
Maison >Périphériques technologiques >IA >MotionLM : technologie de modélisation de langage pour la prédiction de mouvement multi-agents
MotionLM : technologie de modélisation de langage pour la prédiction de mouvement multi-agents

- WBOYavant
- 2023-10-13 12:09:051415parcourir
Cet article est réimprimé avec l'autorisation du compte public Autonomous Driving Heart. Veuillez contacter la source pour la réimpression.
Titre original : MotionLM : Multi-Agent Motion Forecasting as Language Modeling
Lien papier : https://arxiv.org/pdf/2309.16534.pdf
Unité auteur : Waymo
Conférence : ICCV 2023

Idée de thèse :
Pour la planification de la sécurité des véhicules autonomes, il est crucial de prédire de manière fiable le comportement futur des agents routiers. Cette étude représente les trajectoires continues sous forme de séquences de jetons de mouvement discrets et traite la prédiction de mouvement multi-agents comme une tâche de modélisation du langage. Notre modèle proposé, MotionLM, présente plusieurs avantages : Premièrement, il ne nécessite pas l'utilisation de points d'ancrage ou de variables latentes explicites pour apprendre de manière optimale les distributions multimodales. Au lieu de cela, nous exploitons l'objectif de modélisation du langage standard consistant à maximiser la probabilité log moyenne des jetons de séquence. Deuxièmement, notre approche évite les heuristiques d’interaction post-hoc, où la génération de trajectoires d’agents individuels se produit après la notation des interactions. En revanche, MotionLM génère une distribution conjointe de futurs d'agents interactifs dans un seul processus de décodage autorégressif. De plus, la décomposition séquentielle du modèle permet d’inférer des conditions causales temporelles. La méthode que nous proposons atteint de nouvelles performances de pointe sur l'ensemble de données Waymo Open Motion, se classant au premier rang du classement des défis interactifs
Contributions principales :
Dans cet article, nous présentons la prédiction de mouvement multi-agents comme un langage la tâche de modélisation est discutée. Nous introduisons un décodeur causal temporel pour décoder les jetons de mouvement discrets entraînés avec une perte de modélisation de langage causal
Cet article combinera l'échantillonnage dans le modèle avec un schéma d'agrégation de déploiement simple pour améliorer les capacités de reconnaissance de formes pondérées des trajectoires articulaires. Grâce à des expériences dans le cadre du défi de prédiction d'interaction Waymo Open Motion Dataset, nous démontrons que cette nouvelle méthode améliore la métrique conjointe de classement mAP de 6 % et atteint le niveau de performance de pointe
Cet article procède à un examen approfondi de notre méthode. expérimente l’ablation et analyse ses prédictions conditionnelles causales temporelles, qui ne sont en grande partie pas prises en charge par les modèles de prédiction conjoints actuels.
Conception de réseau :
L'objectif de cet article est de modéliser la distribution sur les interactions multi-agents d'une manière générale qui peut être appliquée à différentes tâches en aval, y compris la prédiction minimale, conjointe et conditionnelle. Pour atteindre cet objectif, un cadre génératif expressif est nécessaire, capable de capturer les multiples morphologies dans les scénarios de conduite. De plus, nous envisageons ici d'économiser les dépendances temporelles ; c'est-à-dire que dans notre modèle, l'inférence suit un graphe acyclique orienté, le nœud parent de chaque nœud étant plus tôt dans le temps et son nœud enfant plus tard dans le temps, ce qui rend la prédiction conditionnelle plus proche de la causalité. intervention parce qu’elle élimine certaines corrélations parasites qui autrement conduiraient à la désobéissance à la causalité temporelle. Cet article observe que les modèles conjoints qui ne préservent pas les dépendances temporelles peuvent avoir une capacité limitée à prédire les réponses réelles des agents, une utilisation clé en planification. À cette fin, cet article utilise une décomposition autorégressive du futur décodeur, où les jetons de mouvement de l'agent dépendent conditionnellement de tous les jetons précédemment échantillonnés, et les trajectoires sont dérivées séquentiellement
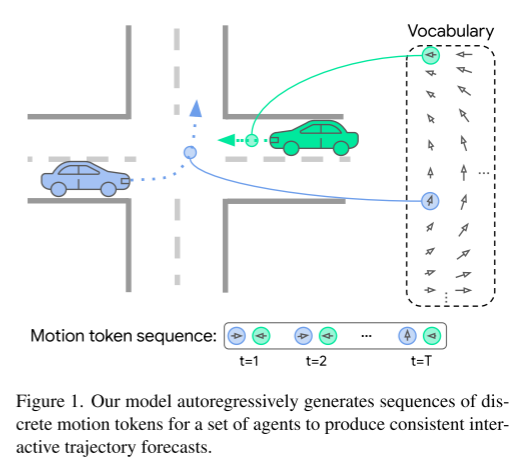
Figure 1. Notre modèle génère de manière autorégressive des séquences de jetons de mouvement discrets pour un ensemble d'agents afin de produire des prédictions de trajectoire interactives cohérentes.
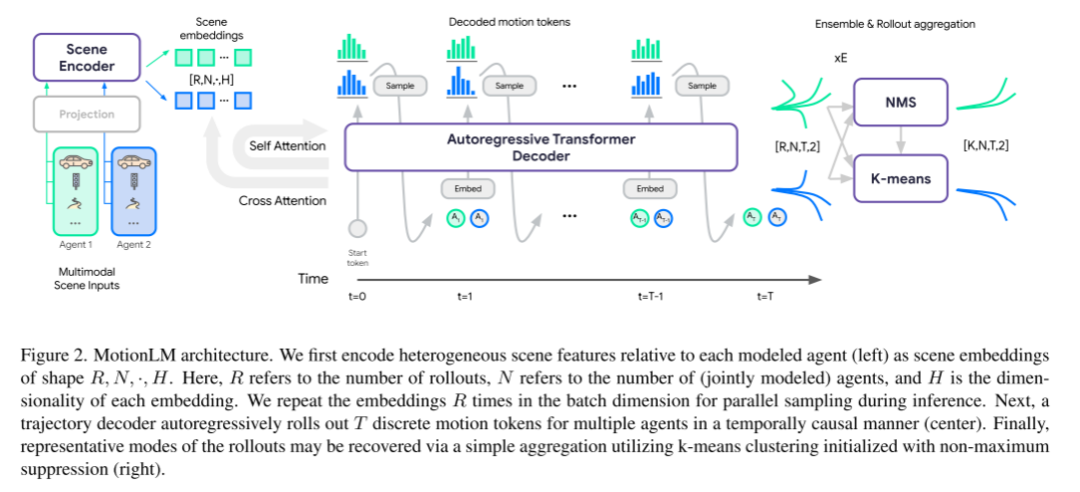
Veuillez consulter la figure 2, qui est l'architecture de MotionLM
Cet article code d'abord les caractéristiques de scène hétérogènes (à gauche) associées à chaque agent de modélisation dans des intégrations de scène de forme R, N, ·, H. Parmi eux, R est le nombre de déploiements, N est le nombre d'agents modélisés conjointement et H est la dimensionnalité de chaque intégration. Au cours du processus d'inférence, afin de paralléliser l'échantillonnage, cet article répète l'intégration R fois dans la dimension du lot. Ensuite, un décodeur de trajectoire déploie T jetons de mouvement discrets pour plusieurs agents de manière temporellement causale (centre). Enfin, le modèle typique de déploiements peut être récupéré par une simple agrégation de clusters à k moyennes en utilisant une initialisation de suppression non maximale (panneau de droite).
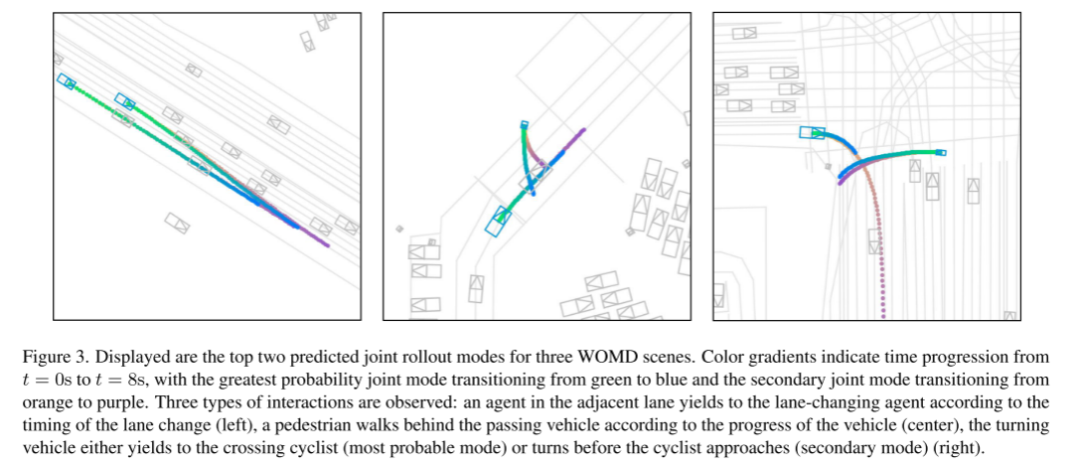
Photo 3. Les deux premiers modes de déploiement conjoint de prédiction pour trois scénarios WOMD sont présentés.
Le dégradé de couleurs représente le changement de temps de t = 0 seconde à t = 8 secondes. Le mode commun passe du vert au bleu et le mode sous-joint passe de l'orange au violet avec la probabilité la plus élevée. Nous avons observé trois types d'interactions : les agents des voies adjacentes céderont le passage à l'agent changeant de voie en fonction du temps de changement de voie (à gauche), les piétons marcheront derrière les véhicules qui passent en fonction de la progression du véhicule (au milieu), et les véhicules qui tournent soit Cèdera le passage à un cycliste qui passe (mode le plus probable), soit tournera avant qu'un cycliste ne s'approche (mode mineur) (côté droit)
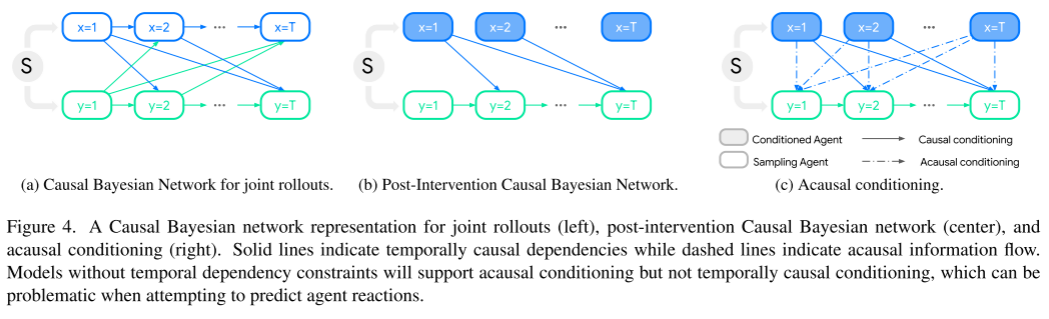
Veuillez consulter la figure 4. Cette figure montre la représentation du réseau bayésien causal de l'induction conjointe (à gauche), du réseau bayésien causal post-intervention (au milieu) et du conditionnement causal (à droite).
Les lignes pleines représentent les corrélations causales dans le temps, tandis que les lignes pointillées représentent le flux d'informations causales. Un modèle sans contraintes temporelles prendra en charge le conditionnement causal mais pas le conditionnement causal temporel, ce qui peut s'avérer problématique lorsqu'on tente de prédire les réponses des agents.
Résultats expérimentaux :
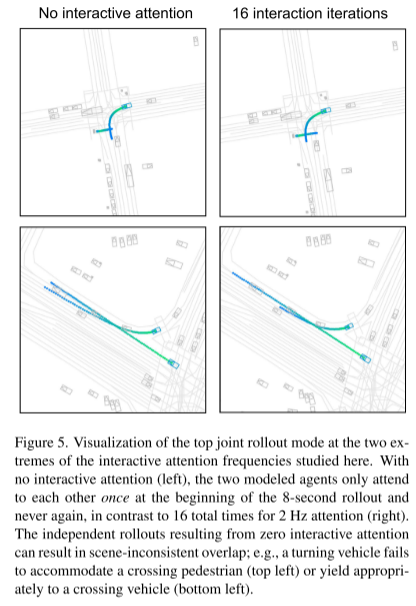
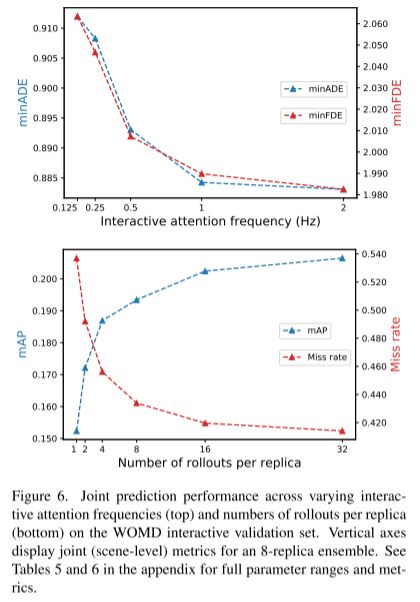
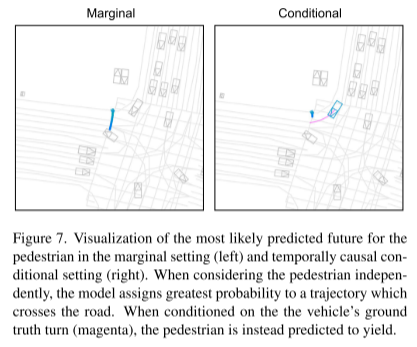
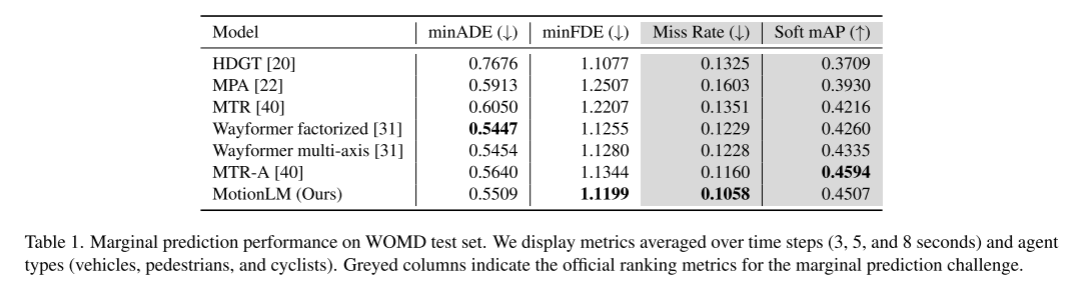
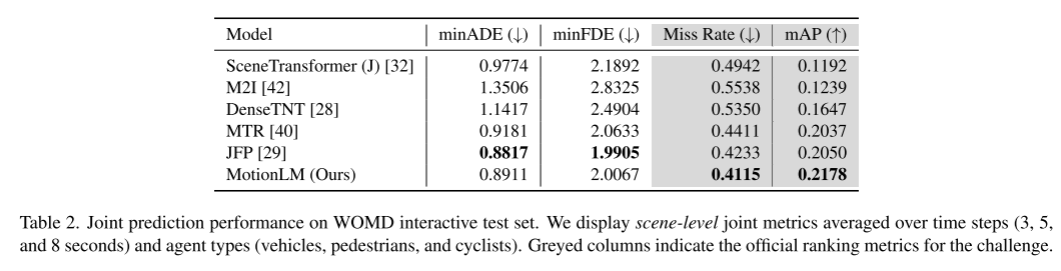
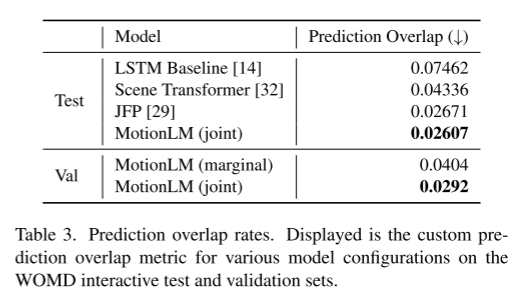

Citation :
Seff, A., Cera, B., Chen, D. , Ng, M., Zhou, A., Nayakanti, N., Refaat, KS et Sapp, B. (2023). MotionLM : Prévision de mouvement multi-agents comme modélisation du langage. /abs/2309.16534
.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Le but de l'intelligence artificielle est de rendre les machines capables de
- Quels sont les quatre éléments d'un système d'intelligence artificielle ?
- Comment visualiser l'intelligence artificielle
- Quelles sont les caractéristiques du modèle de données ?
- Smart App Control sur Windows 11 : comment l'activer ou le désactiver