
Maison >Périphériques technologiques >IA >GPT-4 a amélioré sa précision de 13,7 % grâce à la formation DeepMind, obtenant ainsi de meilleures capacités d'induction et de déduction.
GPT-4 a amélioré sa précision de 13,7 % grâce à la formation DeepMind, obtenant ainsi de meilleures capacités d'induction et de déduction.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-14 20:13:03922parcourir
Actuellement, les grands modèles linguistiques (LLM) démontrent des capacités étonnantes sur les tâches d'inférence, en particulier lorsque des exemples et des étapes intermédiaires sont fournis. Cependant, les méthodes rapides reposent généralement sur des connaissances implicites dans le LLM, et lorsque les connaissances implicites sont fausses ou incompatibles avec la tâche, le LLM peut donner de mauvaises réponses

Maintenant, de Google, de l'Institut Mila, etc. Chercheurs de la recherche Les institutions ont exploré conjointement une nouvelle méthode - permettant au LLM d'apprendre les règles d'inférence et ont proposé un nouveau cadre appelé Hypothèses en Théories (HtT). Cette nouvelle méthode améliore non seulement le raisonnement en plusieurs étapes, mais présente également les avantages de l'interprétabilité et de la transférabilité

Adresse papier : https://arxiv.org/abs/2310.07064
selon Experimental les résultats sur les problèmes de raisonnement numérique et de raisonnement relationnel montrent que la méthode HtT améliore la méthode d'incitation existante et augmente la précision de 11 à 27 %. Dans le même temps, les règles apprises peuvent également être transférées à différents modèles ou différentes formes du même problème
Introduction à la méthode
En général, le cadre HtT contient deux étapes - l'étape inductive et l'étape déductive Étape similaire à la formation et aux tests dans l’apprentissage automatique traditionnel.
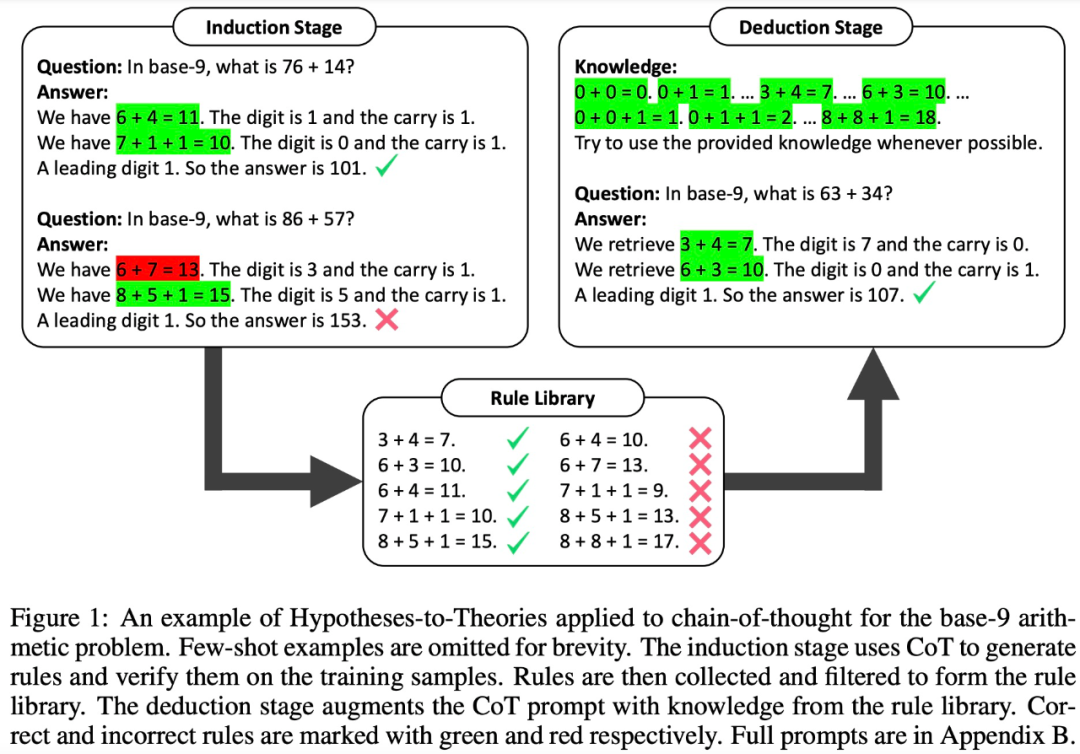
Dans la phase d'intégration, LLM doit d'abord générer et vérifier un ensemble de règles pour des exemples de formation. Cette étude utilise CoT pour déclarer des règles et en dériver des réponses, évaluer la fréquence et l'exactitude des règles, collecter les règles qui apparaissent fréquemment et conduire à des réponses correctes, et former une base de règles
Avec une bonne base de règles, la prochaine étape consiste à déterminer comment pour appliquer cette recherche Ces règles résolvent le problème. À cette fin, dans la phase de déduction, cette étude ajoute une base de règles dans l'invite et demande à LLM de récupérer les règles de la base de règles pour effectuer la déduction, convertissant le raisonnement implicite en raisonnement explicite.
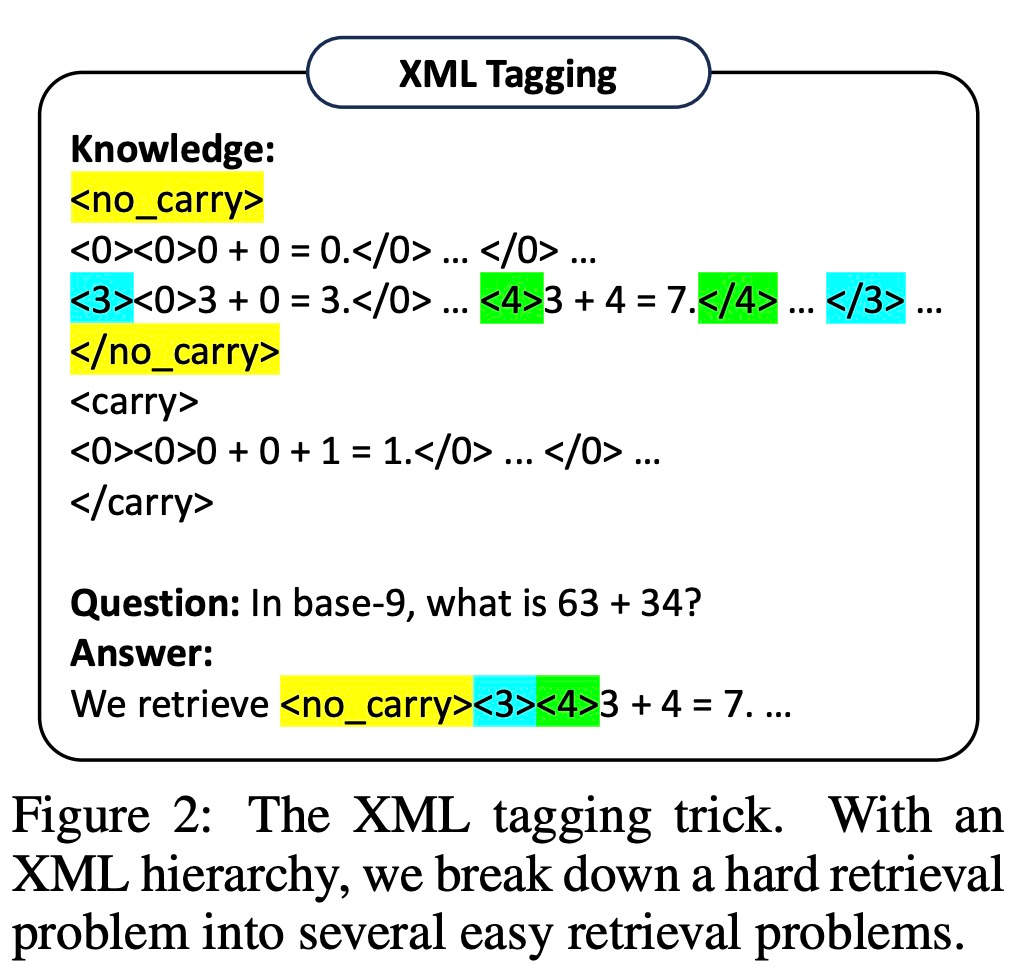
Cependant, des études ont montré que même les LLM très puissants (tels que GPT-4) ont du mal à récupérer les bonnes règles à chaque étape. Par conséquent, cette étude développe des techniques de balisage XML pour améliorer les capacités de récupération de contexte de LLM
Résultats expérimentaux
Pour évaluer HtT, cette étude a effectué des benchmarks sur deux problèmes de raisonnement en plusieurs étapes. Les résultats expérimentaux montrent que HtT améliore la méthode d'invite à quelques échantillons. Les auteurs ont également réalisé des études approfondies sur l’ablation pour fournir une compréhension plus complète du HtT.
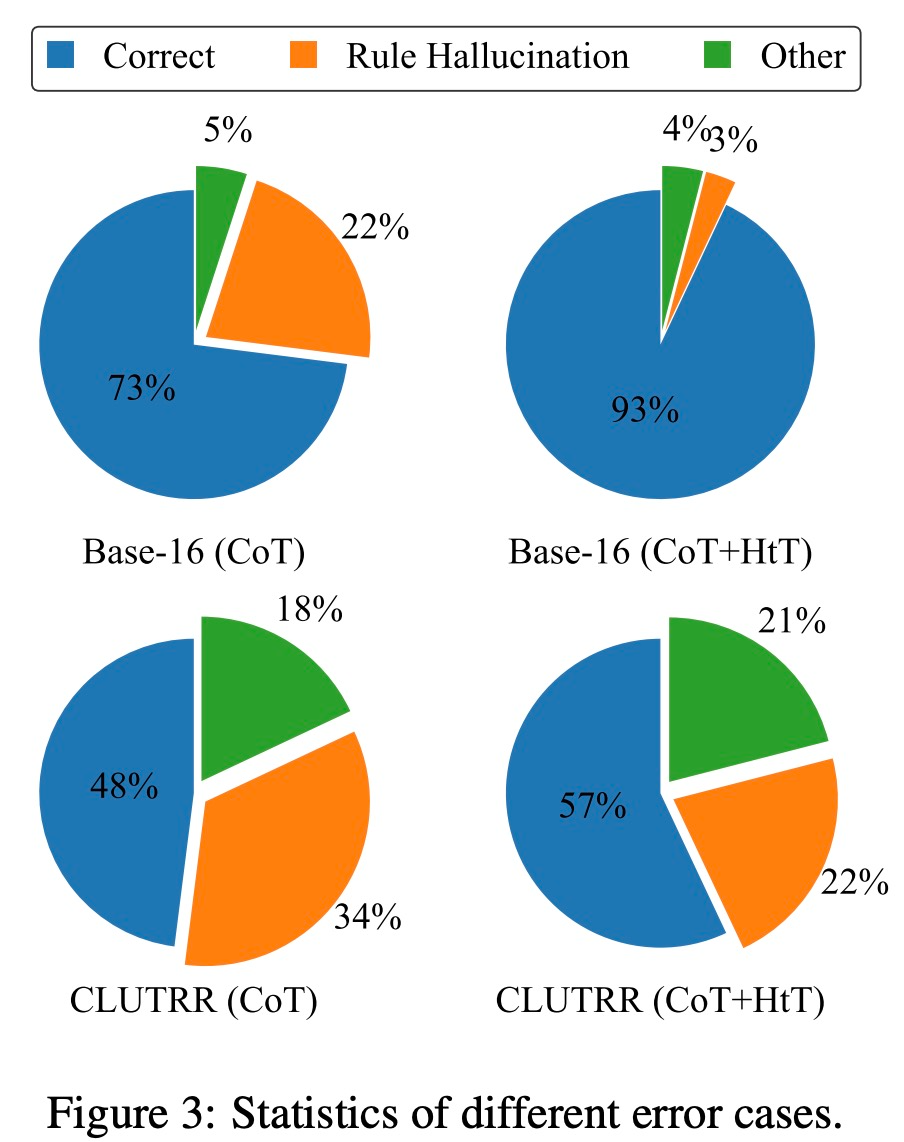
Ils évaluent de nouvelles méthodes sur des problèmes de raisonnement numérique et de raisonnement relationnel. En inférence numérique, ils ont observé une amélioration de 21,0 % de la précision du GPT-4. En raisonnement relationnel, GPT-4 a obtenu une amélioration de la précision de 13,7 %, et GPT-3.5 en a bénéficié encore plus, doublant les performances. Le gain de performance vient principalement de la réduction de l’illusion des règles.
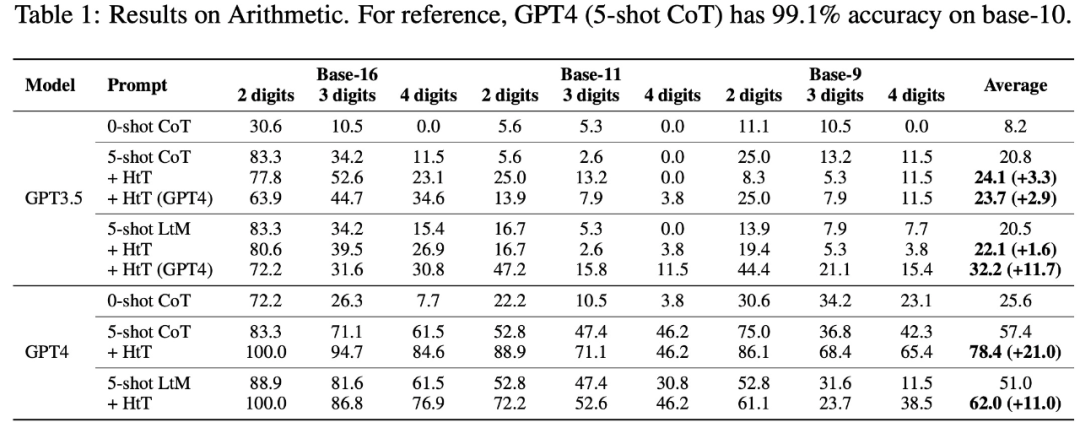
Plus précisément, le tableau 1 ci-dessous montre les résultats sur les ensembles de données arithmétiques en base 16, base 11 et base 9. Parmi tous les systèmes de base, le CoT 0-shot présente les pires performances dans les deux LLM.
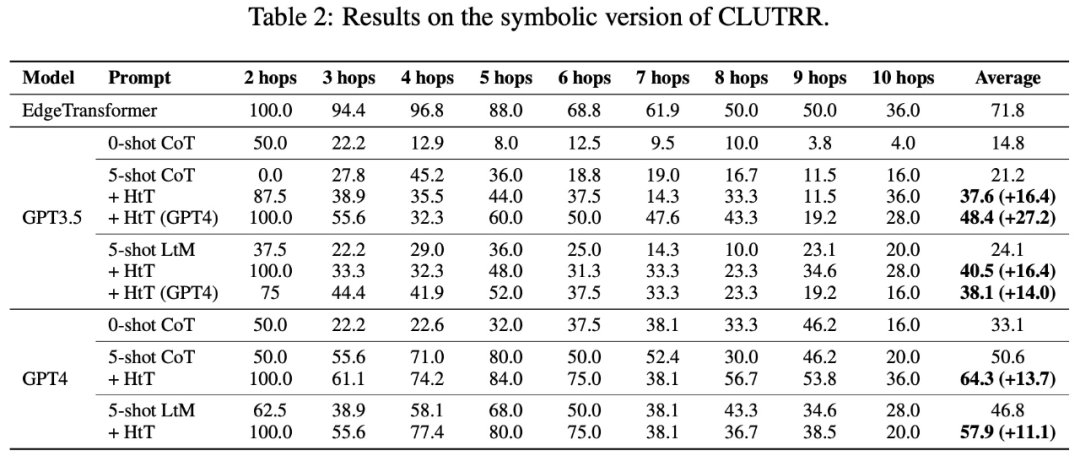
Le tableau 2 présente les résultats comparant différentes méthodes sur CLUTRR. On peut observer que le CoT 0-shot a les pires performances en GPT3.5 et GPT4. Pour la méthode d'invite en quelques tirs, CoT et LtM fonctionnent de la même manière. En termes de précision moyenne, HtT surpasse systématiquement les méthodes d'indication pour les deux modèles de 11,1 à 27,2 %. Il convient de noter que GPT3.5 n'est pas mauvais pour récupérer les règles CLUTRR et bénéficie davantage de HtT que GPT4, probablement parce qu'il y a moins de règles en CLUTRR qu'en arithmétique.
Il convient de mentionner qu'en utilisant les règles de GPT4, les performances CoT sur GPT3.5 sont améliorées de 27,2%, soit plus de deux fois les performances CoT et proches des performances CoT sur GPT4. Par conséquent, les auteurs pensent que HtT peut servir de nouvelle forme de distillation des connaissances d’un LLM fort à un LLM faible.
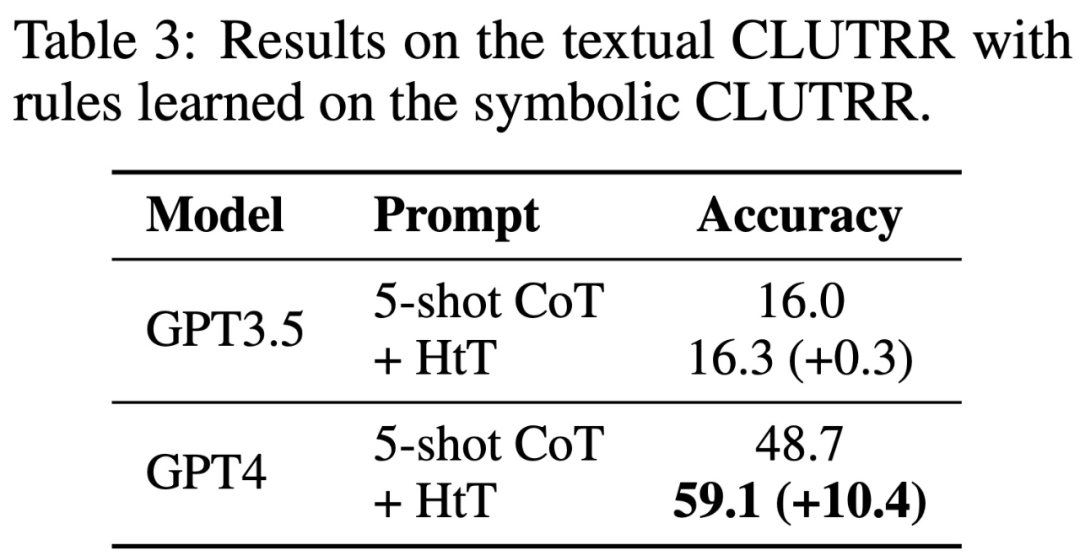
Le tableau 3 montre que HtT améliore considérablement les performances de GPT-4 (version texte). Cette amélioration n'est pas significative pour GPT3.5, car elle produit souvent des erreurs autres que l'illusion de règles lors du traitement de la saisie de texte.
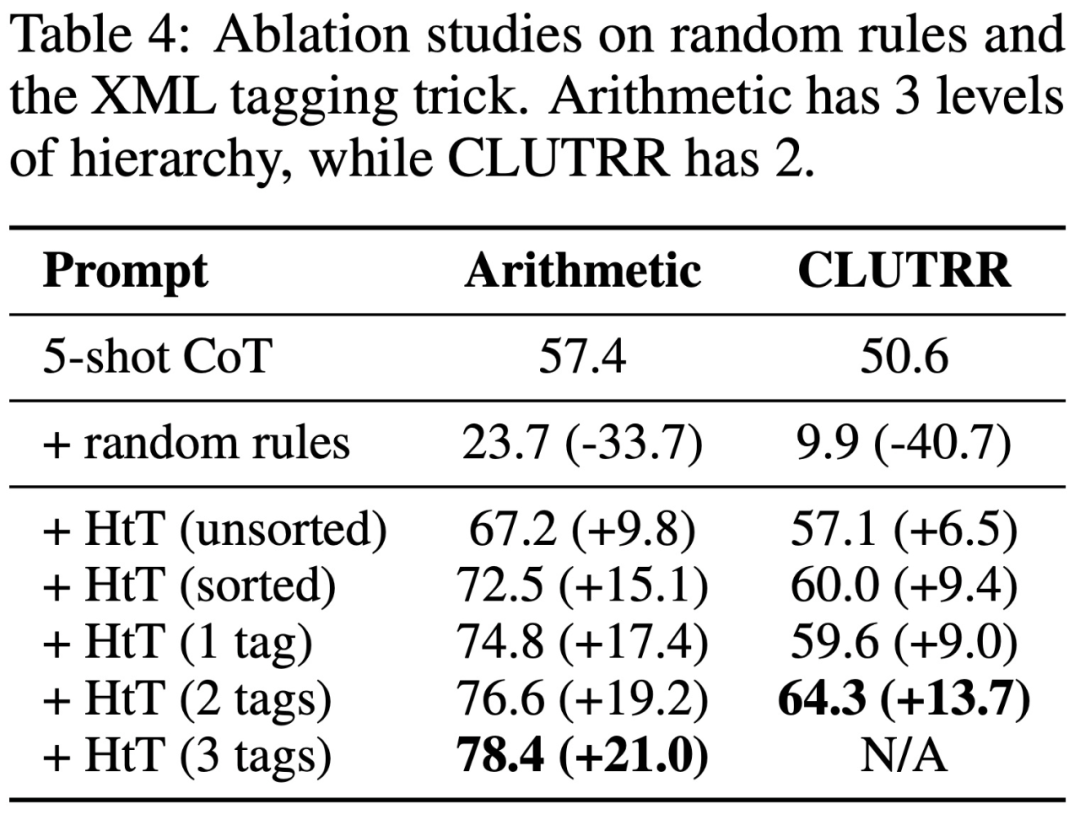
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une introduction à quatre méthodes pour implémenter des fonctions d'apprentissage automatique en Python
- Notions de base de Tensorflow (bibliothèque de logiciels open source d'apprentissage automatique)
- Comment l'intelligence artificielle et l'apprentissage automatique auront un impact sur l'avenir des soins de santé
- Kaifu Lee : Les grands modèles d'IA sont une opportunité historique à ne pas manquer
- Vulgarisation scientifique : Qu'est-ce qu'un grand modèle d'IA ?