par conséquent, On Learning to Summarize with Large Language Models as References (2023) propose d'utiliser de grands modèles tels que GPT pour générer des données de formation afin de guider l'apprentissage du modèle récapitulatif.
Cet article propose 3 façons d'utiliser de grands modèles pour générer des échantillons d'entraînement.
La première consiste à utiliser directement le résumé généré par le grand modèle pour remplacer le résumé généré manuellement, ce qui équivaut à ajuster directement la capacité de génération de résumé du grand modèle avec le modèle en aval. La méthode de formation est toujours MLE.
La deuxième méthode est GPTScore, qui utilise principalement un grand modèle pré-entraîné pour noter le résumé généré, utilise ce score comme base pour évaluer la qualité du résumé, puis utilise une méthode similaire à BRIO pour la formation par apprentissage comparatif. GPTScore est une méthode proposée dans Gptscore : Évaluez comme vous le désirez (2023) pour évaluer la qualité du texte généré sur la base d'un grand modèle.

La troisième méthode est GPTRank. Cette méthode permet au grand modèle de trier chaque résumé au lieu de le noter directement, et permet au grand modèle d'expliquer la logique de tri pour obtenir des résultats de tri plus raisonnables.

5. Résumé
La capacité des grands modèles à générer des résumés est de plus en plus largement reconnue. Par conséquent, l'utilisation de grands modèles comme générateur de cibles d'ajustement de modèles récapitulatifs pour remplacer les résultats d'annotation manuelle deviendra une tendance de développement future. Dans le même temps, l'utilisation de l'apprentissage du contraste de classement pour entraîner la génération de résumés permet au modèle de résumé de percevoir la qualité du résumé et de dépasser l'ajustement du point d'origine, ce qui est également crucial pour améliorer l'effet du modèle de résumé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI