
Maison >Périphériques technologiques >IA >Améliorer l'efficacité de l'ingénierie - génération de recherche améliorée (RAG)
Améliorer l'efficacité de l'ingénierie - génération de recherche améliorée (RAG)

- 王林avant
- 2023-10-14 20:17:011540parcourir
Avec l'avènement de modèles linguistiques à grande échelle tels que GPT-3, des avancées majeures ont été réalisées dans le domaine du traitement du langage naturel (NLP). Ces modèles de langage ont la capacité de générer du texte de type humain et ont été largement utilisés dans divers scénarios tels que les chatbots et la traduction

Cependant, lorsqu'il s'agit de scénarios d'application spécialisés et personnalisés, de grands modèles de langage à usage général peuvent il y a des lacunes dans les connaissances professionnelles. Affiner ces modèles avec des corpus spécialisés est souvent coûteux et prend du temps. « Retrieval Enhanced Generation » (RAG) offre une nouvelle solution technologique pour les applications professionnelles.
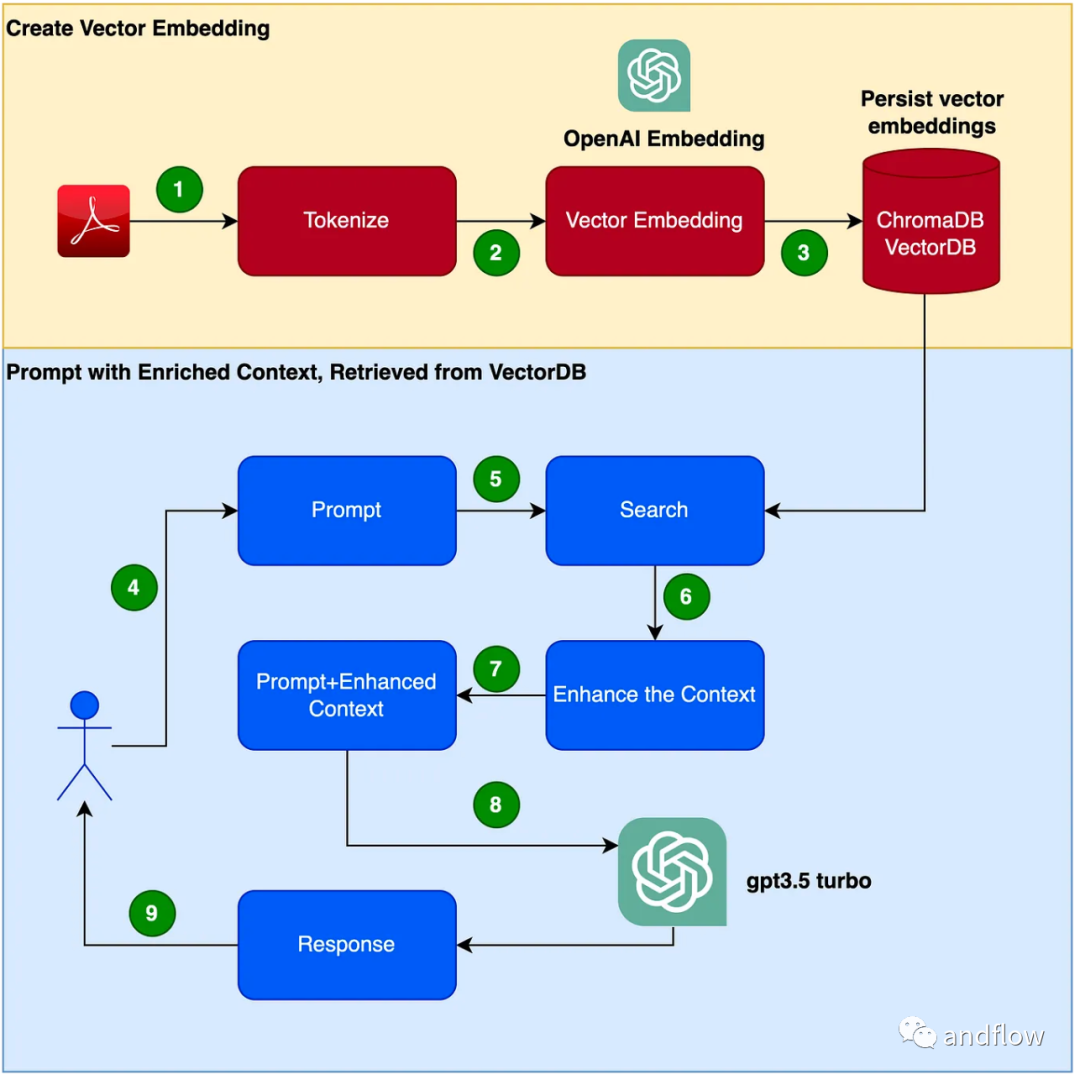
Ci-dessous, nous présentons principalement le fonctionnement de RAG et utilisons un exemple pratique pour utiliser le manuel du produit en tant que corpus professionnel et utiliser GPT-3.5 Turbo comme modèle de questions et réponses pour vérifier son efficacité.
Cas : Développer un chatbot capable de répondre aux questions liées à un produit spécifique. Cette entreprise dispose d'un manuel d'utilisation unique
Introduction à RAG
RAG fournit une solution efficace pour les questions et réponses spécifiques à un domaine. Il convertit principalement les connaissances de l'industrie en vecteurs de stockage et de récupération, combine les résultats de la récupération avec les questions des utilisateurs pour former des informations rapides et enfin utilise de grands modèles pour générer des réponses appropriées. En combinant le mécanisme de récupération et le modèle de langage, la réactivité du modèle est grandement améliorée
Les étapes pour créer un programme de chatbot sont les suivantes :
- Lisez le PDF (fichier PDF du manuel d'utilisation) et tokenisez-le en utilisant chunk_size pour 1000 jetons .
- Créez des vecteurs (vous pouvez utiliser OpenAI EmbeddingsAPI pour créer des vecteurs).
- Stockez les vecteurs dans la bibliothèque de vecteurs locale. Nous utiliserons ChromaDB comme base de données vectorielles (la base de données vectorielles peut également être remplacée par Pinecone ou d'autres produits).
- Les utilisateurs publient des conseils avec des requêtes/questions.
- Récupérez les données de contexte de connaissances de la base de données vectorielles en fonction des questions de l'utilisateur. Ces données contextuelles de connaissances seront utilisées conjointement avec les mots indicateurs dans les étapes suivantes pour améliorer les mots indicateurs, souvent appelé enrichissement contextuel.
- Le mot d'invite contenant la question de l'utilisateur est transmis au LLM avec des connaissances contextuelles améliorées
- Les réponses du LLM basées sur ce contexte.
Développement pratique
(1) Configurer un environnement virtuel Python Configurer un environnement virtuel pour mettre en sandbox notre Python afin d'éviter tout conflit de version ou de dépendance. Exécutez la commande suivante pour créer un nouvel environnement virtuel Python.
需要重写的内容是:pip安装virtualenv,python3 -m venv ./venv,source venv/bin/activate
Le contenu qui doit être réécrit est : (2) Générer une clé OpenAI
L'utilisation de GPT nécessite une clé OpenAI pour l'accès
Le contenu qui doit être réécrit est : (3) Installer les bibliothèques dépendantes
Diverses dépendances requises par l'installateur. Comprend les bibliothèques suivantes :
- lanchain : un framework pour développer des applications LLM.
- chromaDB : Il s'agit de VectorDB pour les intégrations vectorielles persistantes.
- non structuré : utilisé pour prétraiter les documents Word/PDF.
- tiktoken : Framework Tokenizer
- pypdf : Un framework pour lire et traiter des documents PDF.
- openai : accédez au framework OpenAI.
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
Créez une variable d'environnement pour stocker la clé OpenAI.
export OPENAI_API_KEY=<openai-key></openai-key>
(4) Convertissez le fichier PDF du manuel d'utilisation en vecteur et stockez-le dans ChromaDB
Importez toutes les bibliothèques et fonctions dépendantes dont vous avez besoin pour utiliser
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
pour lire le PDF, tokeniser le document et diviser le document .
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)
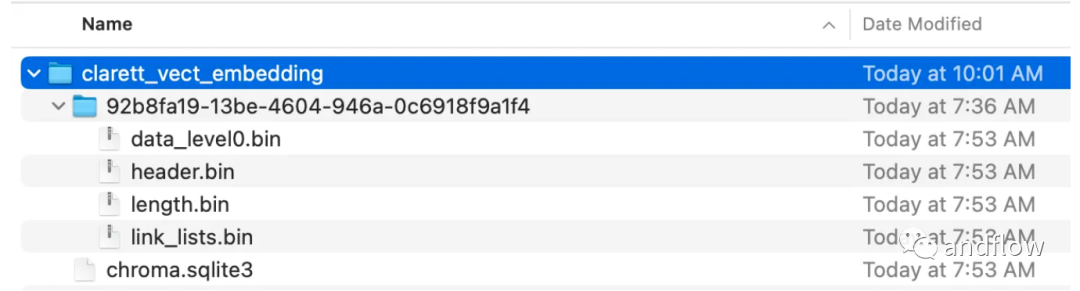
Créez une collection de chrominance et un répertoire local pour stocker les données de chrominance. Ensuite, créez un vecteur (embeddings) et stockez-le dans ChromaDB.
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData,embeddings,collection_name=collection_name,persist_directory=persist_directory)vectDB.persist()
Après avoir exécuté ce code, vous devriez voir un dossier qui a été créé pour stocker les vecteurs.
Une fois l'intégration vectorielle stockée dans ChromaDB, vous pouvez utiliser l'API ConversationalRetrievalChain dans LangChain pour démarrer un composant d'historique de discussion
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm(OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
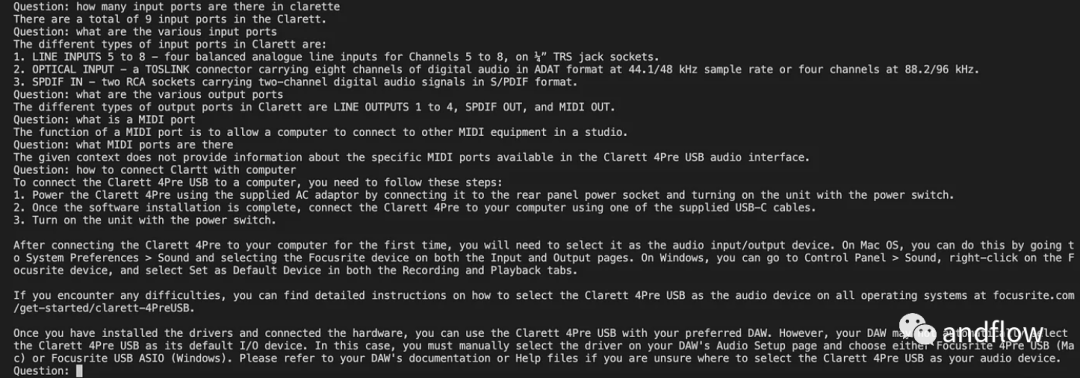
Après avoir initialisé Langchan, nous pouvons l'utiliser pour discuter/Q A. Dans le code ci-dessous, une question saisie par l'utilisateur est acceptée, et une fois que l'utilisateur a saisi « terminé », la question est transmise à LLM pour obtenir la réponse et l'imprimer.
chat_history = []qry = ""while qry != 'done':qry = input('Question: ')if qry != exit:response = chatQA({"question": qry, "chat_history": chat_history})print(response["answer"])

En bref
RAG combine les avantages des modèles linguistiques tels que GPT avec les avantages de la recherche d'informations. En utilisant des informations spécifiques sur le contexte des connaissances pour améliorer la richesse des mots d'invite, le modèle de langage est capable de générer des réponses plus précises et liées au contexte des connaissances. RAG fournit une solution plus efficace et plus rentable que le « réglage fin », fournissant des solutions interactives personnalisables pour les applications industrielles ou les applications d'entreprise
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- événement glisser-glisser html
- À propos de la différence entre HTML5 localStorage et sessionStorage
- Comment obtenir la valeur de SessionStorage en utilisant JS
- Qu'est-ce qu'un fragment en réaction ?
- Meta publie le premier modèle de langage de masque « non paramétrique » NPM : battant GPT-3 avec 500 fois plus de paramètres