
Maison >développement back-end >Tutoriel Python >Utilisez un robot d'exploration Web Python pour voir quels films sont actuellement diffusés dans les salles de cinéma
Utilisez un robot d'exploration Web Python pour voir quels films sont actuellement diffusés dans les salles de cinéma
- Go语言进阶学习avant
- 2023-07-25 17:21:572075parcourir
/1 Avant-propos/

/2 Objectif du projet/
Obtenez les détails des films à venir de Maoyan Movies.
/3 Préparation du projet/
Logiciel : PyCharm
Bibliothèques requises : re quêtes、lxml、aléatoire、 temps
Plug-in : https://maoyan.com/films?showType=2&offset={}
Lorsque vous cliquez sur la page suivante, le offset=() augmente de 30 pour chaque page supplémentaire, vous pouvez donc utiliser {} pour remplacer la variable transformée, puis utilisez une boucle for pour parcourir l'URL afin d'implémenter plusieurs requêtes d'URL.
1. Définir une classe pour hériter de l'objet, définir la méthode d'initialisation pour hériter de soi et la fonction principale main hériter de soi. Importez les bibliothèques et URL requises, le code est le suivant.
import requests
from lxml import etree
import time
import random
class MaoyanSpider(object):
def __init__(self):
self.url = "https://maoyan.com/films?showType=2&offset={}"
def main(self):
pass
if __name__ == '__main__':
spider = MaoyanSpider()
spider.main()2、随机产生UserAgent。
for i in range(1, 50):
# ua.random,一定要写在这里,每次请求都会随机选择。
self.headers = {
'User-Agent': ua.random,
}3、发送请求,获取页面响应。
def get_page(self, url): # random.choice一定要写在这里,每次请求都会随机选择 res = requests.get(url, headers=self.headers) res.encoding = 'utf-8' html = res.text self.parse_page(html)
4、xpath解析一级页面数据,获取页面信息。
1)基准xpath节点对象列表。
# 创建解析对象 parse_html = etree.HTML(html) # 基准xpath节点对象列表 dd_list = parse_html.xpath('//dl[@class="movie-list"]//dd')
2)依次遍历每个节点对象,提取数据。
for dd in dd_list:
name = dd.xpath('.//div[@class="movie-hover-title"]//span[@class="name noscore"]/text()')[0].strip()
star = dd.xpath('.//div[@class="movie-hover-info"]//div[@class="movie-hover-title"][3]/text()')[1].strip()
type = dd.xpath('.//div[@class="movie-hover-info"]//div[@class="movie-hover-title"][2]/text()')[1].strip()
dowld=dd.xpath('.//div[@class="movie-item-hover"]/a/@href')[0].strip()
# print(movie_dict)
movie = '''【即将上映】5、定义movie,保存打印数据。
movie = '''【即将上映】
电影名字: %s
主演:%s
类型:%s
详情链接:https://maoyan.com%s
=========================================================
''' % (name, star, type,dowld)
print( movie)6、random.randint()方法,设置时间延时。
time.sleep(random.randint(1, 3))
7、调用方法,实现功能。
html = self.get_page(url) self.parse_page(html)
/5 Affichage des effets/
1 Cliquez sur le triangle vert pour exécuter la page de début et la page de fin de saisie.
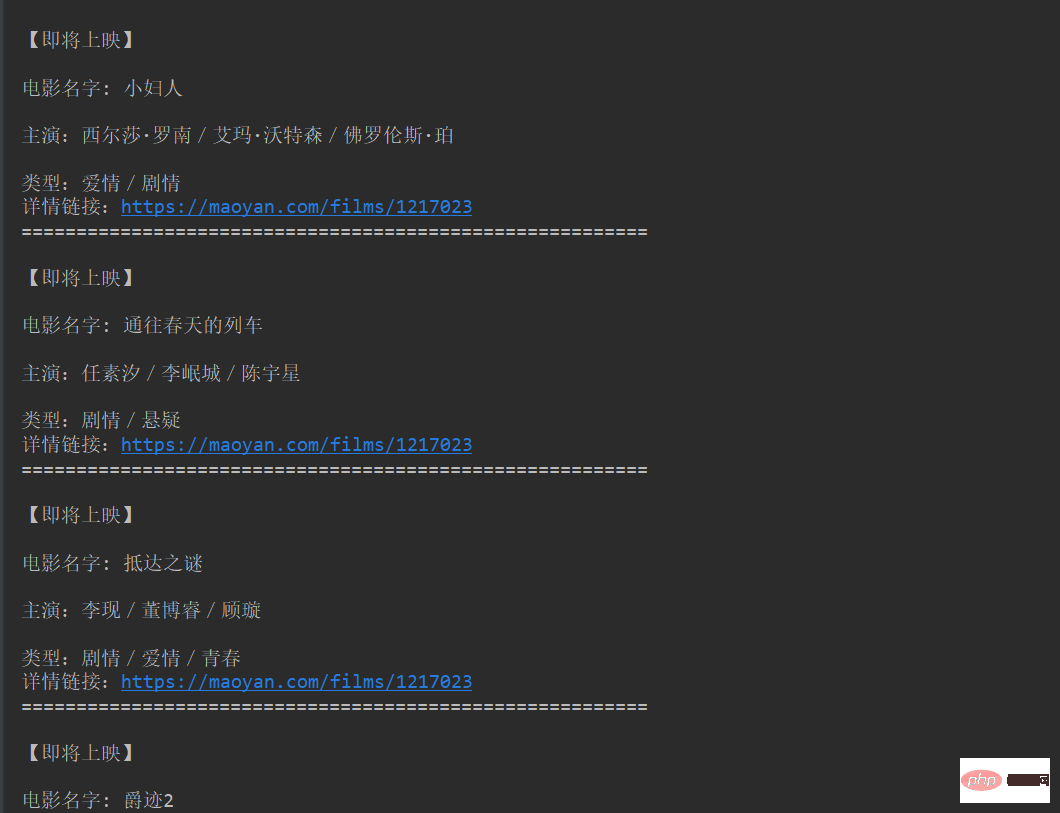
2. Après avoir exécuté le programme, les résultats sont affichés sur la console, comme indiqué dans la figure ci-dessous.
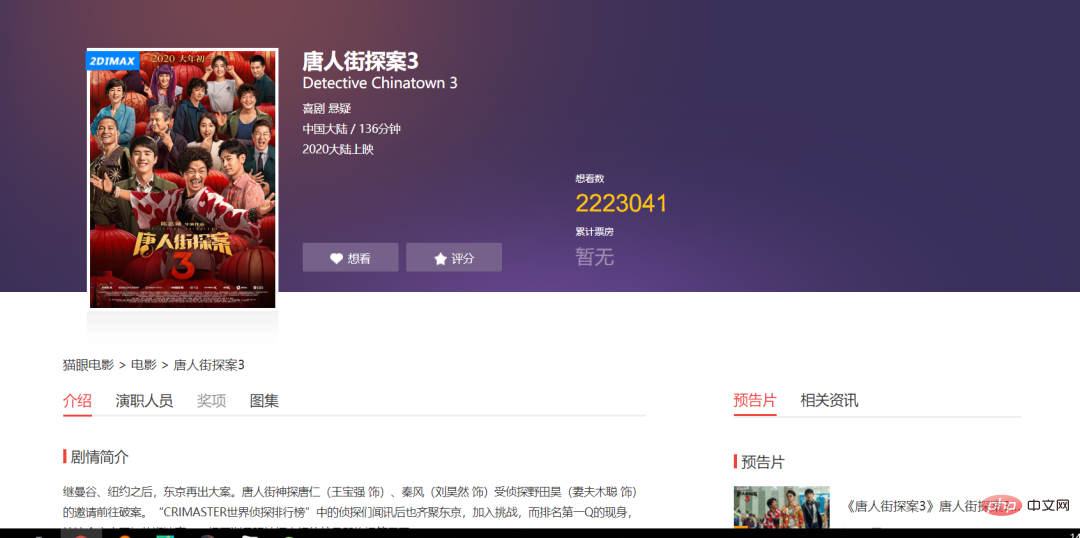
3. Cliquez sur le lien de téléchargement bleu pour afficher les détails en ligne.
/6 Résumé/
1. Essayez-le brièvement.
2. Cet article est basé sur le robot d'exploration Web Python et utilise la bibliothèque de robots pour explorer les films Maoyan.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Un article pour vous aider à comprendre les fonctions récursives de Python
- Un article pour vous aider à comprendre les connaissances en itération de Python
- Un article vous guidera à travers les fonctions de retour Python
- Inventaire des utilisations courantes de dict et set dans la programmation Python
- Inventaire de 7 fonctions couramment utilisées dans la bibliothèque sys du langage de programmation Python