
Maison >Périphériques technologiques >IA >Les modèles ChatGPT peuvent être directement formés ! East China Normal University et le framework open source HugNLP NUS : actualisez le classement en un clic et unifiez entièrement la formation en PNL
Les modèles ChatGPT peuvent être directement formés ! East China Normal University et le framework open source HugNLP NUS : actualisez le classement en un clic et unifiez entièrement la formation en PNL

- 王林avant
- 2023-05-29 20:29:221651parcourir
Récemment, l'équipe HugAILab de l'East China Normal University a développé le cadre HugNLP, qui est un cadre de formation PNL complet et unifié pour les chercheurs et les développeurs. Il peut prendre en charge la classification de texte, la correspondance de texte, les questions et réponses, l'extraction d'informations et la génération de texte. , et de petits échantillons. Apprentissage et autre construction et formation de modèles de tâches PNL.
Adresse open source : https://github.com/HugAILab/HugNLP
Papier : https://arxiv.org/abs/2302.14286
C'est vaut notant que HugNLP intègre également un grand nombre des dernières technologies Prompt, telles que le réglage des invites, l'apprentissage en contexte, le réglage des instructions et la chaîne de pensée, qui seront introduites à l'avenir
L'équipe HugAILab a a également développé une série d'applications, telles que CLUE&GLUE L'outil de brossage de listes peut prendre en charge le produit de formation et de déploiement de modèles ChatGPT HugChat, ainsi que le produit d'extraction unifié d'informations HugIE, etc.
HugNLP est un framework en couches qui suit le modèle de développement « à haute cohésion et faible couplage ». Son noyau comprend la couche modèle (Modèles), la couche processeur (Processeurs), la couche évaluateur (Évaluateurs) et la couche application (Applications) quatre. parties.
Le diagramme du cadre est le suivant :
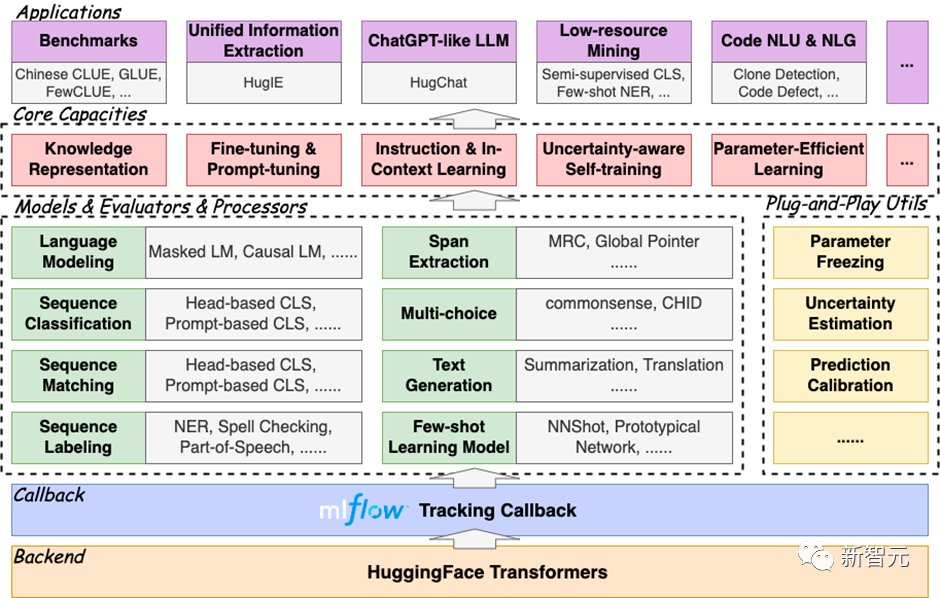
- Couche modèle : contient la partie modèle, principalement divisée selon le type de tâche
- Couche processeur : chargement, mise en cache, segmentation de mots et autres traitements ; de données et converties en Tensor pour la saisie du modèle ;
- Couche d'évaluation : Spécifiez différents processus d'évaluation et indicateurs d'évaluation en fonction de différents types de tâches (classification ou génération) ;
- Couche d'application : Scripts d'exécution d'application correspondants. Théoriquement, la sélection d'un modèle, d'un processeur de données et d'un évaluateur peut correspondre à une application.
HugNLP est entièrement développé sur la base de HuggingFace et dispose de capacités d'expansion et de déploiement faciles. Il intègre également le tracker de formation MLFlow pour permettre aux utilisateurs de suivre les progrès expérimentaux dans le temps et d'effectuer une analyse expérimentale.
Le framework HugNLP est dit complet car il intègre un grand nombre de modèles de tâches PNL. Ce qui a été mis en œuvre jusqu'à présent comprend :
- Pré-formation : LM masqué, LM causal, pré-formation améliorée en termes de connaissances.
- Instruction-Tuning : prend en charge la formation de paradigmes unifiée telle que la génération autorégressive, l'extraction d'intervalles, NLI
- Classification/correspondance de texte : réglage fin traditionnel, réglage rapide, apprentissage en contexte ; Annotation de séquence : prend en charge les tâches d'annotation de séquence telles que NER ;
- Méta-apprentissage : méta-apprentissage basé sur des séquences (SentenceProto), méta-apprentissage basé sur des intervalles (SpanProto), méta-apprentissage basé sur des jetons (TokenProto, NNShot)
- Q&A : prend en charge les questions-réponses extractives, les questions-réponses à choix multiples et les questions-réponses génératives ouvertes ;
- Génération de texte : prend en charge le résumé de texte et la traduction automatique (en cours de développement) ; détection de clone ( Clone), détection de défauts de code (Defact) et autres tâches de code ;
- Déployez rapidement le framework HugNLP
- , il vous suffit d'exécuter trois lignes de code :
git clone https://github.com/HugAILab/HugNLP.gitcd HugNLPpython3 setup.py install
Classement de référence en un clic
pré-formation et injection de connaissances
- Réglage fin et réglage rapide ;
- Dans -Apprentissage contextuel ;
- Autoformation semi-supervisée
- Intelligence du code
- 1. Classement de référence en un clic
- HugNLP a été le premier à développer des outils de classement pour certains classements courants, comme GLUE et CLUE attendez. Les utilisateurs doivent uniquement configurer le nom de l'ensemble de données correspondant pour obtenir une actualisation en un clic.
为了验证框架的有效性,在22年9月提交了CLUE榜单的刷榜结果,选择一系列中文小模型(RoBERTa、MacBERT、P-BERT等)并结合了logits集成方法,至今依然维持在第15名位置,曾一度超越了部分企业。
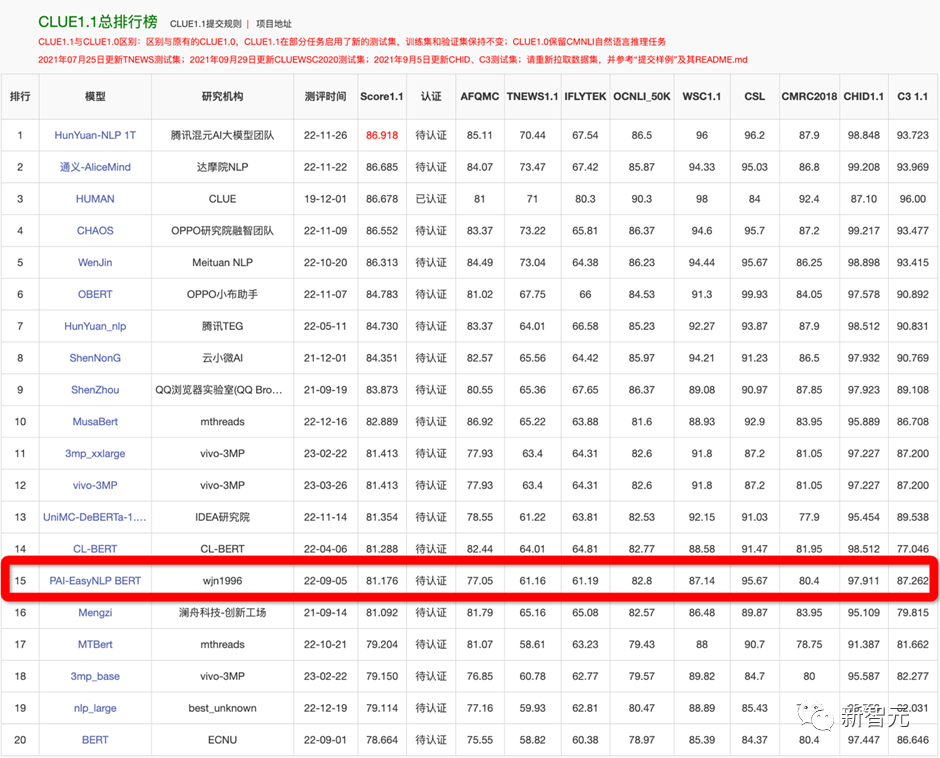
例如如果训练CLUE榜单的AFQMC数据集,可编辑文件
applications/benchmark/clue/clue_finetune_dev.sh
修改参数:
--user_defined="data_name=afqmc"
执行下列命令即可:
bash applications/benchmark/clue/clue_finetune_dev.sh
同样的方法还可以训练一些常用的NLP任务,例如阅读理解、实体识别、以及GLUE英文数据集等。
HugNLP还集成了一系列模型用于刷榜,例如BERT、RoBERTa、DeBERTa、MacBERT、Erlangshen等。
二、预训练与知识注入
传统的一些预训练模型(例如BERT、GPT2等)是在通用语料上训练的,而对领域事实知识可能不敏感,因此需要显式的在预训练阶段注入事实知识。
HugNLP实现了多个知识增强预训练技术,其中包括DKPLM和KP-PLM。可分解的知识注入方法DKPLM和将结构化知识转化为自然语言形式的注入方法KP-PLM是两种不同的注入方式。由于这些知识注入方法采用的是可插拔式的设计,因此无需改变模型结构,这使得在下游任务上进行微调非常容易。
执行下面命令即可进行Masked Language Modeling和Causal Language Modeling的预训练:
bash applications/pretraining/run_pretrain_mlm.shbash applications/pretraining/run_pretrain_casual_lm.sh
三、 Fine-tuning & Prompt-Tuning
Pre-training和Fine-tuning模式通常被遵循,以基于预训练语言模型的NLP。HugNLP也包含Fine-tuning技术。
3.1 参数有效性学习
HugNLP集成了包括Prefix-tuning、Adapter、BitFit、LoRA等参数有效性训练方法,可以加速模型的训练,降低显存占用量。
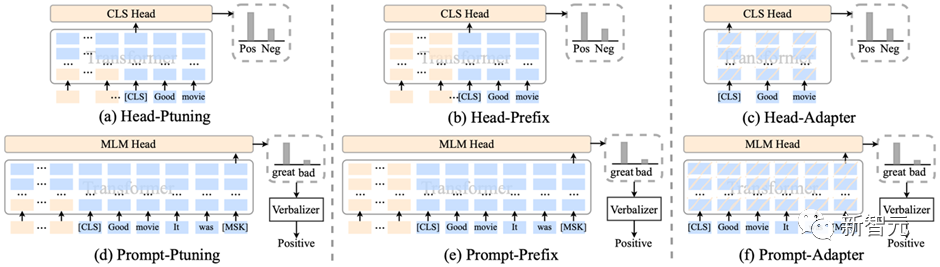
在训练脚本中,只需要添加一行参数,即可开启参数有效性训练:
--use_freezing
对于参数有效性方法,HugNLP实现了若干类别的分类模型,如下所示:
CLASSIFICATION_MODEL_CLASSES = { "head_prefix_cls": { "bert": BertPrefixForSequenceClassification, "roberta": RobertaPrefixForSequenceClassification, }, "head_ptuning_cls": { "bert": BertPtuningForSequenceClassification, "roberta": RobertaPtuningForSequenceClassification, }, "head_adapter_cls": { "bert": BertAdapterForSequenceClassification, "roberta": RobertaAdapterForSequenceClassification, }, "masked_prompt_cls": { "bert": PromptBertForSequenceClassification, "roberta": PromptRobertaForSequenceClassification, }, "masked_prompt_prefix_cls": { "bert": PromptBertPrefixForSequenceClassification, "roberta": PromptRobertaPrefixForSequenceClassification, }, "masked_prompt_ptuning_cls": { "bert": PromptBertPtuningForSequenceClassification, "roberta": PromptRobertaPtuningForSequenceClassification, }, "masked_prompt_adapter_cls": { "bert": PromptBertAdapterForSequenceClassification, "roberta": PromptRobertaAdapterForSequenceClassification, }, }只需要指定下面参数即可,例如选择adapter进行分类:
--task_type=head_adapter_cls
3.2 对抗训练:引入对Embedding的扰动,提高模型的鲁棒性
HugNLP框架集成了若干种对抗训练的方法,其中最简单的对抗方法为FGM算法:
- 首先计算输入样本(通常为word embedding)的损失函数以及在处的梯度:;
- 计算在输入样本的扰动量:,其中为超参数,默认取1.0;
- 得到对抗样本:;
- 根据得到的对抗样本,再次喂入模型中,计算损失,并累积梯度;
- 恢复原始的word embedding,接着下一个batch。
在训练时,只需要添加一行参数,即可默认调用FGM算法:
--do_adv
3.3 Prompt-tuning:通过模板来复用预训练目标
传统的Fine-tuning在低资源场景下容易出现过拟合问题,因此复用预训练的目标可以拉近Pre-training和Fine-tuning之间的语义差异。
HugNLP集成了PET、P-tuning、Prefix-tuning等Prompt-Tuning算法,并无缝嵌入在NLP分类任务的模型里。
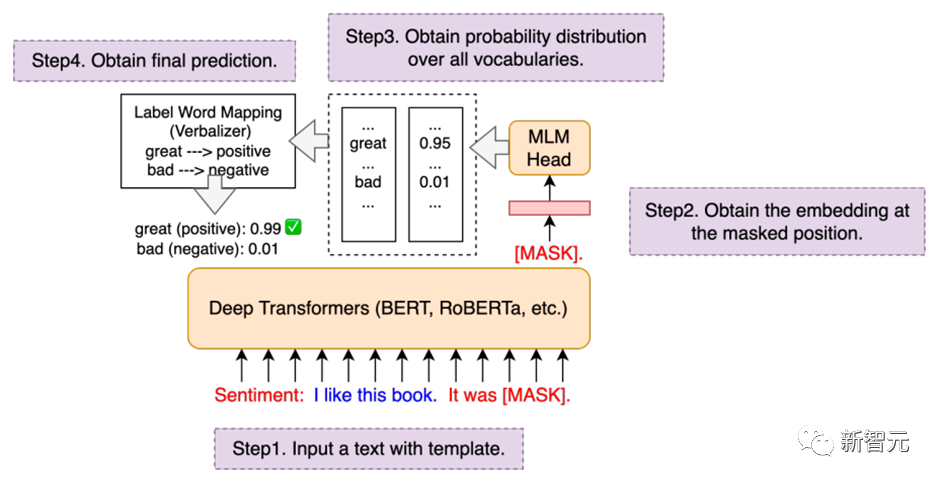
在训练时,只需要指定下面两个参数,即可以开启Prompt-tuning模式,例如选择p-tuning算法:
--task_type=masked_prompt_ptuning_cls--use_prompt_for_cls
四、Instruction-tuning
在构建通用人工智能之前,必须将不同类型的自然语言处理任务进行范式统一,尤其是在大模型时代。HugNLP为此定义了三种统一范式的思想:
- 万物皆可生成:将所有NLP任务建模为单向自回归生成,例如GPT-3、ChatGPT等;
- 万物皆可抽取:将所有NLP任务建模为抽取式机器阅读理解;
- 万物皆可推断:将所有NLP任务建模为自然语言推断;
基于三种不同的范式统一,HugNLP推出两个核心产品,分别是:
- HugChat:基于生成式Instruction的中小型ChatGPT类模型;
- HugIE:基于抽取式Instruction的统一信息抽取框架;
4.1 HugChat:基于Causal Language Modeling的生成式对话模型
最近ChatGPT火爆全球,为了让研究者可以训练自己的ChatGPT,HugNLP框架集成了基于生成式Instruction的训练产品——HugChat,其支持各种类型的单向生成式模型的训练,例如GPT-2、GPT-Neo、OPT、GLM、LLaMA等。
在8张V100 32G的条件下,可训练OPT-13B大模型。HugAILab团队公布了大约200万条英文和300万条中文的对话数据,以用于模型训练。例如训练GPT-2(XL),可直接执行脚本:
bash ./application/instruction_prompting/HugChat/supervised_finetuning/run_causal_instruction_gpt2_xl.sh
使用基于HugNLP训练的GPT-2(1.3B)模型可以轻松地完成对话任务。只需要执行如下命令即可玩转HugChat:
python3 applications/instruction_prompting/HugChat/hugchat.py
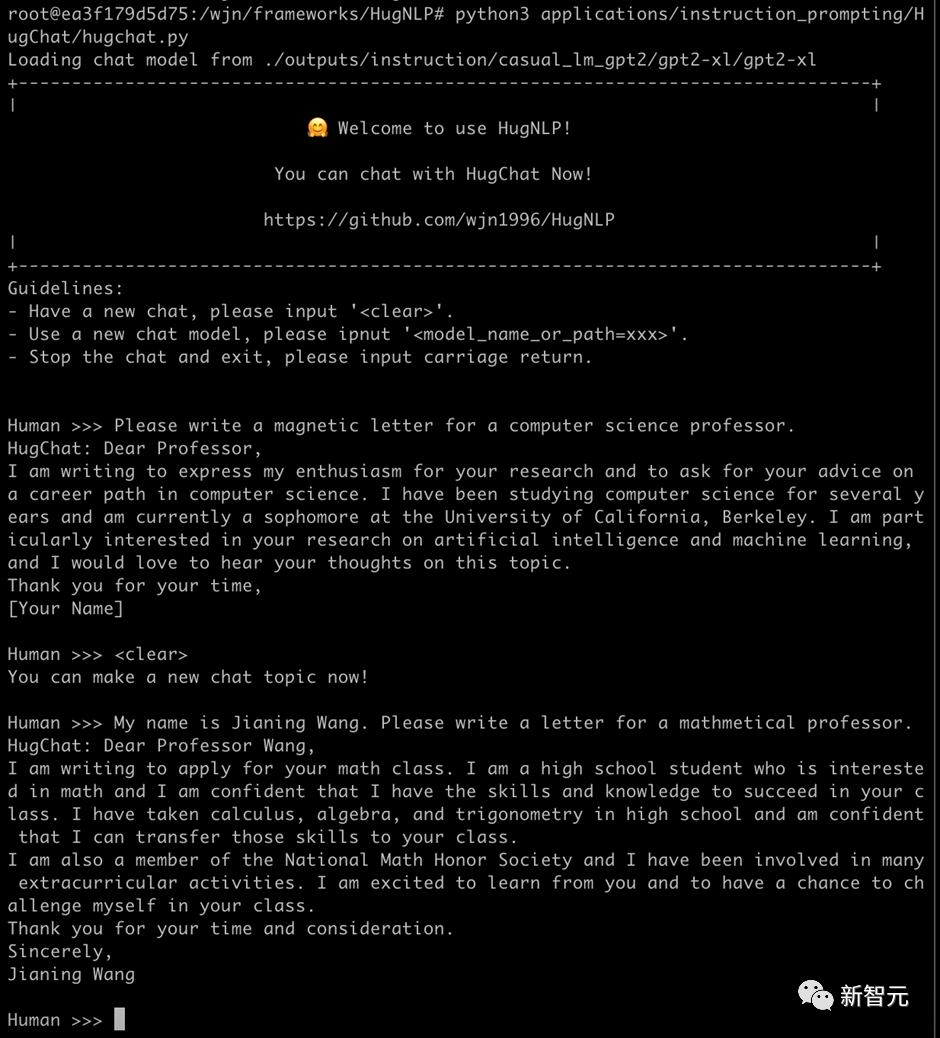
例如可以写套磁信邮件:
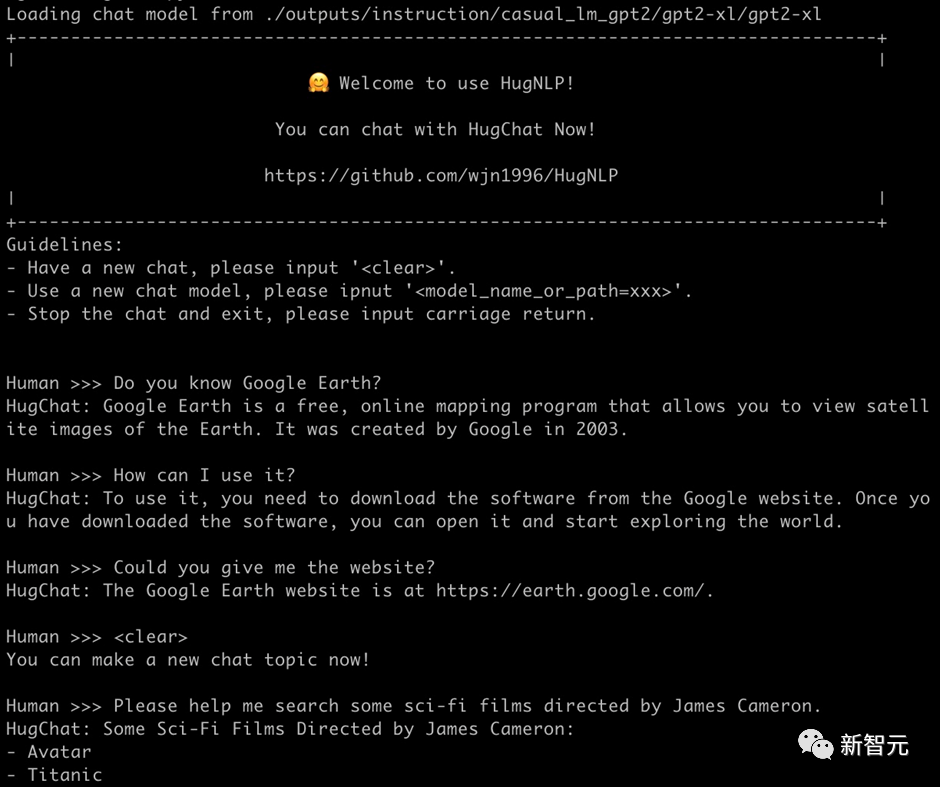
再例如搜索谷歌地球的相关信息:
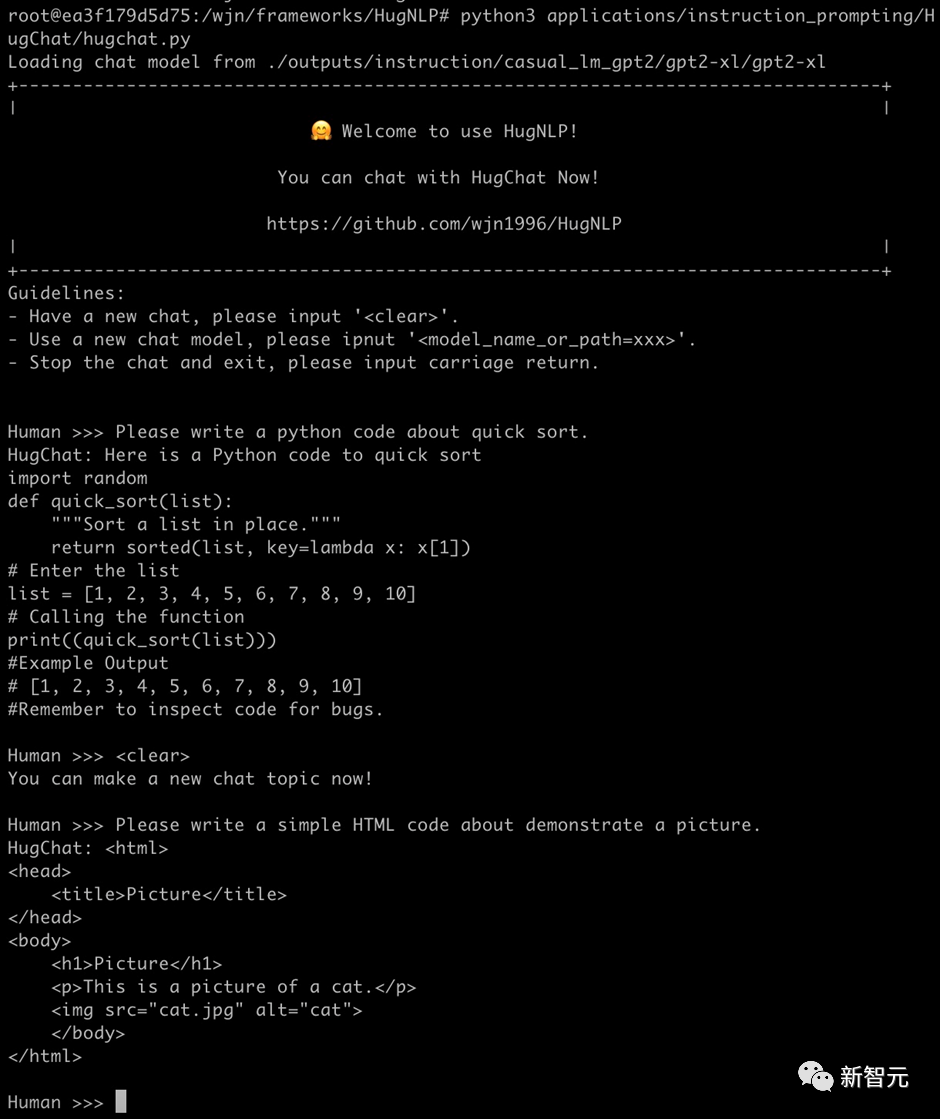
也可以实现编写简单的代码(1.3B的模型具备此能力已经很惊叹了!):
HugNLP目前正在开发其他类型的Decoder-only大模型,相关信息和开源内容如下表所示:
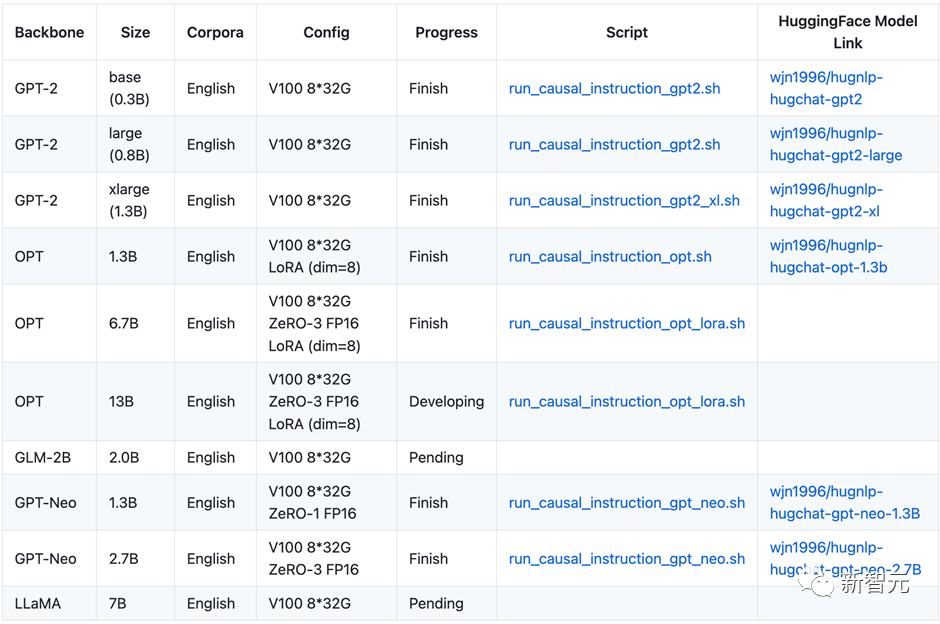
HugChat后期将推出垂直领域的大模型解决方案,同时将与OpenAI API进行融合,推出大模型服务框架。
4.2 HugIE:基于Global Pointer的统一信息抽取框架
信息抽取(Information Extraction)旨在从非结构化的文本中抽取出结构化信息,是构建知识库的重要步骤之一。通常信息抽取包括两个核心步骤,分别是命名实体识别(Named Entity Recognition)和关系抽取(Relation Extraction)。
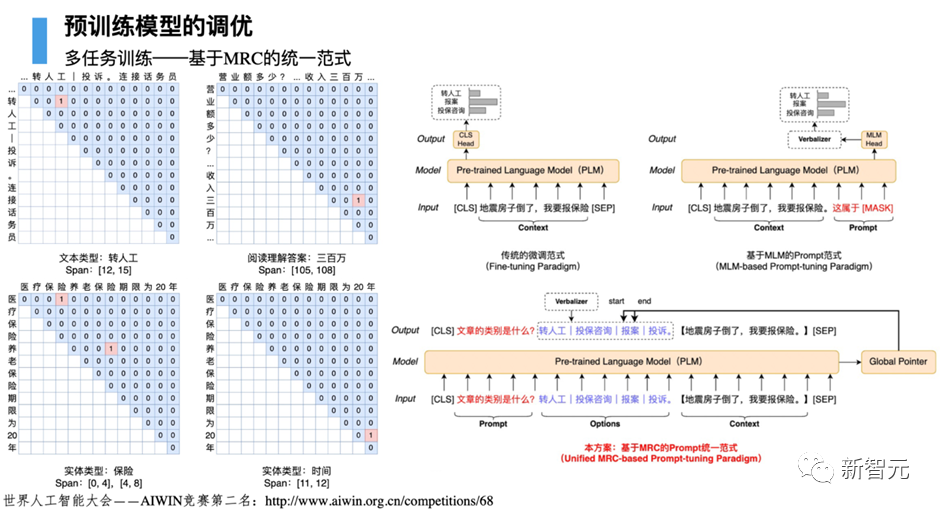
我们基于HugNLP研发一款HugIE产品,旨在实现统一信息处理。其主要核心包括如下几个部分:
- 将实体识别和关系抽取,统一为新的范式——基于抽取式阅读理解的方法。HugIE采用Global Pointer模型实现信息抽取;
- 定义Instruction Prompt,指导模型生成需要抽取的内容;
- 采用多任务训练的方法训练;
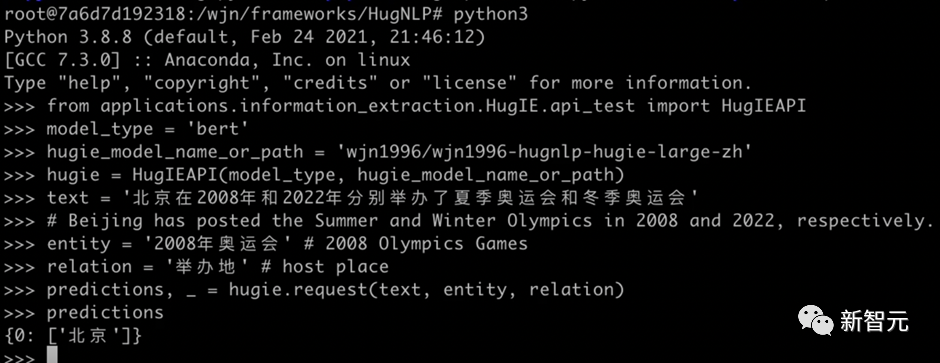
HugIE目前已经开源了模型:https://huggingface.co/wjn1996/wjn1996-hugnlp-hugie-large-zh 可以基于HugNLP框架使用HugIE抽取模型,如下图所示:
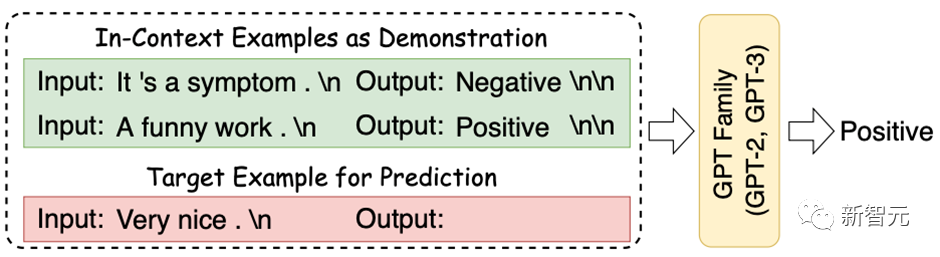
五、In-Context Learning
In-Context Learning(ICL) 首次由GPT-3提出,其旨在挑选少量的标注样本作为提示(Prompt),从而在形式上促使大模型生成目标答案。ICL的优势在于无需对参数进行更新,即可实现惊艳的效果。
HugNLP框架集成了ICL,主要涉及到样本的挑选和预测结果的校准两个部分:
- 样本挑选:默认为从训练集中随机挑选样本,后期将会开发一系列样本挑选的算法,例如聚类、K近邻、余弦相似度等;
-
预测校准:由于所挑选标注样本与待预测样本存在分布差异,需要对预测的概率分布进行校准,这里采用Calibrate Before Use方法,如下图,可以对预测分布进行校准,提高预测效果。
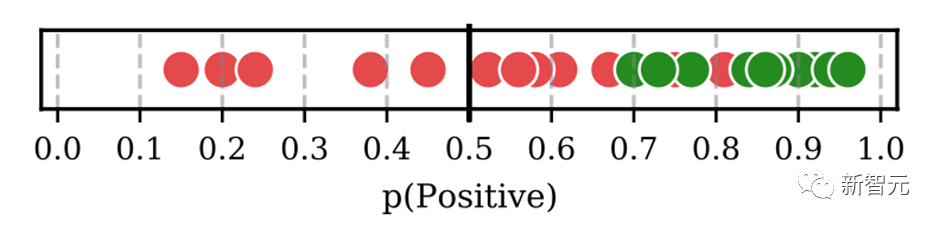
目前ICL已经集成在HugNLP里,只需要指定下面参数即可:
--user_defined="data_name=xxx num_incontext_example=4 l=1 use_calibrate=True"--use_prompt_for_cls
六、半监督Self-training
半监督旨在同时结合标注数据和无标签数据来训练NLP任务。Self-training是一种简单但有效的迭代式训练方法,其通过Teacher模型先获取伪标签,对伪标签进行去噪后,再训练Student模型。Self-training方法传统上存在着较多噪声,可能会削弱训练结果。
为了提高性能,HugNLP引入成熟的Uncertainty-aware Self-training技术。框架图如下所示:
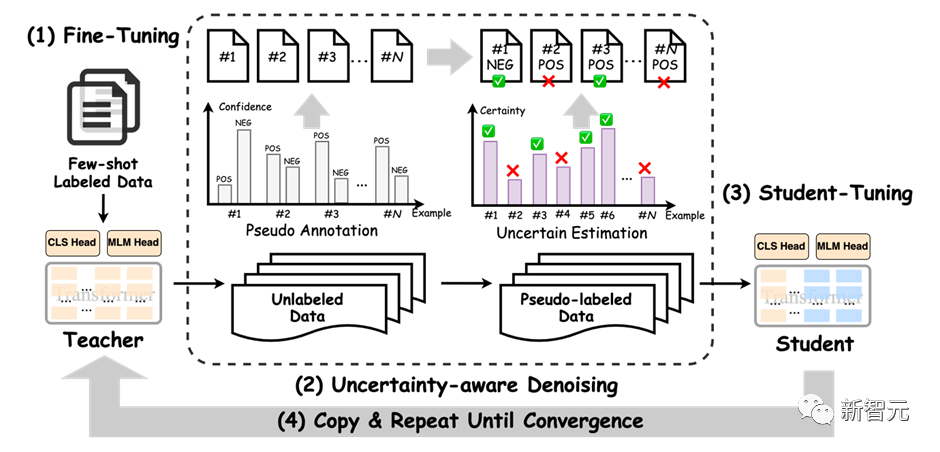
其采用了来自贝叶斯推断中的MC Dropout技术,即对Teacher模型执行 次推理,每次推理开启Dropout开关,从而得到若干与Teacher模型满足独立同分布的模型预测。
基于这些预测结果,可以通过信息熵的变化量得到Teacher模型对无标签数据的不确定性量化指标(即BALD算法),核心公式如下:
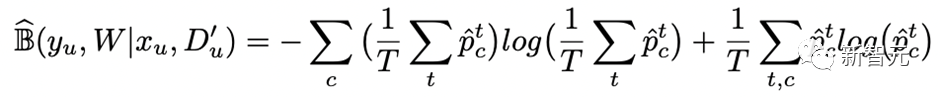
进行多次DC Dropout的代码实现如下(详见hugnlp_trainer.py):
y_T = list()for i in tqdm(range(T)): y_pred = [] for step, inputs in enumerate(unlabeled_dataloader): _, logits, __ = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys) y_pred.extend(logits.detach().cpu().numpy().tolist()) predict_proba = torch.softmax(torch.Tensor(y_pred).to(logits.device), -1) y_T.append(predict_proba.detach().cpu().numpy().tolist()) y_T = np.array(y_T)#compute mean y_mean = np.mean(y_T, axis=0)BALD算法实现如下:def get_BALD_acquisition(y_T):expected_entropy = - np.mean(np.sum(y_T * np.log(y_T + 1e-10), axis=-1), axis=0)expected_p = np.mean(y_T, axis=0)entropy_expected_p = - np.sum(expected_p * np.log(expected_p + 1e-10), axis=-1)return (entropy_expected_p - expected_entropy)
HugNLP使用半监督模式,只需要做两件事:
(1)执行脚本时添加参数:
--use_semi
(2)在指定的数据集目录下,存放unlabeled data文件。
七、其他更丰富的应用
HugNLP has developed numerous applications as listed below, and there are many more exciting applications currently under development.。HugNLP欢迎有志之士加入HugAILab参与开源开发工作。



Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI