
Maison >Périphériques technologiques >IA >L'équipe de Zhu Jun a ouvert le premier modèle de diffusion multimodale à grande échelle basé sur Transformer à l'Université Tsinghua, et il a été complètement achevé après la réécriture du texte et des images.
L'équipe de Zhu Jun a ouvert le premier modèle de diffusion multimodale à grande échelle basé sur Transformer à l'Université Tsinghua, et il a été complètement achevé après la réécriture du texte et des images.

- PHPzavant
- 2023-05-08 20:34:081526parcourir
Il est rapporté que GPT-4 sera publié cette semaine et que la multimodalité sera l'un de ses points forts. Le grand modèle de langage actuel devient une interface universelle pour comprendre diverses modalités et peut donner des textes de réponse basés sur différentes informations modales. Cependant, le contenu généré par le grand modèle de langage se limite uniquement au texte. En revanche, les modèles de diffusion actuels DALL・E 2, Imagen, Stable Diffusion, etc. ont déclenché une révolution dans la création visuelle, mais ces modèles ne supportent qu'une seule fonction crossmodale du texte à l'image, et sont encore loin à partir d’un modèle génératif universel. Le grand modèle multimodal sera capable d'ouvrir les capacités de diverses modalités et de réaliser une conversion entre toutes les modalités, ce qui est considéré comme l'orientation future du développement des modèles génératifs universels.
L'équipe TSAIL dirigée par le professeur Zhu Jun du Département d'informatique de l'Université Tsinghua a récemment publié un article "One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale", qui a été le premier à publier des travaux d'exploration sur des modèles génératifs multimodaux sont réalisés.

Lien papier : https://ml.cs.tsinghua.edu.cn/diffusion/unidiffuser.pdf
Code source ouvert : https://github com/thu-ml/unidiffuser
Cet article propose UniDiffuser, un cadre de modélisation probabiliste conçu pour la multimodalité, et adopte l'architecture de réseau basée sur les transformateurs proposée par l'équipe U-ViT, dans le grand format open source. graphique à l'échelle Un modèle avec un milliard de paramètres a été formé sur l'ensemble de données de la littérature LAION-5B, permettant à un modèle sous-jacent d'accomplir une variété de tâches de génération avec une haute qualité (Figure 1). Pour faire simple, en plus de la génération de texte unidirectionnelle, il peut également réaliser de multiples fonctions telles que la génération d'images, la génération conjointe d'images et de texte, la génération inconditionnelle d'images et de texte, la réécriture d'images et de texte, etc., ce qui améliore considérablement la production. l'efficacité du contenu du texte et des images et améliore encore la génération de texte et de graphiques. L'imagination de l'application du modèle de formule.
Bao Fan, le premier auteur de cet article, est actuellement étudiant en doctorat. Il était le précédent proposant d'Analytic-DPM. Il a remporté le prix d'article exceptionnel de l'ICLR 2022 (actuellement le seul article primé de manière indépendante). complété par une unité continentale) pour son travail remarquable en matière de modèles de diffusion).
De plus, Machine Heart a déjà rendu compte de l'algorithme rapide DPM-Solver proposé par l'équipe TSAIL, qui reste l'algorithme de génération le plus rapide pour les modèles de diffusion. Le grand modèle multimodal est un affichage concentré de l'accumulation approfondie à long terme d'algorithmes et de principes de modèles probabilistes profonds par l'équipe. Parmi les collaborateurs de ce travail figurent Li Chongxuan de la Hillhouse School of Artificial Intelligence de l’Université Renmin, Cao Yue de l’Institut de recherche Zhiyuan de Pékin et d’autres.

Il est à noter que les documents et le code de ce projet ont été open source.
Affichage des effets
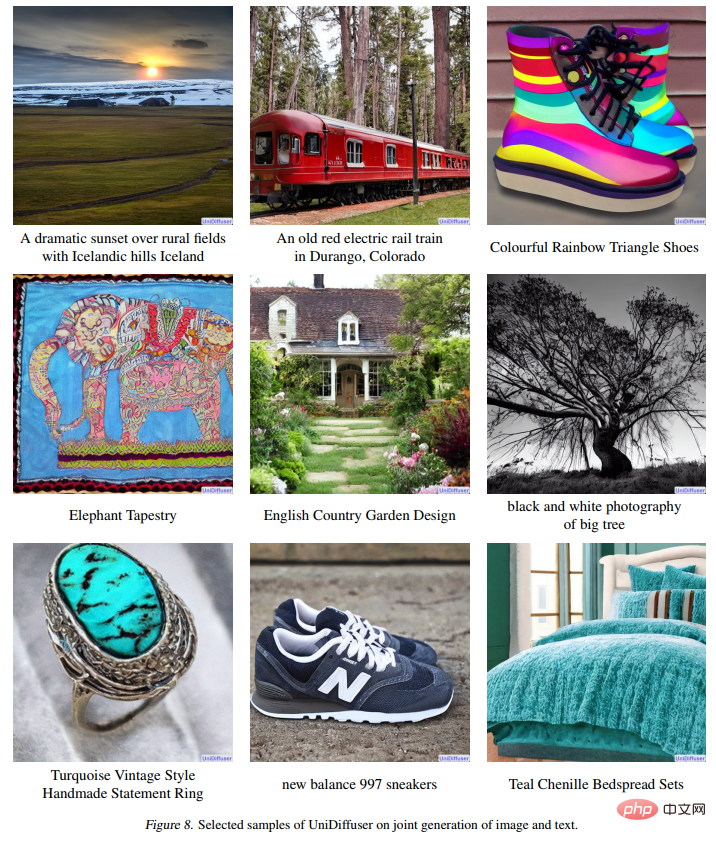
La figure 8 suivante montre l'effet d'UniDiffuser sur la génération conjointe d'images et de textes :
La figure 9 suivante montre l'effet d'UniDiffuser sur le texte à image génération :

La figure 10 suivante montre l'effet d'UniDiffuser sur l'image en texte :

La figure 11 suivante montre l'effet d'UniDiffuser sur la génération d'images inconditionnelles :

La figure 12 ci-dessous montre l'effet d'UniDiffuser sur la réécriture d'images : 🎜# La figure 15 ci-dessous montre qu'UniDiffuser peut passer d'un mode graphique à un mode texte :
La figure 16 ci-dessous montre qu'UniDiffuser peut interpoler deux images réelles : 
L'équipe de recherche a divisé la conception du modèle génératif général en deux sous-problèmes :

Architecture réseau : une architecture réseau unifiée peut-elle être conçue pour prendre en charge diverses modalités d'entrée ?
Cadre de modélisation probabiliste
- pour la modélisation de probabilités cadre, l'équipe de recherche propose UniDiffuser, un cadre de modélisation probabiliste basé sur le modèle de diffusion. UniDiffuser peut modéliser explicitement toutes les distributions dans des données multimodales, y compris les distributions marginales, les distributions conditionnelles et les distributions conjointes. L'équipe de recherche a découvert que l'apprentissage du modèle de diffusion sur différentes distributions peut être unifié dans une seule perspective : d'abord ajouter une certaine taille de bruit aux données des deux modalités, puis prédire le bruit sur les données des deux modalités. La quantité de bruit sur les deux données modales détermine la distribution spécifique. Par exemple, régler la taille du bruit du texte à 0 correspond à la distribution conditionnelle du diagramme vincentien ; régler la taille du bruit du texte à la valeur maximale correspond à la distribution de la génération d'image inconditionnelle et ; un texte de même valeur correspond à la répartition de la génération inconditionnelle d'images. Distribution conjointe d'images et de textes. Selon cette perspective unifiée, UniDiffuser n'a besoin que d'apporter de légères modifications à l'algorithme d'entraînement du modèle de diffusion d'origine pour apprendre toutes les distributions ci-dessus en même temps - comme le montre la figure ci-dessous, UniDiffuser ajoute du bruit à tous les modes en même temps. au lieu d'un seul mode, saisissez l'amplitude du bruit correspondant à tous les modes et le bruit prédit sur tous les modes.
En prenant le mode bimodal comme exemple, la fonction objectif final de l'entraînement est la suivante suit Afficher:
où 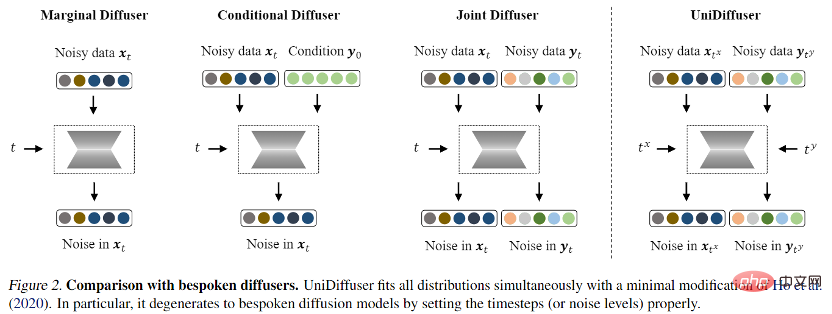
représente les données,
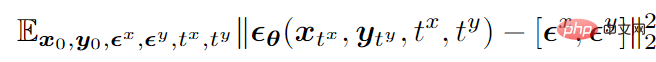
# 🎜 🎜#
représente le bruit gaussien standard ajouté aux deux modes,
représente la quantité de bruit ajoutée par les deux modes (c'est-à-dire le temps). Les deux sont échantillonnés indépendamment à partir de {1,2,…,T},
#🎜. 🎜#
est un réseau de prédiction du bruit qui prédit le bruit sur deux modes en même temps.
Après la formation, UniDiffuser est capable de réaliser une génération inconditionnelle, conditionnelle et conjointe en définissant l'heure appropriée pour les deux modes sur le réseau de prédiction du bruit. Par exemple, définir l'heure du texte sur 0 peut réaliser une génération de texte à image ; définir l'heure du texte sur la valeur maximale peut obtenir une génération d'image inconditionnelle ; génération conjointe d’images et de textes.
Les algorithmes de formation et d'échantillonnage d'UniDiffuser sont répertoriés ci-dessous. On peut voir que ces algorithmes n'ont apporté que des modifications mineures par rapport au modèle de diffusion d'origine et sont faciles à mettre en œuvre.

De plus, étant donné qu'UniDiffuser modélise à la fois les distributions conditionnelles et inconditionnelles, UniDiffuser prend naturellement en charge le guidage sans classificateur. La figure 3 ci-dessous montre l'effet de la génération conditionnelle et de la génération conjointe d'UniDiffuser sous différentes échelles de guidage :

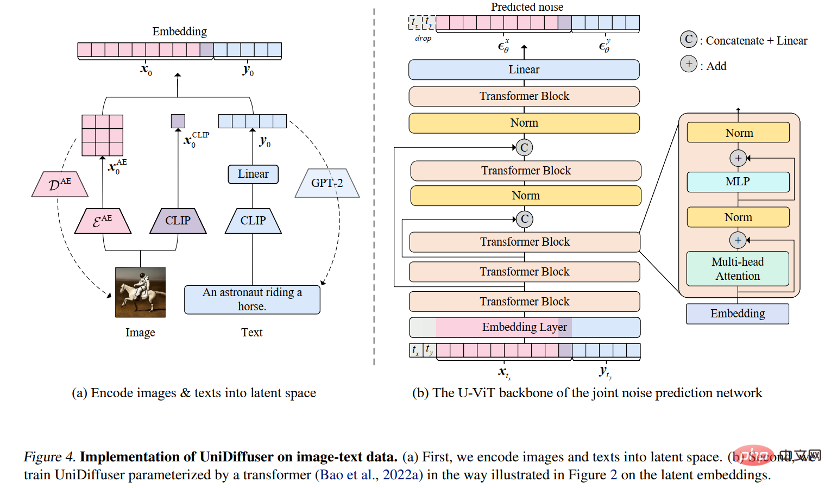
Architecture de réseau
Pour l'architecture de réseau, l'équipe de recherche a proposé d'utiliser une architecture basée sur un transformateur. paramétrer les réseaux de prédiction du bruit. Plus précisément, l’équipe de recherche a adopté l’architecture U-ViT récemment proposée. U-ViT traite toutes les entrées comme des jetons et ajoute des connexions en forme de U entre les blocs de transformateur. L’équipe de recherche a également adopté la stratégie de diffusion stable pour convertir les données de différentes modalités en espace latent, puis modéliser le modèle de diffusion. Il convient de noter que l'architecture U-ViT provient également de cette équipe de recherche et est open source sur https://github.com/baofff/U-ViT.
Résultats expérimentaux
UniDiffuser d'abord comparé à Versatile Diffusion. Versatile Diffusion est un ancien modèle de diffusion multimodale basé sur un cadre multitâche. Tout d’abord, UniDiffuser et Versatile Diffusion ont été comparés sur les effets texte-image. Comme le montre la figure 5 ci-dessous, UniDiffuser est meilleur que Versatile Diffusion en termes de score CLIP et de métriques FID selon différentes échelles de guidage sans classificateur.
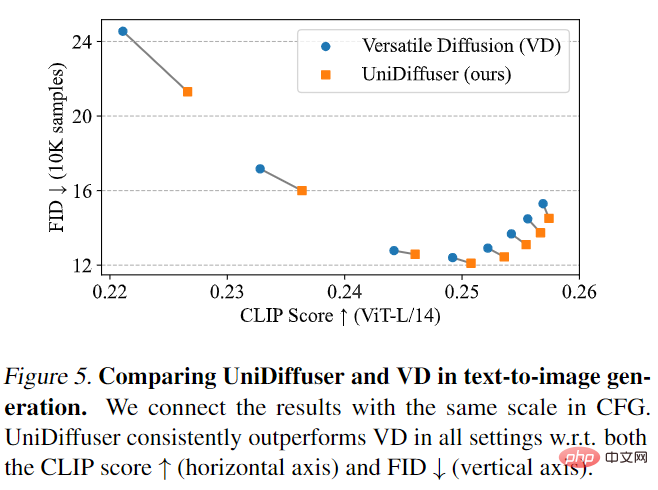
Ensuite, UniDiffuser et Versatile Diffusion ont effectué une comparaison des effets image-texte. Comme le montre la figure 6 ci-dessous, UniDiffuser a un meilleur score CLIP en matière de conversion image-texte.
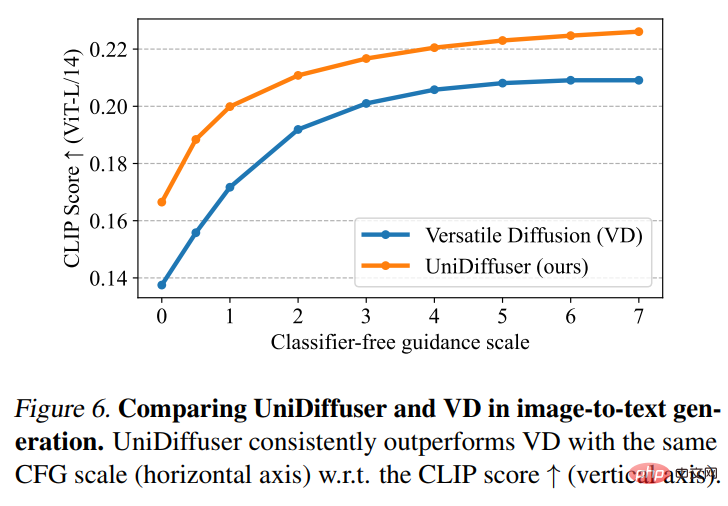
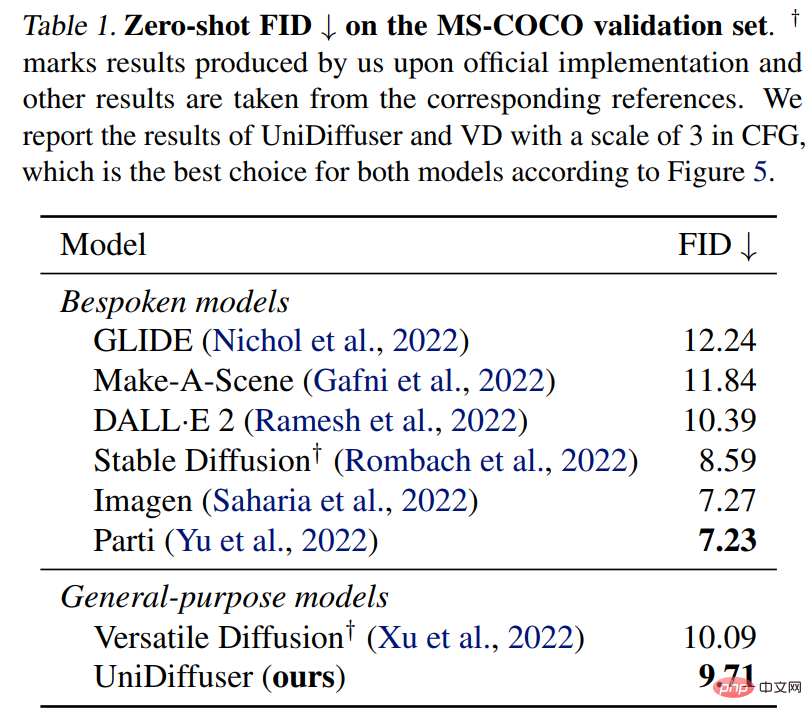
UniDiffuser est également comparé à un modèle texte-graphique dédié pour le FID zéro tir sur MS-COCO. Comme le montre le tableau 1 ci-dessous, UniDiffuser peut obtenir des résultats comparables à ceux des modèles texte-graphique dédiés.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI