
Maison >Périphériques technologiques >IA >Compréhension du monde ouvert des nuages de points 3D, de la classification, de la récupération, des sous-titres et de la génération d'images
Compréhension du monde ouvert des nuages de points 3D, de la classification, de la récupération, des sous-titres et de la génération d'images

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-04 15:04:041518parcourir
Entrez les formes tridimensionnelles d'une chaise à bascule et d'un cheval. Que pouvez-vous obtenir ?


Chariot en bois plus cheval ? Avoir une calèche et un cheval électrique ; une banane et un voilier ? Obtenir un voilier banane, des œufs et des transats ? Obtenez la chaise œuf.
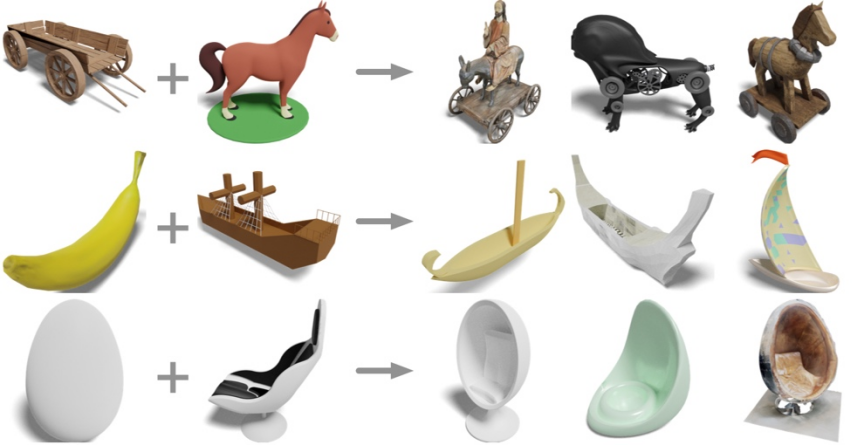
Des chercheurs de l'UCSD, de l'Université Jiao Tong de Shanghai et des équipes de Qualcomm ont proposé le dernier modèle de représentation tridimensionnelle OpenShape, permettant de comprendre le monde ouvert des formes tridimensionnelles.
- Adresse papier : https://arxiv.org/pdf/2305.10764.pdf
- Page d'accueil du projet : https://colin97.github .io/OpenShape /
- Démo interactive : https://huggingface.co/spaces/OpenShape/openshape-demo
- Adresse du code : https://github.com/ Colin97/OpenShape_code
En apprenant un encodeur natif de nuages de points 3D sur des données multimodales (nuage de points - texte - image), OpenShape construit un espace de représentation de formes 3D et intègre du texte et des images avec CLIP Les espaces sont alignés. Grâce à une pré-formation 3D diversifiée et à grande échelle, OpenShape parvient pour la première fois à une compréhension en monde ouvert des formes 3D, en prenant en charge la classification des formes 3D sans tir, la récupération de formes 3D multimodale (saisie texte/image/nuage de points), et sous-titres de nuages de points 3D Tâches multimodales telles que la génération d'images et la génération d'images basées sur des nuages de points 3D.
Classification de forme 3D sans tir
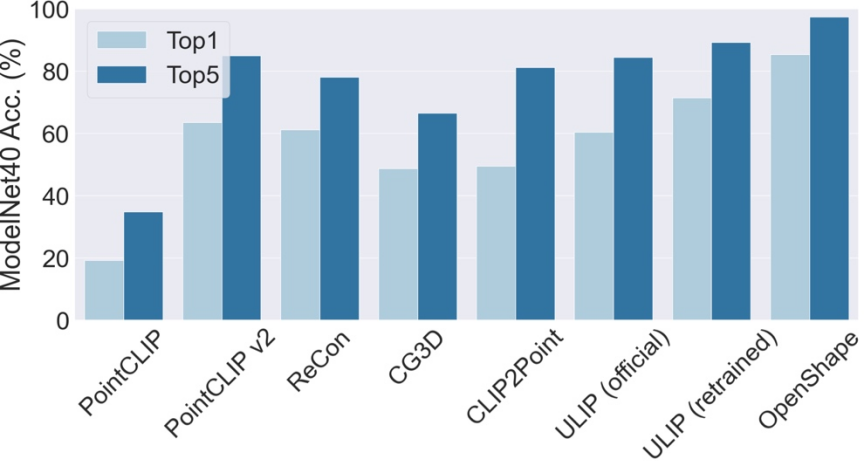
OpenShape prend en charge la classification de forme 3D sans tir. Sans formation supplémentaire ni réglage fin, OpenShape atteint une précision top1 de 85,3 % sur le benchmark ModelNet40 couramment utilisé (comprenant 40 catégories communes), dépassant les méthodes de tir zéro existantes de 24 points de pourcentage et atteignant des performances comparables à certaines méthodes entièrement supervisées pour la première fois.
La précision top3 et top5 d'OpenShape sur ModelNet40 a atteint respectivement 96,5 % et 98,0 %.
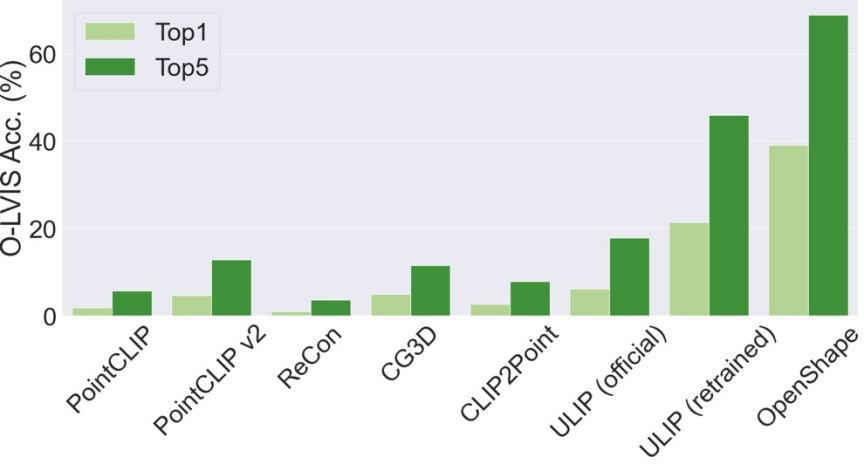
Contrairement aux méthodes existantes qui se limitent principalement à quelques catégories d'objets courantes, OpenShape est capable de classer un large éventail de catégories du monde ouvert. Sur le benchmark Objaverse-LVIS (contenant 1 156 catégories d'objets), OpenShape atteint une précision top1 de 46,8 %, dépassant de loin la précision la plus élevée de seulement 6,2 % des méthodes de tir zéro existantes. Ces résultats montrent qu'OpenShape a la capacité de reconnaître efficacement les formes 3D dans le monde ouvert.
Récupération de forme 3D multimodale
Avec la représentation multimodale d'OpenShape, les utilisateurs peuvent effectuer une récupération de forme 3D sur une entrée d'image, de texte ou de nuage de points. Étudiez la récupération de formes 3D à partir d'ensembles de données intégrés en calculant la similarité cosinus entre la représentation d'entrée et la représentation de forme 3D et en trouvant kNN.

Récupération de forme tridimensionnelle à partir de l'entrée d'image
L'image ci-dessus montre l'image d'entrée et deux formes 3D récupérées.

Récupération de forme tridimensionnelle pour la saisie de texte
La figure ci-dessus montre le texte saisi et la forme tridimensionnelle récupérée. OpenShape apprend un large éventail de concepts visuels et sémantiques, permettant un contrôle précis des sous-catégories (deux premières lignes) et des attributs (les deux dernières lignes, telles que la couleur, la forme, le style et leurs combinaisons). La figure ci-dessus montre le nuage de points 3D d'entrée et deux formes 3D récupérées. L'image ci-dessus prend deux formes 3D en entrée et utilise leur représentation OpenShape pour récupérer la forme simultanée la plus proche des deux entrées trois- forme dimensionnelle. La forme récupérée combine intelligemment les éléments sémantiques et géométriques des deux formes d'entrée.
Génération de texte et d'image basée sur des formes 3D
Étant donné que la représentation de forme 3D d'OpenShape est alignée sur l'espace de représentation d'image et de texte de CLIP, elles peuvent être combinées avec de nombreux modèles dérivés basés sur CLIP pour prendre en charge une variété d'applications multimodales.
Génération de sous-titres pour les nuages de points 3D
En combinant avec le modèle de sous-titres d'image prêt à l'emploi (ClipCap), OpenShape implémente la génération de sous-titres pour les nuages de points 3D.

Génération d'images basée sur un nuage de points 3D
En combinant avec le modèle de diffusion texte-image prêt à l'emploi (Stable unCLIP), OpenShape implémente la génération d'images basée sur un nuage de points 3D (invite de texte facultative prise en charge).

Plus d'exemples de génération d'images basés sur des nuages de points 3D
Détails de la formation Alignement des représentations multimodales basé sur l'apprentissage contrastif :
OpenShape formé a 3D Un encodeur natif qui prend un nuage de points 3D en entrée pour extraire une représentation de la forme 3D. Suite à des travaux antérieurs, nous exploitons l'apprentissage contrastif multimodal pour nous aligner sur les espaces de représentation d'images et de texte de CLIP. Contrairement aux travaux précédents, OpenShape vise à apprendre un espace de représentation conjointe plus général et évolutif. L'objectif de la recherche est principalement d'élargir l'échelle de l'apprentissage de la représentation 3D et de relever les défis correspondants, afin de véritablement comprendre les formes 3D dans le monde ouvert.
Intégration de plusieurs ensembles de données de formes 3D : Étant donné que l'échelle et la diversité des données d'entraînement jouent un rôle crucial dans l'apprentissage des représentations de formes 3D à grande échelle, l'étude a été menée en intégrant quatre des plus grands ensembles de données de formes 3D publics actuellement. Comme le montre la figure ci-dessous, les données d'entraînement étudiées contiennent 876 000 formes d'entraînement. Parmi les quatre ensembles de données, ShapeNetCore, 3D-FUTURE et ABO contiennent des formes 3D de haute qualité vérifiées par l'homme, mais ne couvrent qu'un nombre limité de formes et des dizaines de catégories. L'ensemble de données Objaverse est un ensemble de données 3D récemment publié qui contient beaucoup plus de formes 3D et couvre une classe d'objets plus diversifiée. Cependant, les formes de l'Objaverse sont principalement téléchargées par les internautes et n'ont pas été vérifiées manuellement. Par conséquent, la qualité est inégale et la répartition est extrêmement inégale, nécessitant un traitement ultérieur. 
Filtrage et enrichissement du texte : Une étude a révélé que l'application d'un apprentissage contrastif uniquement entre des formes 3D et des images 2D n'est pas suffisante pour piloter l'alignement des formes 3D et des espaces de texte, même lorsqu'elle est effectuée sur des ensembles de données à grande échelle. Il en va de même pour la formation. La recherche suppose que cela est dû à l'écart de domaine inhérent aux espaces de représentation du langage et des images de CLIP. Par conséquent, la recherche doit aligner explicitement les formes 3D avec le texte. Cependant, les annotations de texte provenant d'ensembles de données 3D originaux sont souvent confrontées à des problèmes tels qu'un contenu manquant, erroné ou approximatif et unique. À cette fin, cet article propose trois stratégies pour filtrer et enrichir le texte afin d'améliorer la qualité de l'annotation du texte : le filtrage de texte à l'aide de GPT-4, la génération de sous-titres et la récupération d'images de rendus 2D de modèles 3D. L'étude propose trois stratégies pour filtrer et enrichir automatiquement le texte bruité dans les ensembles de données originaux.
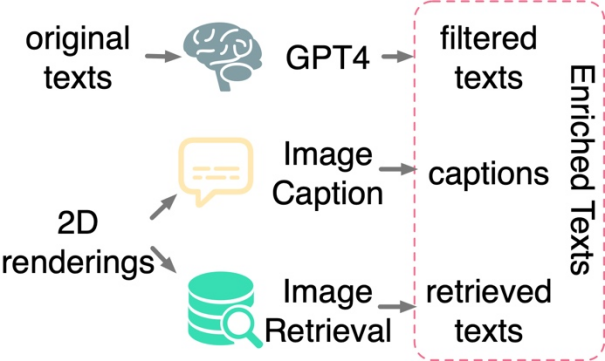
Exemples de filtrage et d'enrichissement de texte
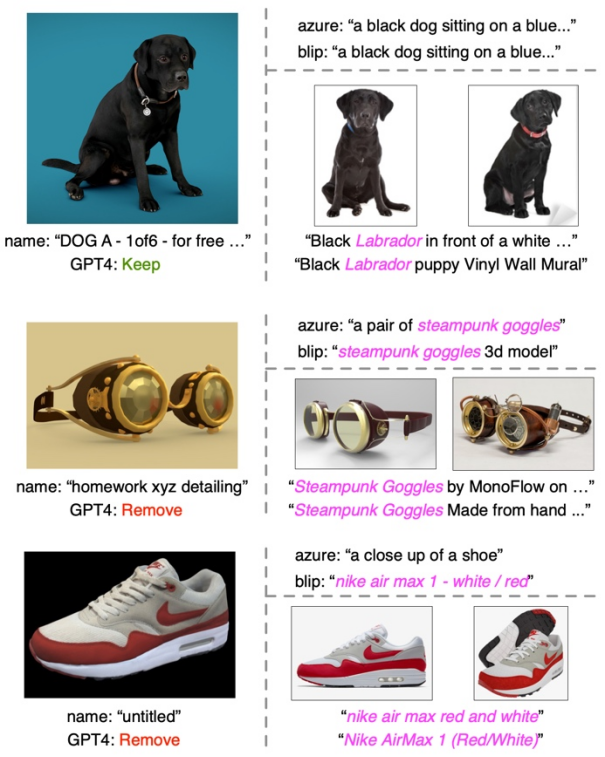 Dans chaque exemple, la partie gauche affiche la vignette, le nom de la forme originale et les résultats filtrés pour GPT-4. La partie supérieure droite montre les légendes des images des deux modèles de sous-titres, tandis que la partie inférieure droite montre les images récupérées et leur texte correspondant.
Dans chaque exemple, la partie gauche affiche la vignette, le nom de la forme originale et les résultats filtrés pour GPT-4. La partie supérieure droite montre les légendes des images des deux modèles de sous-titres, tandis que la partie inférieure droite montre les images récupérées et leur texte correspondant.
Développez le réseau fédérateur tridimensionnel. Étant donné que les travaux précédents sur l'apprentissage des nuages de points 3D ciblaient principalement des ensembles de données 3D à petite échelle comme ShapeNet, ces réseaux fédérateurs peuvent ne pas être directement applicables à notre formation 3D à grande échelle, et l'échelle du réseau fédérateur doit être étendue en conséquence. L'étude a révélé que différents réseaux fédérateurs 3D présentent des comportements et une évolutivité différents lorsqu'ils sont formés sur des ensembles de données de différentes tailles. Parmi eux, PointBERT basé sur Transformer et SparseConv basé sur la convolution tridimensionnelle présentent des performances et une évolutivité plus puissantes, ils ont donc été sélectionnés comme réseau fédérateur tridimensionnel.
Comparaison des performances et de l'évolutivité de différents réseaux fédérateurs lors de la mise à l'échelle de la taille du modèle fédérateur 3D sur l'ensemble de données intégré.
Exploration d'exemples négatifs durs : 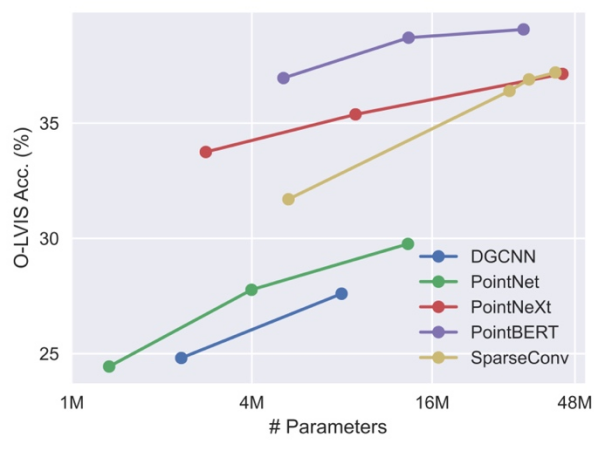 L'ensemble de données d'ensemble de cette étude présente un degré élevé de déséquilibre de classes. Certaines catégories courantes, comme l'architecture, peuvent occuper des dizaines de milliers de formes, tandis que de nombreuses autres catégories, comme les morses et les portefeuilles, sont sous-représentées avec seulement quelques dizaines de formes, voire moins. Par conséquent, lorsque des lots sont construits de manière aléatoire pour un apprentissage contrasté, il est peu probable que des formes provenant de deux catégories facilement confondues (par exemple, pommes et cerises) apparaissent dans le même lot pour être contrastées. À cette fin, cet article propose une stratégie d'exploration d'exemples négatifs difficiles hors ligne pour améliorer l'efficacité et les performances de la formation.
L'ensemble de données d'ensemble de cette étude présente un degré élevé de déséquilibre de classes. Certaines catégories courantes, comme l'architecture, peuvent occuper des dizaines de milliers de formes, tandis que de nombreuses autres catégories, comme les morses et les portefeuilles, sont sous-représentées avec seulement quelques dizaines de formes, voire moins. Par conséquent, lorsque des lots sont construits de manière aléatoire pour un apprentissage contrasté, il est peu probable que des formes provenant de deux catégories facilement confondues (par exemple, pommes et cerises) apparaissent dans le même lot pour être contrastées. À cette fin, cet article propose une stratégie d'exploration d'exemples négatifs difficiles hors ligne pour améliorer l'efficacité et les performances de la formation.
Bienvenue pour essayer la démo interactive sur HuggingFace.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI