
Maison >Périphériques technologiques >IA >NeRF et le passé et le présent de la conduite autonome, résumé de près de 10 articles !
NeRF et le passé et le présent de la conduite autonome, résumé de près de 10 articles !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-14 15:09:191637parcourir
Depuis que Neural Radiance Fields a été proposé en 2020, le nombre d'articles connexes a augmenté de façon exponentielle. Il est non seulement devenu une branche importante de la reconstruction tridimensionnelle, mais est également progressivement devenu actif à la frontière de la recherche en tant qu'outil important pour l'autonomie. conduite.
NeRF a soudainement émergé au cours des deux dernières années, principalement parce qu'il ignore l'extraction et la mise en correspondance des points caractéristiques, la géométrie et la triangulation épipolaires, le PnP plus l'ajustement du bundle et d'autres étapes du pipeline de reconstruction CV traditionnel, et ignore même la reconstruction, la cartographie et la cartographie du maillage. traçage de la lumière. Apprenez un champ de rayonnement directement à partir d'une image d'entrée 2D, puis produisez une image rendue à partir du champ de rayonnement qui se rapproche d'une vraie photo. En d’autres termes, laissez un modèle 3D implicite basé sur un réseau neuronal s’adapter à l’image 2D à partir d’une perspective spécifiée et lui donner à la fois de nouvelles synthèses de perspective et de nouvelles capacités. Le développement de NeRF est également étroitement lié à la conduite autonome, ce qui se reflète spécifiquement dans l'application de reconstruction de scènes réelles et de simulateurs de conduite autonome. NeRF est efficace pour restituer des images au niveau photo, de sorte que les scènes de rue modélisées avec NeRF peuvent fournir des données d'entraînement très réalistes pour la conduite autonome ; les cartes NeRF peuvent être modifiées pour combiner les bâtiments, les véhicules et les piétons dans divers coins difficiles à capturer dans la réalité. Ce cas peut être utilisé pour tester les performances d’algorithmes tels que la perception, la planification et l’évitement d’obstacles. NeRF est donc une branche de la reconstruction 3D et un outil de modélisation. La maîtrise de NeRF est devenue une compétence indispensable pour les chercheurs en reconstruction ou en conduite autonome.
Aujourd'hui, je vais trier le contenu lié au Nerf et à la conduite autonome Près de 11 articles vous emmèneront explorer le passé et le présent de Nerf et la conduite autonome
1 Le travail pionnier de Nerf
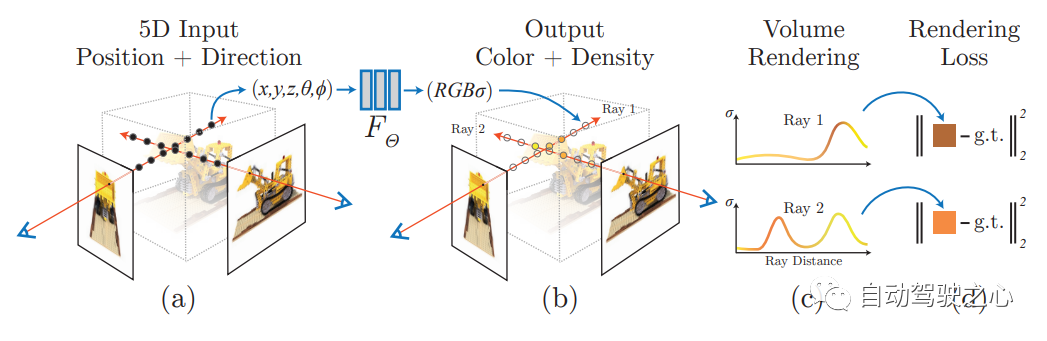
La réécriture ; le contenu est : NeRF : Représentation du champ de rayonnement neuronal des scènes pour la synthèse de vues. Dans le premier article d'ECCV2020
, une méthode Nerf est proposée, qui utilise un ensemble de vues d'entrée clairsemée pour optimiser la fonction de scène à volume continu sous-jacente, obtenant ainsi les derniers résultats de vue pour synthétiser des scènes complexes. Cet algorithme utilise un réseau profond entièrement connecté (non convolutif) pour représenter la scène. L'entrée est une seule coordonnée 5D continue (y compris la position spatiale (x, y, z) et la direction de visualisation (θ, ξ)), et la sortie. est la position spatiale de la densité volumique et du rayonnement d'émission lié à la vue
NERF utilise des images posées en 2D comme supervision. Il n'est pas nécessaire de convoluer l'image. Au lieu de cela, il apprend un ensemble de paramètres implicites en apprenant continuellement le codage de position et en utilisant la couleur de l'image. comme supervision, représentant des scènes 3D complexes. Grâce à la représentation implicite, le rendu sous n'importe quelle perspective peut être réalisé.
2.Mip-NeRF 360
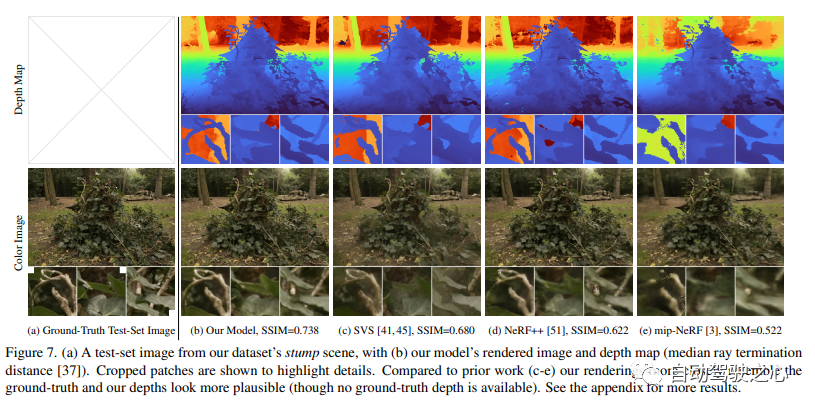
Le contenu de recherche du CVPR2020 porte sur les scènes extérieures sans frontières. Parmi eux, Mip-NeRF 360 : le champ de rayonnement neuronal anti-aliasing sans limites est l'un des axes de recherche
Lien papier : https://arxiv.org/pdf/2111.12077.pdf
Bien que le champ de rayonnement neural (NeRF) soit déjà dans l'objet et montrent de bons résultats de composition de vue sur de petites régions délimitées de l'espace, mais ils sont difficiles à obtenir dans des scènes « sans bordure » où la caméra peut pointer dans n'importe quelle direction et le contenu peut exister à n'importe quelle distance. Dans ce cas, les modèles de type NeRF existants produisent souvent des rendus flous ou à faible résolution (en raison d'un déséquilibre dans les détails et à l'échelle des objets proches et distants), sont plus lents à s'entraîner et souffrent d'une mauvaise reconstruction à partir d'un ensemble de petites images. se produisent en raison de l’ambiguïté inhérente à la tâche dans les grandes scènes. Cet article propose une extension de mip-NeRF, une variante de NeRF qui résout les problèmes d'échantillonnage et d'alias, qui utilise le paramétrage de scène non linéaire, la distillation en ligne et un nouveau régulariseur basé sur la distorsion pour surmonter les problèmes causés par les défis illimités. Il permet une réduction de 57 % de l'erreur quadratique moyenne par rapport au mip-NeRF et est capable de générer des vues synthétiques réalistes et des cartes de profondeur détaillées pour des scènes du monde réel très complexes et sans frontières.

3.Instant-NGP
Le contenu qui doit être réécrit est : "Expression de scène hybride de voxels explicites et de fonctionnalités implicites (SIGGRAPH 2022)"
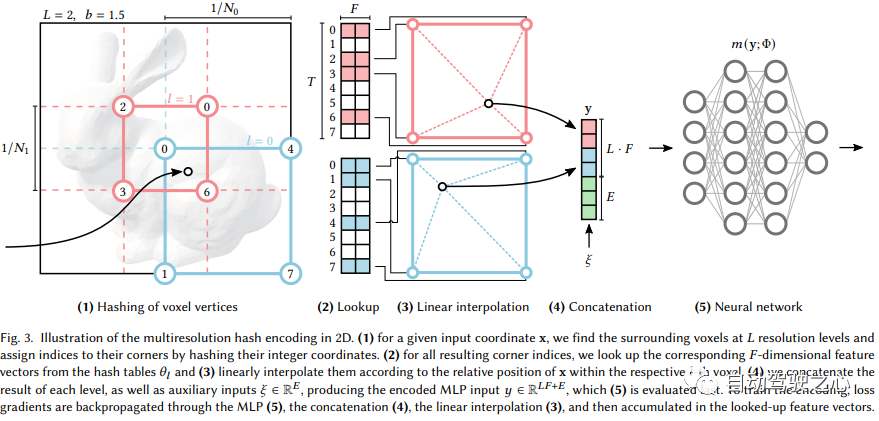
Utilisation d'un codage de hachage multi-résolution la primitive neurographique instantanée
doit être réécrite est : Lien : https://nvlabs.github.io/instant-ngp
Jetons d'abord un coup d'œil aux similitudes et aux différences entre Instant-NGP et NeRF :
- Également basé sur le rendu de volume
- Différent du MLP de NeRF, NGP utilise une grille de voxels paramétrée clairsemée comme expression de scène
- Basé sur les dégradés, il optimise la scène et le MLP en même temps (un MLP est utilisé comme décodeur) ; .
On peut voir que le grand framework est toujours le même. La différence la plus importante est que NGP a sélectionné la grille de voxels paramétrée comme expression de scène. Grâce à l'apprentissage, les paramètres enregistrés dans le voxel deviennent la forme de la densité de la scène. Le plus gros problème avec MLP est qu’il est lent. Afin de reconstruire la scène avec une haute qualité, un réseau relativement grand est souvent nécessaire, et il faudra beaucoup de temps pour parcourir le réseau pour chaque point d'échantillonnage. L'interpolation au sein de la grille est beaucoup plus rapide. Cependant, si la grille veut exprimer des scènes de haute précision, elle nécessite des voxels de haute densité, ce qui entraînera une utilisation extrêmement élevée de la mémoire. Considérant qu'il existe de nombreux endroits vides dans la scène, NVIDIA a proposé une structure clairsemée pour exprimer la scène. F2-NeRF
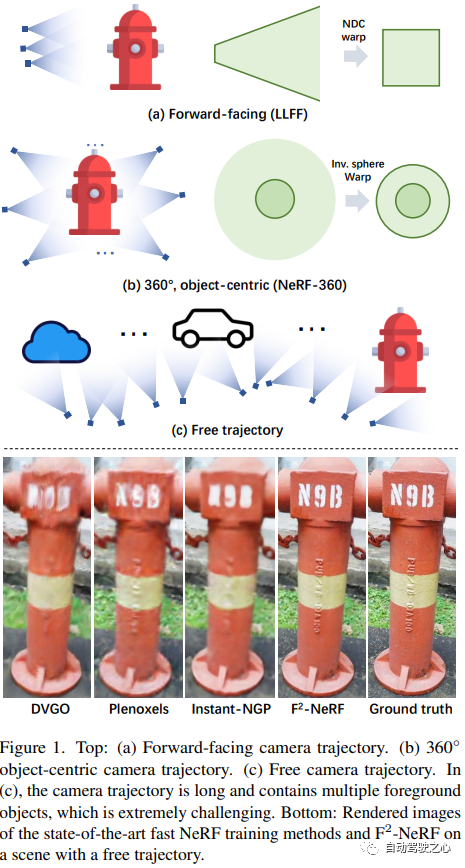
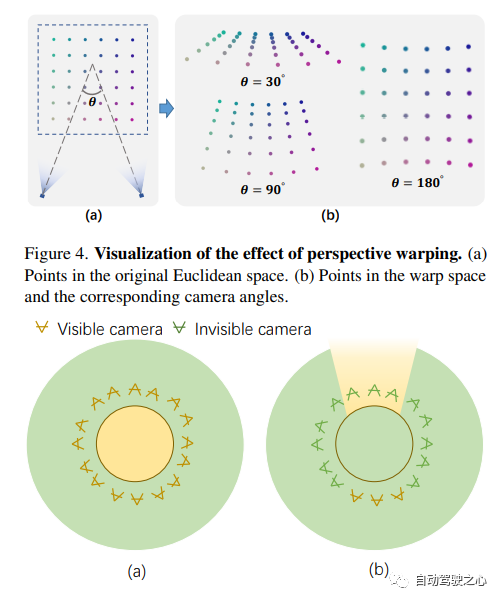
 F2-NeRF : Entraînement rapide sur le terrain à rayonnement neuronal avec trajectoires de caméra gratuites
F2-NeRF : Entraînement rapide sur le terrain à rayonnement neuronal avec trajectoires de caméra gratuites
Lien papier : https://totoro97.github.io /projects/f2-nerf/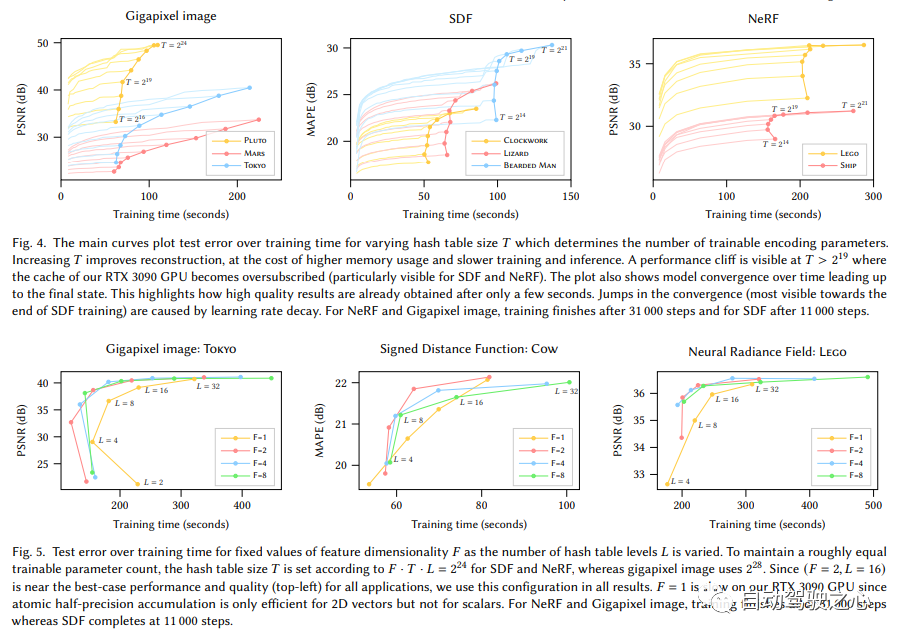
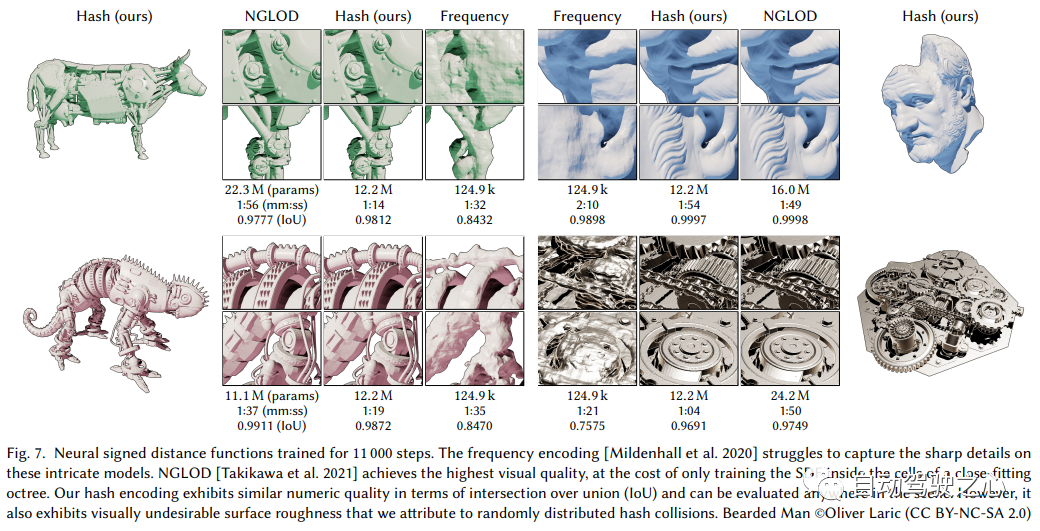

5.MobileNeRF
Application de rendu en temps réel côté mobile, réalisant la fonction de Nerf exportant Mesh, et cette technologie a été adoptée par la conférence CVPR2023 !
MobileNeRF : Exploiter le pipeline de rastérisation de polygones pour un rendu efficace du champ neuronal sur les architectures mobiles.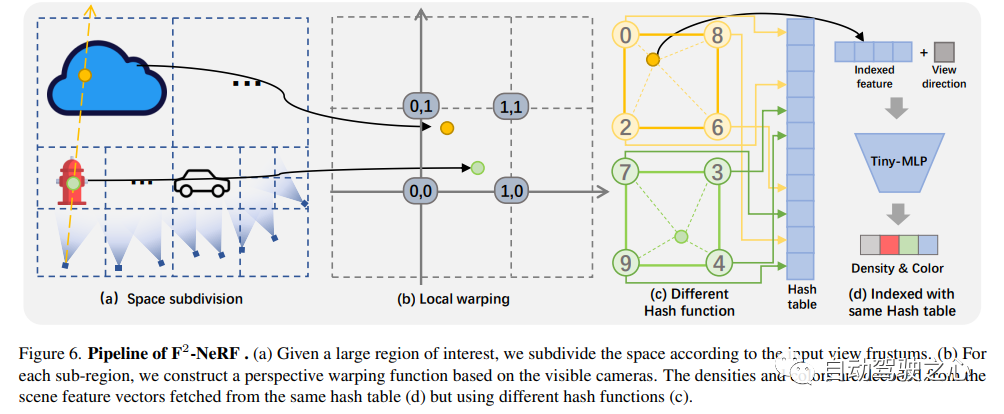
 Le champ de rayonnement neuronal (NeRF) a été prouvé L'incroyable capacité à synthétiser des images de scènes 3D à partir de nouvelles vues. Cependant, ils s’appuient sur des algorithmes de rendu volumétrique spécialisés basés sur le ray marching qui ne correspondent pas aux capacités du matériel graphique largement déployé. Cet article présente une nouvelle représentation NeRF basée sur des polygones texturés qui peut synthétiser efficacement de nouvelles images via des pipelines de rendu standard. NeRF est représenté comme un ensemble de polygones dont la texture représente l'opacité binaire et les vecteurs de caractéristiques. Le rendu traditionnel des polygones à l'aide d'un tampon z produit une image dans laquelle chaque pixel possède des caractéristiques qui sont interprétées par un petit MLP dépendant de la vue exécuté dans le fragment shader pour produire la couleur finale du pixel. Cette approche permet à NeRF d'effectuer un rendu à l'aide d'un pipeline de rastérisation de polygones traditionnel qui fournit un parallélisme massif au niveau des pixels, permettant des fréquences d'images interactives sur diverses plates-formes informatiques, y compris les téléphones mobiles.
Le champ de rayonnement neuronal (NeRF) a été prouvé L'incroyable capacité à synthétiser des images de scènes 3D à partir de nouvelles vues. Cependant, ils s’appuient sur des algorithmes de rendu volumétrique spécialisés basés sur le ray marching qui ne correspondent pas aux capacités du matériel graphique largement déployé. Cet article présente une nouvelle représentation NeRF basée sur des polygones texturés qui peut synthétiser efficacement de nouvelles images via des pipelines de rendu standard. NeRF est représenté comme un ensemble de polygones dont la texture représente l'opacité binaire et les vecteurs de caractéristiques. Le rendu traditionnel des polygones à l'aide d'un tampon z produit une image dans laquelle chaque pixel possède des caractéristiques qui sont interprétées par un petit MLP dépendant de la vue exécuté dans le fragment shader pour produire la couleur finale du pixel. Cette approche permet à NeRF d'effectuer un rendu à l'aide d'un pipeline de rastérisation de polygones traditionnel qui fournit un parallélisme massif au niveau des pixels, permettant des fréquences d'images interactives sur diverses plates-formes informatiques, y compris les téléphones mobiles.

6.Co-SLAM
Notre travail de localisation visuelle en temps réel et de cartographie NeRF a été inclus dans CVPR2023
Co-SLAM : Coordonnées conjointes et codages paramétriques clairsemés pour le SLAM neuronal en temps réel
Lien papier : https://arxiv.org/pdf/2304.14377.pdf
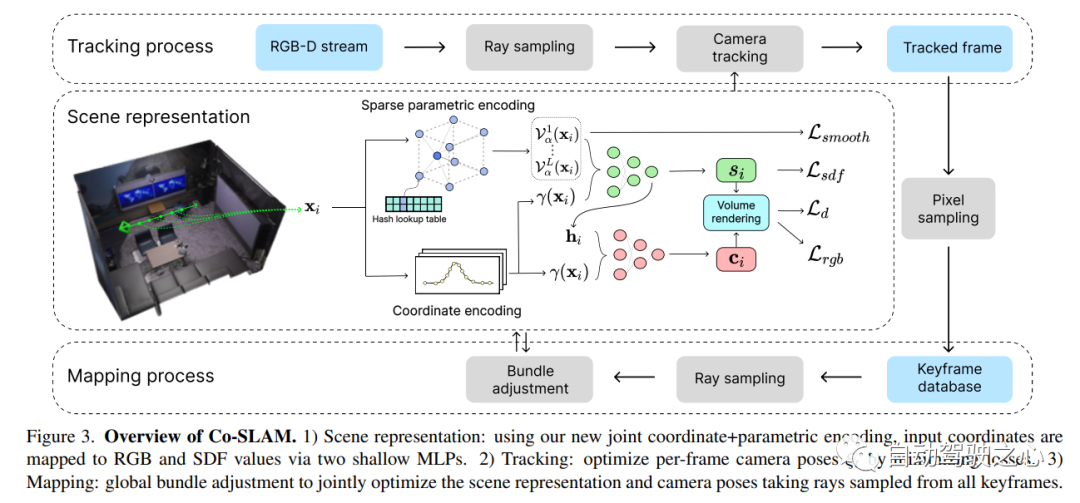
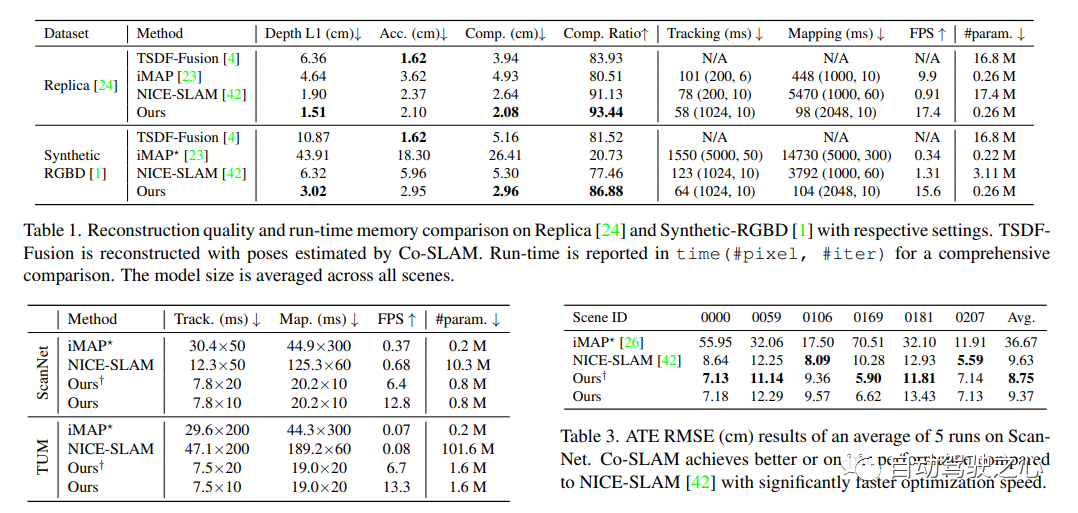
Co-SLAM est un système SLAM RVB-D en temps réel qui utilise des représentations neuronales implicites pour le suivi de la caméra et la reconstruction de surface haute fidélité. Co-SLAM représente la scène sous la forme d'une grille de hachage multi-résolution pour exploiter sa capacité à converger rapidement et à représenter des caractéristiques locales. De plus, afin d’incorporer les a priori de cohérence de surface, Co-SLAM utilise une méthode de codage par blocs, ce qui prouve qu’il peut compléter efficacement une scène dans des zones non observées. Notre encodage conjoint combine les avantages de la vitesse, de la reconstruction haute fidélité et des a priori de cohérence de surface de Co-SLAM. Grâce à une stratégie d'échantillonnage de rayons, Co-SLAM est capable de regrouper globalement les ajustements de toutes les images clés !

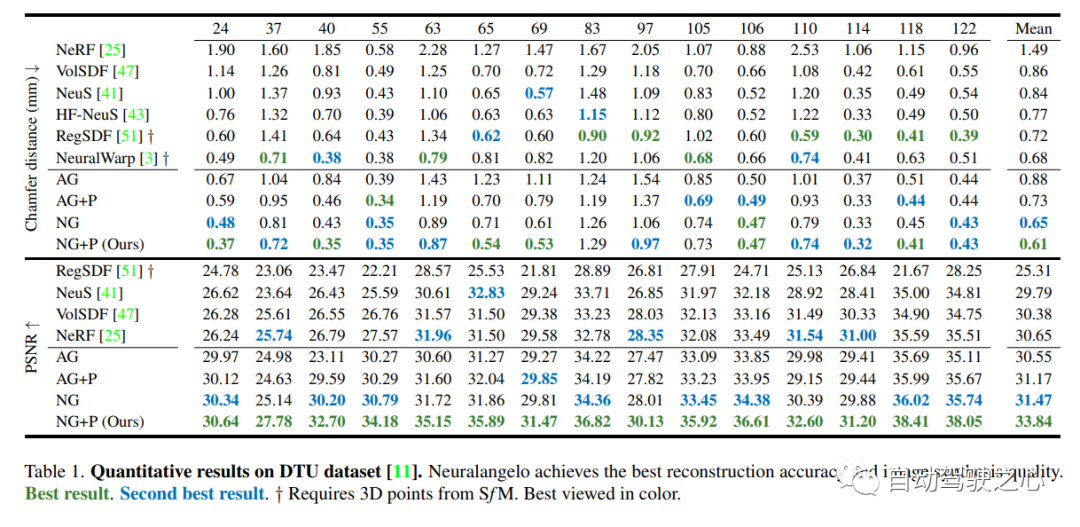
7.Neuralangelo
La meilleure méthode actuelle de reconstruction de surface NeRF (CVPR2023)

Le contenu réécrit est le suivant suit :
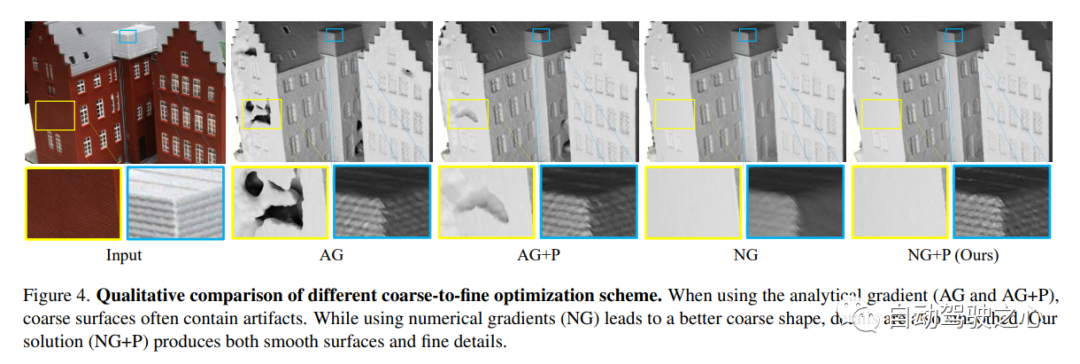
Il a été démontré que le rendu neuronal basé sur l’image est capable de reconstruire des surfaces neuronales pour récupérer des structures 3D denses. Cependant, les méthodes actuelles ont encore des difficultés à récupérer la structure détaillée des scènes du monde réel. Pour résoudre ce problème, cette étude propose une méthode appelée Neuralangelo, qui combine les capacités de représentation des grilles de hachage 3D multi-résolution avec le rendu de la surface neuronale. Deux éléments clés de cette approche sont :
(1) Les gradients numériques pour le calcul des dérivées d'ordre supérieur en tant qu'opérations de lissage, et (2) le contrôle de l'optimisation grossière à fine sur les grilles de hachage à différents niveaux de détail.
Même sans entrées auxiliaires telles que la profondeur, Neuralangelo est toujours capable de récupérer efficacement des structures de surface 3D denses à partir d'images multi-vues. La fidélité est grandement améliorée par rapport aux méthodes précédentes, permettant une reconstruction détaillée de scènes à grande échelle à partir de la capture vidéo RVB !


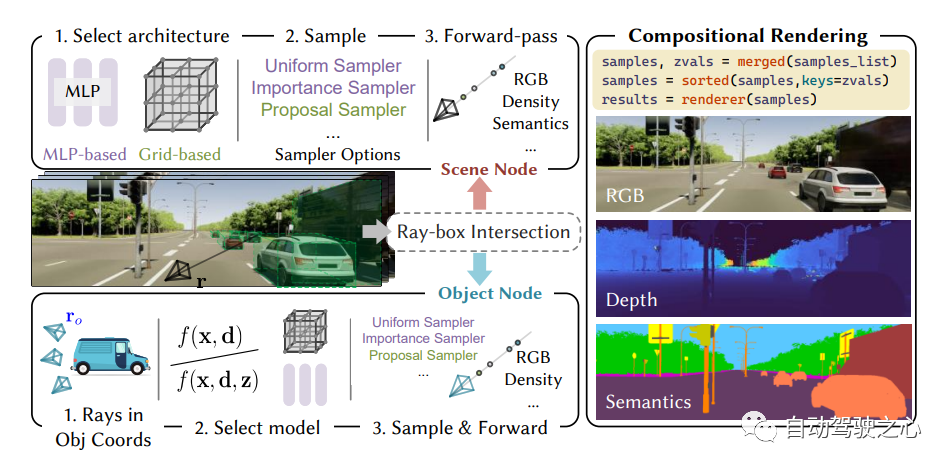
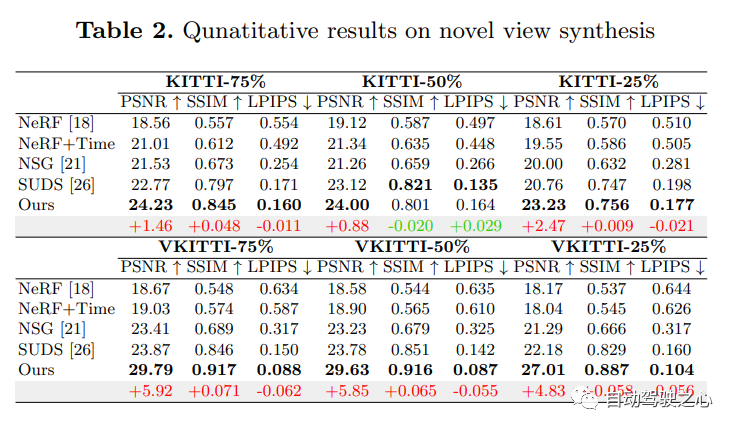
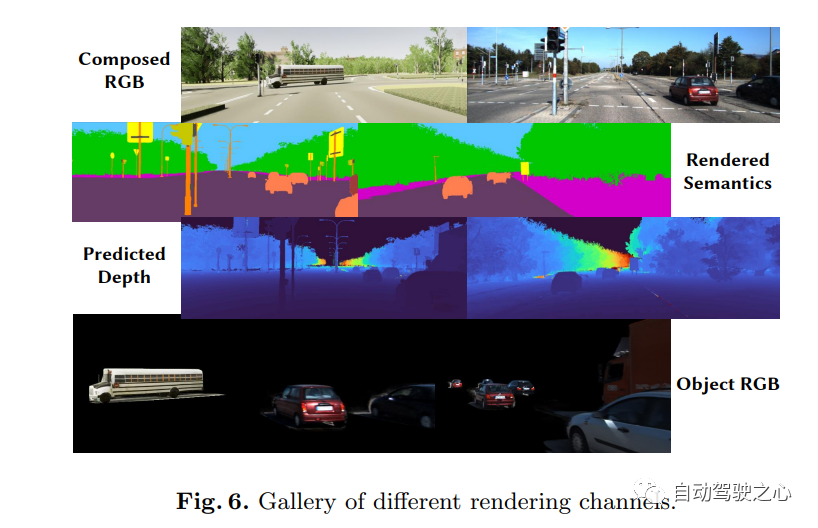
8.MARS
Le premier outil de simulation NeRF de conduite autonome open source.
Ce qui doit être réécrit est : https://arxiv.org/pdf/2307.15058.pdf
Les voitures autonomes peuvent rouler en douceur dans des situations ordinaires, et il est généralement admis qu'une simulation réaliste de capteurs jouera un rôle dans la résolution les situations de coin restantes jouent un rôle clé. À cette fin, MARS propose un simulateur de conduite autonome basé sur des champs de rayonnement neuronal. Par rapport aux travaux existants, MARS présente trois caractéristiques distinctives : (1) La connaissance des instances. Le simulateur modélise séparément les instances de premier plan et l'environnement d'arrière-plan à l'aide de réseaux distincts de sorte que les caractéristiques statiques (par exemple, taille et apparence) et dynamiques (par exemple, trajectoire) des instances peuvent être contrôlées séparément. (2) Modularité. Le simulateur permet une commutation flexible entre différents réseaux fédérateurs, stratégies d'échantillonnage, modes d'entrée, etc. modernes liés au NeRF. On espère que cette conception modulaire pourra promouvoir les progrès académiques et le déploiement industriel de simulations de conduite autonome basées sur NeRF. (3) Réel. Le simulateur est configuré pour des résultats photoréalistes de pointe avec une sélection de modules optimale.
Le point le plus important est : l'open source !

9.Uniocc
pour le contenu qui doit être réécrit, "Nerf et 3D Occupant Networks, AD2023 Challenge"
Uniocc: Unificant la prédiction d'occupation 3D centrée sur la vision avec rendu géométrique et sémantique.
Lien papier : https://arxiv.org/abs/2306.09117
UniOCC est une méthode de prédiction d'occupation 3D centrée sur la vision. Les méthodes traditionnelles de prédiction d'occupation utilisent principalement des étiquettes d'occupation 3D pour optimiser les caractéristiques de projection de l'espace 3D. Cependant, le processus de génération de ces étiquettes est complexe et coûteux, repose sur des annotations sémantiques 3D, est limité par la résolution des voxels et ne peut pas fournir un espace à granularité fine. .Sémantique. Pour résoudre ce problème, cet article propose une nouvelle méthode de prédiction d'occupation unifiée (UniOcc) qui impose explicitement des contraintes géométriques spatiales et complète la supervision sémantique fine via le rendu des rayons de volume. Cette approche améliore considérablement les performances du modèle et démontre le potentiel de réduction des coûts d'annotation manuelle. Compte tenu de la complexité de l’étiquetage de l’occupation 3D, nous introduisons en outre le cadre enseignant-élève (DTS) de détection de profondeur pour utiliser des données non étiquetées afin d’améliorer la précision des prédictions. Notre solution a obtenu un score mIoU de 51,27% sur le classement officiel d'un seul modèle, se classant troisième dans ce challenge
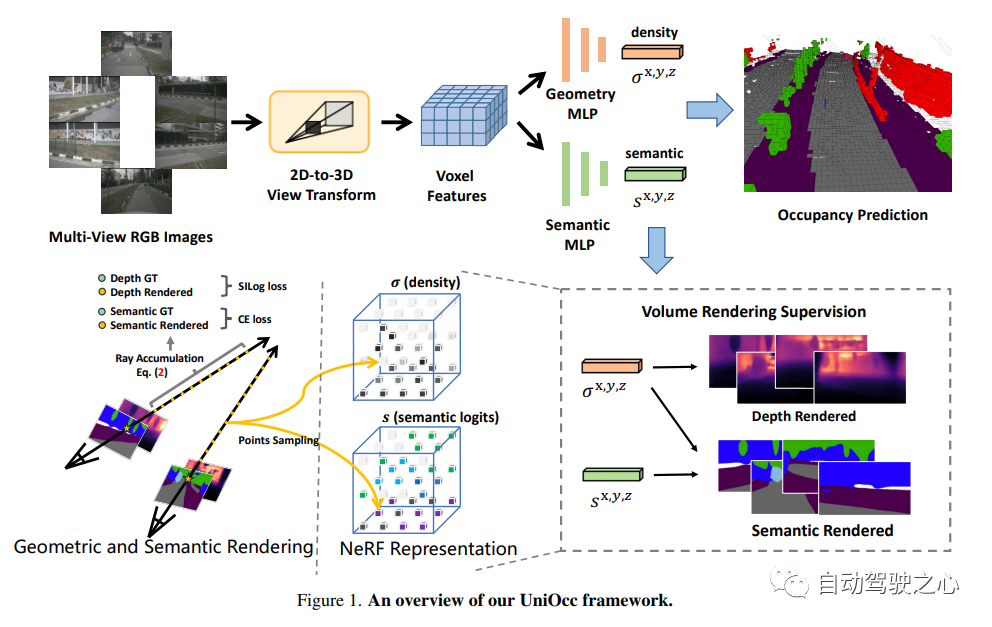
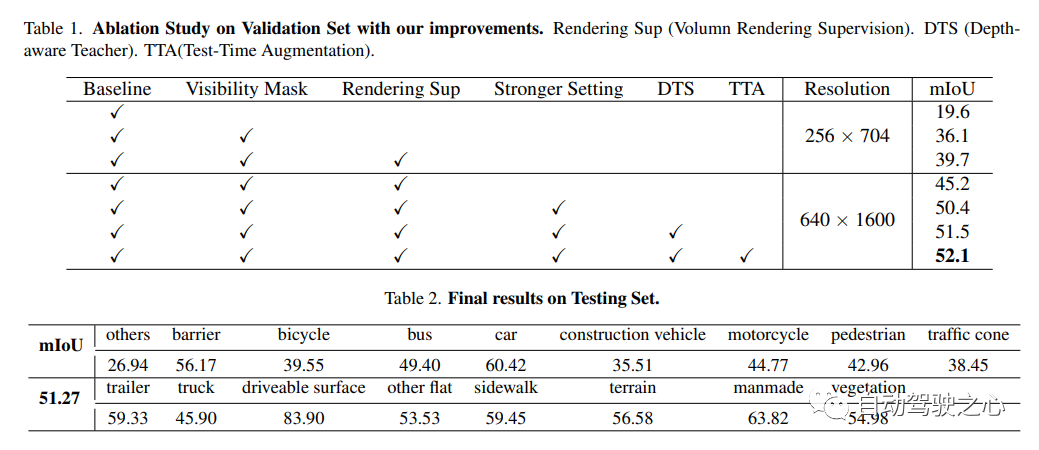
10 Unisim
produit par Wowaoao, absolument Excellent produit !
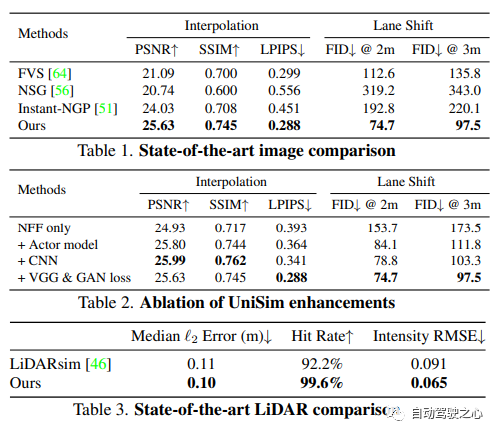
UniSim : Un simulateur de capteurs neuronaux en boucle fermée
Lien papier : https://arxiv.org/pdf/2308.01898.pdf
Une raison importante qui freine la vulgarisation de la conduite autonome est que la sécurité est encore insuffisante. Le monde réel est trop complexe, surtout avec l’effet longue traîne. Les scénarios de limites sont essentiels à une conduite sûre et sont divers mais difficiles à rencontrer. Il est très difficile de tester les performances des systèmes de conduite autonome dans ces scénarios car ces scénarios sont difficiles à rencontrer, et les tests dans le monde réel sont très coûteux et dangereux.
Pour résoudre ce défi, l'industrie et le monde universitaire ont commencé à y prêter attention. au développement de systèmes de simulation. Au début, le système de simulation se concentrait principalement sur la simulation du comportement de mouvement des autres véhicules/piétons et sur le test de la précision du module de planification de la conduite autonome. Ces dernières années, la recherche s'est progressivement déplacée vers la simulation au niveau des capteurs, c'est-à-dire la simulation pour générer des données brutes telles que des images lidar et des caméras, afin de réaliser des tests de bout en bout des systèmes de conduite autonome, de la perception à la prédiction en passant par la planification. .
Différent des travaux précédents, UniSim a réalisé les deux pour la première fois :
-
Haute réalisme : Peut simuler avec précision le monde réel (images et LiDAR) et réduire l'écart de domaine
-
Test en boucle fermée (fermé -simulation en boucle) :Peut générer des scènes dangereuses rares pour tester des véhicules sans pilote et permettre aux véhicules sans pilote d'interagir librement avec l'environnement
-
Évolutif (évolutif) :Peut être facilement étendu à d'autres Pour de nombreux scénarios, vous il suffit de collecter des données une seule fois pour reconstruire et simuler la mesure

Le contenu qui doit être réécrit est : la construction du système de simulation
UniSim commence d'abord à partir des données collectées dans le monde numérique Reconstruire scènes de conduite autonome, y compris les voitures, les piétons, les routes, les bâtiments et les panneaux de signalisation. Ensuite, contrôlez la scène reconstruite pour la simulation afin de générer des scènes clés rares.
Simulation en boucle fermée
UniSim peut effectuer des tests de simulation en boucle fermée. Premièrement, en contrôlant le comportement de la voiture, UniSim peut créer une scène dangereuse et rare, comme une voiture arrivant soudainement dans la voie actuelle. Ensuite, UniSim simule pour générer les données correspondantes ; puis exécute le système de conduite autonome et génère les résultats de la planification du chemin en fonction des résultats de la planification du chemin, le véhicule sans pilote se déplace vers l'emplacement désigné suivant et met à jour la scène (véhicule sans pilote et ; position des autres véhicules), puis nous continuons à simuler, à exécuter le système de conduite autonome et à mettre à jour l'état du monde virtuel... Grâce à ce test en boucle fermée, le système de conduite autonome et l'environnement de simulation peuvent interagir pour créer une scène qui est complètement différent des données originales

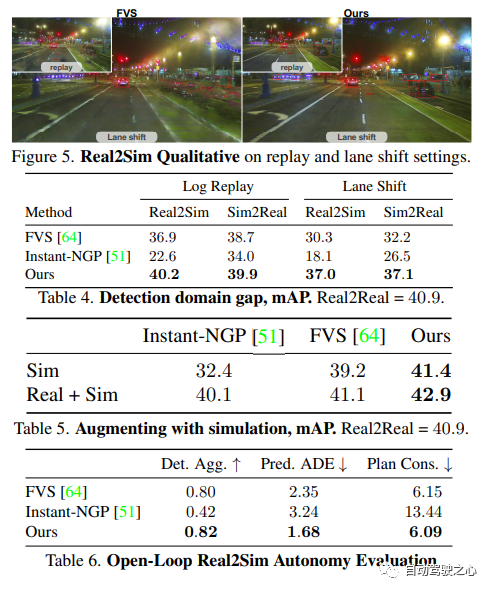
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser Python pour dessiner des tableaux académiques
- Méthode d'adaptation de domaine virtuel-réel pour la détection et la classification de voies de conduite autonomes
- Chen Guanling, partenaire technique de Fuyou Trucks : Application de la conduite autonome dans la logistique des grandes lignes
- Résumé des ressources d'ensembles de données open source pour la conduite autonome
- Comment utiliser les outils d'IA pour rédiger une bonne thèse de premier cycle : la technologie peut vous aider