
Maison >Périphériques technologiques >IA >Une approche surprenante de la redondance temporelle : une nouvelle façon de réduire le coût de calcul des transformateurs visuels
Une approche surprenante de la redondance temporelle : une nouvelle façon de réduire le coût de calcul des transformateurs visuels

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-06 14:45:041822parcourir
Transformer a été conçu à l'origine pour les tâches de traitement du langage naturel, mais est désormais largement utilisé dans les tâches de vision. Visual Transformer a démontré une excellente précision dans plusieurs tâches de reconnaissance visuelle et a atteint les meilleures performances actuelles dans des tâches telles que la classification d'images, la classification vidéo et la détection d'objets
Un inconvénient majeur de Visual Transformer est le coût de calcul élevé. Les réseaux convolutifs typiques (CNN) nécessitent des dizaines de GFlops par image, tandis que les transformateurs visuels nécessitent souvent un ordre de grandeur supérieur, atteignant des centaines de GFlops par image. Lors du traitement vidéo, ce problème est encore plus grave en raison de l'énorme quantité de données. Le coût de calcul élevé rend difficile le déploiement de transformateurs visuels sur des appareils dotés de ressources limitées ou d'exigences de latence strictes, ce qui limite les scénarios d'application de cette technologie, sinon nous aurions déjà des applications passionnantes.
Dans un article récent, trois chercheurs de l'Université du Wisconsin-Madison, Matthew Dutson, Yin Li et Mohit Gupta, ont pour la première fois proposé que la redondance temporelle entre les entrées suivantes puisse être utilisée pour réduire le coût du transformateur visuel dans les applications vidéo. . Ils ont également publié le code du modèle, qui inclut le module PyTorch utilisé pour créer Eventful Transformer.

- Adresse papier : https://arxiv.org/pdf/2308.13494.pdf
- Adresse du projet : http://wisionlab.com/project/eventful-transformers
Redondance temporelle : supposons d'abord qu'il existe un transformateur visuel capable de traiter une séquence vidéo image par image ou un clip vidéo par clip vidéo. Ce Transformer peut être un simple modèle de traitement image par image (comme un détecteur d'objet) ou une étape intermédiaire dans un modèle spatio-temporel (comme la première étape du modèle décomposé de ViViT). Contrairement au Transformer de traitement du langage, où une entrée est une séquence complète, les chercheurs fournissent ici plusieurs entrées différentes (images ou clips vidéo) au Transformer au fil du temps.
Les vidéos naturelles contiennent une redondance temporelle importante, c'est-à-dire que les différences entre les images suivantes sont faibles. Néanmoins, les réseaux profonds, y compris les Transformers, calculent généralement chaque image « à partir de zéro ». Cette méthode élimine les informations potentiellement pertinentes obtenues grâce à un raisonnement précédent, ce qui est extrêmement inutile. Dès lors, ces trois chercheurs se sont demandés : peut-on réutiliser les résultats de calculs intermédiaires des étapes de calcul précédentes pour améliorer l’efficacité du traitement des séquences redondantes ?
Inférence adaptative : pour les transformateurs visuels et les réseaux profonds en général, le coût de l'inférence est souvent dicté par l'architecture. Cependant, dans les applications réelles, les ressources disponibles peuvent changer au fil du temps, par exemple en raison de processus concurrents ou de changements de puissance. Par conséquent, il peut s'avérer nécessaire de modifier le coût de calcul du modèle au moment de l'exécution. L’un des principaux objectifs de conception fixés par les chercheurs dans ce nouvel effort était l’adaptabilité : leur approche permettait de contrôler en temps réel les coûts de calcul. La figure 1 ci-dessous (en bas) donne un exemple de modification du budget de calcul pendant le traitement vidéo.
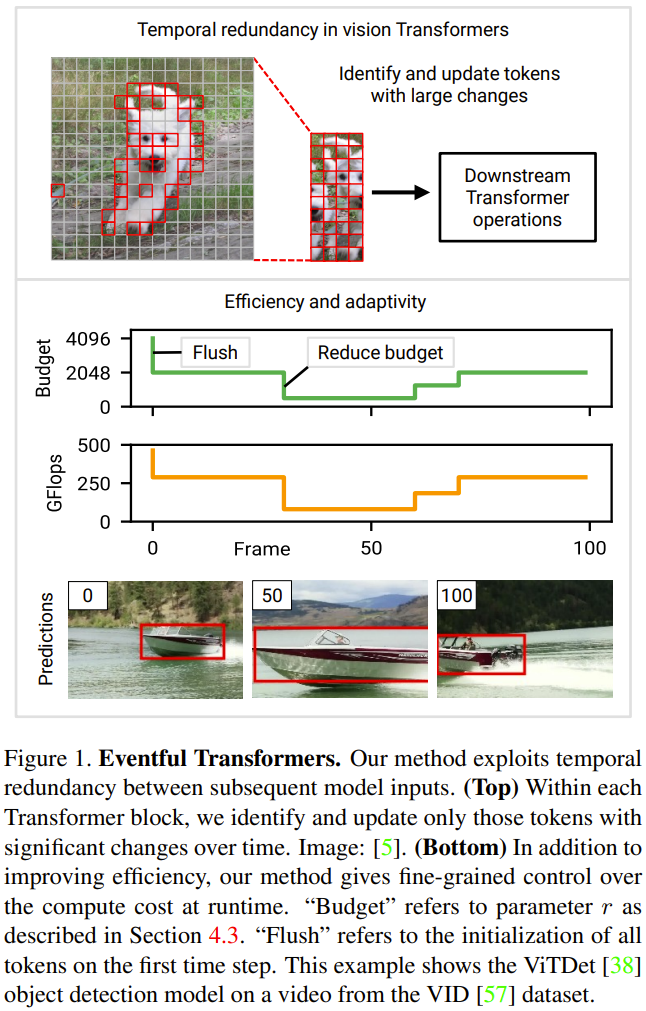
Transformateur basé sur les événements : cet article propose un transformateur basé sur les événements qui peut exploiter la redondance temporelle entre les entrées pour obtenir un raisonnement efficace et adaptatif. Le terme événementisation est inspiré des caméras événementielles, des capteurs qui enregistrent discrètement des images à mesure que la scène change. Le Transformer basé sur les événements suit les changements au niveau des jetons au fil du temps et met à jour de manière sélective la représentation des jetons et la carte d'auto-attention à chaque pas de temps. Le module Transformer basé sur les événements contient un module de contrôle pour contrôler le nombre de jetons de mise à jour. Cette méthode convient aux modèles existants (généralement sans recyclage) et convient à de nombreuses tâches de traitement vidéo. Les chercheurs ont également mené des expériences pour prouver que les résultats montrent que l'Eventful Transformer peut être utilisé sur les meilleurs modèles existants tout en réduisant considérablement le coût de calcul et en conservant la précision d'origine
Eventful Transformer
Contenu réécrit : L'objectif de cette recherche vise à accélérer les transformateurs visuels pour la reconnaissance vidéo. Dans ce scénario, le transformateur visuel doit traiter de manière répétée des images vidéo ou des clips vidéo. Les tâches spécifiques incluent la détection de cible vidéo et la reconnaissance d'action vidéo. L’idée clé proposée est d’exploiter la redondance temporelle, c’est-à-dire de réutiliser les résultats de calcul des pas de temps précédents. Ce qui suit décrira en détail comment modifier le module Transformer pour avoir la capacité de percevoir la redondance temporelle
Token Gating : Détection de la redondance
Cette section présentera deux nouveaux modules proposés par les chercheurs : token gate et token buffer. Ces modules permettent au modèle d'identifier et de mettre à jour les jetons qui ont changé de manière significative depuis la dernière mise à jour. Module Gate : Cette porte sélectionne une partie M du jeton d'entrée N et l'envoie à la couche aval pour effectuer des calculs. Il conserve un jeton de référence défini dans sa mémoire, noté u. Ce vecteur de référence contient la valeur de chaque token au moment de sa plus récente mise à jour. À chaque pas de temps, chaque jeton est comparé à sa valeur de référence correspondante et le jeton qui est significativement différent de la valeur de référence est mis à jour.
Marquez maintenant l'entrée actuelle de cette porte comme c. À chaque pas de temps, l'état de la porte est mis à jour et sa sortie est déterminée selon le processus suivant (voir Figure 2 ci-dessous) :
1 Calculez l'erreur totale e = u − c. 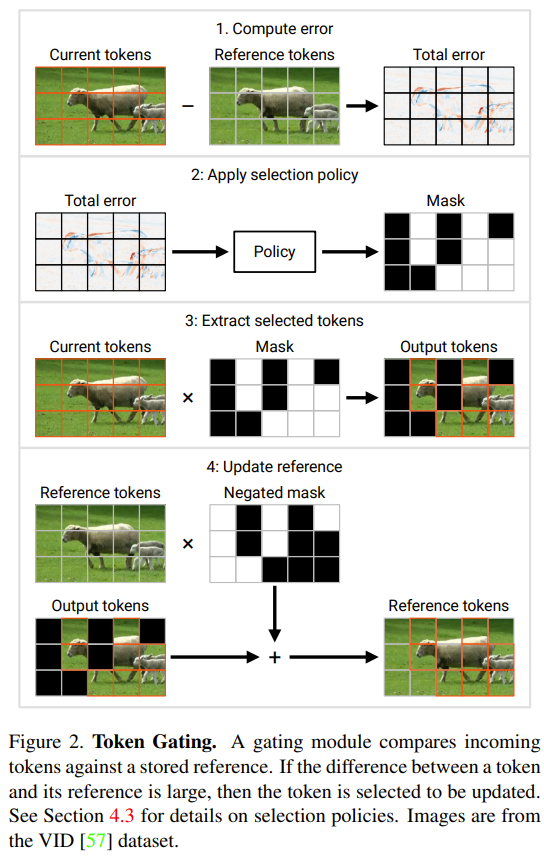
2. Utiliser une stratégie de sélection pour l'erreur e. La stratégie de sélection renvoie un masque binaire m (équivalent à une liste d'index de jetons), indiquant quels M jetons doivent être mis à jour.
3. Extrayez le jeton sélectionné par la stratégie ci-dessus. Ceci est décrit sur la figure 2 comme le produit c × m ; en pratique, il est obtenu en effectuant une opération de « rassemblement » le long du premier axe de c. Les jetons collectés sont enregistrés ici sous la forme
, qui est la sortie de la porte. 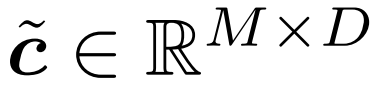 4. Mettez à jour le jeton de référence avec le jeton sélectionné. La figure 2 décrit ce processus comme
4. Mettez à jour le jeton de référence avec le jeton sélectionné. La figure 2 décrit ce processus comme
; l'opération utilisée en pratique est « scatter ». Dans le premier pas de temps, la porte met à jour tous les jetons (en initialisant u ← c et en renvoyant c˜ = c). 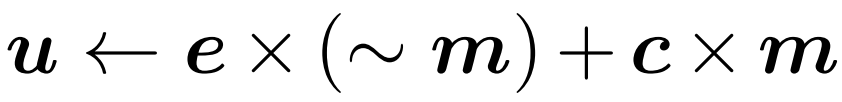 Module tampon : Le module tampon maintient un tenseur d'état
Module tampon : Le module tampon maintient un tenseur d'état
, qui suit chaque jeton d'entrée 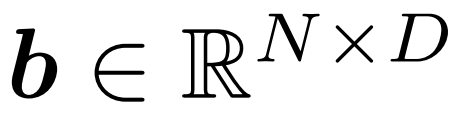 Le tampon distribue les jetons de f (c˜) à la position correspondante dans b. Il renvoie ensuite le b mis à jour comme sortie, voir la figure 3 ci-dessous.
Le tampon distribue les jetons de f (c˜) à la position correspondante dans b. Il renvoie ensuite le b mis à jour comme sortie, voir la figure 3 ci-dessous.
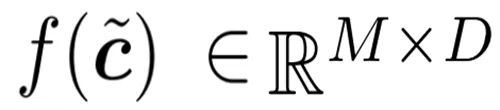
Les chercheurs ont associé chaque porte à un tampon derrière elle. Voici un modèle d'utilisation simple : la sortie de la porte 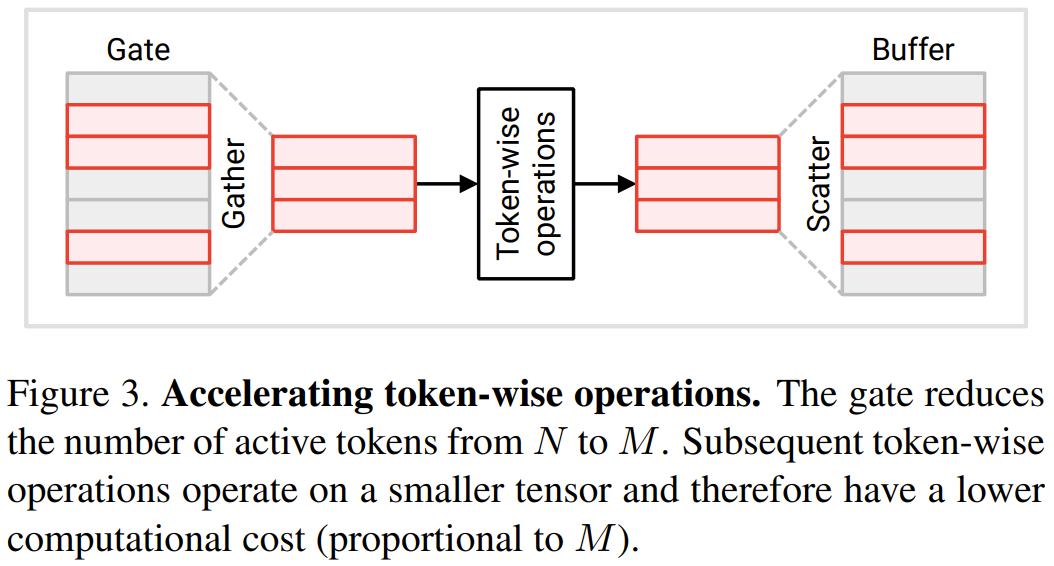
est transmise à une série d'opérations f (c˜) sur chaque jeton ; puis le tenseur résultant
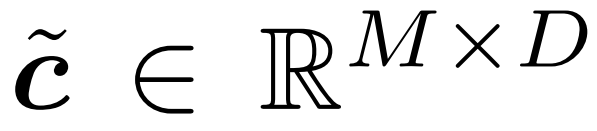 est transmis à un tampon, dont la forme complète sera restauré.
est transmis à un tampon, dont la forme complète sera restauré. 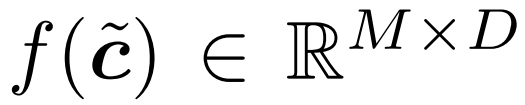 Reconstruisez le transformateur avec une redondance perceptible
Reconstruisez le transformateur avec une redondance perceptible
Afin de profiter de la redondance temporelle ci-dessus, le chercheur a proposé un schéma de modification du module Transformateur. La figure 4 ci-dessous montre la conception du module Eventful Transformer. Cette méthode peut accélérer les opérations sur des jetons individuels (tels que MLP) ainsi que la multiplication de la valeur-clé de requête et de la valeur d'attention.
Dans le module Operation Transformer pour chaque jeton, de nombreuses opérations sont pour chaque jeton, ce qui signifie qu'elles n'impliquent pas d'échange d'informations entre les jetons, y compris les transformations linéaires en MLP et MSA. Afin de réduire les coûts de calcul, les chercheurs ont déclaré que les opérations orientées jetons sur les jetons non sélectionnés par la porte peuvent être ignorées. Du fait de l'indépendance entre les tokens, cela ne change pas le résultat de l'opération sur le token sélectionné. Voir la figure 3.
Plus précisément, les chercheurs ont utilisé une séquence continue d'une paire de tampons de porte lors du traitement des opérations de chaque jeton, y compris la transformation W_qkv, la transformation W_p et MLP. Il convient de noter qu'avant de sauter la connexion, ils ont également ajouté un tampon pour garantir que les jetons des deux opérandes d'addition peuvent être correctement alignés. Le coût d'opération pour chaque jeton est proportionnel au nombre de jetons. En réduisant le nombre de N à M, le coût d'opération en aval par jeton sera réduit de N/M fois
Regardons maintenant les résultats du produit requête-clé-valeur B = q k^T
La figure 5 ci-dessous montre une méthode permettant de mettre à jour de manière éparse un sous-ensemble d'éléments dans le produit requête-clé-valeur B.
Le coût global de ces mises à jour est de 2NMD, comparé au coût du calcul de B à partir de zéro est de N^2D. A noter que le coût de la nouvelle méthode est proportionnel à M, le nombre de tokens choisis. Lorsque M
Attention - produit de valeurs : Le chercheur a proposé une méthode basée sur l'incrément Δ Stratégie de mise à jour.
La figure 6 montre une méthode nouvellement proposée pour calculer efficacement trois termes incrémentaux
Lorsque M est inférieur à la moitié de N, la quantité de calcul peut être réduite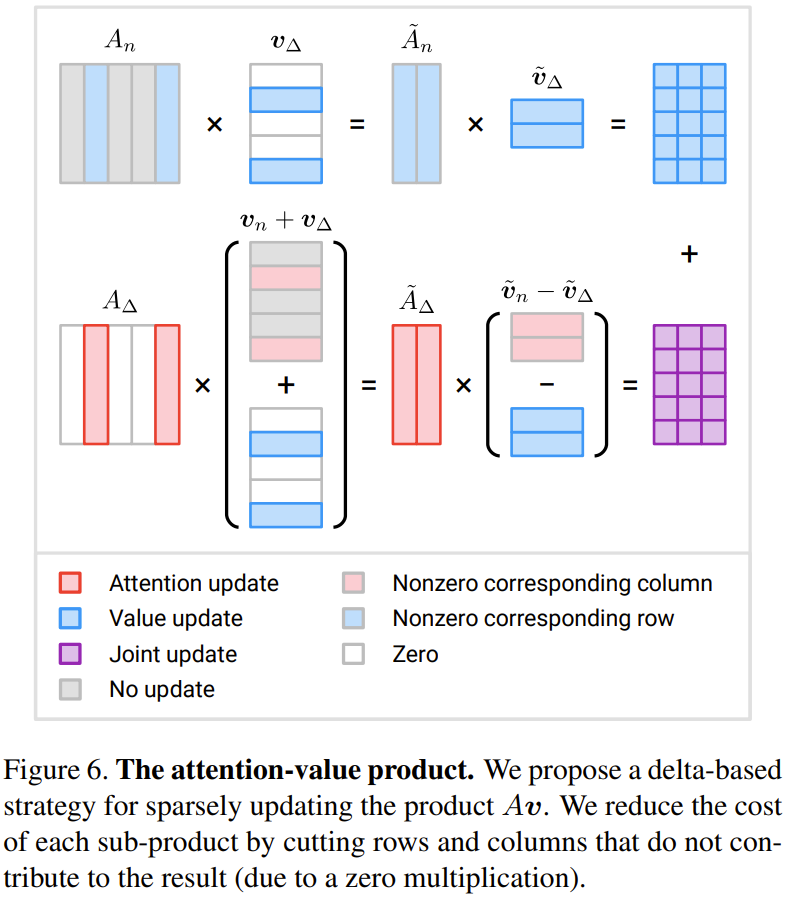
stratégie de sélection de jetons
Une conception importante d'Eventful Transformer est sa stratégie de sélection de jetons. Étant donné un tenseur d'erreur de porte e, le but d'une telle politique est de générer un masque m indiquant les jetons qui doivent être mis à jour. Les stratégies spécifiques incluent :
Stratégie Top-r : Cette stratégie sélectionne les r jetons avec la plus grande erreur e (la norme L2 est utilisée ici).
Stratégie de seuil : Cette stratégie sélectionnera tous les jetons dont la norme d'erreur e dépasse le seuil h
Contenu réécrit : Autres stratégies : L'utilisation de stratégies de sélection de jetons plus complexes et sophistiquées peut obtenir de meilleurs résultats Compromis précision-coût , par exemple, un réseau de politiques léger peut être utilisé pour apprendre la politique. Cependant, la formation du mécanisme de prise de décision de la politique peut se heurter à des difficultés car le masque binaire m est généralement non différentiable. Une autre idée consiste à utiliser le score d’importance comme information de référence pour la sélection. Cependant, ces idées nécessitent encore des recherches plus approfondies. Résultats expérimentaux de détection de cibles. où l’axe positif est le taux d’épargne informatique et l’axe négatif est la réduction relative du score mAP50 pour la nouvelle méthode. On peut constater que la nouvelle méthode permet de réaliser d’importantes économies de calcul avec un léger sacrifice de précision.
La figure 8 ci-dessous montre la comparaison des méthodes et les résultats expérimentaux d'ablation pour la tâche de détection de cible vidéo
La figure 9 ci-dessous montre les résultats expérimentaux pour la reconnaissance d'action vidéo.
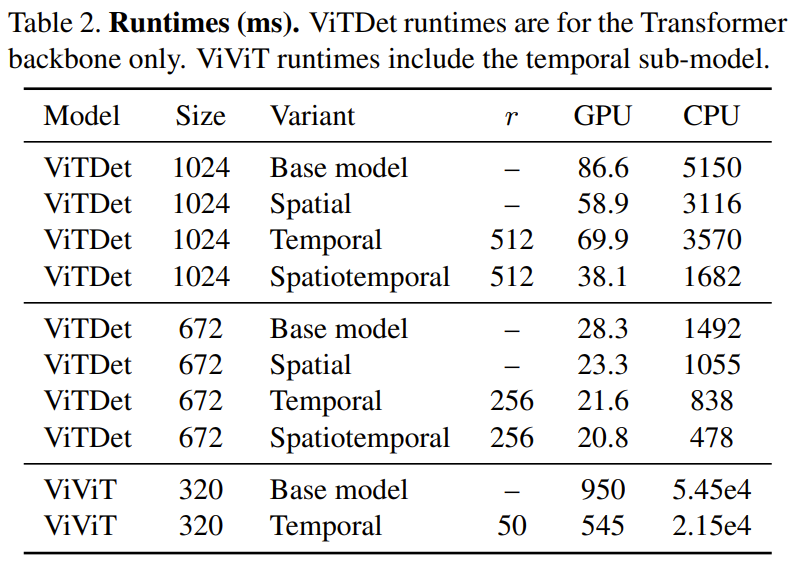
Dans le tableau 2 ci-dessous, les résultats de temps (en millisecondes) sont affichés sur un processeur (Xeon Silver 4214, 2,2 GHz) et un GPU (NVIDIA RTX3090). On peut observer que la redondance temporelle sur le GPU entraîne une augmentation de vitesse de 1,74 fois, tandis que l'amélioration sur le CPU atteint 2,47 fois
Pour plus de détails techniques et de résultats expérimentaux, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment supprimer les données en double dans Excel pour qu'il n'en reste qu'une seule
- Quels sont les types de données de base de Java
- Les méta-chercheurs font une nouvelle tentative en matière d'IA : apprendre aux robots à naviguer physiquement sans cartes ni formation
- Formation personnalisée de modèles d'apprentissage profond à l'aide de techniques d'apprentissage par transfert
- Les modèles ChatGPT peuvent être directement formés ! East China Normal University et le framework open source HugNLP NUS : actualisez le classement en un clic et unifiez entièrement la formation en PNL