
Maison >développement back-end >Tutoriel Python >Comment appliquer le multi-processus Python
Comment appliquer le multi-processus Python

- PHPzavant
- 2023-05-25 09:28:051616parcourir
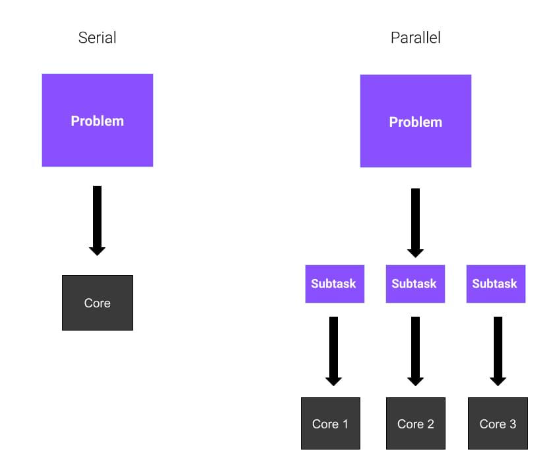
Informatique parallèle et série
Imaginez que vous avez un énorme problème à résoudre et que vous êtes seul. Vous devez calculer les racines carrées de huit nombres différents. Que fais-tu? Vous n'avez pas beaucoup de choix. Commencez par le premier nombre et calculez le résultat. Ensuite, vous passez à d'autres personnes.
Et si vous avez trois amis bons en mathématiques et prêts à vous aider ? Chacun d'eux calculera la racine carrée de deux nombres et votre travail sera plus facile car la charge de travail est répartie également entre vos amis. Cela signifie que votre problème sera résolu plus rapidement.
D'accord, tout est clair ? Dans ces exemples, chaque ami représente un cœur du CPU. Dans le premier exemple, vous résolvez l’ensemble de la tâche de manière séquentielle. C'est ce qu'on appelle le Calcul sériel. Dans le deuxième exemple, puisque vous utilisez un total de quatre cœurs, vous utilisez l'informatique parallèle. L'informatique parallèle implique l'utilisation de processus parallèles ou de processus répartis entre plusieurs cœurs d'un processeur.
Modèle de programmation parallèle
Nous avons établi ce qu'est la programmation parallèle, mais comment l'utiliser ? Nous avons déjà dit que le calcul parallèle implique l'exécution de plusieurs tâches sur plusieurs cœurs d'un processeur, ce qui signifie que ces tâches sont exécutées simultanément. Avant de procéder à la parallélisation, vous devez considérer plusieurs problèmes. Par exemple, existe-t-il d’autres optimisations qui peuvent accélérer nos calculs ?
Maintenant, tenons pour acquis que la parallélisation est la solution la plus adaptée. Il existe trois modes principaux de calcul parallèle :
Parallèle complet. Les tâches peuvent s'exécuter indépendamment et n'ont pas besoin de communiquer entre elles.
Parallélisme de mémoire partagée. Les processus (ou threads) doivent communiquer, ils partagent donc un espace d'adressage global.
Messagerie. Les processus doivent partager des messages en cas de besoin.
Dans cet article, nous vous expliquerons le premier modèle, qui est aussi le plus simple.
Python Multiprocessing : parallélisme basé sur les processus en Python
Une façon d'obtenir le parallélisme en Python est d'utiliser le module multiprocessing. Le module multiprocessing vous permet de créer plusieurs processus, chacun avec son propre interpréteur Python. Par conséquent, le multitraitement Python implémente un parallélisme basé sur les processus. multiprocessing模块允许你创建多个进程,每个进程都有自己的 Python 解释器。因此,Python 多进程实现了基于进程的并行。
你可能听说过其他库,比如threading,它也是Python内置的,但它们之间有着重要的区别。multiprocessing模块创建新进程,而threading
Vous avez peut-être entendu parler d'autres bibliothèques, telles que threading, qui sont également intégrées à Python, mais il existe des différences importantes entre elles. Le module multiprocessing crée de nouveaux processus, tandis que threading crée de nouveaux threads.
Avantages de l'utilisation du multi-traitement
Vous vous demandez peut-être : "Pourquoi choisir le multi-traitement ?" Le multi-traitement peut améliorer considérablement l'efficacité d'un programme en exécutant plusieurs tâches en parallèle plutôt que séquentiellement. Un terme similaire est multithreading, mais ils sont différents.
Un processus est un programme chargé en mémoire pour s'exécuter et ne partage pas sa mémoire avec d'autres processus. Un thread est une unité d'exécution dans un processus. Plusieurs threads s'exécutent dans un processus et partagent l'espace mémoire du processus entre eux.
Le Global Interpreter Lock (GIL) de Python n'autorise qu'un seul thread à s'exécuter à la fois sous l'interpréteur, ce qui signifie que vous ne pourrez pas profiter des avantages en termes de performances du multi-threading si vous avez besoin de l'interpréteur Python. C'est pourquoi le multitraitement est plus avantageux que le threading en Python. Plusieurs processus peuvent s'exécuter en parallèle car chaque processus possède son propre interpréteur qui exécute les instructions qui lui sont assignées. De plus, le système d'exploitation examinera votre programme dans plusieurs processus et les planifiera séparément, c'est-à-dire que votre programme disposera d'une plus grande part des ressources informatiques totales. Par conséquent, le multitraitement est plus rapide lorsque le programme est lié au processeur. Dans les situations où il y a beaucoup d’E/S dans un programme, les threads peuvent être plus efficaces car la plupart du temps, le programme attend la fin des E/S. Cependant, plusieurs processus sont généralement plus efficaces car ils s’exécutent simultanément.
Voici quelques avantages du multi-traitement :
Meilleure utilisation du processeur lors de tâches à forte consommation de processeur
Plus de contrôle sur les sous-threads par rapport aux threads
-
Facile à coder
Le le premier avantage est lié à la performance. Étant donné que le multitraitement crée de nouveaux processus, vous pouvez mieux utiliser la puissance de calcul du processeur en répartissant les tâches entre les autres cœurs. De nos jours, la plupart des processeurs sont multicœurs et si vous optimisez votre code, vous pouvez gagner du temps grâce au calcul parallèle.
Le deuxième avantage est une alternative au multi-threading. Les threads ne sont pas des processus, et cela a ses conséquences. Si vous créez un thread, il est dangereux de le terminer comme un processus normal ou même de l'interrompre. Étant donné que la comparaison entre multi-traitement et multi-threading dépasse le cadre de cet article, j'écrirai un article séparé plus tard pour parler de la différence entre multi-traitement et multi-threading.
Le troisième avantage du multi-traitement est qu'il est facile à mettre en œuvre car la tâche que vous essayez de gérer est adaptée à la programmation parallèle.
Démarrez avec le multi-traitement Python
Nous sommes enfin prêts à écrire du code Python !
Nous commencerons par un exemple très basique que nous utiliserons pour illustrer les aspects fondamentaux du multitraitement Python. Dans cet exemple, nous aurons deux processus :
parentsouvent. Il n’existe qu’un seul processus parent et il peut avoir plusieurs processus enfants.parent经常。只有一个父进程,它可以有多个子进程。child进程。这是由父进程产生的。每个子进程也可以有新的子进程。
我们将使用该child过程来执行某个函数。这样,parent可以继续执行。
一个简单的 Python多进程示例
这是我们将用于此示例的代码:
from multiprocessing import Process
def bubble_sort(array):
check = True
while check == True:
check = False
for i in range(0, len(array)-1):
if array[i] > array[i+1]:
check = True
temp = array[i]
array[i] = array[i+1]
array[i+1] = temp
print("Array sorted: ", array)
if __name__ == '__main__':
p = Process(target=bubble_sort, args=([1,9,4,5,2,6,8,4],))
p.start()
p.join()
在这个片段中,我们定义了一个名为bubble_sort(array)。这个函数是冒泡排序算法的一个非常简单的实现。如果你不知道它是什么,请不要担心,因为它并不重要。要知道的关键是它是一个可以实现某个功能的函数。
进程类
从multiprocessing,我们导入类Process。此类表示将在单独进程中运行的活动。事实上,你可以看到我们已经传递了一些参数:
target=bubble_sort,意味着我们的新进程将运行该bubble_sort函数args=([1,9,4,52,6,8,4],),这是作为参数传递给目标函数的数组
一旦我们创建了 Process 类的实例,我们只需要启动该进程。这是通过编写p.start()完成的。此时,该进程开始。
在我们退出之前,我们需要等待子进程完成它的计算。该join()方法等待进程终止。
在这个例子中,我们只创建了一个子进程。正如你可能猜到的,我们可以通过在Process类中创建更多实例来创建更多子进程。
进程池类
如果我们需要创建多个进程来处理更多 CPU 密集型任务怎么办?我们是否总是需要明确地开始并等待终止?这里的解决方案是使用Pool类。
Pool类允许你创建一个工作进程池,在下面的示例中,我们将研究如何使用它。这是我们的新示例:
from multiprocessing import Pool
import time
import math
N = 5000000
def cube(x):
return math.sqrt(x)
if __name__ == "__main__":
with Pool() as pool:
result = pool.map(cube, range(10,N))
print("Program finished!")
在这个代码片段中,我们有一个cube(x)函数,它只接受一个整数并返回它的平方根。很简单,对吧?
然后,我们创建一个Pool类的实例,而不指定任何属性。默认情况下,Pool类为每个 CPU 核心创建一个进程。接下来,我们使用几个参数运行map方法。
map方法将cube函数应用于我们提供的可迭代对象的每个元素——在本例中,它是从10到N的每个数字的列表。
这样做的最大优点是列表上的计算是并行进行的!
joblib
包joblib是一组使并行计算更容易的工具。它是一个用于多进程的通用第三方库。它还提供缓存和序列化功能。要安装joblib包,请在终端中使用以下命令:
pip install joblib
我们可以将之前的示例转换为以下示例以供使用joblib:
from joblib import Parallel, delayed
def cube(x):
return x**3
start_time = time.perf_counter()
result = Parallel(n_jobs=3)(delayed(cube)(i) for i in range(1,1000))
finish_time = time.perf_counter()
print(f"Program finished in {finish_time-start_time} seconds")
print(result)
事实上,直观地看到它的作用。delayed()
enfant. Ceci est généré par le processus parent. Chaque processus enfant peut également avoir de nouveaux processus enfants. 🎜Nous utiliserons la procédure child pour exécuter une fonction. De cette façon, parent peut continuer l'exécution. 🎜
Un exemple simple de multi-processus Python
C'est ce que nous utiliserons pour cet exemple Code : 🎜
result = Parallel(n_jobs=3)((cube, (i,), {}) for i in range(1,1000))
Dans cet extrait, nous définissons une classe appelée bubble_sort(array). Cette fonction est une implémentation très simple de l’algorithme de tri à bulles. Si vous ne savez pas ce que c'est, ne vous inquiétez pas car ce n'est pas important. L'essentiel à savoir est que c'est une fonction qui fait quelque chose. 🎜
Classe de processus
Depuis le multitraitement, nous importons la classeProcessus. Cette classe représente les activités qui s'exécuteront dans un processus distinct. En fait, vous pouvez voir que nous avons passé certains paramètres : 🎜
- 🎜🎜
target=bubble_sort, c'est-à-dire Notre le nouveau processus exécutera la fonction bubble_sort🎜🎜🎜args=([1,9,4,52,6,8,4],), ce est le tableau passé en paramètre à la fonction cible 🎜Une fois que nous avons créé une instance de la classe Process, il ne nous reste plus qu'à démarrer le processus . Cela se fait en écrivant p.start(). C’est à ce stade que le processus commence. 🎜
Nous devons attendre que le processus enfant termine ses calculs avant de quitter. La méthode join() attend la fin du processus. 🎜
Dans cet exemple, nous ne créons qu'un seul processus enfant. Comme vous pouvez le deviner, nous pouvons créer plus de processus enfants en créant plus d'instances dans la classe Process. 🎜
Classe de pool de processus
Si nous devons créer plusieurs processus pour gérer des ressources CPU plus gourmandes. à voir avec les tâches de type ? Devons-nous toujours explicitement démarrer et attendre la fin ? La solution ici est d'utiliser la classe Pool. 🎜
La classe Pool permet de créer un pool de processus de travail, dans l'exemple suivant nous verrons comment l'utiliser. Voici notre nouvel exemple : 🎜
result = Parallel(n_jobs=3, prefer="threads")(delayed(cube)(i) for i in range(1,1000))
Dans cet extrait de code, nous avons une fonction cube(x) qui accepte simplement un entier et renvoie sa racine carrée. Assez simple, non ? 🎜
Ensuite, nous créons une instance de la classe Pool sans spécifier de propriétés. Par défaut, la classe Pool crée un processus par cœur de processeur. Ensuite, nous exécutons la méthode map avec quelques paramètres. 🎜
La méthode map applique la fonction cube à chaque élément de l'itérable que nous fournissons - dans ce cas, qui est un liste de tous les nombres de 10 à N. 🎜
Le plus gros avantage est que les calculs de la liste sont effectués en parallèle ! 🎜
joblib🎜
Le package joblib est un ensemble d'outils qui permettent de réaliser du calcul parallèle outil plus simple. Il s'agit d'une bibliothèque tierce à usage général pour le multi-processus. Il fournit également des fonctionnalités de mise en cache et de sérialisation. Pour installer le package joblib, utilisez la commande suivante dans le terminal : 🎜
from multiprocessing import Pool
import time
import math
N = 5000000
def cube(x):
return math.sqrt(x)
if __name__ == "__main__":
# first way, using multiprocessing
start_time = time.perf_counter()
with Pool() as pool:
result = pool.map(cube, range(10,N))
finish_time = time.perf_counter()
print("Program finished in {} seconds - using multiprocessing".format(finish_time-start_time))
print("---")
# second way, serial computation
start_time = time.perf_counter()
result = []
for x in range(10,N):
result.append(cube(x))
finish_time = time.perf_counter()
print("Program finished in {} seconds".format(finish_time-start_time))
Nous pouvons convertir l'exemple précédent en l'exemple suivant pour une utilisation joblib : 🎜
> python code.py Program finished in 1.6385094 seconds - using multiprocessing --- Program finished in 2.7373942999999996 seconds
En fait, voyez intuitivement ce qu'il fait. La fonction delayed() est un wrapper autour d'une autre fonction qui génère une version "retardée" d'un appel de fonction. Cela signifie qu'il n'exécute pas la fonction immédiatement lorsqu'elle est appelée. 🎜
然后,我们多次调用delayed函数,并传递不同的参数集。例如,当我们将整数1赋予cube函数的延迟版本时,我们不计算结果,而是分别为函数对象、位置参数和关键字参数生成元组(cube, (1,), {})。
我们使用Parallel()创建了引擎实例。当它像一个以元组列表作为参数的函数一样被调用时,它将实际并行执行每个元组指定的作业,并在所有作业完成后收集结果作为列表。在这里,我们创建了n_jobs=3的Parallel()实例,因此将有三个进程并行运行。
我们也可以直接编写元组。因此,上面的代码可以重写为:
result = Parallel(n_jobs=3)((cube, (i,), {}) for i in range(1,1000))
使用joblib的好处是,我们可以通过简单地添加一个附加参数在多线程中运行代码:
result = Parallel(n_jobs=3, prefer="threads")(delayed(cube)(i) for i in range(1,1000))
这隐藏了并行运行函数的所有细节。我们只是使用与普通列表理解没有太大区别的语法。
充分利用 Python多进程
创建多个进程并进行并行计算不一定比串行计算更有效。对于 CPU 密集度较低的任务,串行计算比并行计算快。因此,了解何时应该使用多进程非常重要——这取决于你正在执行的任务。
为了让你相信这一点,让我们看一个简单的例子:
from multiprocessing import Pool
import time
import math
N = 5000000
def cube(x):
return math.sqrt(x)
if __name__ == "__main__":
# first way, using multiprocessing
start_time = time.perf_counter()
with Pool() as pool:
result = pool.map(cube, range(10,N))
finish_time = time.perf_counter()
print("Program finished in {} seconds - using multiprocessing".format(finish_time-start_time))
print("---")
# second way, serial computation
start_time = time.perf_counter()
result = []
for x in range(10,N):
result.append(cube(x))
finish_time = time.perf_counter()
print("Program finished in {} seconds".format(finish_time-start_time))
此代码段基于前面的示例。我们正在解决同样的问题,即计算N个数的平方根,但有两种方法。第一个涉及 Python 进程的使用,而第二个不涉及。我们使用time库中的perf_counter()方法来测量时间性能。
在我的电脑上,我得到了这个结果:
> python code.py Program finished in 1.6385094 seconds - using multiprocessing --- Program finished in 2.7373942999999996 seconds
如你所见,相差不止一秒。所以在这种情况下,多进程更好。
让我们更改代码中的某些内容,例如N的值。 让我们把它降低到N=10000,看看会发生什么。
这就是我现在得到的:
> python code.py Program finished in 0.3756742 seconds - using multiprocessing --- Program finished in 0.005098400000000003 seconds
发生了什么?现在看来,多进程是一个糟糕的选择。为什么?
与解决的任务相比,在进程之间拆分计算所带来的开销太大了。你可以看到在时间性能方面有多大差异。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!