
Maison >Périphériques technologiques >IA >La recherche sur les grands modèles de Google a déclenché une vive controverse : la capacité de généralisation au-delà des données de formation a été remise en question, et les internautes ont déclaré que la singularité de l'AGI pourrait être retardée.
La recherche sur les grands modèles de Google a déclenché une vive controverse : la capacité de généralisation au-delà des données de formation a été remise en question, et les internautes ont déclaré que la singularité de l'AGI pourrait être retardée.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-13 08:26:39848parcourir
Un nouveau résultat récemment découvert par Google DeepMind a suscité une large controverse dans le domaine des Transformers :
Sa capacité de généralisation ne peut pas être étendue au contenu au-delà des données d'entraînement.
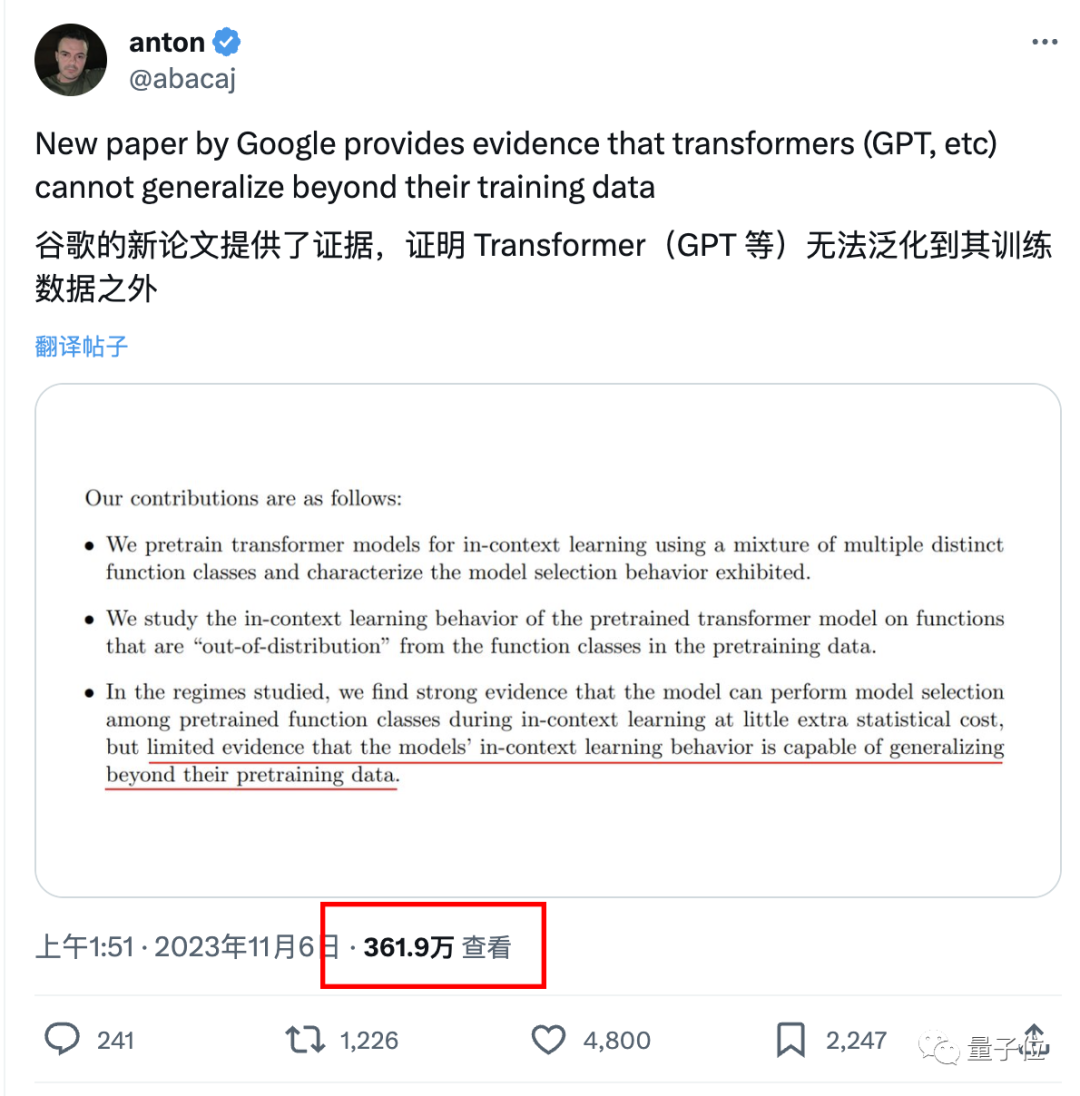
À l'heure actuelle, cette conclusion n'a pas été vérifiée davantage, mais elle a alarmé de nombreux grands noms. Par exemple, François Chollet, le père de Keras, a déclaré que si la nouvelle est vraie, elle deviendra un grand événement en. la grande industrie du mannequinat.

Google Transformer est l'infrastructure derrière les grands modèles d'aujourd'hui, et le "T" de GPT que nous connaissons y fait référence.
Une série de grands modèles démontrent de fortes capacités d'apprentissage contextuel et peuvent rapidement apprendre des exemples et effectuer de nouvelles tâches.
Mais maintenant, des chercheurs de Google semblent également avoir souligné son défaut fatal : il est impuissant au-delà des données d'entraînement, c'est-à-dire des connaissances humaines existantes.
Pendant un certain temps, de nombreux praticiens ont cru que l'AGI était redevenue hors de portée.
Certains internautes ont souligné que certains détails clés ont été ignorés dans le document, tels que l'expérience n'implique que l'échelle de GPT-2 et que les données d'entraînement ne sont pas assez riches
Comme Au fil du temps, des internautes plus sérieux qui ont étudié cet article ont souligné qu'il n'y avait rien de mal dans les conclusions de la recherche elle-même, mais que les gens ont fait des interprétations excessives sur cette base.

Après que l'article ait suscité des discussions animées parmi les internautes, l'un des auteurs a également publiquement apporté deux précisions :
Premièrement, un simple Transformer a été utilisé dans l'expérience, qui n'est ni un « grand » modèle ni un modèle de langage ;
Deuxièmement, le modèle peut apprendre de nouvelles tâches, mais il ne peut pas être généralisé à de nouveaux types de tâches

Depuis lors, certains internautes ont répété cette expérience dans Colab, mais ont obtenu des résultats complètement différents.

Alors, jetons d'abord un coup d'œil à cet article et à ce que Samuel, qui a proposé différents résultats, a dit.
La nouvelle fonction est presque impossible à prédire
Dans cette expérience, l'auteur a utilisé un framework d'apprentissage automatique basé sur Jax pour former un modèle Transformer proche de la taille de GPT-2, qui ne contient que la partie décodeur
Ce modèle contient 12 couches, 8 Il y a une tête d'attention, la dimension de l'espace d'intégration est de 256 et le nombre de paramètres est d'environ 9,5 millions
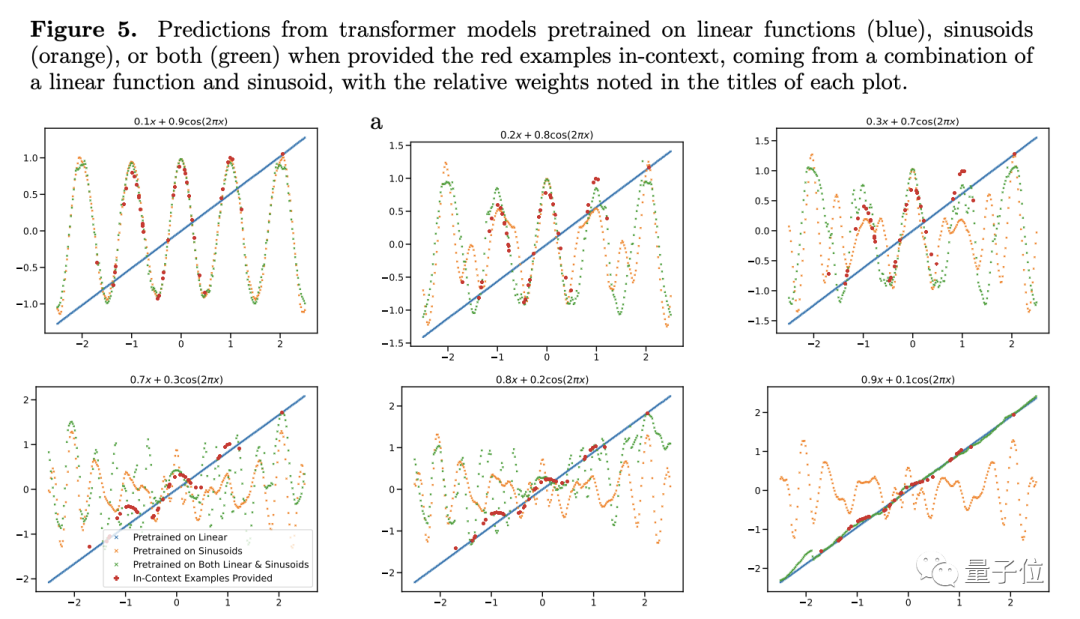
Afin de tester sa capacité de généralisation, l'auteur a choisi les fonctions comme objet de test. Ils entrent la fonction linéaire et la fonction sinusoïdale dans le modèle comme données d'entraînement. Ces deux fonctions sont actuellement connues du modèle, et les résultats de prédiction sont naturellement très bons. Cependant, lorsque les chercheurs ont comparé la fonction linéaire et la fonction sinusoïdale. , Des problèmes surviennent lorsque les convexités sont combinées.
La combinaison de convexité n'est pas si mystérieuse. L'auteur a construit une fonction de la forme f(x)=a·kx+(1-a)sin(x). À notre avis, il s'agit simplement de la simple addition de deux fonctions en proportion. .
Nous pensons cela parce que nos cerveaux sont programmés pour cette capacité de généralisation, mais les modèles à grande échelle sont différents
Pour les modèles qui n'ont appris que les fonctions linéaires et sinusoïdales, une simple addition semble nouvelle
Pour cette nouvelle fonction, les prédictions de Transformer ont presque aucune précision (voir Figure 4c), donc l'auteur estime que le modèle manque de capacité de généralisation sur la fonction
Afin de vérifier davantage sa conclusion, l'auteur a ajusté le poids de la fonction linéaire ou sinusoïdale, mais malgré cela, les performances de prédiction du Transformateur n'ont pas changé de manière significative.
Il n'y a qu'une seule exception : lorsque le poids de l'un des éléments est proche de 1, les résultats de prédiction du modèle sont plus cohérents avec la situation réelle.
Si le poids est de 1, cela signifie que la nouvelle fonction inconnue devient directement la fonction qui a été vue lors de l'entraînement. Ce type de données n'aide évidemment pas la capacité de généralisation du modèle
D'autres expériences montrent également que. Transformateur non seulement Il est très sensible au type de fonction, et même le même type de fonction peut devenir des conditions inconnues.
Les chercheurs ont découvert que lors de la modification de la fréquence d'une fonction sinusoïdale, même dans un modèle de fonction simple, les résultats de prédiction semblent changer
Ce n'est que lorsque la fréquence est proche de la fonction dans les données d'entraînement que le modèle peut donner des prédictions plus précises. , Lorsque la fréquence est trop élevée ou trop basse, il y a de sérieux écarts dans les résultats de prédiction...
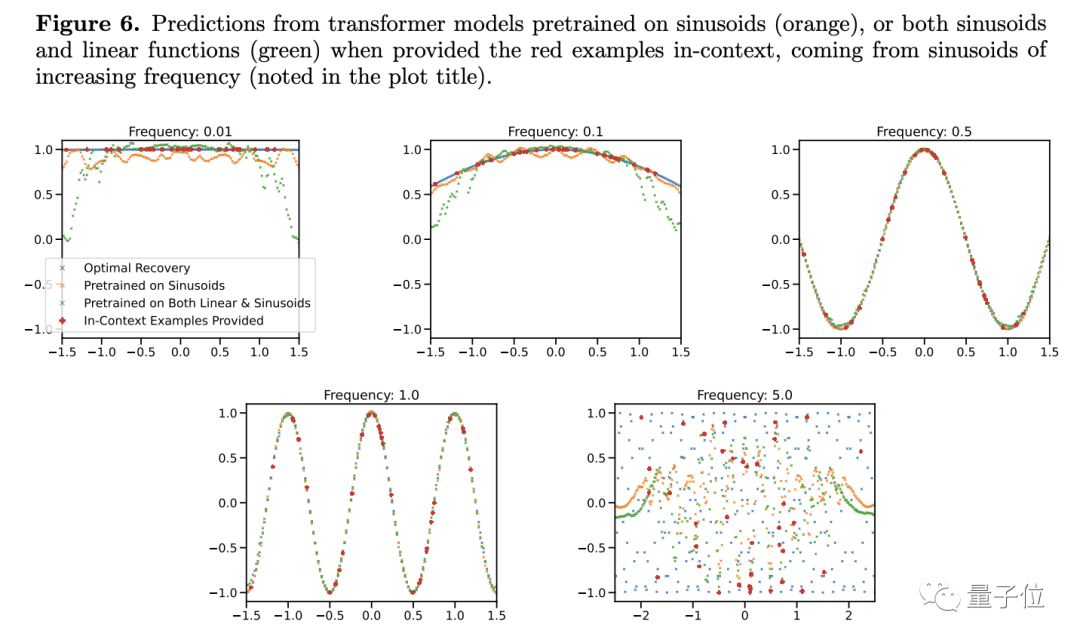
D'après cela, l'auteur estime que tant que les conditions sont légèrement différentes, le grand modèle ne le saura pas que faire. Cela ne signifie-t-il pas que le général Votre capacité chimique est faible ?
L'auteur a également décrit certaines limites de la recherche dans l'article et comment appliquer des observations sur des données fonctionnelles à des problèmes de langage naturel tokenisés.
L'équipe a également tenté des expériences similaires sur des modèles de langage mais a rencontré quelques obstacles. Comment définir correctement les familles de tâches (équivalentes aux types de fonctions ici), les combinaisons convexes, etc.
Cependant, le modèle de Samuel est à petite échelle, avec seulement 4 couches. Il peut être appliqué à la combinaison de fonctions linéaires et sinusoïdales après 5 minutes de formation sur Colab
Et s'il ne peut pas être généralisé
Selon cela. à l'intégralité de l'article À en juger par le contenu complet, la conclusion du PDG de Quora dans cet article est très étroite et ne peut être établie que lorsque de nombreuses hypothèses sont vraies

Le lauréat du prix Sloan et professeur de l'UCLA, Gu Quanquan, a déclaré que la conclusion de l'article lui-même Il n’y a pas de controverse, mais il ne faut pas surinterpréter ce terme.
Selon des recherches antérieures, le modèle Transformer ne peut pas se généraliser uniquement lorsqu'il est confronté à un contenu significativement différent des données de pré-entraînement. En fait, la capacité de généralisation des grands modèles est généralement évaluée par la diversité et la complexité des tâches

Si vous étudiez attentivement la capacité de généralisation de Transformer, j'ai peur que la balle ne vole pendant un certain temps.
Mais, même si vous manquez vraiment de capacité de généralisation, que pouvez-vous faire ?
Jim Fan, scientifique en IA chez NVIDIA, a déclaré que ce phénomène n'est en fait pas surprenant, car Transformern'est pas une panacée en premier lieu Les grands modèles fonctionnent bien parce que les données d'entraînement sont ce qui nous intéresse.

Jim a ajouté : C'est comme dire que vous utilisez 100 milliards de photos de chats et de chiens pour entraîner un modèle visuel, puis demandez au modèle de reconnaître les avions, puis découvrez que, wow, vous ne le faites vraiment pas. les reconnaître.

Lorsque les humains sont confrontés à des tâches inconnues, les modèles à grande échelle ne sont pas les seuls à ne pas être en mesure de trouver des solutions. Cela implique-t-il également que les humains manquent de capacité de généralisation ?

Par conséquent, dans un processus orienté vers un objectif, qu'il s'agisse d'un grand modèle ou d'un humain, le but ultime est de résoudre le problème, et la généralisation n'est qu'un moyen
Changez cette expression en chinois. Puisque la capacité de généralisation est insuffisante, entraînez-la jusqu'à ce qu'il n'y ait plus de données autres que l'échantillon d'entraînement
Alors, que pensez-vous de cette recherche ?
Adresse papier : https://arxiv.org/abs/2311.00871
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelle unité représente la mémoire dans le modèle informatique de von Neumann ?
- Quels sont les trois éléments d'un modèle de données ?
- Quelle est la principale contribution du modèle informatique de la machine de Turing ?
- Quel modèle de données la plupart des systèmes de gestion de bases de données utilisent-ils actuellement ?
- Dans la technologie des bases de données, quels sont les quatre principaux modèles de données ?