
Maison >Périphériques technologiques >IA >'Peu de mots, une grande quantité d'informations', des chercheurs de Salesforce et du MIT enseignent la 'révision' de GPT-4, l'ensemble de données est open source
'Peu de mots, une grande quantité d'informations', des chercheurs de Salesforce et du MIT enseignent la 'révision' de GPT-4, l'ensemble de données est open source

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-09-20 23:57:02907parcourir
La technologie de synthèse automatique a fait de grands progrès ces dernières années, principalement en raison du changement de paradigme : du réglage fin supervisé sur des ensembles de données étiquetés à l'utilisation de grands modèles de langage (LLM) pour des indices zéro, tels que GPT-4. Des invites soigneusement conçues permettent un contrôle précis de la longueur, du sujet, du style et d'autres fonctionnalités du résumé sans formation supplémentaire
Mais un aspect est souvent négligé : la densité des informations du résumé. Théoriquement, en tant que compression d'un autre texte, un résumé devrait être plus dense, c'est-à-dire contenir plus d'informations, que le fichier source. Compte tenu de la latence élevée du décodage LLM, il est important de couvrir davantage d’informations avec moins de mots, notamment pour les applications en temps réel.
Cependant, la densité de l'information est une question ouverte : si le résumé ne contient pas assez de détails, cela équivaut à aucune information ; s'il contient trop d'informations sans augmenter la longueur totale, il deviendra difficile à comprendre. Pour transmettre plus d'informations dans un budget de vocabulaire fixe, vous devez combiner abstraction, compression et fusion
Dans une étude récente, des chercheurs de Salesforce, du MIT et d'autres institutions ont tenté de Cette limite est déterminée par préférence pour un ensemble de plus en plus des résumés plus denses générés par GPT-4. Cette méthode fournit beaucoup d'inspiration pour améliorer la « capacité d'expression » des grands modèles de langage tels que GPT-4.

Lien papier : https://arxiv.org/pdf/2309.04269.pdf
Adresse de l'ensemble de données : https://huggingface.co/datasets/griffin/chain_of_density
Détails spécifiques Dites , leur approche utilise le nombre moyen d'entités par balise comme indicateur de densité, générant ainsi un résumé initial contenant peu d'entités. Ensuite, sans augmenter la longueur totale (la longueur totale est 5 fois celle du résumé d'origine), identifie et fusionne de manière itérative 1 à 3 entités manquantes dans le résumé précédent, de sorte que le rapport entités/balises dans chaque résumé soit supérieur à celui du résumé précédent. Grâce à l'analyse des données de préférences humaines, les auteurs ont finalement identifié une forme de résumé presque aussi dense que les résumés écrits par des humains et plus dense que les résumés générés par les invites GPT-4 ordinaires.
Les contributions globales de l'étude comprennent :
- Développer une approche itérative basée sur des invites (CoD) qui rend les résumés de plus en plus denses en entités
- Effectuer une évaluation manuelle et automatisée des résumés de plus en plus denses dans les articles de CNN/Daily Mail, pour mieux comprendre le compromis ; entre le caractère informatif (privilégiant plus d'entités) et la clarté (privilégiant moins d'entités)
- Résumés GPT-4 open source, annotations et un ensemble de 5000 résumés CoD non annotés, pour évaluation ou affinement.
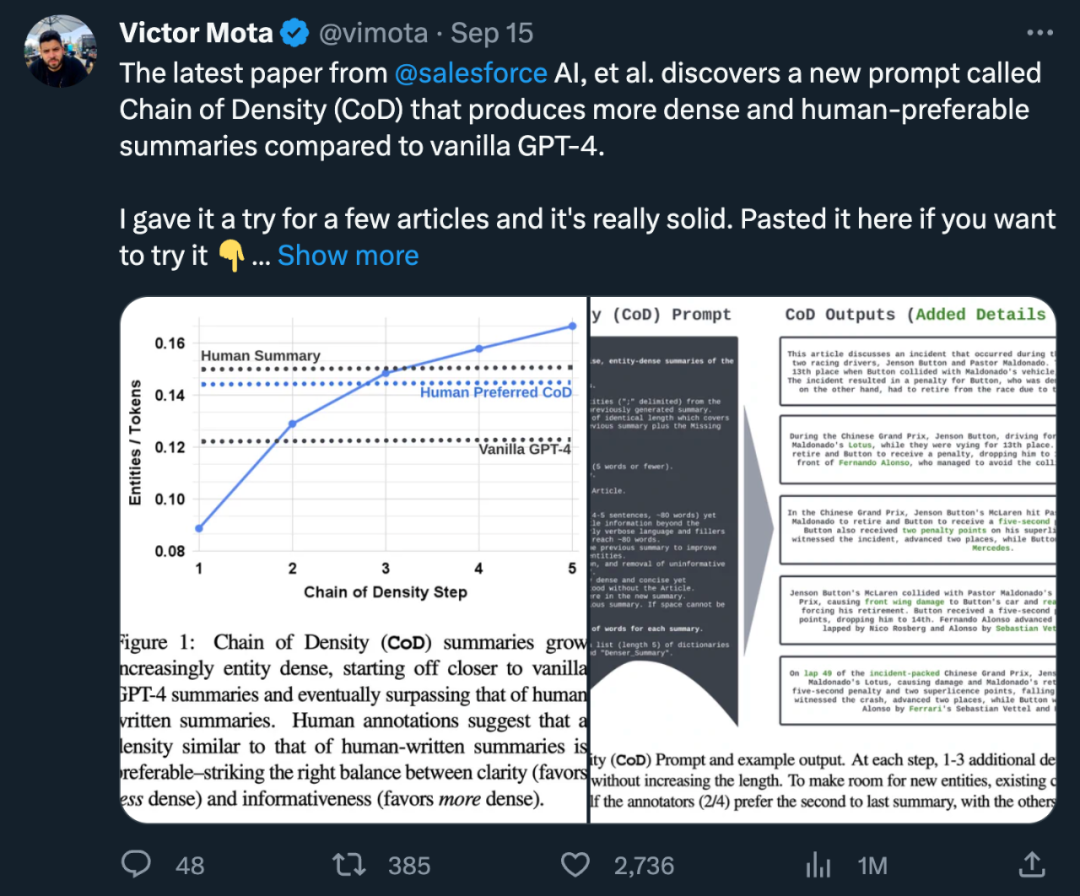
Qu'est-ce que CoD
L'auteur définit une invite appelée "CoD" (Chain of Density) pour générer un résumé initial et augmenter progressivement sa densité d'entité. Plus précisément, au sein d'un nombre fixe d'interactions, un ensemble d'entités saillantes uniques dans le texte source sont identifiées et fusionnées dans le résumé précédent sans augmenter la longueur
Dans la figure 2, l'invite est affichée et des exemples de sortie. L'auteur ne précise pas explicitement les types d'entités, mais définit les entités manquantes comme :
- Connexe : lié à l'histoire principale
- Spécifique : descriptif mais concis (5 mots ou moins) ; Roman : N'apparaît pas dans les résumés précédents ;
- Fidèle : Présent dans l'article
- Partout : Situé n'importe où dans l'article ;
 L'auteur a sélectionné au hasard 100 articles de l'ensemble de tests de résumé CNN/DailyMail pour générer des résumés CoD pour eux. Pour faciliter la référence, ils ont comparé les statistiques récapitulatives de CoD aux résumés de référence rédigés par des humains et aux résumés générés par GPT-4 sous l'invite normale : "Écrivez un très court résumé de l'article. Pas plus de 70 mots."
L'auteur a sélectionné au hasard 100 articles de l'ensemble de tests de résumé CNN/DailyMail pour générer des résumés CoD pour eux. Pour faciliter la référence, ils ont comparé les statistiques récapitulatives de CoD aux résumés de référence rédigés par des humains et aux résumés générés par GPT-4 sous l'invite normale : "Écrivez un très court résumé de l'article. Pas plus de 70 mots."
Dans l'étude, l'auteur a résumé sous deux aspects : les statistiques directes et les statistiques indirectes. Les statistiques directes (jetons, entités, densité des entités) sont directement contrôlées par CoD, tandis que les statistiques indirectes sont un sous-produit attendu de la densification.
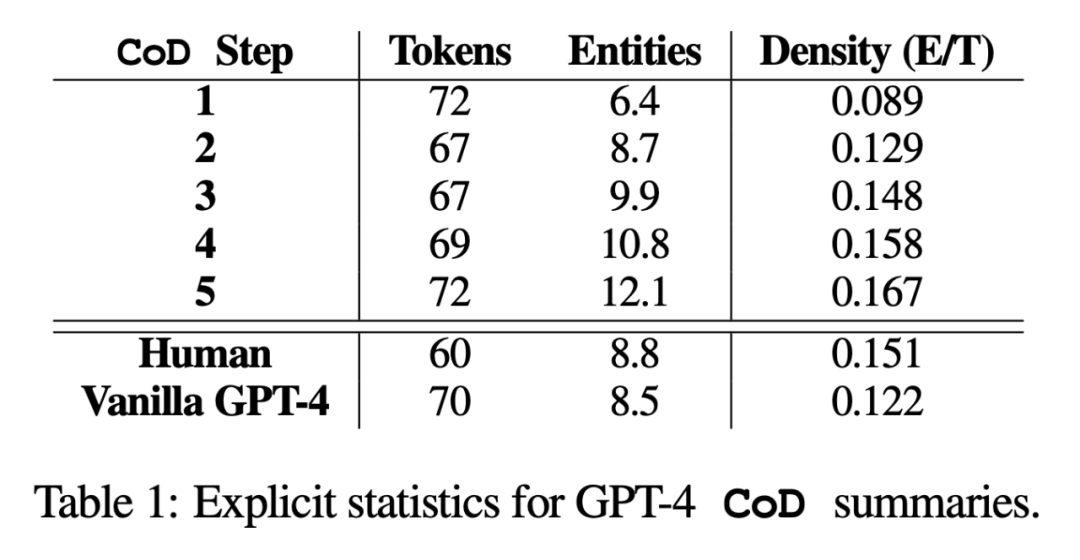
Le contenu réécrit est le suivant : Selon les statistiques, en supprimant les mots inutiles dans les longs résumés, la longueur moyenne de la deuxième étape a été réduite de 5 jetons (de 72 à 67). La densité initiale d'entités est de 0,089, ce qui est inférieur au GPT-4 humain et vanille (0,151 et 0,122), et après 5 étapes de densification, elle monte finalement à 0,167
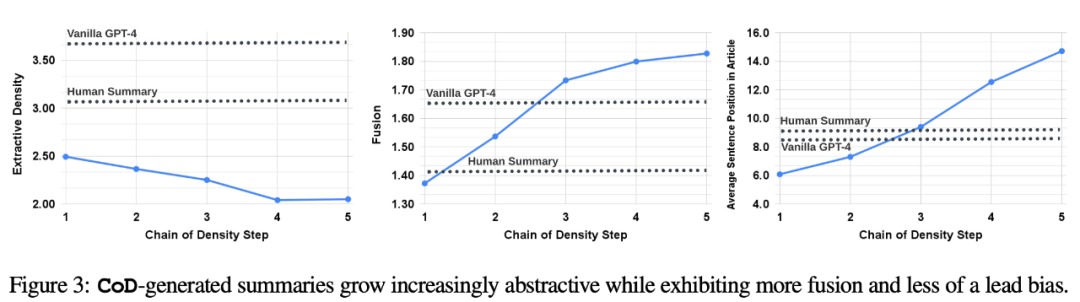
statistiques indirectes. Le niveau d'abstraction devrait augmenter à chaque étape de CoD, car le résumé est réécrit à plusieurs reprises pour faire de la place à chaque entité supplémentaire. Les auteurs mesurent l'abstraction en utilisant la densité d'extraction : la longueur carrée moyenne des fragments extraits (Grusky et al., 2018). De même, la fusion de concepts devrait augmenter de façon monotone à mesure que des entités sont ajoutées à un résumé de longueur fixe. Les auteurs ont exprimé le degré d'intégration par le nombre moyen de phrases sources alignées avec chaque phrase récapitulative. Pour l'alignement, les auteurs utilisent la méthode du gain relatif ROUGE (Zhou et al., 2018), qui aligne la phrase source avec la phrase cible jusqu'à ce que le gain relatif ROUGE des phrases supplémentaires ne soit plus positif. Ils s’attendaient également à des changements dans la distribution du contenu ou dans la position dans l’article d’où provient le contenu résumé.
Plus précisément, les auteurs prédisent que les résumés de Call of Duty (CoD) montreront dans un premier temps un fort « biais d'amorçage », c'est-à-dire que davantage d'entités seront introduites au début de l'article. Cependant, à mesure que l’article se développe, ce parti pris s’affaiblit progressivement et des entités commencent à être introduites à partir du milieu et de la fin de l’article. Pour mesurer cela, nous avons utilisé les résultats de l'alignement dans la fusion et mesuré le rang moyen des phrases sources alignées. La figure 3 confirme ces hypothèses : à mesure que le nombre d'étapes de réécriture augmente, l'abstraction augmente également. densité d'extraction à gauche), le taux de fusion augmente (image du milieu) et le résumé commence à incorporer le contenu du milieu et de la fin de l'article (image de droite). Il est intéressant de noter que tous les résumés CoD étaient plus abstraits que les résumés écrits par des humains et les résumés de base. évaluation basée sur les notes à l'aide de GPT-4
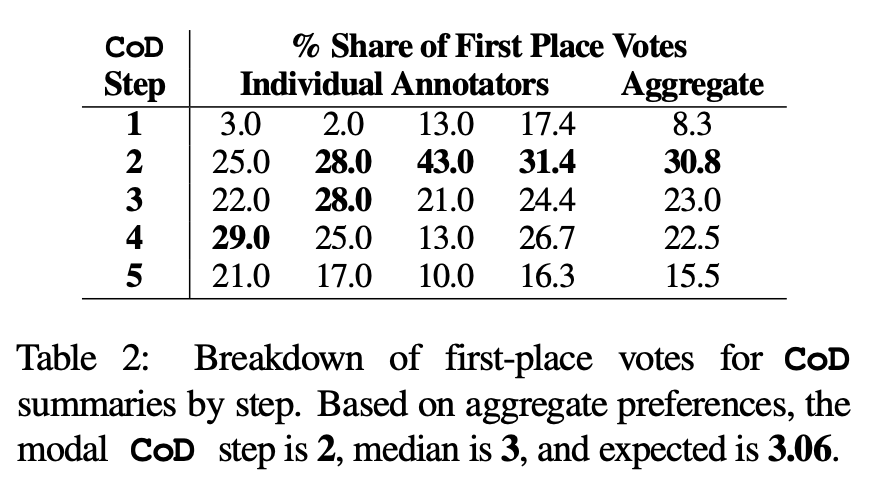
Préférences humaines. Plus précisément, pour les mêmes 100 articles (5 étapes * 100 = 500 résumés au total), l'auteur a montré au hasard les résumés et articles CoD « recréés » aux quatre premiers auteurs de l'article. Chaque annotateur a donné son résumé préféré sur la base de la définition de Stiennon et al. (2020) d'un « bon résumé ». Le tableau 2 rapporte les votes de première place de chaque annotateur dans l'étape CoD, ainsi que le résumé de chaque annotateur. Dans l'ensemble, 61 % des résumés de première place (23,0+22,5+15,5) impliquaient ≥3 étapes de densification. Le nombre médian d’étapes CoD préférées se situe au milieu (3), avec un nombre d’étapes attendu de 3,06.
Sur la base de la densité moyenne du résumé de l'étape 3, on peut en déduire grossièrement que la densité d'entités préférée de tous les candidats CoD est de ∼ 0,15. Comme le montre le tableau 1, cette densité est cohérente avec les résumés rédigés par des humains (0,151), mais nettement supérieure à celle des résumés rédigés avec des invites GPT-4 ordinaires (0,122).
Mesure automatique. En complément de l'évaluation humaine (ci-dessous), les auteurs ont utilisé GPT-4 pour noter les résumés CoD (1 à 5 points) selon 5 dimensions : caractère informatif, qualité, cohérence, attribuable et totalité. Comme le montre le tableau 3, la densité est en corrélation avec le caractère informatif, mais jusqu'à une limite, le score culminant à l'étape 4 (4,74).
Parmi les scores moyens de chaque dimension, les première et dernière étapes de CoD ont les scores les plus bas, tandis que les trois étapes du milieu ont des scores proches (4,78, 4,77 et 4,76 respectivement).
Analyse qualitative. Il existe un compromis évident entre cohérence/lisibilité et contenu informatif du résumé. La figure 4 montre deux étapes CoD : le résumé d'une étape est amélioré par plus de détails, tandis que le résumé de l'autre étape est compromis. Dans l'ensemble, le résumé CoD intermédiaire est capable d'atteindre cet équilibre, mais ce compromis doit encore être défini et quantifié avec précision dans les travaux futurs
Pour plus de détails sur le document, veuillez vous référer au document original.
Pour plus de détails sur le document, veuillez vous référer au document original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!