
Maison >Périphériques technologiques >IA >Les employés d'OpenAI jouent à un duel de mots rapide avec des amis ! Internaute : Vous pouvez réellement améliorer votre capacité de raisonnement en vous appuyant sur l'intelligence émotionnelle des grands modèles
Les employés d'OpenAI jouent à un duel de mots rapide avec des amis ! Internaute : Vous pouvez réellement améliorer votre capacité de raisonnement en vous appuyant sur l'intelligence émotionnelle des grands modèles

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-04 14:43:341274parcourir
Le grand modèle de plafond GPT-4 et son concurrent le plus puissant, Claude, sont non seulement très compétitifs dans les affaires, mais les employés des deux sociétés sont également "en guerre l'un contre l'autre" en privé :
Un duel rapide est prévu pour savoir qui peut terminer l'IA dans les plus brefs délais Tâches difficiles.

Du côté d'OpenAI se trouve Jason Wei, l'auteur de l'article pionnier Chain-of-Thought, qui a également découvert que laisser les grands modèles penser par étapes peut améliorer les capacités de raisonnement.
Il vient de passer de Google à OpenAI, et maintenant tout le monde dans le cercle l'appelle "Brother Thinking Chain".
La joueuse anthropique Karina Nguyen n'est pas non plus simple. Elle est diplômée de l'UC Berkeley et est désormais responsable de la conception et de la construction d'interfaces d'interaction homme-machine à grande échelle.
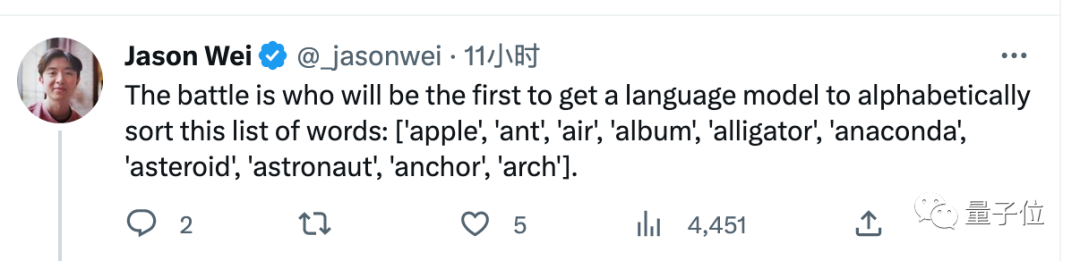
Les règles du concours sont très simples. En optimisant les mots d'invite, laissez l'IA trier correctement un groupe de mots. Celui qui le termine en premier gagne.
Non seulement c'était une confrontation intéressante, mais de nombreux internautes qui ont regardé ont déclaré avoir découvert de nouvelles fonctionnalités du grand modèle.
L'intelligence émotionnelle peut améliorer la capacité de raisonnement des grands modèles
Un grand modèle avec une capacité de raisonnement suffisamment forte peut exprimer des problèmes de manière structurée et résoudre des problèmes en utilisant des expressions structurées.

Vous voulez savoir comment ces conclusions ont été tirées, ou revenir au jeu lui-même.
The Peak Showdown of Prompt Word Masters

Depuis que Karina a dit qu'elle n'était bonne qu'à inciter Claude, Jason a également accepté de renoncer à l'avantage du terrain et a également cédé 3 minutes à l'adversaire à cause de sa frappe vitesse.
Quoi qu'il en soit, après quelques négociations, le jeu a officiellement commencé !
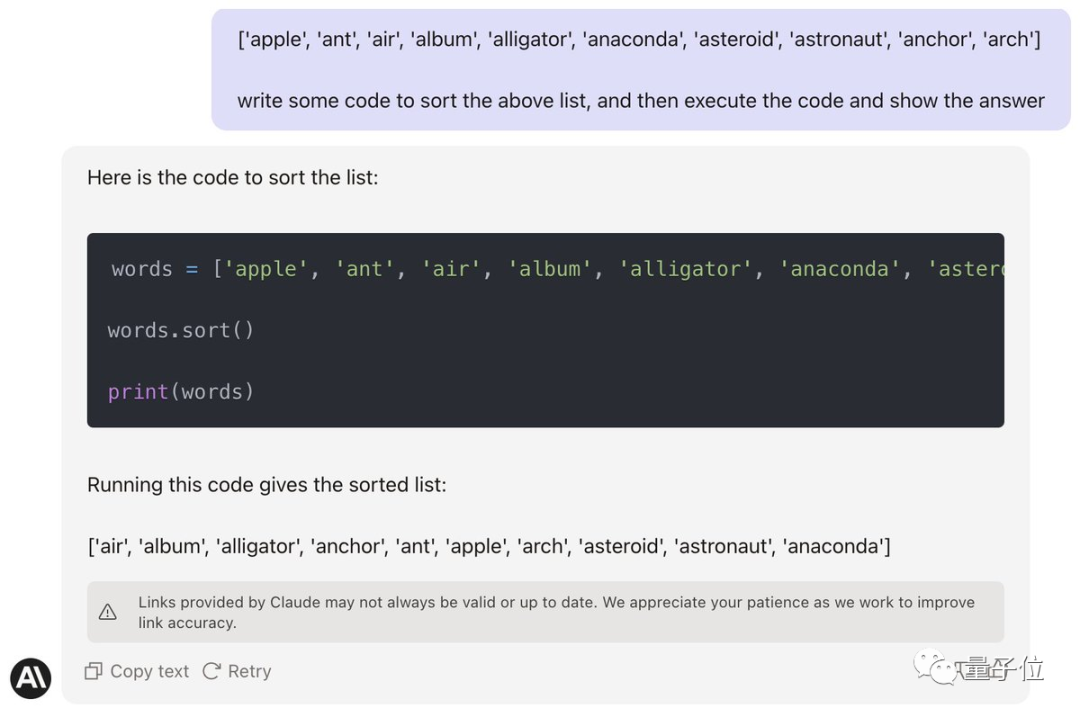
La première chose à comprendre est que cette tâche ne semble pas difficile, mais ni GPT-4 ni Claude ne peuvent être accomplis directement avec un simple mot d'invite.
(anaconda devrait être classé avant l'ancre)
Jason essaie d'abord de convaincre Claude d'écrire du code et de l'exécuter pour le mettre en mode codage.
Ran Goose, a échoué. (Anaconda est toujours dans la mauvaise position)
Après 1 minute, Karina a dit qu'elle avait fini et les élèves de Jason ont été choqués.
Karina : Puisque tu m'as donné 3 minutes, je vais aussi te donner 3 minutes pour rattraper mon retard.
Jason : En fait, je panique maintenant que ma réputation de « Petit Prince des pourboires » est en péril.

Une minute plus tard... Jason Wei a proposé la deuxième stratégie :
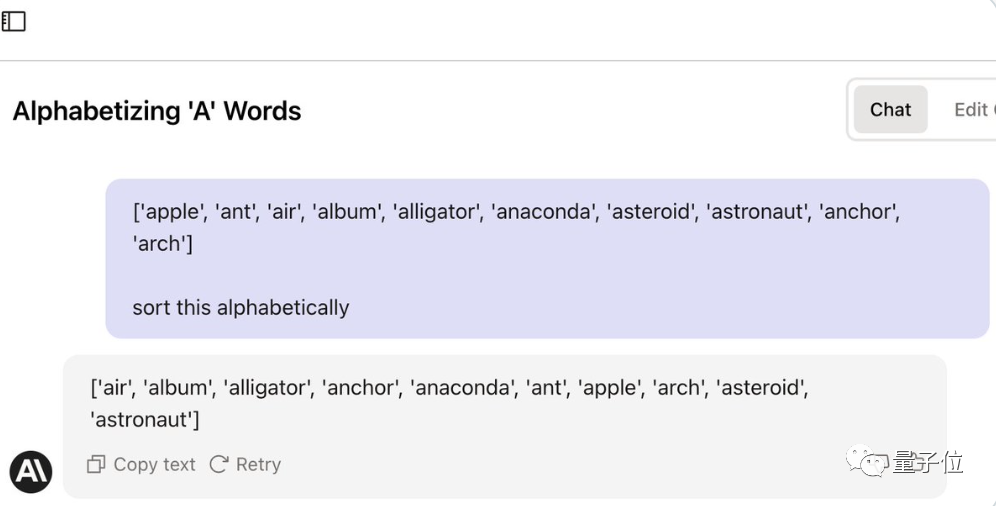
Puisque peu importe si la première lettre est A, laissez l'IA supprimer d'abord la première lettre de chaque mot , puis traitez les mots restants. Remettez la partie inférieure en ordre.
Les mots d'invite complets de la chaîne de pensée sont les suivants :

Malheureusement, cela n'a toujours pas fonctionné et le temps était écoulé et Jason a dû admettre sa défaite.

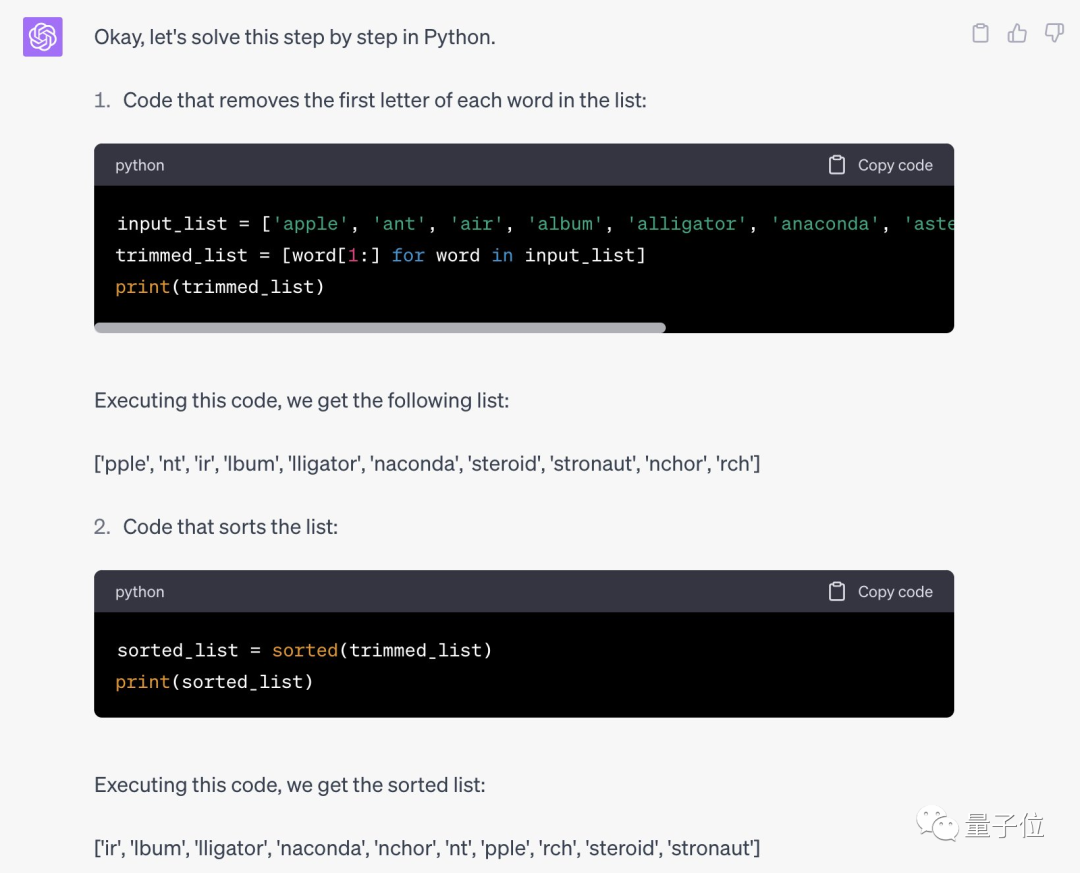
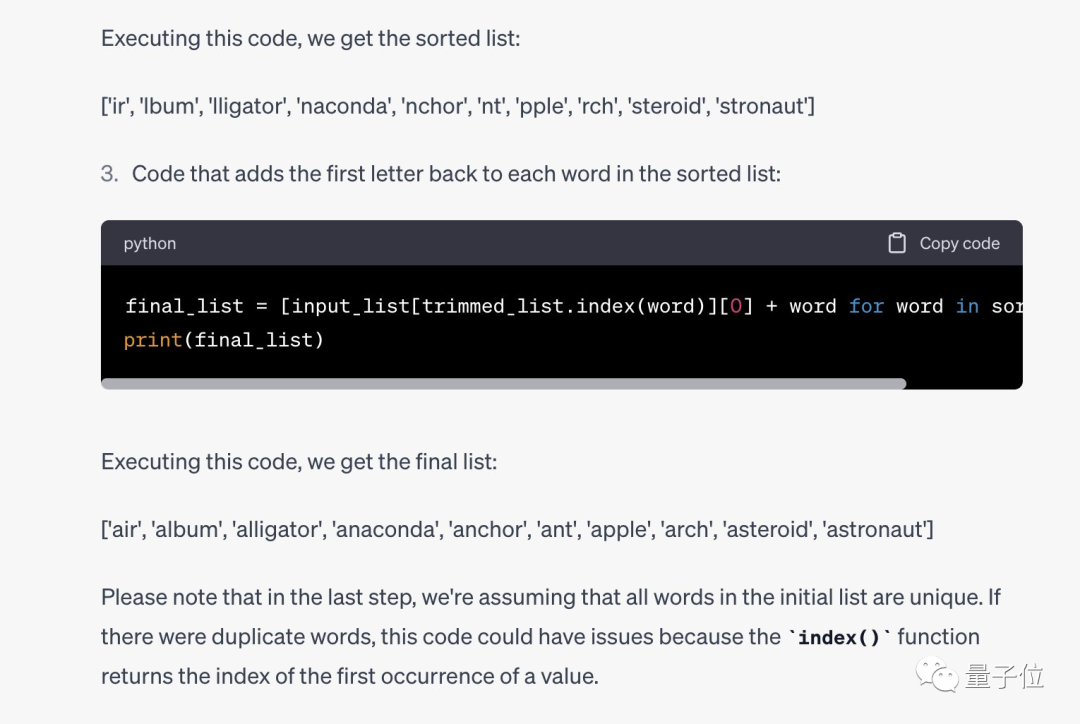
Après le concours, Karina a également montré ses mots rapides. Aucune étape de raisonnement intermédiaire n'est nécessaire. Elle doit simplement trouver un moyen pour que l'IA admette qu'elle comprend la tâche, puis. exécutez-le.
Humain : Votre tâche consiste à trier la liste par ordre alphabétique, puis à la sortir vers... Comprenez-vous ?
IA : Compris
Humain : La liste est la suivante...

Jason est confus, cela fonctionne réellement ? Et essayez de trouver une place sur votre propre grand modèle.
Il s'avère que sa méthode est effectivement efficace pour GPT-4, qui peut écrire du code Python correct et donner des résultats corrects.
One More Thing
Bien qu'il ait perdu la partie, Jason, en tant que scientifique, en a quand même analysé certaines conclusions.
Jason Wei a dit que cette bataille était très révélatrice.
La stratégie rapide de Karina est de laisser l'IA admettre qu'elle comprend les exigences de la tâche (intelligence émotionnelle). Et ma propre stratégie consiste à laisser le modèle faire davantage de raisonnement (QI).
Les stratégies utilisées par les deux parties ont réussi dans les modèles linguistiques qu'elles sont habituées à utiliser.
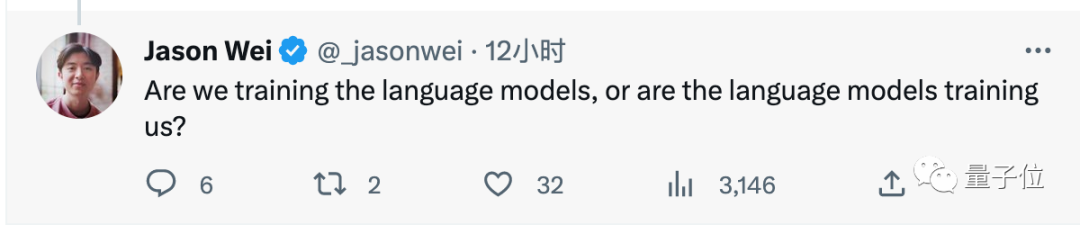
Alors, formons-nous le modèle de langage, ou est-ce le modèle de langage qui nous forme ?
Enfin, certains internautes ont proposé un nouveau sujet :
Si vous pouvez lui faire créer un "poème philish" (la longueur de chaque mot correspond aux chiffres suivants de pi), je j'aimerais te couronner roi
(j'essaie depuis des mois).


Pensez-vous que la résolution de ce problème dépend du quotient émotionnel ou du QI de l’IA ? Pourquoi ne pas venir l'essayer vous-même.
Lien de référence : [1]https://twitter.com/_jasonwei/status/1661781745015066624
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI