
Maison >Périphériques technologiques >IA >Nouveau titre : lancement du NVIDIA H200 : capacité du HBM augmentée de 76 %, la puce IA la plus puissante qui améliore considérablement les performances des grands modèles de 90 %
Nouveau titre : lancement du NVIDIA H200 : capacité du HBM augmentée de 76 %, la puce IA la plus puissante qui améliore considérablement les performances des grands modèles de 90 %

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-14 15:21:131428parcourir

Actualités le 14 novembre, Nvidia a officiellement lancé le nouveau GPU H200 et mis à jour la gamme de produits GH200 lors de la conférence "Supercomputing 23" le 13 au matin, heure locale
Parmi eux, le H200 est toujours construit sur l'architecture Hopper H100 existante, mais ajoute plus de mémoire à large bande passante (HBM3e) pour mieux gérer les grands ensembles de données nécessaires au développement et à la mise en œuvre de l'intelligence artificielle, permettant d'exécuter de grands modèles. est amélioré de 60% à 90% par rapport à la génération précédente H100. Le GH200 mis à jour alimentera également la prochaine génération de supercalculateurs IA. Plus de 200 exaflops de puissance de calcul de l’IA seront mis en ligne en 2024.
H200 : capacité HBM augmentée de 76%, performances des grands modèles améliorées de 90%
Plus précisément, le nouveau H200 offre jusqu'à 141 Go de mémoire HBM3e, fonctionnant effectivement à environ 6,25 Gbit/s, pour une bande passante totale de 4,8 To/s par GPU dans les six piles HBM3e. Il s'agit d'une énorme amélioration par rapport à la génération précédente H100 (avec 80 Go HBM3 et 3,35 To/s de bande passante), avec une augmentation de plus de 76 % de la capacité HBM. Selon les données officielles, lors de l'exécution de grands modèles, le H200 apportera une amélioration de 60 % (GPT3 175B) à 90 % (Llama 2 70B) par rapport au H100


Bien que certaines configurations du H100 offrent plus de mémoire, comme le H100 NVL qui associe les deux cartes et offre un total de 188 Go de mémoire (94 Go par GPU), même par rapport à la variante H100 SXM, le nouveau H200 SXM Il fournit 76 % de capacité de mémoire en plus et 43 % de bande passante en plus.
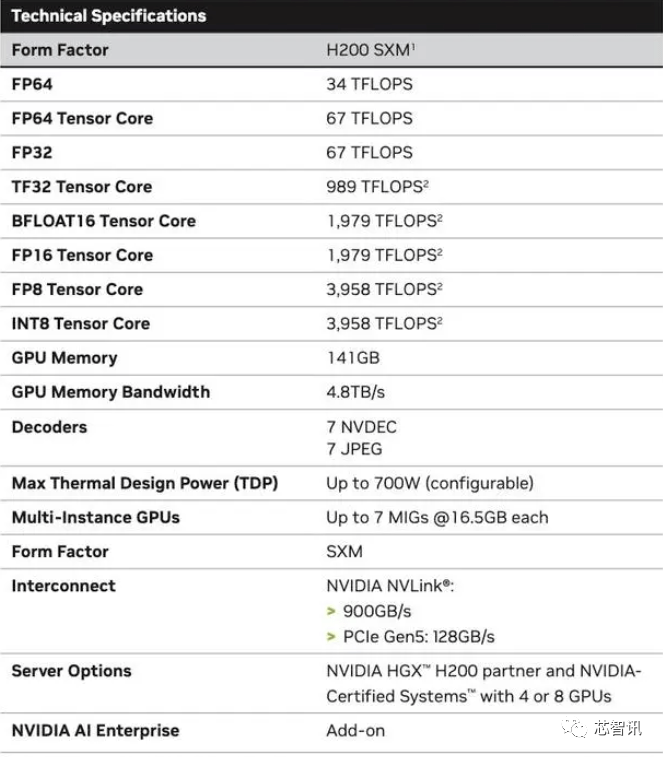
Il faut préciser que les performances de calcul brutes du H200 ne semblent pas avoir beaucoup changé. La seule diapositive que Nvidia a montrée montre que les performances de calcul reflétées étaient basées sur une configuration HGX 200 utilisant huit GPU, avec une performance totale de "32 PFLOPS FP8". Alors que le H100 d'origine fournissait 3 958 téraflops de puissance de calcul FP8, huit de ces GPU fournissent également environ 32 PFLOPS de puissance de calcul FP8
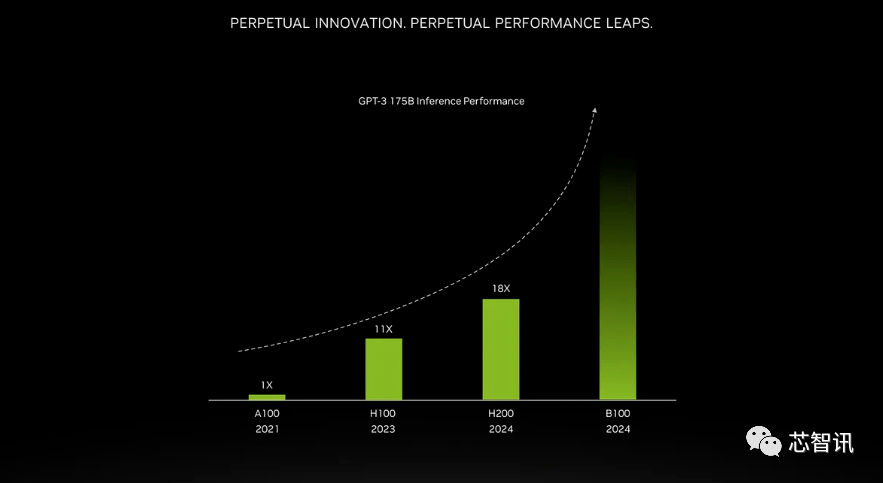
L'amélioration apportée par une mémoire à bande passante plus élevée dépend de la charge de travail. Les grands modèles (tels que le GPT-3) bénéficieront grandement de l'augmentation de la capacité mémoire HBM. Selon Nvidia, le H200 sera jusqu'à 18 fois plus performant que l'A100 d'origine et environ 11 fois plus rapide que le H100 lors de l'exécution de GPT-3. De plus, un teaser pour le prochain Blackwell B100 montre qu'il contient une barre plus haute qui devient noire, environ deux fois plus longue que le H200 le plus à droite
De plus, les H200 et H100 sont compatibles entre eux. En d’autres termes, les entreprises d’IA qui utilisent le modèle de formation/inférence H100 peuvent passer en toute transparence à la dernière puce H200. Les fournisseurs de services cloud n'ont pas besoin d'apporter de modifications lors de l'ajout du H200 à leur portefeuille de produits.
Nvidia a déclaré qu'en lançant de nouveaux produits, ils espèrent suivre le rythme de la croissance de la taille des ensembles de données utilisés pour créer des modèles et des services d'intelligence artificielle. Les capacités de mémoire améliorées rendront le H200 plus rapide dans le processus de transmission des données au logiciel, un processus qui aide à entraîner l'intelligence artificielle à effectuer des tâches telles que la reconnaissance d'images et de parole.
« L'intégration d'une mémoire HBM plus rapide et de plus grande capacité contribue à améliorer les performances des tâches exigeantes en termes de calcul, notamment les modèles d'IA génératifs et les applications de calcul hautes performances, tout en optimisant l'utilisation et l'efficacité du GPU, a déclaré Ian Buck, vice-président des produits.
Dion Harris, responsable des produits pour centres de données chez NVIDIA, a déclaré : « Lorsque vous regardez les tendances de développement du marché, la taille des modèles augmente rapidement. C'est un exemple de la façon dont nous continuons à introduire les technologies les plus récentes et les plus performantes.
Les fabricants d'ordinateurs centraux et les fournisseurs de services cloud devraient commencer à utiliser le H200 au deuxième trimestre 2024. Les partenaires fabricants de serveurs NVIDIA (dont Evergreen, ASUS, Dell, Eviden, Gigabyte, HPE, Hongbai, Lenovo, Wenda, MetaVision, Wistron et Wiwing) peuvent utiliser le H200 pour mettre à jour les systèmes existants, tandis qu'Amazon, Google, Microsoft, Oracle, etc. deviendra le premier fournisseur de services cloud à adopter H200.Compte tenu de la forte demande actuelle du marché pour les puces NVIDIA AI et du nouveau H200 ajoutant une mémoire HBM3e plus chère, le prix du H200 sera certainement plus cher. Nvidia n'indique pas de prix, mais la génération précédente du H100 coûtait entre 25 000 et 40 000 dollars.
La porte-parole de NVIDIA, Kristin Uchiyama, a déclaré que le prix final sera déterminé par les partenaires fabricants de NVIDIA
Quant à savoir si le lancement du H200 affectera la production du H100, Kristin Uchiyama a déclaré : « Nous nous attendons à ce que l'offre totale augmente tout au long de l'année
. »Les puces IA haut de gamme de Nvidia ont toujours été considérées comme le meilleur choix pour traiter de grandes quantités de données et former de grands modèles de langage et des outils de génération d'IA. Cependant, lorsque la puce H200 a été lancée, les sociétés d’IA recherchaient encore désespérément des puces A100/H100 sur le marché. L'attention du marché reste de savoir si Nvidia peut fournir une offre suffisante pour répondre à la demande du marché. Par conséquent, NVIDIA n’a pas répondu si les puces H200 seraient rares comme les puces H100
Cependant, l'année prochaine pourrait être une période plus favorable pour les acheteurs de GPU. Selon un rapport du Financial Times d'août, NVIDIA prévoit de tripler la production de H100 en 2024, et l'objectif de production passera d'environ 500 000 en 2023. 2 millions en 2024. Mais l’IA générative est toujours en plein essor et la demande sera probablement plus forte à l’avenir.
Par exemple, le GPT-4 récemment lancé est formé sur environ 10 000 à 25 000 blocs A100. Le grand modèle d’IA de Meta nécessite environ 21 000 blocs A100 pour la formation. Stability AI utilise environ 5 000 A100. La formation Falcon-40B nécessite 384 A100
Selon Musk, GPT-5 peut nécessiter 30 000 à 50 000 H100. Le devis de Morgan Stanley est de 25 000 GPU.
Sam Altman a nié la formation GPT-5, mais a mentionné que "OpenAI a une grave pénurie de GPU, et moins il y a de personnes utilisant nos produits, mieux c'est."
Bien entendu, outre NVIDIA, AMD et Intel entrent également activement sur le marché de l'IA pour concurrencer NVIDIA. Le MI300X précédemment lancé par AMD est équipé d'un HBM3 de 192 Go et d'une bande passante mémoire de 5,2 To/s, ce qui le fera largement dépasser le H200 en termes de capacité et de bande passante.
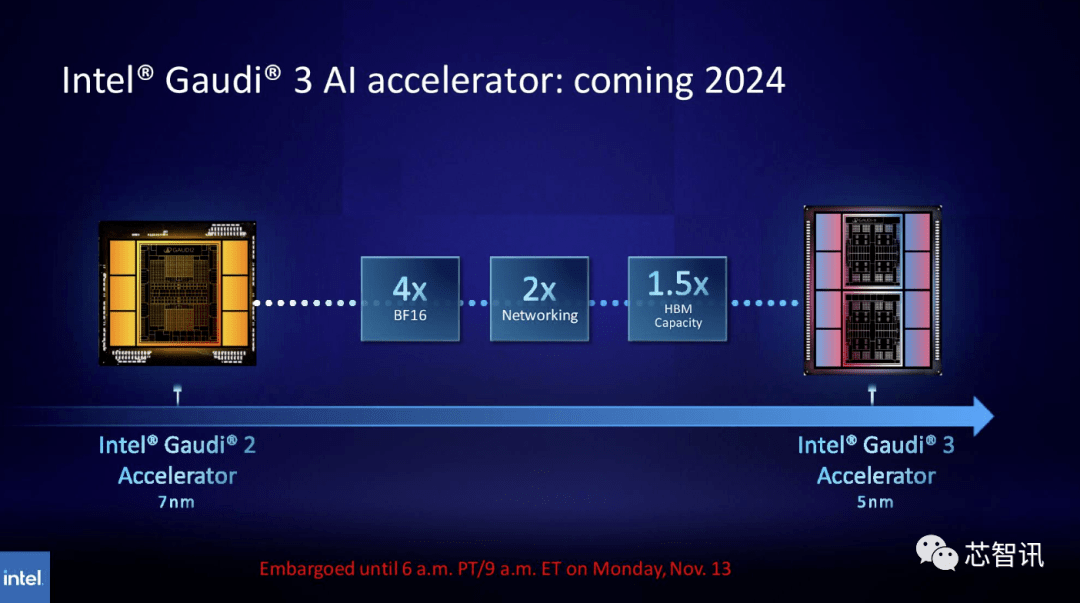
De même, Intel prévoit d'augmenter la capacité HBM des puces Gaudi AI. Selon les dernières informations publiées, Gaudi 3 utilise un processus 5 nm, et ses performances dans les charges de travail BF16 seront quatre fois supérieures à celles de Gaudi 2, et ses performances réseau seront également deux fois supérieures à celles de Gaudi 2 (Gaudi 2 dispose de 24 100 cartes réseau GbE RoCE). De plus, Gaudi 3 a 1,5 fois la capacité HBM de Gaudi 2 (Gaudi 2 a un HBM2E de 96 Go). Comme le montre l'image ci-dessous, Gaudi 3 utilise une conception basée sur des chipsets avec deux clusters informatiques, contrairement à Gaudi 2 qui utilise la solution monopuce d'Intel
Nouvelle superpuce GH200 : alimente la prochaine génération de supercalculateurs IA
En plus de lancer le nouveau GPU H200, NVIDIA a également lancé une version améliorée de la super puce GH200. Cette puce utilise la technologie d'interconnexion de puce NVIDIA NVLink-C2C, combinant le dernier GPU H200 et le processeur Grace (je ne sais pas s'il s'agit d'une version mise à niveau). Chaque super puce GH200 embarquera également un total de 624 Go de mémoire

À titre de comparaison, la génération précédente du GH200 est basée sur un GPU H100 et un processeur Grace à 72 cœurs, fournissant 96 Go de HBM3 et 512 Go de LPDDR5X intégrés dans le même package.
Bien que NVIDIA n'ait pas introduit les détails du processeur Grace dans la super puce GH200, NVIDIA a fourni quelques comparaisons entre le GH200 et les « processeurs x86 modernes à double socket ». On peut voir que le GH200 a apporté une amélioration de 8 fois aux performances de l'ICON, et que MILC, Quantum Fourier Transform, RAG LLM Inference, etc. ont apporté des dizaines, voire des centaines de fois d'amélioration.
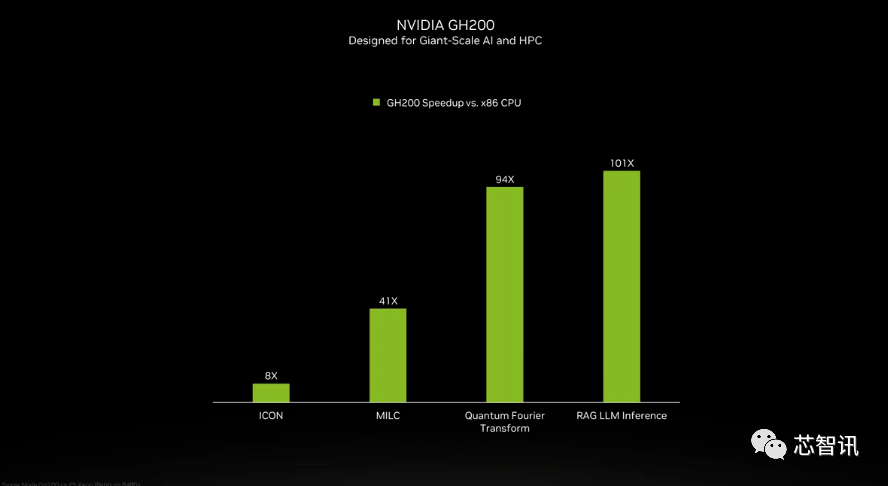
Mais il faut préciser que les systèmes accélérés et « non accélérés » sont mentionnés. qu'est-ce que cela signifie? Nous ne pouvons que supposer que les serveurs x86 exécutent un code qui n’est pas entièrement optimisé, d’autant plus que le monde de l’intelligence artificielle évolue rapidement et que de nouvelles avancées en matière d’optimisation semblent apparaître régulièrement.
Le nouveau GH200 sera également utilisé dans le nouveau système HGX H200. Ceux-ci sont dits « parfaitement compatibles » avec les systèmes HGX H100 existants, ce qui signifie que le HGX H200 peut être utilisé dans la même installation pour augmenter les performances et la capacité de mémoire sans avoir besoin de reconcevoir l'infrastructure.
Selon certaines informations, le supercalculateur alpin du Centre national suisse de calcul scientifique pourrait être l'un des premiers supercalculateurs Grace Hopper basés sur le GH100 mis en service l'année prochaine. Le premier système GH200 à entrer en service aux États-Unis sera le supercalculateur Venado du Laboratoire national de Los Alamos. Les systèmes Vista du Texas Advanced Computing Center (TACC) utiliseront également les superpuces Grace CPU et Grace Hopper qui viennent d'être annoncées, mais on ne sait pas si elles seront basées sur le H100 ou le H200

Actuellement, le plus grand supercalculateur installé est le supercalculateur Jupiter du Jϋlich Supercomputing Center. Il abritera « près » de 24 000 superpuces GH200, totalisant 93 exaflops de calcul d’IA (vraisemblablement utilisant FP8, bien que la plupart des IA utilisent encore BF16 ou FP16). Il fournira également 1 exaflop de calcul FP64 traditionnel. Il utilisera une carte « Quad GH200 » avec quatre superpuces GH200.
Ces nouveaux supercalculateurs que NVIDIA prévoit d'installer au cours de la prochaine année atteindront, collectivement, plus de 200 exaflops de puissance de calcul en matière d'intelligence artificielle
Si le sens original n'a pas besoin d'être modifié, le contenu doit être réécrit en chinois et la phrase originale n'a pas besoin d'apparaître
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Mini programme : utilisez wx:key pour améliorer l'efficacité du rendu de wx:for
- Comment les programmeurs peuvent-ils s'améliorer à l'avenir ?
- Qu'est-ce que php-fpm ? Comment optimiser pour améliorer les performances ?
- Grosse avancée, annoncée par l'Académie chinoise des sciences ! 1,5 à 10 fois plus rapides que Nvidia, les puces IA vont-elles changer le monde ? Limite quotidienne directe du leader du concept
- IBM envisage d'utiliser ses propres puces IA dans de nouveaux services cloud [Avec analyse des perspectives mondiales de développement des puces IA]