
Maison >Périphériques technologiques >IA >Laissez les grands modèles d'IA poser des questions de manière autonome : GPT-4 élimine les obstacles à la conversation avec les humains et démontre des niveaux de performance plus élevés
Laissez les grands modèles d'IA poser des questions de manière autonome : GPT-4 élimine les obstacles à la conversation avec les humains et démontre des niveaux de performance plus élevés

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-13 08:26:321191parcourir
Dans les dernières tendances dans le domaine de l'intelligence artificielle, la qualité des invites générées artificiellement a un impact décisif sur la précision de réponse des grands modèles de langage (LLM). OpenAI propose que des questions précises, détaillées et spécifiques soient essentielles à la performance de ces grands modèles de langage. Cependant, les utilisateurs ordinaires peuvent-ils garantir que leurs questions sont suffisamment claires pour le LLM ?
Le contenu qui doit être réécrit est le suivant : Il convient de noter qu'il existe une différence significative entre la compréhension naturelle des humains dans certaines situations et l'interprétation automatique. Par exemple, le concept de « mois pairs » fait évidemment référence à des mois comme février et avril pour les humains, mais GPT-4 peut le comprendre à tort comme des mois avec un nombre de jours pair. Cela révèle non seulement les limites de l’intelligence artificielle dans la compréhension du contexte quotidien, mais nous incite également à réfléchir à la manière de communiquer plus efficacement avec ces grands modèles linguistiques. Avec les progrès continus de la technologie de l'intelligence artificielle, comment combler le fossé entre les humains et les machines dans la compréhension du langage est un sujet important pour les recherches futures
À ce sujet, l'Institut général de recherche dirigé par le professeur Gu Quanquan de l'Université de Californie , Los Angeles (UCLA) Le laboratoire d'intelligence artificielle a publié un rapport de recherche proposant une solution innovante au problème d'ambiguïté dans la compréhension des problèmes de grands modèles de langage (tels que GPT-4). Cette recherche a été réalisée par les doctorants Deng Yihe, Zhang Weitong et Chen Zixiang

- Adresse papier : https://arxiv.org/pdf/2311.04205.pdf
- Projet adresse : https://uclaml.github.io/Rephrase-and-Respond
Le contenu chinois réécrit est le suivant : Le cœur de cette solution est de laisser un grand modèle de langage répéter et élargir les questions soulevées, afin que pour améliorer l’exactitude de vos réponses. L'étude a révélé que les questions reformulées par GPT-4 sont devenues plus détaillées et que le format des questions était plus clair. Cette méthode de retraitement et d'expansion améliore considérablement la précision des réponses du modèle. Des expériences ont montré qu'une question bien répétée augmente la précision de la réponse de 50 % à près de 100 %. Cette amélioration des performances démontre non seulement le potentiel d'auto-amélioration des grands modèles de langage, mais offre également une nouvelle perspective sur la façon dont l'intelligence artificielle peut traiter et comprendre le langage humain plus efficacement. Une invite simple mais efficace : « Reformulez et développez la question, et ». répondre »(RaR pour faire court). Ce mot d'invite améliore directement la qualité des réponses de LLM aux questions, démontrant une amélioration importante dans le traitement des problèmes.
L'équipe de recherche a également proposé une variante de RaR appelée « Two-step RaR » pour tirer pleinement parti de la capacité de grands modèles comme GPT-4 à reformuler le problème. Cette approche suit deux étapes : premièrement, pour une question donnée, un LLM de reformulation spécialisé est utilisé pour générer une question de reformulation ; deuxièmement, la question originale et la question reformulée sont combinées et utilisées pour demander une réponse à un LLM de réponse.

Résultats

Les chercheurs ont mené des expériences sur différentes tâches, et les résultats ont montré que le RaR en une seule étape et le RaR en deux étapes peuvent améliorer efficacement la précision des réponses de GPT4. Notamment, RaR montre des améliorations significatives sur des tâches qui seraient autrement difficiles pour GPT-4, approchant même une précision de 100 % dans certains cas. L'équipe de recherche a résumé les deux conclusions clés suivantes :
1. Restate and Extend (RaR) fournit une méthode d'invite de boîte noire plug-and-play qui peut améliorer efficacement les performances de LLM sur diverses tâches. 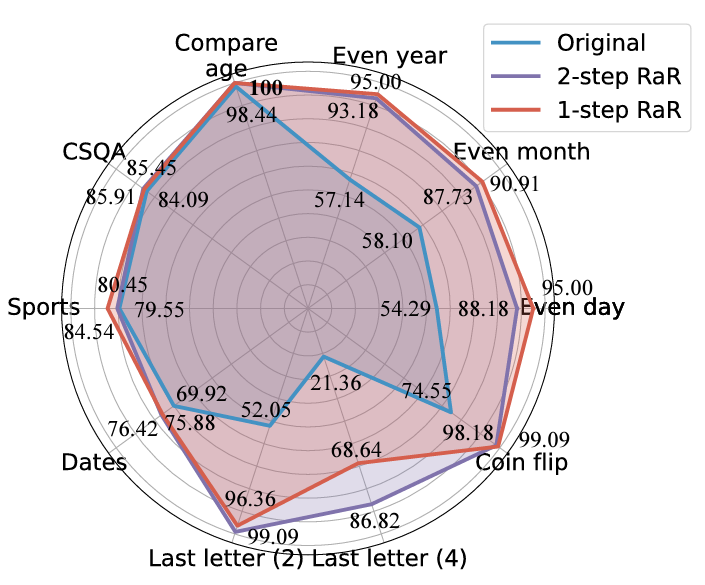
2. Lors de l'évaluation des performances du LLM sur les tâches de réponse aux questions (QA), il est crucial de vérifier la qualité des questions.
Les chercheurs ont utilisé la méthode RaR en deux étapes pour mener des recherches visant à explorer les performances de différents modèles tels que GPT-4, GPT-3.5 et Vicuna-13b-v.15. Les résultats expérimentaux montrent que pour les modèles dotés d'une architecture plus complexe et de capacités de traitement plus fortes, tels que GPT-4, la méthode RaR peut améliorer considérablement la précision et l'efficacité des problèmes de traitement. Pour les modèles plus simples, comme Vicuna, même si l’amélioration est moindre, elle montre quand même l’efficacité de la stratégie RaR. Sur cette base, les chercheurs ont examiné plus en détail la qualité des questions après avoir raconté différents modèles. Les questions de reformulation pour des modèles plus petits peuvent parfois perturber l'intention de la question. Et les modèles avancés comme GPT-4 fournissent des questions de paraphrase qui sont cohérentes avec les intentions humaines et peuvent améliorer les réponses d'autres modèles

Cette découverte révèle un phénomène important : différents niveaux de paraphrase du modèle de langage. Les questions varient en qualité et efficacité. Surtout pour les modèles avancés comme GPT-4, les problèmes qu'il réaffirme permettent non seulement de mieux comprendre le problème, mais peuvent également servir de contribution efficace pour améliorer les performances d'autres modèles plus petits.
Différence par rapport à la chaîne de pensée (CoT)
Pour comprendre la différence entre RaR et la chaîne de pensée (CoT), les chercheurs ont proposé leurs représentations mathématiques et ont clarifié en quoi RaR est mathématiquement différent de CoT et avec quelle facilité ils peuvent être combinés.
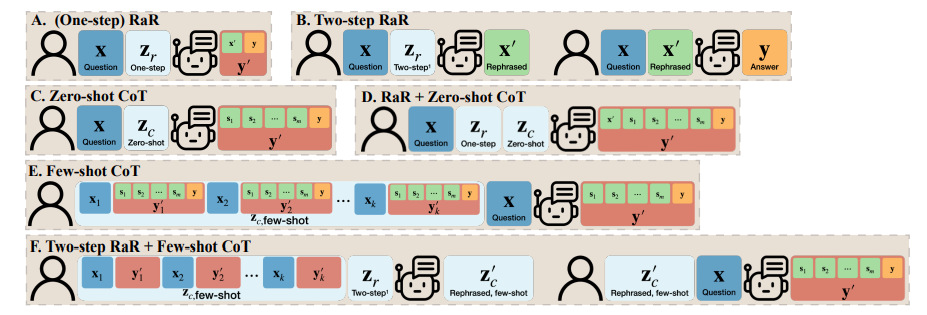
Avant d’examiner comment améliorer la capacité de raisonnement du modèle, cette étude souligne que la qualité des questions doit être améliorée pour garantir que la capacité de raisonnement du modèle puisse être correctement évaluée. Par exemple, dans le problème du « lancer de pièces », il a été constaté que GPT-4 comprenait le « retournement » comme une action de lancer aléatoire, qui était différente de l'intention humaine. Même si « réfléchissons étape par étape » est utilisé pour guider le modèle dans le raisonnement, ce malentendu persistera tout au long du processus d'inférence. Ce n'est qu'après avoir clarifié la question que le grand modèle de langage a répondu à la question prévue

De plus, les chercheurs ont remarqué qu'en plus du texte de la question, les exemples de questions et réponses utilisés pour le CoT à quelques plans étaient également écrits par des humains. Cela soulève la question : comment réagissent les grands modèles de langage (LLM) lorsque ces exemples construits artificiellement sont défectueux ? Cette étude fournit un exemple intéressant et révèle que de mauvais exemples de CoT en quelques plans peuvent avoir un impact négatif sur le LLM. En prenant comme exemple la tâche « Final Letter Join », les exemples de problèmes utilisés précédemment ont montré des effets positifs sur l'amélioration des performances du modèle. Cependant, lorsque la logique de l'invite changeait, par exemple de la recherche de la dernière lettre à la recherche de la première lettre, GPT-4 donnait la mauvaise réponse. Ce phénomène met en évidence la sensibilité du modèle aux exemples artificiels.

Les chercheurs ont découvert qu'en utilisant RaR, GPT-4 peut corriger des défauts logiques dans un exemple donné, améliorant ainsi la qualité et la robustesse des CoT à quelques tirs
Conclusion
Communication humaine et large entre les modèles de langage (LLM) peuvent être mal compris : les questions qui semblent claires aux humains peuvent être comprises par les grands modèles de langage comme d'autres questions. L'équipe de recherche de l'UCLA a résolu ce problème en proposant RaR, une nouvelle méthode qui incite LLM à reformuler et à clarifier la question avant d'y répondre
L'efficacité de RaR a été démontrée par des expériences menées sur plusieurs ensembles de données de référence. L'évaluation a été confirmée. Les résultats d'une analyse plus approfondie montrent que la qualité du problème peut être améliorée en reformulant le problème, et cet effet d'amélioration peut être transféré entre différents modèles
Pour les perspectives futures, on s'attend à ce que les méthodes similaires à RaR continuent d'être améliorées, et au en même temps, l'intégration avec d'autres méthodes telles que CoT fournira un moyen plus précis et plus efficace d'interagir entre les humains et les grands modèles de langage, repoussant à terme les limites des capacités d'explication et de raisonnement de l'IA
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!