
Maison >Périphériques technologiques >IA >Nouvelle percée dans la « génération interactive de personnes et de scènes » ! L'Université Tianda et l'Université Tsinghua publient le Narrateur : piloté par du texte, naturellement contrôlable |
Nouvelle percée dans la « génération interactive de personnes et de scènes » ! L'Université Tianda et l'Université Tsinghua publient le Narrateur : piloté par du texte, naturellement contrôlable |

- PHPzavant
- 2023-09-11 23:13:051007parcourir
La génération naturelle et contrôlable d'interactions avec la scène humaine (HSI) joue un rôle important dans de nombreux domaines tels que la création de contenu de réalité virtuelle/réalité augmentée (VR/AR) et l'intelligence artificielle centrée sur l'humain.
Cependant, les méthodes existantes ont une contrôlabilité limitée, des types d'interaction limités et des résultats générés non naturels, ce qui limite sérieusement leurs scénarios d'application dans la vie réelle
Dans la recherche de l'ICCV 2023, l'Université de Tianjin et l'Université de Tsinghua L'équipe est arrivée avec une solution appelée Narrator pour explorer ce problème. Cette solution se concentre sur la tâche difficile consistant à générer de manière naturelle et contrôlable des interactions réalistes et diverses entre la scène humaine à partir de descriptions textuelles
 images
images
Lien vers la page d'accueil du projet : http://cic.tju.edu.cn/faculty/ likun/projects/Narrator
Le contenu réécrit est : Lien de code : https://github.com/HaibiaoXuan/Narrator
Du point de vue de la cognition humaine, idéal Le modèle génératif devrait être capable de raisonner correctement sur les relations spatiales et explorer les degrés de liberté des interactions.
L'auteur propose donc un modèle génératif basé sur le raisonnement relationnel. Ce modèle modélise les relations spatiales dans les scènes et les descriptions à travers des graphiques de scène, et introduit un mécanisme d'interaction au niveau des parties qui représente les actions interactives sous forme d'états de parties du corps atomique
En particulier, l'auteur propose une génération multi-personnes simple mais efficace stratégie, il s'agit de la première exploration de la génération interactive contrôlable de scènes à plusieurs personnes
Enfin, après des expériences approfondies et des recherches sur les utilisateurs, l'auteur a prouvé que le narrateur peut générer diverses manières contrôlables. travaux existants
Motivation de la méthode
Les méthodes existantes de génération d'interactions entre humains et scènes se concentrent principalement sur la relation géométrique physique de l'interaction, mais manquent de contrôle sémantique sur la génération, et sont également limitées à la génération d'un seul joueur.
Par conséquent, les auteurs se concentrent sur la tâche difficile consistant à générer de manière contrôlable des interactions réalistes et diverses entre la scène humaine à partir de descriptions en langage naturel. Les auteurs ont observé que les humains utilisent généralement la perception spatiale et la reconnaissance des actions pour décrire naturellement les personnes engagées dans diverses interactions dans différents endroits.
 Picture
Picture
Le contenu réécrit est le suivant : Selon la figure 1, le narrateur peut générer naturellement et de manière contrôlable des interactions sémantiquement cohérentes et physiquement raisonnables avec la scène humaine, applicables aux situations suivantes : (a) Par relation spatiale -interaction guidée, (b) interaction guidée par plusieurs actions, (c) interaction de scène à plusieurs personnes et (d) interaction personne-scène combinant les types d'interaction ci-dessus
Plus précisément, les relations spatiales peuvent être utilisées. Décrire les interrelations entre différents objets dans une scène ou une zone locale. Les actions interactives sont spécifiées par l'état des parties atomiques du corps, comme les pieds d'une personne au sol, s'appuyer sur le torse, taper avec la main droite, baisser la tête, etc.
Avec cela comme point de départ, le L'auteur utilise des graphiques de scène pour représenter les relations spatiales et propose que le mécanisme JGLSG (Joint Global and Local Scene Graph) soit adopté pour fournir une connaissance de la position globale pour la génération suivante.
Dans le même temps, considérant que l'état des parties du corps est la clé pour simuler des interactions réalistes cohérentes avec le texte, l'auteur a introduit un mécanisme d'action au niveau des parties (PLA) pour établir la correspondance entre les parties du corps humain et les actions.
Bénéficiant de la cognition observationnelle efficace et de la flexibilité et de la réutilisabilité du raisonnement relationnel proposé, l'auteur propose en outre une stratégie de génération multi-personnes simple et efficace, qui est à l'époque la première stratégie naturellement contrôlable et générée par l'utilisateur. Solution conviviale de génération d’interactions multi-scènes humaines (MHSI). "Idées de méthodes" -scène dimensionnelle
image
Figure 2 Présentation du cadre du Narrateur Comme le montre la figure 2, cette méthode utilise un auto-encodeur variationnel conditionnel (cVAE) basé sur Transformer, qui comprend principalement les éléments suivants parties :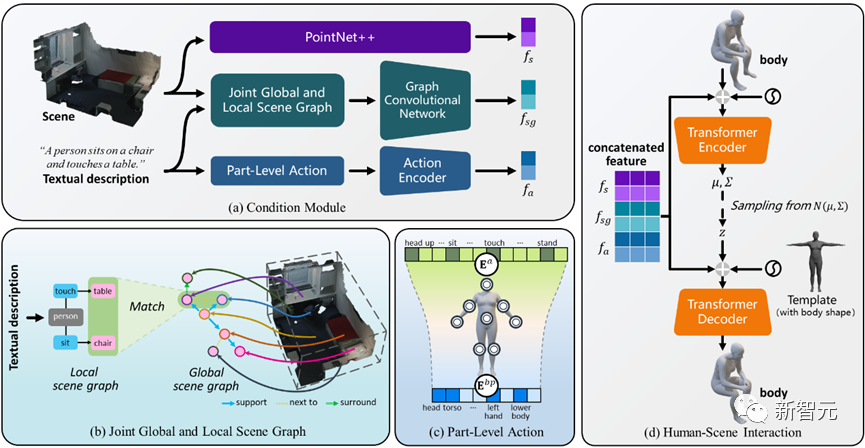 Par rapport aux recherches existantes, nous concevons un mécanisme conjoint de graphe de scène global et local pour raisonner sur des relations spatiales complexes et atteindre une conscience du positionnement global
Par rapport aux recherches existantes, nous concevons un mécanisme conjoint de graphe de scène global et local pour raisonner sur des relations spatiales complexes et atteindre une conscience du positionnement global
2) Cibler les personnes qui passeront en même temps Observation de actions interactives complétées par différentes parties du corps, introduisant un mécanisme d'action au niveau des composants pour obtenir des interactions réalistes et diverses.
Pendant le processus d'optimisation de la perception de la scène, nous avons également introduit la perte bipartite interactive afin d'obtenir de meilleurs résultats. Le résultat généré
4) S'étend davantage à la génération d'interactions à plusieurs personnes et favorise finalement la première étape de l'interaction de scène à plusieurs personnes.
Mécanisme combiné de graphe de scène global et local
Le raisonnement des relations spatiales peut fournir au modèle des indices spécifiques à la scène, ce qui joue un rôle important dans l'obtention d'une contrôlabilité naturelle de l'interaction homme-scène.
Pour atteindre cet objectif, l'auteur propose un mécanisme conjoint de graphe de scène global et local, qui est mis en œuvre à travers les trois étapes suivantes :
1 Génération de graphe de scène globale : étant donné une scène, utilisez les pré-entraînés. le modèle de graphique de scène génère un graphique de scène global, c'est-à-dire 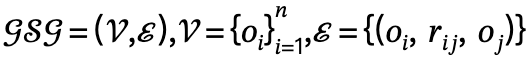 , où
, où 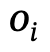 ,
, 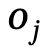 sont des objets avec des étiquettes de catégorie,
sont des objets avec des étiquettes de catégorie, 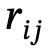 est la relation entre
est la relation entre 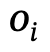 et
et 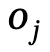 , n est le nombre d'objets, m est le nombre de relations ;
, n est le nombre d'objets, m est le nombre de relations ;
, où
définit le triplet sujet-prédicat-objet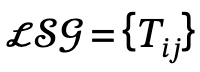
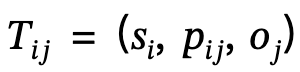
.
L'auteur exploite les contraintes géométriques et physiques pour une optimisation tenant compte de la scène afin d'améliorer les résultats de génération. Tout au long du processus d'optimisation, cette méthode garantit que la pose générée ne dévie pas, tout en favorisant le contact avec la scène et en contraignant le corps pour éviter l'interpénétration avec la scène Compte tenu de la scène tridimensionnelle S et des paramètres SMPL-X générés , la perte d'optimisation est :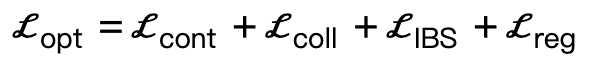
Parmi eux, 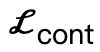 encourage les sommets du corps à entrer en contact avec la scène ;
encourage les sommets du corps à entrer en contact avec la scène ; 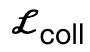 est un terme de collision basé sur une distance signée ;
est un terme de collision basé sur une distance signée ; 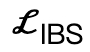 est une perte de surface bipartie interactive (IBS) introduite en plus par rapport au travail existant, qui est échantillonné à égale distance ; entre la scène et le corps humain Point set;
est une perte de surface bipartie interactive (IBS) introduite en plus par rapport au travail existant, qui est échantillonné à égale distance ; entre la scène et le corps humain Point set; 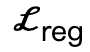 est un facteur de régularisation utilisé pour pénaliser les paramètres qui s'écartent de l'initialisation.
est un facteur de régularisation utilisé pour pénaliser les paramètres qui s'écartent de l'initialisation.
Interaction de scène multijoueur (MHSI)
Dans les scènes du monde réel, dans de nombreux cas, il n'y a pas qu'une seule personne qui interagit avec la scène, mais plusieurs personnes qui interagissent de manière indépendante ou associée.
Cependant, en raison du manque d'ensembles de données MHSI, les méthodes existantes nécessitent généralement des efforts manuels supplémentaires et ne peuvent pas gérer cette tâche de manière contrôlable et automatique.
À cette fin, l'auteur utilise uniquement des ensembles de données existants sur une seule personne et propose une stratégie simple et efficace pour la direction de la génération multi-personnes.
À partir d'une description textuelle liée à plusieurs personnes, l'auteur l'analyse d'abord en plusieurs graphiques de scènes locales 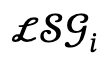 et actions interactives
et actions interactives 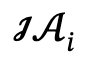 , et définit l'ensemble candidat comme
, et définit l'ensemble candidat comme 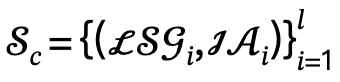 , où l est le nombre de personnes.
, où l est le nombre de personnes.
Pour chaque élément de l'ensemble candidat, il est d'abord saisi dans le Narrateur avec la scène  et le graphique de scène global correspondant
et le graphique de scène global correspondant  , puis le processus d'optimisation est effectué.
, puis le processus d'optimisation est effectué.
Afin de gérer les collisions entre les personnes, une perte supplémentaire 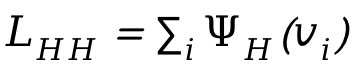 est introduite dans le processus d'optimisation, où
est introduite dans le processus d'optimisation, où 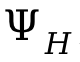 est la distance signée entre les personnes.
est la distance signée entre les personnes.
Ensuite, lorsque la perte d'optimisation est inférieure au seuil déterminé sur la base de l'expérience expérimentale, ce résultat généré est accepté et mis à jour  en ajoutant des nœuds humains ; sinon, le résultat généré est considéré comme non fiable et mis à jour
en ajoutant des nœuds humains ; sinon, le résultat généré est considéré comme non fiable et mis à jour  en protégeant le nœud objet correspondant ;
en protégeant le nœud objet correspondant ;
Il est à noter que cette méthode de mise à jour établit la relation entre les résultats de chaque génération et les résultats de la génération précédente, évite un certain degré d'encombrement, et est plus raisonnable en termes de répartition spatiale et plus interactive qu'une simple génération multiple .réaliste.
Le processus ci-dessus peut être exprimé comme suit :
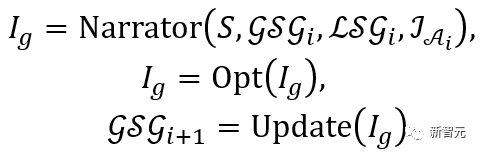
Résultats expérimentaux
Étant donné que les méthodes existantes actuelles ne peuvent pas générer naturellement et de manière contrôlable des interactions homme-scène directement à partir de descriptions textuelles, nous allons PiGraph [ 1], POSA [2], COINS [3] sont raisonnablement étendus pour fonctionner avec des descriptions textuelles et utilisent les mêmes ensembles de données pour entraîner leurs modèles officiels. Après modification, nous avons nommé ces méthodes PiGraph-Text, POSA-Text et COINS-Text
 Photos
Photos
Figure 3 Résultats de comparaison qualitative de différentes méthodes
La figure 3 montre les résultats de comparaison qualitative du Narrateur et de trois lignes de base. En raison des limitations de représentation de PiGraph-Text, il présente des problèmes de pénétration plus graves.
POSA-Text tombe souvent dans les minima locaux pendant le processus d'optimisation, ce qui entraîne de mauvais contacts interactifs. COINS-Text lie les actions à des objets spécifiques, manque de conscience globale de la scène, conduit à la pénétration d'objets non spécifiés et est difficile à gérer des relations spatiales complexes.
En revanche, le Narrateur peut raisonner correctement sur les relations spatiales en fonction de différents niveaux de descriptions textuelles et analyser les états corporels sous plusieurs actions, obtenant ainsi de meilleurs résultats de génération.
En termes de comparaison quantitative, comme le montre le tableau 1, le Narrateur surpasse les autres méthodes dans cinq indicateurs, montrant que les résultats générés par cette méthode ont une cohérence de texte plus précise et une meilleure plausibilité physique.
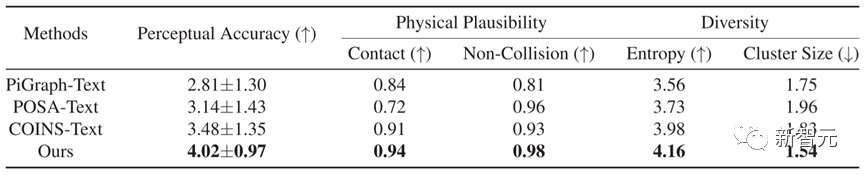 Tableau 1 Résultats de comparaison quantitative de différentes méthodes
Tableau 1 Résultats de comparaison quantitative de différentes méthodes
De plus, l'auteur fournit également une comparaison et une analyse détaillées pour mieux comprendre l'efficacité de la stratégie MHSI proposée.
Considérant qu'il n'y a actuellement aucun travail sur MHSI, ils ont choisi une approche simple comme base de référence, à savoir la génération séquentielle et l'optimisation avec COINS.
Afin de faire une comparaison équitable, une perte de collision artificielle est également introduite. La figure 4 et le tableau 2 montrent respectivement les résultats qualitatifs et quantitatifs, qui prouvent tous deux fortement que la stratégie proposée par l'auteur est sémantiquement cohérente et physiquement raisonnable sur MHSI.
 Figure 4 Comparaison qualitative avec MHSI en utilisant la méthode de génération et d'optimisation séquentielle COINS
Figure 4 Comparaison qualitative avec MHSI en utilisant la méthode de génération et d'optimisation séquentielle COINS

À propos de l'auteur

Les principales orientations de la recherche inclure une vision tridimensionnelle, Vision par ordinateur et génération d'interactions homme-scène

Principaux axes de recherche : vision tridimensionnelle, vision par ordinateur, reconstruction du corps humain et des vêtements

Les axes de recherche incluent principalement la tridimensionnalité vision, vision par ordinateur et génération d'images

La direction de recherche se concentre principalement sur la vision par ordinateur et le graphisme centrés sur l'humain

Principales directions de recherche : infographie, vision tridimensionnelle et photographie informatique
Lien de la page d'accueil personnelle : https://liuyebin.com/
[ 1] Savva M, Chang AM, Ghosh P, Tesch J, et al. Remplir des scènes 3D en apprenant l'interaction homme-scène[C]. 14718. [3] Zhao K, Wang S, Zhang Y, et al. Synthèse compositionnelle d'interactions homme-scène avec contrôle sémantique [C]. Conférence européenne sur la vision par ordinateur Cham : Springer Nature Suisse, 2022 : 311-327.
[3] Zhao K, Wang S, Zhang Y, et al. Synthèse compositionnelle d'interactions homme-scène avec contrôle sémantique [C]. Conférence européenne sur la vision par ordinateur Cham : Springer Nature Suisse, 2022 : 311-327.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment changer de scène dans les photos PS
- Quels sont les scénarios applicables pour le modèle singleton ?
- Selon différents scénarios d'application, les robots peuvent être divisés en plusieurs types
- L'équipe de Zhu Jun a ouvert le premier modèle de diffusion multimodale à grande échelle basé sur Transformer à l'Université Tsinghua, et il a été complètement achevé après la réécriture du texte et des images.
- Série recommandée de manuels d'IA intégrant l'industrie et l'éducation ‖ Baidu s'associe à la maison d'édition Tsinghua pour aider à développer les talents en IA