
Maison >Périphériques technologiques >IA >Le travail innovant de l'équipe de Chen Danqi : Obtention de SOTA à 5% de coût, déclenchant un engouement pour la « tonte d'alpaga »
Le travail innovant de l'équipe de Chen Danqi : Obtention de SOTA à 5% de coût, déclenchant un engouement pour la « tonte d'alpaga »

- 王林avant
- 2023-10-12 14:29:04805parcourir
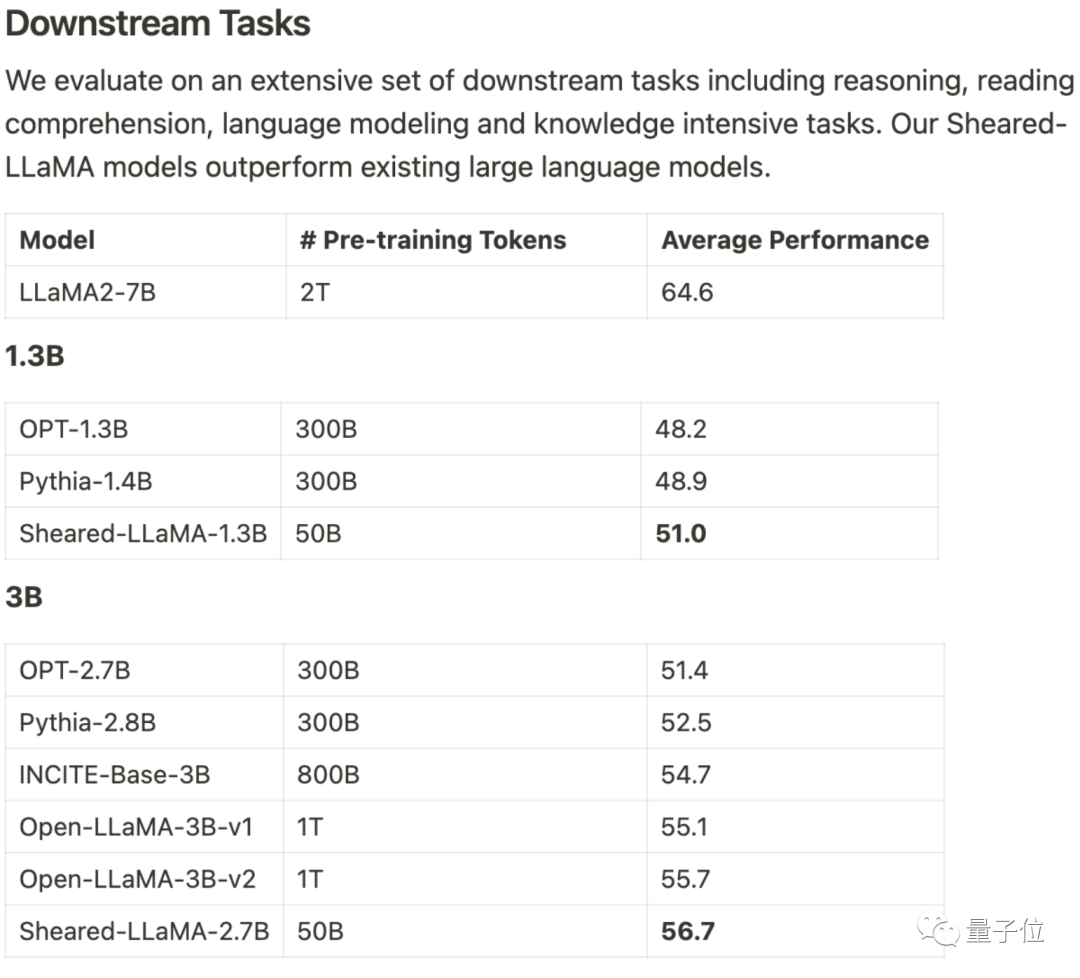
Il n'utilise que 3% du montant du calcul et 5% du coût pour obtenir SOTA, dominant les grands modèles open source à l'échelle 1B-3B.
Ce résultat vient de l'équipe de Princeton Chen Danqi, et s'appelle LLM-ShearingMéthode d'élagage grand modèle.

Basés sur Alpaca LLaMA 2 7B, les modèles Sheared-LLama taillés 1,3B et 3B sont obtenus grâce à une taille structurée directionnelle.

Pour surpasser le modèle précédent de la même échelle dans l'évaluation des tâches en aval, il doit être réécrit
Xia Mengzhou, le premier auteur, a déclaré : « C'est beaucoup plus rentable que la pré-formation à partir de zéro."

L'article donne également un exemple de sortie élaguée de Sheared-LLaMA, indiquant que malgré la taille de seulement 1,3B et 2,7B, elle peut déjà générer des réponses cohérentes et riches.
Pour la même tâche de « jouer le rôle d'un analyste de l'industrie des semi-conducteurs », la structure de réponse de la version 2.7B est encore plus claire.

L'équipe a déclaré que bien qu'actuellement seule la version Llama 2 7B ait été utilisée pour les expériences d'élagage, la méthode peut être étendue à d'autres architectures de modèles et peut également être étendue à n'importe quelle échelle .
Un avantage supplémentaire après l'élagage est que vous pouvez choisir des ensembles de données de haute qualité pour un pré-entraînement continu

Certains développeurs ont déclaré qu'il y a à peine 6 mois, presque tout le monde pensait que les modèles inférieurs à 65B n'avaient aucune utilisation pratique
À ce rythme, je parie que les modèles 1B-3B seront également d’une grande valeur, sinon maintenant, du moins bientôt.

Traitez l'élagage comme une optimisation contrainte
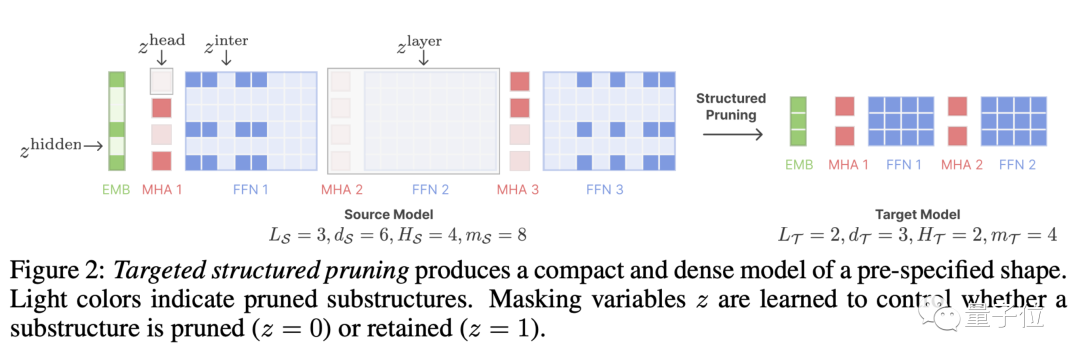
LLM-Shearing, plus précisément une sorte de élagage structuré directionnel, qui taille un grand modèle selon une structure cible spécifiée.
Les méthodes d'élagage précédentes peuvent entraîner une dégradation des performances du modèle car certaines structures seront supprimées, affectant sa capacité d'expression
Nous proposons une nouvelle méthode en traitant l'élagage comme un problème d'optimisation contraint. Nous recherchons des sous-réseaux qui correspondent à la structure spécifiée en apprenant la matrice du masque d'élagage et visons à maximiser les performances
Ensuite, nous continuons à pré-entraîner le modèle élagué et à restaurer dans une certaine mesure la perte de performances causée par l'élagage.
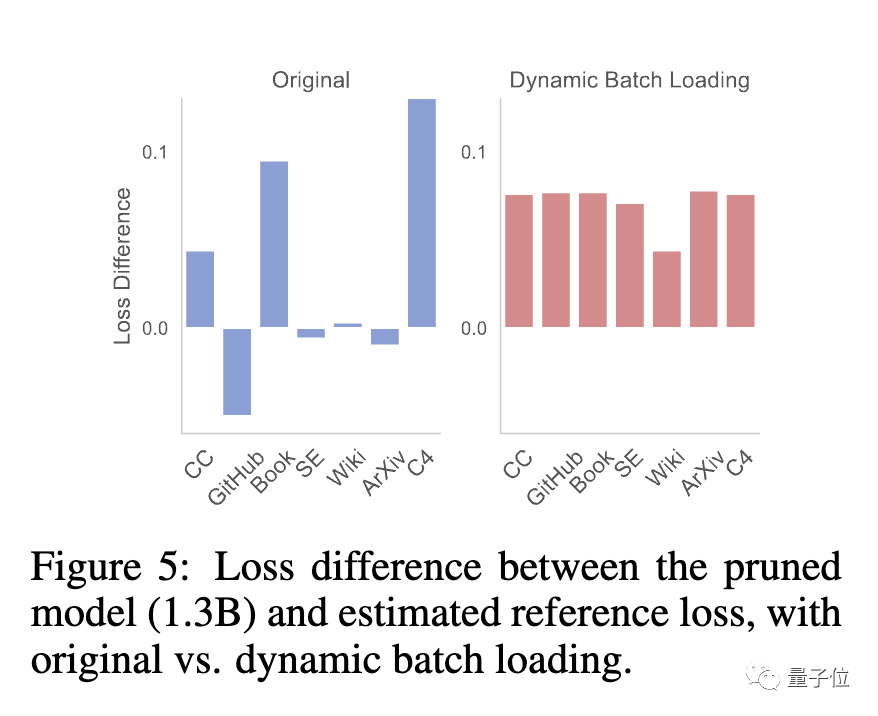
À ce stade, l'équipe a constaté que le modèle élagué et le modèle formé à partir de zéro présentaient des taux de réduction des pertes différents pour différents ensembles de données, ce qui entraînait le problème d'une faible efficacité d'utilisation des données.
À cette fin, l'équipe a proposé Dynamic Batch Loading (Dynamic Batch Loading), qui ajuste dynamiquement la proportion de données dans chaque domaine en fonction du taux de réduction des pertes du modèle sur différentes données de domaine, améliorant ainsi l'efficacité de l'utilisation des données.
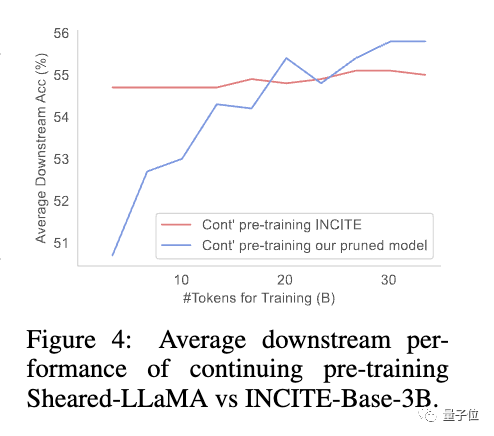
L'étude a révélé que même si les modèles élagués ont des performances initiales médiocres par rapport aux modèles de taille équivalente formés à partir de zéro, ils peuvent rapidement s'améliorer avec un pré-entraînement continu et éventuellement surpasser
Cela montre que l'élagage à partir d'une base solide des branches du modèle , ce qui peut offrir de meilleures conditions d’initialisation pour poursuivre la pré-formation.
continuera à être mis à jour, venez couper un par un
Les auteurs de l'article sont des doctorants de Princeton Xia Mengzhou, Gao Tianyu, Tsinghua Zhiyuan Zeng, Princeton professeur adjoint Chen Dan琦 .
Xia Mengzhou est diplômée de l'Université de Fudan avec un baccalauréat et de la CMU avec une maîtrise.
Gao Tianyu est un étudiant de premier cycle diplômé de l'Université Tsinghua. Il a remporté le prix spécial Tsinghua en 2019
Tous deux sont étudiants de Chen Danqi, et Chen Danqi est actuellement professeur adjoint à l'Université de Princeton et membre du Princeton Natural. Language Processing Group La co-responsable de
Récemment, sur sa page d'accueil personnelle, Chen Danqi a mis à jour son orientation de recherche.
"Cette période est principalement axée sur le développement de modèles à grande échelle, et les sujets de recherche incluent : "
- Comment la récupération peut jouer un rôle important dans les modèles de nouvelle génération, en améliorant le réalisme, l'adaptabilité, l'interprétabilité et la crédibilité.
- Formation et déploiement à faible coût de grands modèles, méthodes de formation améliorées, gestion des données, compression des modèles et optimisation de l'adaptation des tâches en aval.
- Également intéressé par les travaux qui améliorent véritablement la compréhension des capacités et des limites des grands modèles actuels, tant sur le plan empirique que théorique.

Sheared-Llama est déjà disponible sur Hugging Face
L'équipe a déclaré qu'elle continuerait à mettre à jour la bibliothèque open source
Lorsque de plus grands modèles seront publiés, coupez-les un par un et continuez à sortir des petits modèles performants.

One More Thing
Je dois dire que les grands modèles sont vraiment trop bouclés maintenant.
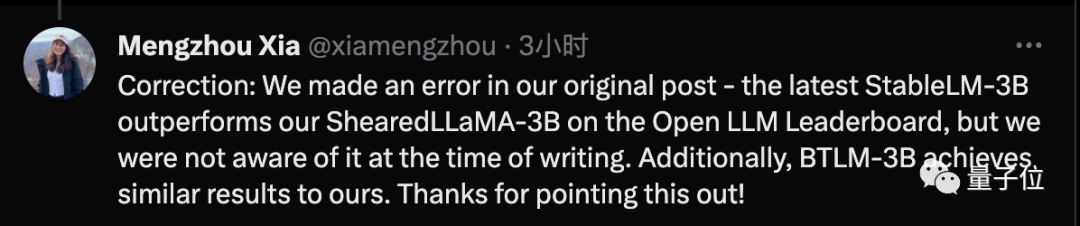
Mengzhou Xia vient de publier une correction, déclarant que la technologie SOTA a été utilisée lors de la rédaction de l'article, mais qu'une fois l'article terminé, elle a été dépassée par la dernière technologie Stable-LM-3B
Adresse du papier : https : / /arxiv.org/abs/2310.06694
Hugging Face : https://huggingface.co/princeton-nlp
Lien vers la page d'accueil du projet : https://xiamengzhou.github.io/sheared-llama/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- La nouvelle méthode de segmentation de modèles 3D vous libère les mains ! Aucun étiquetage manuel n'est requis, une seule formation est requise et les catégories non étiquetées peuvent également être reconnues |
- Implémentez une formation Edge avec moins de 256 Ko de mémoire et le coût est inférieur à un millième de celui de PyTorch
- Les méta-chercheurs font une nouvelle tentative en matière d'IA : apprendre aux robots à naviguer physiquement sans cartes ni formation
- Utiliser Pytorch pour mettre en œuvre l'apprentissage contrastif SimCLR pour une pré-formation auto-supervisée
- Le nouveau travail de l'équipe de Zhu Jun à l'Université Tsinghua : utilisez des entiers à 4 chiffres pour entraîner Transformer, qui est 2,2 fois plus rapide que FP16, 35,1 % plus rapide, accélérant l'arrivée d'AGI !