
Maison >Périphériques technologiques >IA >Le langage, le démantèlement de robots, le MIT et d'autres utilisent GPT-4 pour générer automatiquement des tâches de simulation et les migrer vers le monde réel
Le langage, le démantèlement de robots, le MIT et d'autres utilisent GPT-4 pour générer automatiquement des tâches de simulation et les migrer vers le monde réel

- PHPzavant
- 2023-10-16 14:21:041696parcourir

Dans le domaine de la robotique, la mise en œuvre de stratégies robotiques universelles nécessite une grande quantité de données, et la collecte de ces données dans le monde réel prend du temps et est laborieuse. Bien que la simulation constitue une solution économique pour générer différents volumes de données au niveau de la scène et de l'instance, la diversité croissante des tâches dans les environnements simulés reste confrontée à des défis en raison de la grande quantité de main d'œuvre requise (en particulier pour les tâches complexes). Il en résulte des références de simulation artificielle typiques ne contenant généralement que des dizaines à des centaines de tâches.
Comment le résoudre ? Ces dernières années, les grands modèles de langage ont continué à faire des progrès significatifs dans le traitement du langage naturel et la génération de code pour diverses tâches. De même, le LLM a été appliqué à plusieurs aspects de la robotique, notamment les interfaces utilisateur, la planification des tâches et des mouvements, le résumé du journal du robot, la conception des coûts et des récompenses, révélant de solides capacités dans les tâches basées sur la physique et dans la génération de code.
Dans une étude récente, des chercheurs du MIT CSAIL, de l'Université Jiao Tong de Shanghai et d'autres institutions ont exploré plus en détail si le LLM pouvait être utilisé pour créer diverses tâches de simulation et explorer davantage leurs capacités.
Plus précisément, les chercheurs ont proposé un cadre GenSim basé sur LLM, qui fournit un mécanisme automatisé pour concevoir et vérifier la disposition des actifs des tâches et la progression des tâches. Plus important encore, les tâches générées présentent une grande diversité, favorisant la généralisation des stratégies robotiques au niveau des tâches. De plus, sur le plan conceptuel, avec GenSim, les capacités de raisonnement et de codage de LLM sont affinées en stratégies verbales-visuelles-action grâce à la synthèse intermédiaire de données simulées.

Adresse papier : https://arxiv.org/pdf/2310.01361.pdf
Le framework GenSim se compose des trois parties suivantes :
- Tâches et mécanismes d'invite pour les correspondances implémentation du code ;
- Deuxièmement, une bibliothèque de tâches qui met en cache les codes d'instructions de haute qualité précédemment générés pour la vérification et le réglage fin du modèle de langage, et les renvoie sous la forme d'un ensemble complet de données de tâches
- Enfin, l'utilisation d'un langage ; pipeline de formation politique multitâche optimisé qui génère des données pour améliorer la généralisation au niveau des tâches.
Le framework fonctionne selon deux modes différents en même temps. Parmi eux, dans le cadre d'un objectif, l'utilisateur a une tâche spécifique ou souhaite concevoir un parcours de tâches. À l’heure actuelle, GenSim adopte une approche descendante, prenant les tâches attendues en entrée et générant de manière itérative des tâches associées pour atteindre les objectifs attendus. Dans un environnement exploratoire, en cas de manque de connaissance préalable de la tâche cible, GenSim explore progressivement le contenu au-delà des tâches existantes et établit une stratégie de base indépendante de la tâche.
Dans la figure 1 ci-dessous, le chercheur a initialisé une bibliothèque de tâches contenant 10 tâches organisées manuellement, a utilisé GenSim pour l'étendre et générer plus de 100 tâches.

Les chercheurs ont également proposé plusieurs métriques personnalisées pour mesurer progressivement la qualité des tâches de simulation générées, et ont évalué plusieurs LLM dans des contextes exploratoires et orientés vers des objectifs. Pour la bibliothèque de tâches générée par GPT-4, ils ont effectué un réglage fin supervisé sur des LLM tels que GPT-3.5 et Code-Llama, améliorant ainsi les performances de génération de tâches de LLM. Dans le même temps, la réalisabilité des tâches est mesurée quantitativement grâce à une formation stratégique, et des statistiques de tâches de différents attributs et des comparaisons de codes entre différents modèles sont fournies.
De plus, les chercheurs ont également formé des stratégies de robots multitâches qui se sont bien généralisées sur toutes les tâches de génération et ont amélioré les performances zéro par rapport aux modèles formés uniquement sur les performances de généralisation humaine. Une formation conjointe avec la tâche de génération GPT-4 peut améliorer les performances de généralisation de 50 % et transférer environ 40 % des tâches zéro-shot vers de nouvelles tâches dans les simulations.
Enfin, les chercheurs ont également envisagé le transfert de la simulation au réel, montrant que la pré-formation sur différentes tâches de simulation peut améliorer de 25 % la capacité de généralisation dans le monde réel.
En résumé, les politiques formées sur les tâches générées par différents LLM parviennent à une meilleure généralisation au niveau des tâches à de nouvelles tâches, soulignant le potentiel d'étendre les tâches simulées via LLM pour former les politiques de base.
Shubham Saboo, directeur de la gestion des produits chez Tenstorrent AI, a fait l'éloge de cette recherche. Il a déclaré qu'il s'agissait d'une recherche révolutionnaire sur GPT-4 combinée à des robots, utilisant un LLM tel que GPT-4 pour générer une série de tâches robotiques simulées. sur pilote automatique, faisant de l'apprentissage sans tir et de l'adaptation des robots au monde réel une réalité.

Introduction à la méthode
Comme le montre la figure 2 ci-dessous, le framework GenSim génère des environnements de simulation, des tâches et des démonstrations via la synthèse de programmes. Le pipeline GenSim démarre à partir du créateur de la tâche et la chaîne d'invites s'exécute en deux modes, le mode orienté vers un objectif et le mode exploratoire, en fonction de la tâche cible. La bibliothèque de tâches de GenSim est un composant en mémoire utilisé pour stocker des tâches de haute qualité générées précédemment. Les tâches stockées dans la bibliothèque de tâches peuvent être utilisées pour la formation aux politiques multitâches ou pour affiner le LLM.

Créateur de tâches
Comme le montre la figure 3 ci-dessous, la chaîne de langage générera d'abord la description de la tâche, puis générera l'implémentation associée. La description de la tâche comprend le nom de la tâche, les ressources et le résumé de la tâche. Cette étude utilise quelques exemples d'invites dans le pipeline pour générer du code.
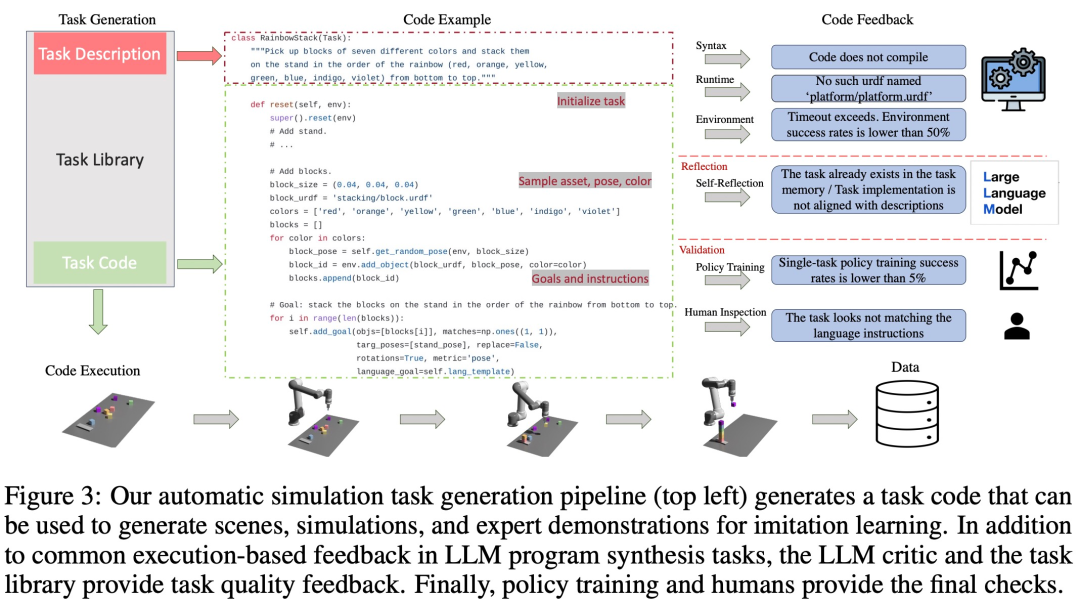
Bibliothèque de tâches
La bibliothèque de tâches du framework GenSim stocke les tâches générées par le créateur de tâches pour générer de meilleures nouvelles tâches et former des stratégies multitâches. La bibliothèque de tâches est initialisée en fonction des tâches issues de benchmarks créés manuellement.
La bibliothèque de tâches fournit au créateur de la tâche la description de la tâche précédente comme condition pour la phase de génération de description, et le code précédent pour la phase de génération de code, et invite le créateur de la tâche à sélectionner la tâche de référence dans la bibliothèque de tâches comme l'exemple de tâche d'écriture d'une nouvelle tâche. Une fois la mise en œuvre de la tâche terminée et tous les tests réussis, LLM est invité à « réfléchir » à la nouvelle tâche et à la bibliothèque de tâches, et à prendre une décision globale quant à savoir si la tâche nouvellement générée doit être ajoutée à la bibliothèque.
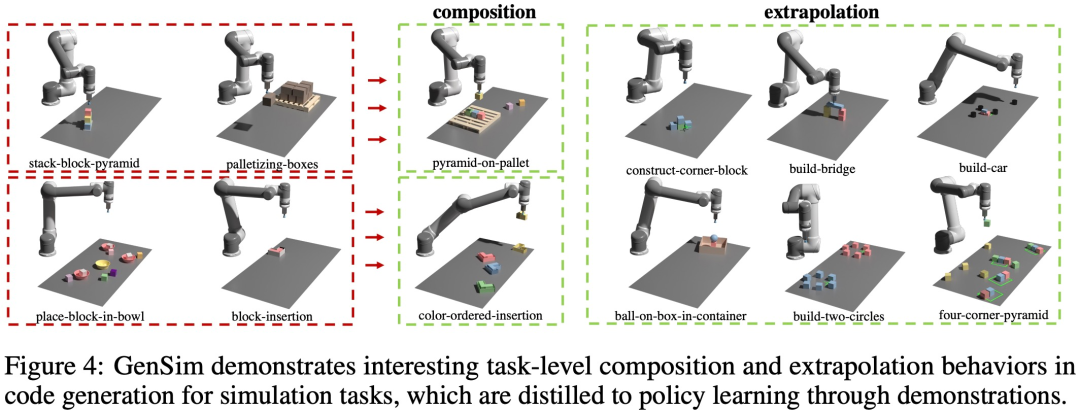
Comme le montre la figure 4 ci-dessous, l'étude a également observé que GenSim présente un comportement intéressant de combinaison et d'extrapolation au niveau des tâches :
Comme le montre la figure 5 ci-dessous, cette étude considère le programme comme une représentation efficace de la tâche et des données de démonstration associées (Figure 5). Il est possible de définir l'espace d'intégration entre les tâches, et son indice de distance est sensible à. divers facteurs liés à la perception (tels que la pose et la forme de l'objet) sont plus robustes.
Expériences et résultats
 Cette étude valide le cadre GenSim par des expériences, ciblant les questions spécifiques suivantes : (1) Quelle est l'efficacité du LLM dans la conception et la mise en œuvre de tâches de simulation ? GenSim peut-il améliorer les performances du LLM dans la génération de tâches ? (2) La formation sur les tâches générées par LLM peut-elle améliorer la capacité de généralisation des politiques ? La formation politique bénéficierait-elle davantage si elle lui confiait davantage de tâches de génération ? (3) La pré-formation sur les tâches de simulation générées par LLM est-elle bénéfique pour le déploiement de politiques robotiques dans le monde réel ?
Cette étude valide le cadre GenSim par des expériences, ciblant les questions spécifiques suivantes : (1) Quelle est l'efficacité du LLM dans la conception et la mise en œuvre de tâches de simulation ? GenSim peut-il améliorer les performances du LLM dans la génération de tâches ? (2) La formation sur les tâches générées par LLM peut-elle améliorer la capacité de généralisation des politiques ? La formation politique bénéficierait-elle davantage si elle lui confiait davantage de tâches de génération ? (3) La pré-formation sur les tâches de simulation générées par LLM est-elle bénéfique pour le déploiement de politiques robotiques dans le monde réel ?
Évaluer la capacité de généralisation des tâches de simulation de robot LLM
Comme le montre la figure 6 ci-dessous, pour la génération de tâches en mode exploration et en mode orienté objectif, la chaîne d'invites en deux étapes de quelques échantillons et d'une bibliothèque de tâches peut améliorer efficacement le taux de réussite de la génération de code.
Généralisation au niveau des tâches
Optimisation de la stratégie en quelques étapes pour les tâches associées. Comme on peut l'observer sur le côté gauche de la figure 7 ci-dessous, la formation conjointe des tâches générées par LLM peut améliorer les performances de la politique sur la tâche CLIPort d'origine de plus de 50 %, en particulier dans les situations de faibles données (telles que 5 démos). Généralisation de la politique Zero-shot aux tâches invisibles. Comme le montre la figure 7, en pré-entraînant sur davantage de tâches générées par LLM, notre modèle peut mieux se généraliser aux tâches du benchmark Ravens d'origine. Au milieu à droite de la figure 7, les chercheurs se sont également pré-entraînés sur 5 tâches sur différentes sources de tâches, y compris des tâches écrites manuellement, des LLM à source fermée et des LLM affinés à source ouverte, et ont observé un niveau de tâche zéro similaire. généralisation. Adapter le modèle pré-entraîné au monde réel Les chercheurs ont transféré les stratégies entraînées dans l'environnement simulé à l'environnement réel. Les résultats sont présentés dans le tableau 1 ci-dessous. Le modèle pré-entraîné sur 70 tâches générées par GPT-4 a mené 10 expériences sur 9 tâches et a atteint un taux de réussite moyen de 68,8 %, ce qui est meilleur que la pré-entraînement sur la tâche CLIPort uniquement. Par rapport au modèle de base, il s'est amélioré de plus de 25 %, et par rapport au modèle pré-entraîné sur seulement 50 tâches, il s'est amélioré de 15 %. Les chercheurs ont également observé que la pré-formation sur différentes tâches de simulation améliorait la robustesse des tâches complexes à long terme. Par exemple, les modèles pré-entraînés GPT-4 affichent des performances plus robustes sur les tâches de construction réelles. Expérience d'ablation Taux de réussite de l'entraînement par simulation. Dans le tableau 2 ci-dessous, les chercheurs démontrent les taux de réussite de la formation politique à tâche unique et multitâche sur un sous-ensemble de tâches générées avec 200 démos. Pour la formation aux politiques sur les tâches de génération GPT-4, son taux de réussite moyen des tâches est de 75,8 % pour les tâches uniques et de 74,1 % pour les tâches multiples. Générer des statistiques de tâches. Dans la figure 9 (a) ci-dessous, le chercheur montre les statistiques de tâches de différentes caractéristiques des 120 tâches générées par LLM. Il existe un équilibre intéressant entre les couleurs, les actifs, les actions et le nombre d'instances générées par le modèle LLM. Par exemple, le code généré contient de nombreuses scènes avec plus de 7 instances d'objet, ainsi que de nombreuses actions primitives de sélection et de placement et des actifs tels que des blocs. Comparaison de génération de code. Dans la figure 9 (b) ci-dessous, les chercheurs évaluent qualitativement les cas d'échec dans les expériences descendantes de GPT-4 et Code Llama. Veuillez vous référer au document original pour plus de détails techniques. 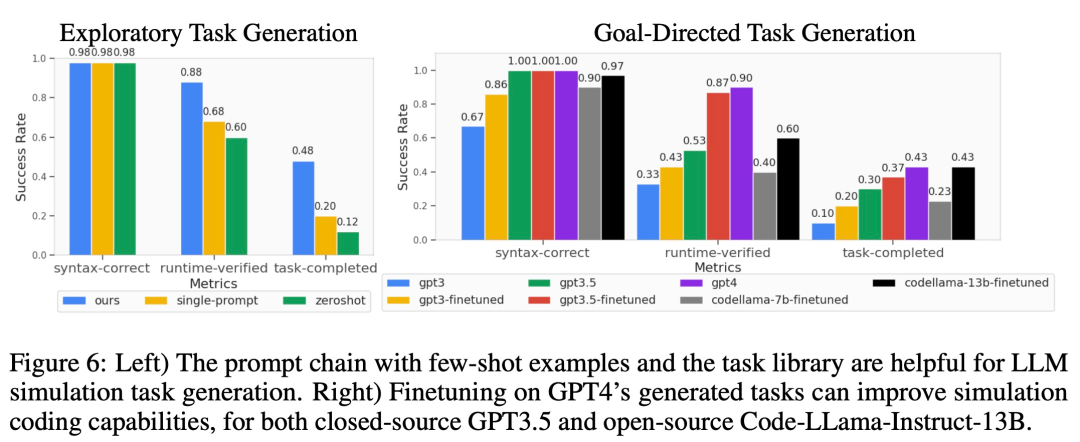





Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment Python traite les données Excel
- Quelles sont les cinq méthodes d'analyse des données spss ?
- Formation personnalisée de modèles d'apprentissage profond à l'aide de techniques d'apprentissage par transfert
- En tête de la liste internationale faisant autorité en matière d'analyse sémantique conversationnelle SParC et CoSQL, le nouveau modèle de pré-formation des connaissances sur les tables de dialogue à plusieurs tours, interprétation STAR
- Premier article : Un nouveau paradigme pour la formation de modèles d'occupation 3D multi-vues en utilisant uniquement des étiquettes 2D