
Maison >Périphériques technologiques >IA >Méthode d'adaptation de domaine virtuel-réel pour la détection et la classification de voies de conduite autonomes
Méthode d'adaptation de domaine virtuel-réel pour la détection et la classification de voies de conduite autonomes

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-08 14:31:121959parcourir
Article arXiv « Adaptation du domaine Sim-to-Real pour la détection et la classification des voies dans la conduite autonome », mai 2022, travail à l'Université de Waterloo, Canada.

Bien que le cadre de détection et de classification supervisée pour la conduite autonome nécessite de grands ensembles de données annotées, la méthode Unsupervised Domain Adaptation (UDA, Unsupervised Domain Adaptation) pilotée par des données synthétiques générées par l'éclairage d'environnements de simulation réels est peu coûteuse, Solution qui prend moins de temps. Cet article propose un schéma UDA de méthodes discriminantes et génératives contradictoires pour les applications de détection et de classification des lignes de voie dans la conduite autonome.
Présente également le générateur d'ensembles de données Simulanes, qui tire parti des énormes scènes de circulation et des conditions météorologiques de CARLA pour créer un ensemble de données synthétiques naturelles. Le cadre UDA proposé prend l'ensemble de données synthétiques étiquetées comme domaine source, tandis que le domaine cible est constitué des données réelles non étiquetées. Utilisez la génération contradictoire et le discriminateur de fonctionnalités pour déboguer le modèle d'apprentissage et prédire l'emplacement et la catégorie de la voie du domaine cible. L'évaluation est effectuée avec des ensembles de données réelles et synthétiques.
Le framework UDA open source se trouve sur githubcom/anita-hu/sim2real-lane-detection, et le générateur d'ensembles de données se trouve sur github.com/anita-hu/simulanes.
La conduite dans le monde réel est diversifiée, avec des conditions de circulation, des conditions météorologiques et des environnements variables. La diversité des scénarios de simulation est donc cruciale pour la bonne adaptabilité du modèle au monde réel. Il existe de nombreux simulateurs open source pour la conduite autonome, à savoir CARLA et LGSVL. Cet article choisit CARLA pour générer l'ensemble de données de simulation. En plus de l'API Python flexible, CARLA contient également un riche contenu cartographique pré-dessiné couvrant des scènes urbaines, rurales et routières.
Générateur de données de simulation Simulanes génère une variété de scénarios de simulation dans des environnements urbains, ruraux et routiers, y compris 15 catégories de voies et une météo dynamique. La figure montre des échantillons de l'ensemble de données synthétiques. Les piétons et les véhicules participants sont générés de manière aléatoire et placés sur la carte, augmentant ainsi la difficulté de l'ensemble de données par occlusion. Selon les ensembles de données TuSimple et CULane, le nombre maximum de voies à proximité du véhicule est limité à 4 et les ancrages de rangée sont utilisés comme étiquettes.

Étant donné que le simulateur CARLA ne fournit pas directement les étiquettes d'emplacement des voies, le système de points de cheminement de CARLA est utilisé pour générer des étiquettes. Un waypoint CARLA est une position prédéfinie que le pilote automatique du véhicule doit suivre, située au centre de la voie. Afin d'obtenir l'étiquette de position de voie, le waypoint de la voie actuelle est déplacé vers la gauche et la droite de W/2, où W est la largeur de voie donnée par le simulateur. Ces points de cheminement déplacés sont ensuite projetés dans le système de coordonnées de la caméra et ajustés par spline pour générer des étiquettes le long de points d'ancrage de rangée prédéterminés. L'étiquette de classe est donnée par le simulateur et constitue l'une des 15 classes.
Pour générer un ensemble de données avec N images, divisez N uniformément sur toutes les cartes disponibles. À partir de la carte CARLA par défaut, les villes 1, 3, 4, 5, 7 et 10 ont été utilisées, tandis que les villes 2 et 6 n'ont pas été utilisées en raison des différences entre les étiquettes de position des voies extraites et les positions des voies de l'image. Pour chaque carte, les véhicules participants apparaissent à des endroits aléatoires et se déplacent de manière aléatoire. La météo dynamique est obtenue en changeant doucement la position du soleil en fonction sinusoïdale du temps et en produisant occasionnellement des tempêtes, qui affectent l'apparence de l'environnement à travers des variables telles que la couverture nuageuse, le volume d'eau et l'eau stagnante. Pour éviter d'enregistrer plusieurs images au même emplacement, vérifiez si le véhicule s'est déplacé de l'emplacement de l'image précédente et régénérez un nouveau véhicule s'il est resté à l'arrêt trop longtemps.
Lorsque l'algorithme sim-to-real est appliqué à la détection de voie, une approche de bout en bout est adoptée et le Modèle de détection de voie ultra-rapide (UFLD) est utilisé comme réseau de base. UFLD a été choisi car son architecture légère peut atteindre 300 images/seconde avec la même résolution d'entrée tout en atteignant des performances comparables aux méthodes de pointe. UFLD formule la tâche de détection de voie comme une méthode de sélection basée sur les lignes, où chaque voie est représentée par une série de positions horizontales de lignes prédéfinies, c'est-à-dire des ancres de ligne. Pour chaque ancre de ligne, la position est divisée en w cellules de grille. Pour l'ancre de la i-ème voie et de la j-ème rangée, la prédiction d'emplacement devient un problème de classification, où le modèle génère la probabilité Pi,j de sélectionner la cellule de grille (w+1). La dimension supplémentaire dans la sortie est l'absence de voies.
UFLD propose une branche de segmentation auxiliaire pour agréger des fonctionnalités à plusieurs échelles afin de modéliser des fonctionnalités locales. Elle n'est utilisée que lors de la formation. Avec la méthode UFLD, la perte d'entropie croisée est utilisée pour la perte de segmentation Lseg. Pour la classification des voies, une petite branche de la couche entièrement connectée (FC) est ajoutée pour recevoir les mêmes fonctionnalités que la couche FC pour la prédiction de la position des voies. La perte de classification de voie Lcls utilise également la perte d'entropie croisée.
Pour atténuer le problème de dérive de domaine des paramètres UDA, UNIT(« Réseaux de traduction d'image à image non supervisés», NIPS, 2017) & MUNIT(« Traduction multimodale d'image à image non supervisée, » ECCV 2018) méthode de génération contradictoire et méthode discriminante contradictoire utilisant un discriminateur de fonctionnalités. Comme le montre la figure : une méthode de génération contradictoire (A) et une méthode de discrimination contradictoire (B) sont proposées. UNIT et MUNIT sont représentés en (A), qui montre l'entrée du générateur pour la traduction d'image. Les entrées de style supplémentaires dans MUNIT sont affichées avec des lignes bleues en pointillés. Pour plus de simplicité, la sortie de l'encodeur de style MUNIT est omise car elle n'est pas utilisée pour la traduction d'image.

Les résultats expérimentaux sont les suivants :
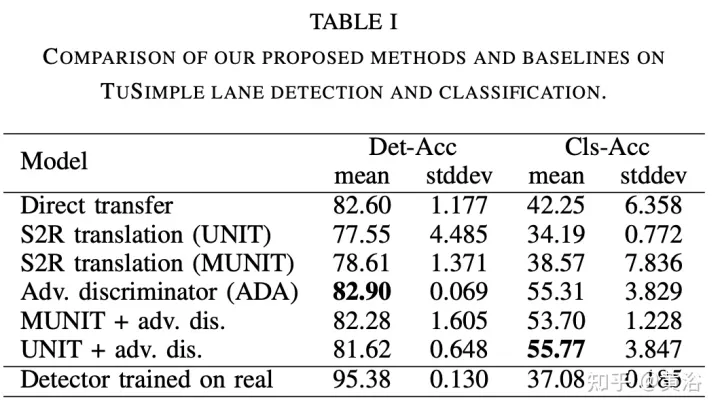

Gauche : méthode de transfert direct, droite : méthode d'identification contradictoire (ADA)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI