
Maison >Périphériques technologiques >IA >Analyse technique et partage de pratiques : mode utilisateur et mode noyau dans la virtualisation de conteneurs GPU double moteur
Analyse technique et partage de pratiques : mode utilisateur et mode noyau dans la virtualisation de conteneurs GPU double moteur

- 王林avant
- 2023-04-23 15:40:101202parcourir
Comment maximiser l’efficacité de la puissance de calcul matérielle est une question de grande préoccupation pour tous les opérateurs et utilisateurs de ressources. En tant que société leader en matière d'IA, Baidu propose peut-être les scénarios d'application d'IA les plus complets du secteur.
Dans cet article, nous partagerons et discuterons des solutions de virtualisation de conteneurs GPU dans des scénarios d'IA complexes et des meilleures pratiques en usine.
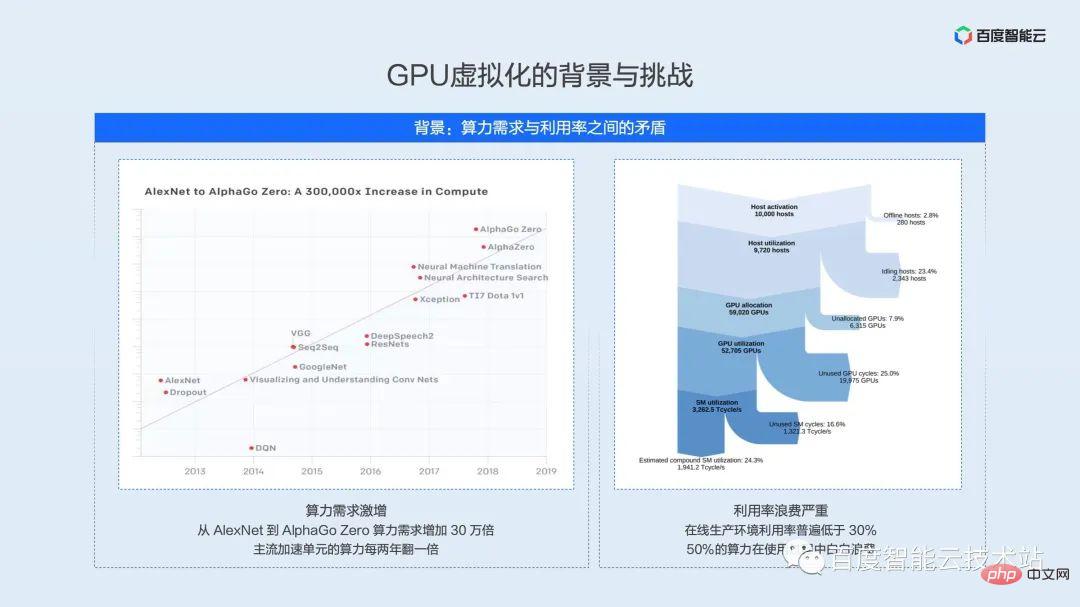
Les parties gauche et droite de l'image ci-dessous ont été montrées à plusieurs reprises à différentes occasions. Le but principal de leur présentation ici est de souligner la demande de puissance de calcul - la croissance exponentielle de la puissance de calcul du matériel et la faible utilisation des ressources dans scénarios d'application réels. La contradiction entre les déchets.
La partie de gauche représente les statistiques d'OpenAI. Depuis 2012, la puissance de calcul requise pour la formation des modèles a doublé tous les 3,4 mois. Pour les grands modèles tels qu'AlphaGoZero, la puissance de calcul de la formation a augmenté de 300 000 fois. . D’une part, à mesure que la demande de puissance de calcul augmente, les performances de calcul des unités d’accélération de l’IA grand public doublent également tous les deux ans. D'un autre côté, l'efficacité de l'utilisation des ressources limite la pleine utilisation des performances du matériel.
La partie de droite est le résultat de l’analyse de la charge d’apprentissage automatique du centre de données de Facebook en 2021. Une grande quantité de puissance de calcul de l'IA est perdue dans des liens tels que les pannes, la planification, la perte de tranches de temps et le gaspillage d'unités d'espace, et l'utilisation réelle de la puissance de calcul est inférieure à 30 %. Nous pensons que c’est également la situation actuelle à laquelle sont confrontés les principaux opérateurs d’infrastructures nationaux.
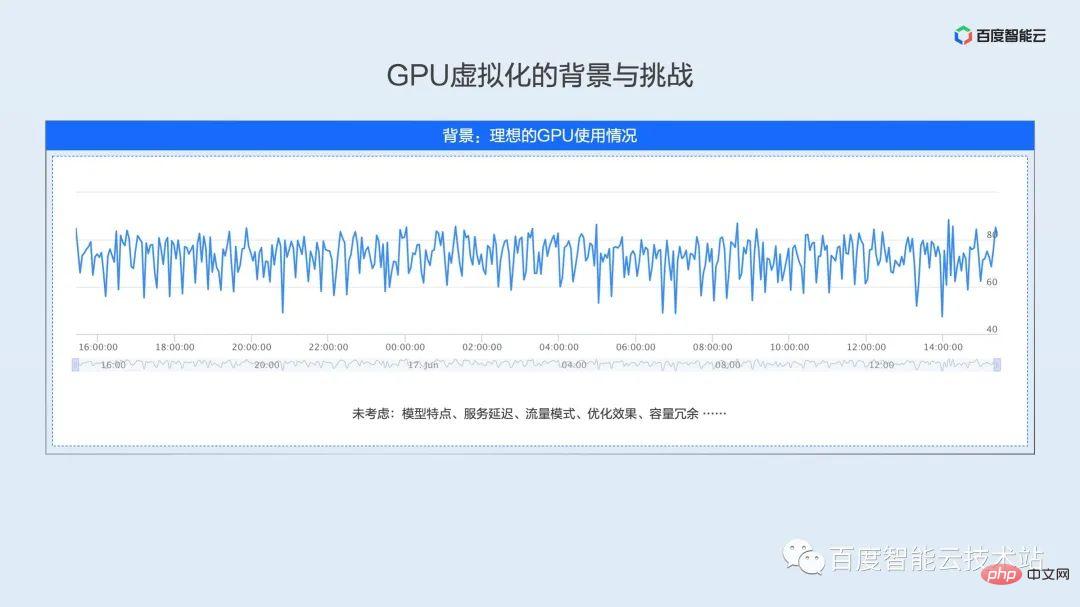
Je viens de mentionner que le taux d'utilisation du cluster en ligne est inférieur à 30%, ce qui n'est peut-être pas conforme aux perceptions de nombreux étudiants. De nombreux étudiants en ligne peuvent être des développeurs de modèles et d’algorithmes. Notre compréhension générale est que l'utilisation peut rester très élevée pendant la formation et les tests, et peut même atteindre 100 %.
Cependant, lorsque le modèle sera lancé dans l'environnement de production, il sera soumis à de nombreuses contraintes. Ces contraintes font que le taux d'utilisation est bien inférieur à nos attentes.
Utilisons un espace limité pour résumer les principales contraintes :
- Caractéristiques du modèle : chaque modèle de réseau est différent et les combinaisons d'opérateurs sous-jacentes appelées sont différentes, ce qui affectera grandement l'utilisation du GPU.
- SLA de service : les services dans différents scénarios nécessitent des SLA différents. Certains services ont des exigences élevées en temps réel et doivent même être strictement contrôlés dans un délai de 10 ms. Ces services ne peuvent donc pas améliorer l'utilisation en augmentant la taille du lot, ou même la taille du lot ne peut être que de 1.
- Modèle de trafic : différents algorithmes de modèle servent différents scénarios d'application, tels que la reconnaissance OCR, qui peuvent être fréquemment appelées pendant le travail. La reconnaissance vocale est plus souvent utilisée pendant les déplacements domicile-travail ou pendant les divertissements et les loisirs, ce qui entraîne des fluctuations de pointe et de vallée dans l'utilisation du GPU tout au long de la journée.
- Effet d'optimisation : En fonction de la fréquence d'itération du modèle et des scénarios de couverture, la granularité d'optimisation du modèle est également différente. Il est concevable qu’il soit difficile pour un taux d’utilisation d’un modèle qui n’est pas entièrement optimisé d’atteindre un niveau élevé.
- Redondance de capacité : avant la mise en ligne du modèle, une planification détaillée de la capacité doit être effectuée. Quel est le trafic maximum et si plusieurs régions sont nécessaires ? Dans ce processus, une redondance de capacité sera réservée, ce qui est également difficile à ignorer. problèmes en temps normal. Un gaspillage d’énergie.
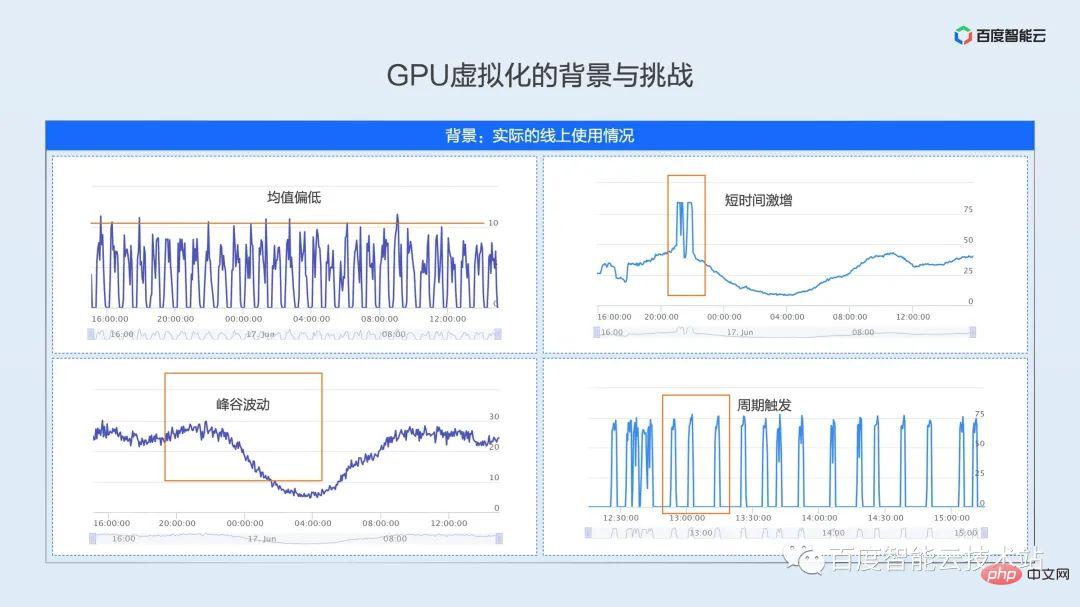
Sous les contraintes ci-dessus, le taux d'utilisation de l'environnement de production réel peut être ce que nous voulons montrer ensuite. Nous extrayons ces modèles d'utilisation de l'environnement de production en ligne complexe et changeant.
- Type à moyenne basse : comme le montre l'image ci-dessus à gauche, il s'agit d'une véritable activité d'inférence en ligne. En raison des limitations des caractéristiques du modèle et du SLA du service, l'utilisation maximale du GPU n'est que de 10 % et l'utilisation moyenne. sera encore plus faible.
- Type de fluctuation de pic et de vallée : comme le montre l'image ci-dessous à gauche, il s'agit d'un modèle typique d'utilisation d'inférence en ligne pour les entreprises. Le service atteindra un pic pendant la journée et l'utilisation sera à un point bas à partir de tard dans la nuit. au lendemain matin, l'utilisation moyenne tout au long de la journée n'est que de 20 %. Environ 10 %, le taux d'utilisation minimum est inférieur à 10 %.
- Type de surtension à court terme : comme le montre l'image en haut à droite, la courbe d'utilisation est fondamentalement la même que l'image en bas à gauche, mais il y aura deux pics d'utilisation évidents pendant les heures de grande écoute la nuit. jusqu'à 80 % Afin de répondre à la qualité du service en période de pointe, ce service réservera une grande mémoire tampon pendant le processus de déploiement et l'utilisation moyenne des ressources est d'un peu plus de 30 %.
- Type déclenché par période : comme le montre l'image de droite ci-dessous, il s'agit du mode d'utilisation d'un scénario de formation en ligne typique. La tâche de formation en ligne se situe entre la formation hors ligne et l'inférence en ligne. Par exemple, un lot de données arrive toutes les 15 minutes, mais la formation de ce lot de données ne prend que 2 à 3 minutes et le GPU reste inactif pendant une longue période.
Les scénarios d'application de l'IA sont complexes et modifiables. Ce qui précède ne répertorie que quatre scénarios typiques. Comment équilibrer les performances de l'entreprise et l'efficacité des ressources dans des scénarios complexes est le premier défi que nous rencontrons dans la virtualisation GPU.
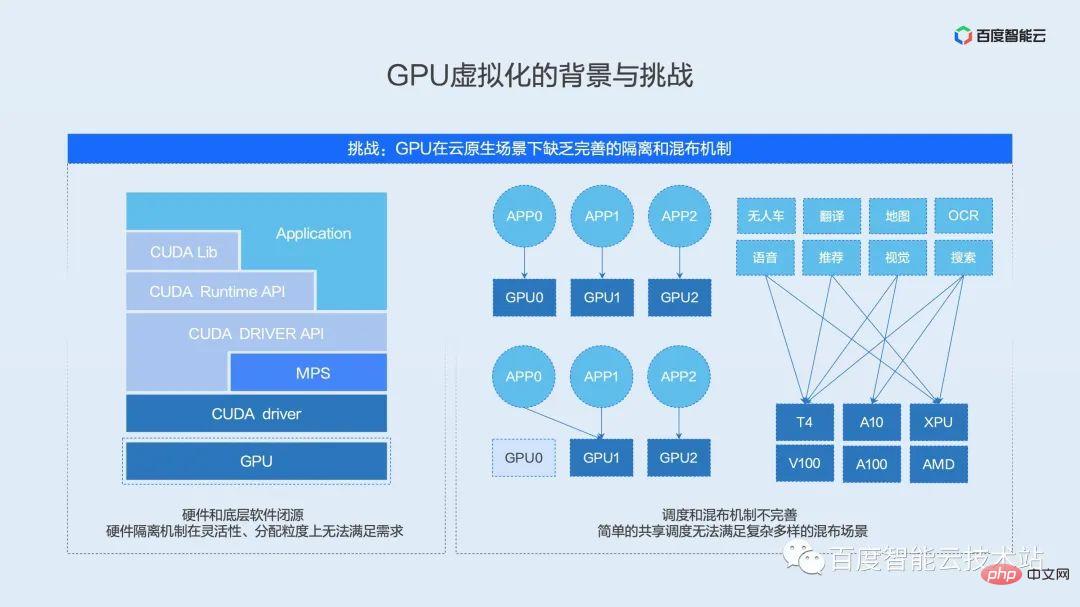
Le deuxième défi auquel nous sommes confrontés dans le processus de virtualisation GPU est le manque d'isolation complète du GPU et de mécanisme de mixage.
Nous prenons comme exemple le GPU NVIDIA grand public actuel. L'écosystème logiciel et matériel typique de l'IA est divisé en plusieurs niveaux : couche d'application et de structure, couche d'exécution, couche de pilotes et couche matérielle.
Tout d'abord, la couche supérieure est l'application de l'utilisateur, qui comprend divers frameworks courants tels que PaddlePaddle, TensorFlow, PyTorch, etc. Sous la couche application se trouve la couche d'interface API encapsulée par le fournisseur de matériel, comprenant diverses bibliothèques d'opérateurs communes et interfaces d'accès au runtime matériel. Sous cette couche d'interface API se trouve la couche pilote qui communique avec le matériel. Cette couche est située dans l'état du noyau et constitue la couche d'interface logicielle qui communique directement avec le périphérique. En bas se trouve le véritable matériel d’accélération de l’IA, responsable de l’exécution des opérateurs.
Les solutions de virtualisation traditionnelles sont implémentées en combinaison avec l'état du noyau du pilote et la logique de virtualisation matérielle. Ces deux niveaux constituent l'IP de base des fournisseurs de matériel et sont généralement de source fermée. Comme nous le mentionnerons plus tard, le mécanisme d'isolation natif GPU actuel ne peut pas répondre aux exigences d'utilisation dans les scénarios cloud natifs en termes de flexibilité et de force d'allocation.
En plus du mécanisme d'isolation, le mécanisme de distribution hybride existant est également difficile à répondre aux besoins de scénarios complexes. Nous avons vu qu'il existe de nombreuses solutions open source pour la planification partagée dans l'industrie. Ces solutions open source planifient simplement deux tâches. en un à partir de la carte de niveau de ressource. Dans les scénarios réels, un simple partage entraînera un impact mutuel entre les entreprises, des retards prolongés et même une détérioration du débit, rendant le partage simple incapable d'être véritablement appliqué dans les environnements de production.
Dans la section d'analyse des modèles d'utilisation ci-dessus, nous avons vu que différentes entreprises et différents scénarios ont des modèles d'utilisation différents. Comment faire abstraction des scénarios commerciaux et personnaliser les solutions hybrides est la clé de la mise en œuvre de l'environnement de production.
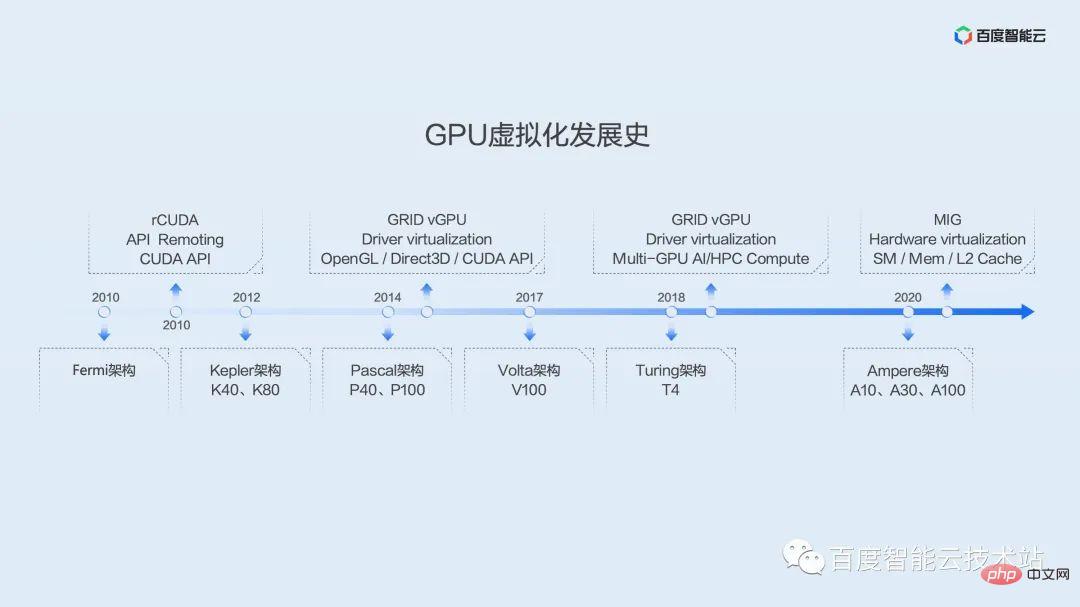
Afin de donner à chacun une compréhension plus complète du développement du GPU et de l'histoire de la virtualisation, nous utilisons ici une image pour montrer l'historique du développement de la virtualisation GPU.
L'application du GPU dans l'informatique générale remonte à l'architecture Tesla de l'ère G80. Il s'agit de la première génération d'architecture à implémenter des shaders unifiés, utilisant un processeur SM à usage général pour remplacer le processeur d'image graphique d'origine par des sommets et des pixels séparés. canalisations.
Le premier GPU introduit par Baidu remonte à l'architecture Fermi. Depuis lors, un certain nombre de solutions de virtualisation sont apparues dans l’industrie, dont la plupart se concentrent sur le détournement d’API. Le représentant typique ici est rCUDA, un projet initialement soutenu par des groupes universitaires. Jusqu'à récemment, il a maintenu une certaine fréquence de mises à jour et d'itérations, mais il semble se concentrer sur la recherche universitaire et n'a pas été largement utilisé dans les environnements de production.
L'introduction à grande échelle des GPU par Baidu était basée sur l'architecture Kepler. L'architecture Kepler a ouvert l'ère du super ordinateur d'IA auto-développé par Baidu, X-MAN. X-MAN 1.0 implémente pour la première fois une configuration de 16 cartes sur une seule machine et peut réaliser une liaison dynamique et un rapport flexible entre CPU et GPU au niveau matériel PCIe. Limité par les performances d’une seule carte, on se concentrait à l’époque sur l’expansion plutôt que sur la segmentation.
Les performances des architectures Pascal, Volta et Turing qui ont suivi se sont rapidement améliorées et la demande de virtualisation est devenue de plus en plus évidente. Nous voyons que depuis la première architecture Kepler, NV a officiellement fourni la solution de virtualisation GRID vGPU, initialement destinée aux scénarios de rendu graphique et de bureau à distance. Vers 2019, des solutions ont également été fournies pour des scénarios d’IA et de calcul haute performance. Cependant, ces solutions reposent sur des machines virtuelles et sont rarement utilisées dans les scénarios d’IA.
Dans la génération Ampere, NV a lancé la solution de fractionnement d'instance MIG, qui réalise le fractionnement de plusieurs ressources matérielles telles que SM, MEM et cache L2 au niveau matériel, offrant de bonnes performances d'isolation matérielle. Cependant, cette solution est supportée à partir de l'architecture Ampere, et il existe certaines restrictions sur les modèles de cartes. Seuls quelques modèles, A100 et A30, peuvent le prendre en charge. Et même après découpage, les performances d'une seule instance dépassent la puissance de calcul du T4 et ne peuvent pas bien résoudre le problème d'efficacité de l'environnement de production actuel.
Après que tout le monde ait quelques impressions sur l'histoire de l'architecture GPU et de la virtualisation, présentons en détail les principaux niveaux, ou voies techniques, de mise en œuvre de la virtualisation GPU.
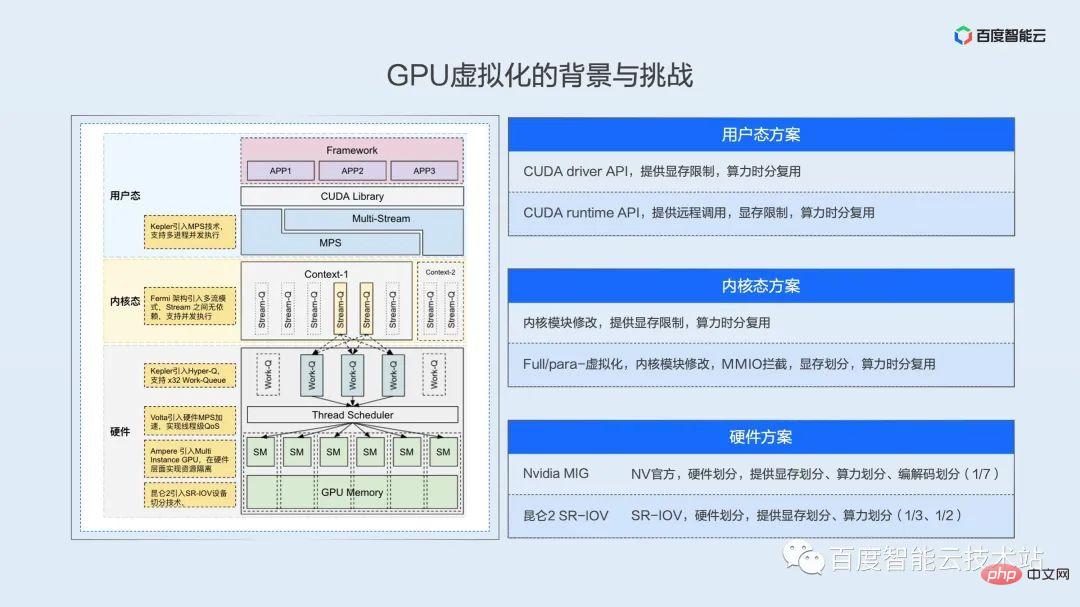
Pour réaliser l'isolation de la virtualisation des ressources, vous devez d'abord que les ressources soient séparables dans la dimension temporelle ou spatiale. Du point de vue de l'utilisateur, plusieurs tâches peuvent être exécutées simultanément ou en parallèle.
Nous discutons ici du parallélisme ou de l'espace de concurrence à plusieurs niveaux de mode utilisateur, de mode noyau et de matériel.
Étant donné que l'écosystème logiciel et matériel de NV est fermé, le diagramme schématique ici est tiré de notre livre blanc sur l'architecture complète, de nos documents inversés et de notre propre compréhension. Nous espérons que chacun pourra corriger les inexactitudes à temps.
Solution en mode utilisateur
Regardons cette image de haut en bas. Tout d'abord, plusieurs processus sont naturellement concurrents du point de vue du GPU, c'est-à-dire multiplexés dans le temps. Le pilote et le matériel sont responsables de la commutation des tâches selon une rotation de tranche de temps. Grâce à cette couche de mécanisme, nous pouvons implémenter des limitations sur les ressources informatiques et les ressources de mémoire vidéo au niveau de l'API pour obtenir des effets de virtualisation. L'API ici peut être divisée en deux couches. La première couche est l'API du pilote. Cette couche d'API est proche du pilote et constitue le seul moyen pour tous les appels de couche supérieure d'accéder au GPU. de l'API, cela équivaut à contrôler l'accès aux ressources de l'utilisateur. Permettez-moi de mentionner ici que la technologie MPS fournie par NV peut réaliser un multiplexage par répartition spatiale, ce qui offre également la possibilité d'optimiser davantage les performances de l'entreprise. Nous développerons en détail dans la partie pratique de mise en œuvre ultérieure.
Solution d'état du noyau
La couche suivante est l'état du noyau. Qu'il s'agisse de virtualisation complète ou de paravirtualisation au niveau de la machine virtuelle, ou des solutions de conteneurs des principaux fournisseurs de cloud au cours des deux dernières années, le système est implémenté au niveau du noyau. Interception d'appels et détournement MMIO, la plus grande difficulté dans l'état du noyau est que de nombreux registres et comportements MMIO ne sont pas bien documentés, ce qui nécessite une ingénierie inverse complexe.
Solution matérielle
Sous l'état du noyau se trouve la couche matérielle. Le véritable parallélisme est garanti au niveau de cette couche. Qu'il s'agisse de la technologie MIG de NV ou de la technologie SR-IOV de Baidu Kunlun, la puissance de calcul est implémentée dans la logique matérielle. et multiplexage par répartition spatiale. Par exemple, Kunlun peut réaliser un partitionnement matériel de 1/3 et 1/2, et A100 peut réaliser un partitionnement des ressources avec une granularité minimale de 1/7.
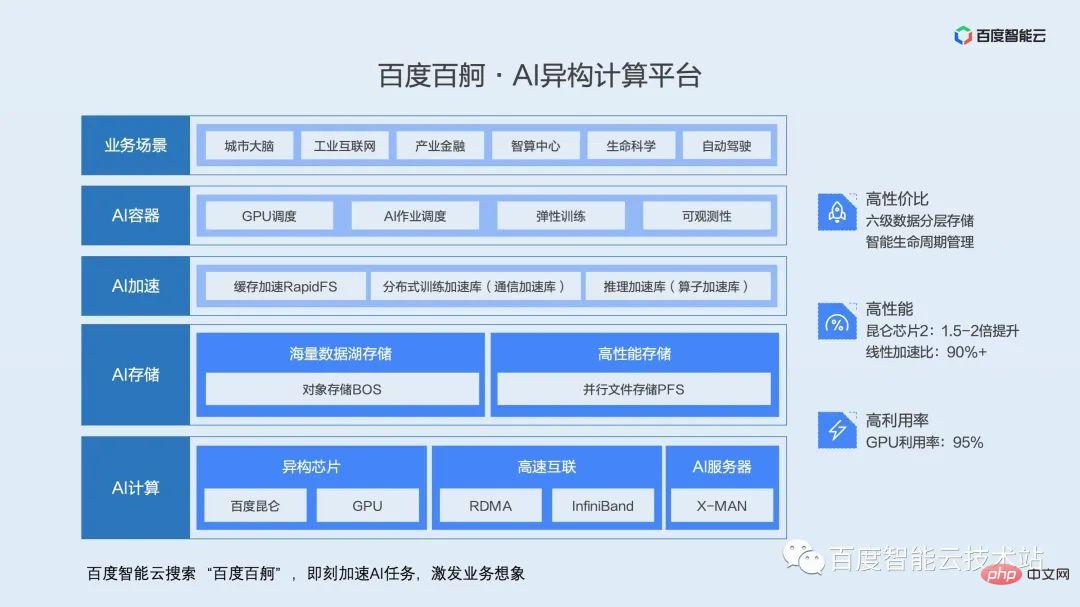
Nous avons consacré beaucoup d'espace ci-dessus à vous présenter les défis et la situation actuelle de la virtualisation GPU. Voyons ensuite comment Baidu répond en interne à ces défis.
Cette image montre Baidu Smart Cloud - une architecture de virtualisation de conteneur GPU à double moteur.
Les conteneurs sont mis en avant ici car nous pensons qu'à l'avenir, les applications d'IA full-link convergeront progressivement vers les plates-formes cloud natives pour réaliser un développement, une formation et une inférence complets de conteneurs. Selon une étude Gartner, 70 % des tâches d’IA seront déployées dans des conteneurs en 2023. La conteneurisation interne de Baidu a débuté en 2011 et compte désormais plus de 10 ans d'expérience en matière de déploiement et d'optimisation. Nous nous engageons également à apporter cette partie des capacités du produit et de l'expérience d'optimisation perfectionnée dans la vie réelle à la communauté et à la majorité des utilisateurs.
Les moteurs doubles sont également mis en valeur ici. Dans l'architecture globale, nous utilisons deux ensembles de moteurs d'isolation, le mode utilisateur et le mode noyau, pour répondre aux différents besoins des utilisateurs en matière d'isolation, de performances, d'efficacité et d'autres aspects.
Au-dessus du moteur d'isolation se trouve la couche de mise en commun des ressources. Cette couche est basée sur notre compréhension approfondie du système logiciel et matériel et met progressivement en œuvre le découplage, l'éloignement et la mise en commun des ressources accélérées par l'IA. couche d’infrastructure.
Au-dessus de la couche de mise en commun des ressources se trouve la couche de planification unifiée des ressources Matrix/k8s (Matrix est ici le système de planification conteneurisé dans l'usine Baidu). En plus du mécanisme de planification, nous résumerons une variété de ressources basées sur différents scénarios commerciaux. Les stratégies de mixage incluent le mixage partagé, le mixage préemptif, le mixage en temps partagé, le mixage par marée, etc. Ces stratégies de distribution mixte seront développées en détail dans la partie pratique suivante.
S'appuyer sur l'isolation et la planification des ressources est le scénario de liaison complète des activités d'IA, y compris le développement de modèles, la formation de modèles et le raisonnement en ligne.

Ensuite, je partagerai avec vous l'implémentation respectivement des moteurs d'isolation en mode utilisateur et en mode noyau.
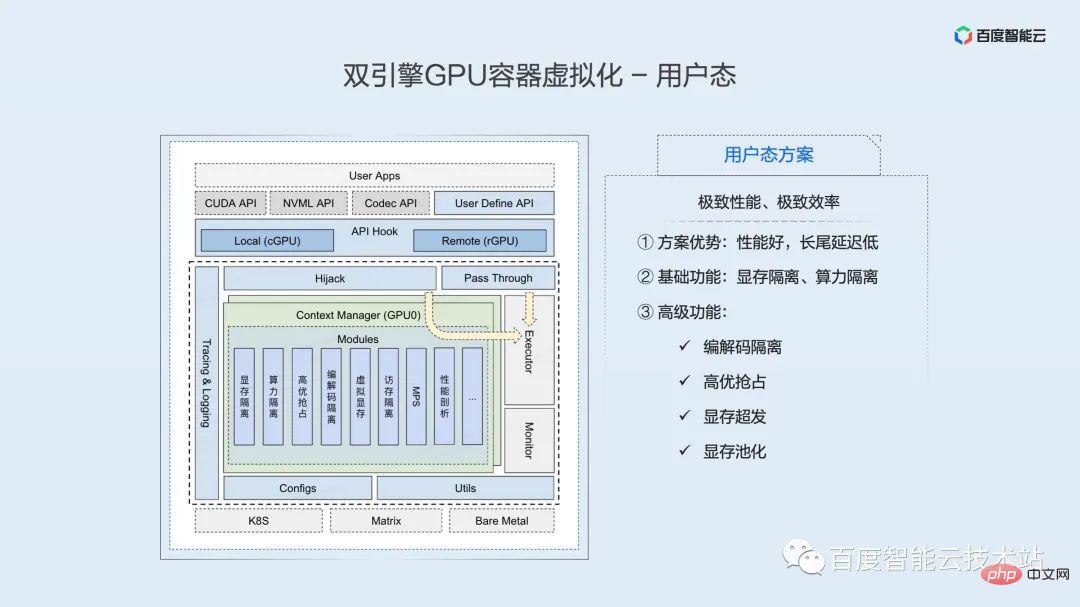
La figure suivante est un diagramme schématique de l'architecture de base du moteur d'isolation de l'espace utilisateur. En haut du diagramme d'architecture se trouve l'application utilisateur, qui comprend divers frameworks couramment utilisés, tels que PaddlePaddle, TensorFlow, PyTorch, etc.
Située sous l'application utilisateur se trouve une série d'interfaces API Hook. Sur la base de cet ensemble d'interfaces, nous pouvons réaliser une utilisation locale et un montage à distance des ressources GPU. En remplaçant les bibliothèques dynamiques sous-jacentes sur lesquelles s'appuie le framework, le contrôle et l'isolation des ressources sont obtenus. Il est important de noter que cette solution est totalement transparente pour l'application, et que les opérations de remplacement de bibliothèque nécessaires ont été automatiquement complétées par le moteur de conteneur et la partie planification.
L'API CUDA atteindra éventuellement l'exécuteur testamentaire par deux chemins après Hook. Ici, la grande majorité des API, telles que l'API de gestion des appareils, n'effectuent aucune opération après être passées par Hook et sont directement transmises à l'exécuteur pour exécution. Un petit nombre d'API liées à l'application des ressources passeront par une couche d'interception, à travers laquelle une série de fonctions de virtualisation de l'espace utilisateur pourront être implémentées. La logique de cette couche est mise en œuvre de manière suffisamment efficace et l'impact sur les performances est presque négligeable.
Actuellement, le moteur d'isolation en mode utilisateur peut fournir de riches fonctions d'isolation et de contrôle, notamment l'isolation de base de la mémoire vidéo et l'isolation de la puissance de calcul. Nous avons également étendu de nombreuses fonctionnalités avancées : isolation des encodeurs, préemption de haute qualité, surdistribution de la mémoire vidéo, pooling de la mémoire vidéo, etc.
Les avantages de la solution en mode utilisateur sont de bonnes performances et une faible latence longue traîne. Elle convient aux scénarios commerciaux qui recherchent des performances de mécanisme et une efficacité extrême, tels que les activités d'inférence en ligne sensibles aux délais.
Sur la base de l'isolement, nous fournissons des fonctions à distance. L'introduction de la télécommande améliorera considérablement la flexibilité de la configuration des ressources et l'efficacité de l'utilisation, que nous développerons à la fin de cet article.
Ce partage est un partage technologique. Ici, j'utiliserai un peu d'espace pour développer les points clés et les difficultés de la technologie à distance, dans l'espoir de stimuler les idées commerciales et les discussions techniques de chacun.
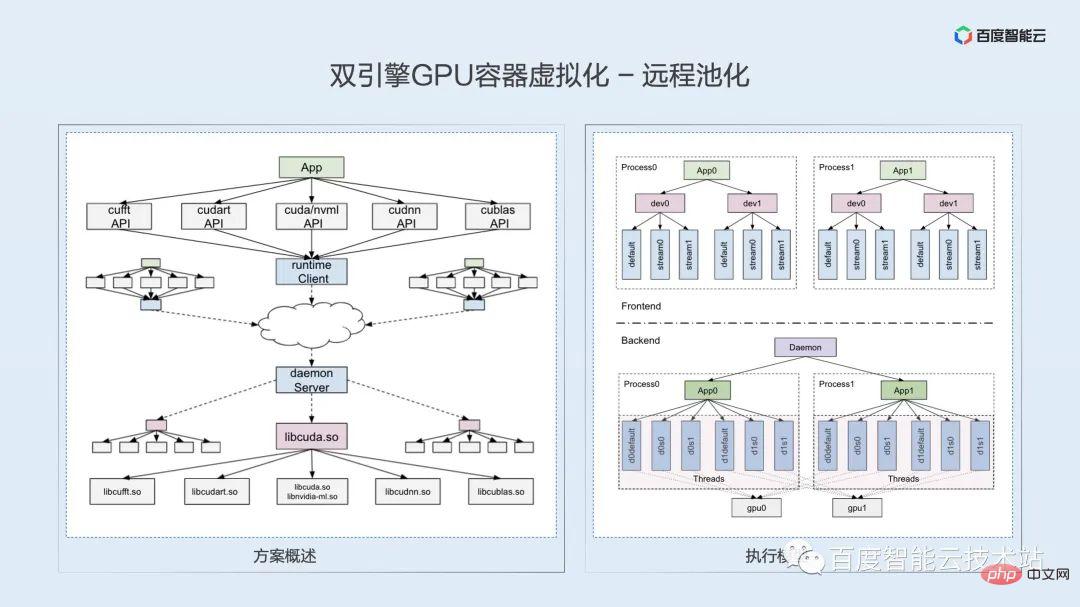
Selon la pile technologique logicielle et matérielle que nous avons mentionnée dans le défi de virtualisation précédent, l'accès à distance au GPU peut généralement être implémenté au niveau de la couche de liaison matérielle, de la couche pilote, de la couche d'exécution et de la couche utilisateur. Cependant, après une analyse technique approfondie. Et en combinaison avec notre compréhension des scénarios commerciaux, nous pensons que la couche d'exécution la plus appropriée à l'heure actuelle.
Déterminer le parcours technique de la couche d'exécution et comment le mettre en œuvre ? Quel est l’intérêt de la technologie ? Nous pensons que c'est avant tout une question de cohérence sémantique. En fonction de l'éloignement de l'exécution, le processus local d'origine doit être divisé en deux processus : client et serveur. Le runtime CUDA est fermé et la logique de mise en œuvre interne ne peut pas être explorée. Comment garantir que la logique du programme d'origine et la sémantique de l'API sont conservées après la division du processus ? Nous utilisons ici un modèle de thread un-à-un pour garantir l'alignement logique et sémantique au sein de l'API ?
La difficulté de la mise en œuvre à distance est le problème de nombreuses API. En plus de la bibliothèque dynamique libcudart.so, le runtime implique également une série de bibliothèques dynamiques et d'API telles que cuDNN, cuBLAS et cuFFT, impliquant des milliers d'interfaces API différentes. . Nous utilisons la technologie de compilation pour réaliser une analyse automatique des fichiers d'en-tête et une génération automatique de code, et complétons l'analyse des API cachées grâce à l'ingénierie inverse.
Solution à la solution distante 0-1 Après l'adaptation, la rétrocompatibilité ultérieure est en fait relativement facile à résoudre. À l'heure actuelle, il semble que l'API CUDA soit relativement stable et que les nouvelles versions ne nécessitent qu'une petite quantité d'adaptation incrémentielle.
Le multiplexage spatial et le multiplexage temporel ont été mentionnés à plusieurs reprises ci-dessus. Voici une explication détaillée :
- Multiplexage temporel : Comme son nom l'indique, il s'agit d'un multiplexage au niveau de la tranche de temps. Ceci est similaire à la planification des processus CPU. Dans une seule tranche de temps, un seul processus GPU est en cours d'exécution. Plusieurs processus GPU s'exécutent alternativement au niveau micro et ne peuvent être que simultanés. Cela a également pour conséquence que, dans un certain intervalle de temps, si le processus ne peut pas faire bon usage des ressources informatiques, ces ressources informatiques sont gaspillées.
- Multiplexage par répartition spatiale : différent du multiplexage par répartition temporelle, dans le multiplexage par répartition spatiale, à un certain micro-instant, plusieurs processus peuvent s'exécuter sur un GPU en même temps. Tant que les ressources de ce GPU ne sont pas entièrement utilisées, d'autres processus. Le noyau peut être lancé. Les noyaux des deux processus sont entrelacés et exécutés à un niveau micro, réalisant véritablement le parallélisme et utilisant davantage les ressources GPU.
Comme présenté dans la section de présentation, les méthodes de virtualisation actuellement courantes, notamment la virtualisation de l'état du noyau et la virtualisation NVIDIA vGPU, sont en fait des solutions de multiplexage temporel basées sur la rotation des tranches de temps au niveau inférieur.
NV a lancé MPS - une solution de service multi-processus pour les scénarios de concurrence multi-processus. Cette solution peut réaliser un multiplexage par répartition spatiale et est actuellement la seule solution qui prend en compte à la fois l'efficacité et les performances.
Voici une brève introduction à MPS. MPS équivaut à fusionner le contexte de deux processus en un seul processus. Le processus fusionné entrelace les noyaux des deux processus précédents pour le lancement. Cela présente deux avantages :
- Pas besoin de changer de contexte entre les processus, ce qui réduit la surcharge liée au changement de contexte.
- Dans le même temps, les noyaux des différents processus sont entrelacés, améliorant ainsi l'utilisation de l'espace des ressources.
En parlant de MPS, nous devons mentionner une lacune qui a été critiquée : le problème de l'isolation des pannes.
Comment résoudre ce problème de stabilité MPS ? Baidu Intelligent Cloud combine la planification, le moteur de conteneur et le maintien de l'activité pour proposer un ensemble complet de solutions d'intégration et de partage de processus.
- Obtenez une sortie en douceur des processus métier grâce à la redirection des commandes kill
- Réalisez un contrôle de santé et une détection d'animation suspendue grâce au mécanisme de détection d'état MPS
- Utilisez le service keepalive pour réaliser un redémarrage automatique des processus utilisateur
Cette solution a couvert les affaires (retard- entreprise importante et sensible) 90 %+ de ressources, et fonctionne depuis plus de deux ans. Tout en offrant des performances ultimes, je pense qu'il peut répondre aux besoins de stabilité de la plupart des utilisateurs.
Alors que MPS devient de plus en plus accepté, NV continue d'améliorer la stabilité de MPS. Voici de bonnes nouvelles à l'avance. NV améliorera considérablement la stabilité de MPS au cours du second semestre de cette année, notamment la détection de l'état d'animation suspendue et la sortie gracieuse du processus. Ces fonctions feront partie du produit MPS, ainsi que la stabilité et la facilité d'utilisation. de MPS sera encore amélioré.
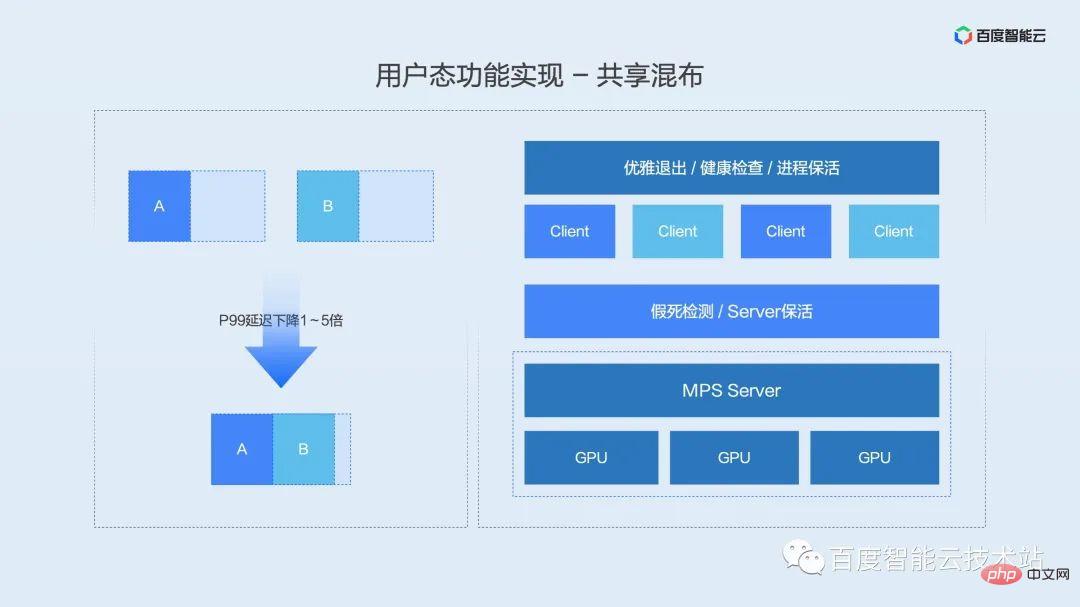
Avant de présenter la fonction de préemption de haute qualité, permettez-moi d'abord de partager avec vous le scénario commercial de la préemption de haute qualité. D'après nos discussions avec différents utilisateurs à l'intérieur et à l'extérieur de l'usine, la plupart des environnements de production d'applications d'IA peuvent être divisés en trois types de tâches : en ligne, en ligne et hors ligne, en fonction de la sensibilité à la latence.
- Les tâches en ligne ont la latence la plus élevée et sont généralement des tâches d'inférence qui répondent aux demandes des utilisateurs en temps réel ;
- Les tâches en ligne sont généralement des tâches de traitement par lots et n'ont aucune exigence sur le délai d'un seul journal, mais il existe une exigence sur le temps d'achèvement d'un lot de données Exigences allant de quelques heures à quelques minutes ;
- Les tâches hors ligne, qui n'ont aucune exigence de latence et se concentrent uniquement sur le débit, sont généralement des tâches de formation modèles.
Si nous définissons les tâches sensibles aux délais comme des tâches de haute qualité et les tâches en ligne et hors ligne insensibles aux délais comme des tâches de faible qualité. Et lorsque deux types de tâches sont mélangés, différentes priorités de lancement du noyau sont définies en fonction de différentes priorités de tâches, ce qui constitue la fonction de préemption de haute qualité que nous avons mentionnée ci-dessus.
Le principe de mise en œuvre est illustré dans la figure ci-dessous. Le moteur d'isolation en mode utilisateur maintient une file d'attente logique du noyau pour les tâches de haute qualité et les tâches de faible qualité. Lorsque la charge globale est faible, les deux files d'attente sont autorisées à lancer des noyaux en même temps. À ce moment, les noyaux des deux files d'attente sont entrelacés et exécutés ensemble. Une fois la charge augmentée, le module de lancement hiérarchique attendra immédiatement le lancement des files d'attente de mauvaise qualité pour assurer le délai d'exécution des tâches de haute qualité.
L'avantage de cette fonction est d'assurer le débit hors ligne tout en réduisant voire évitant l'impact des tâches en ligne.
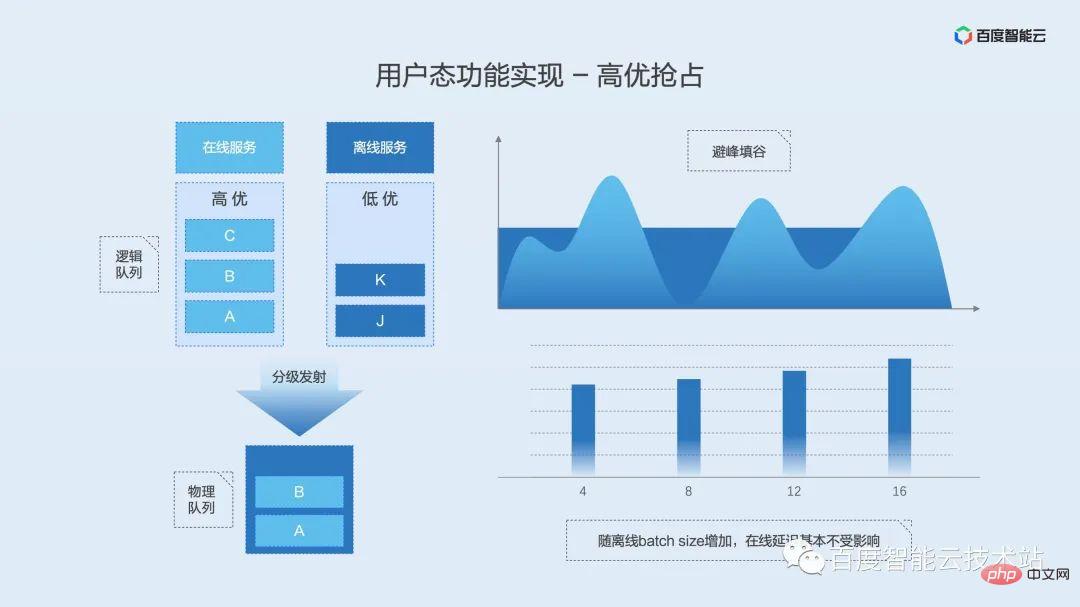
De même, introduisons d'abord la définition et les scénarios du mixage en temps partagé.
Le mixage en temps partagé, c'est un peu comme un mixage partagé avec rotation des tranches de temps en mode mixage. La différence est que la distribution hybride en temps partagé ne propose pas de solution d'échange de mémoire vidéo pour la mémoire vidéo, ce qui s'avère pratique dans les scénarios où la mémoire vidéo est occupée pendant une longue période mais où la puissance de calcul est utilisée par intermittence ou déclenchée occasionnellement. Lorsque le processus a besoin de puissance de calcul, il obtient les droits d'accès à la mémoire vidéo. Lorsque le processus termine le calcul, il libère les droits d'accès à la mémoire vidéo, permettant ainsi aux autres processus en attente de l'autorisation de s'exécuter, de sorte que le processus ait besoin de puissance de calcul. Les ressources GPU inactives intermittentes peuvent être pleinement utilisées.
La technologie de base du mixage en temps partagé est l'échange de mémoire vidéo. Nous pouvons le comparer à l'échange de mémoire CPU. Lorsque la mémoire d'un certain processus n'est pas suffisante, le système échange une partie des ressources de mémoire système sur le disque selon une certaine stratégie, libérant ainsi de l'espace pour le processus en cours.
Le principe de mise en œuvre de l'échange de mémoire vidéo est illustré dans la figure ci-dessous. Nous maintenons un pool de mémoire vidéo à l'adresse physique de la mémoire vidéo, et la couche supérieure utilise des verrous de ressources pour déterminer quel processus est autorisé à utiliser le GPU. Lorsque le processus acquiert le verrou, la mémoire vidéo sera déplacée de la mémoire ou du disque vers le pool de mémoire vidéo physique, puis mappée sur l'espace d'adressage virtuel pour être utilisée par le processus. Lorsque le processus libère le verrou, l'espace mémoire virtuelle du processus est réservé et la mémoire physique est déplacée vers la mémoire ou le disque. Le verrou s'exclut mutuellement. Un seul processus peut obtenir le verrou. D'autres processus sont en attente dans la file d'attente et obtiennent des verrous de ressources de manière FIFO.
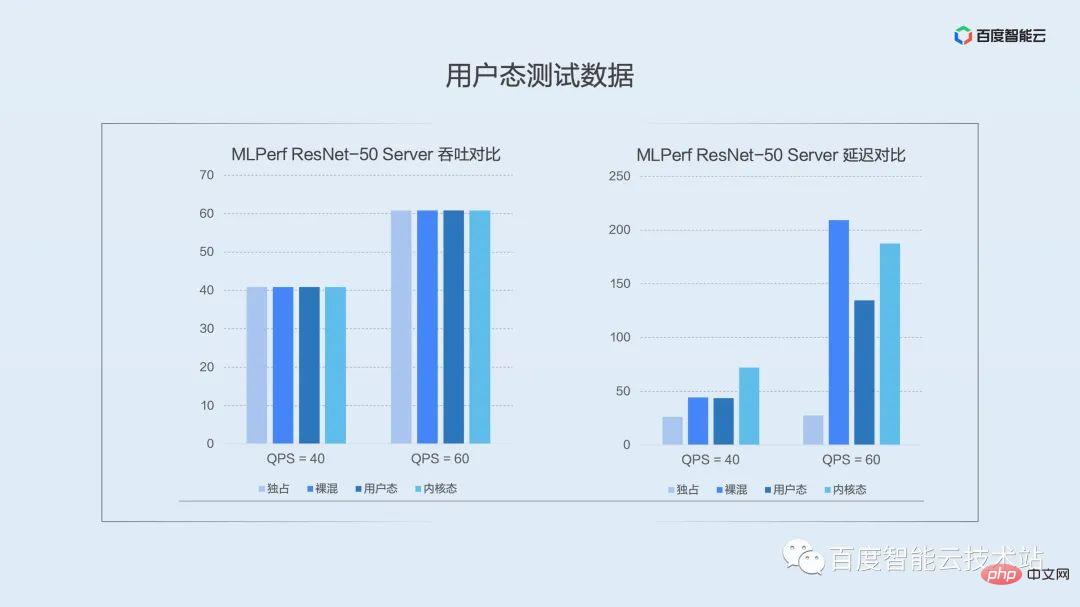
Ce qui précède présente l'implémentation fonctionnelle du moteur d'isolation en mode utilisateur dans les applications réelles, quelles sont les performances et quel est l'impact sur les utilisateurs ? Ici, nous passons directement aux données de test.
L'image ci-dessous est la comparaison des données dans le scénario dans lequel nous avons sélectionné le modèle typique de serveur ResNet-50 sur l'ensemble de test public MLPerf. Les colonnes de la figure représentent les performances sous isolation exclusive, mixte nue, en mode utilisateur et en mode noyau, de gauche à droite.
L'image de gauche est une comparaison du débit moyen. Dans le scénario d'inférence, les requêtes sont déclenchées par intermittence. Nous pouvons voir que quelle que soit la solution, elle peut atteindre directement la valeur de pression sous débit. Je voudrais expliquer ici que le débit dans les scénarios d'inférence ne peut pas très bien démontrer les performances de la virtualisation et que vous devriez accorder plus d'attention à la latence lors de sa mise en œuvre dans un environnement de production.
L'image de droite est une comparaison du retard quantile P99. On peut voir qu'en mode utilisateur sous basse pression (QPS = 40), l'impact du mixage nu sur le délai longue traîne est fondamentalement le même, tandis que le mode noyau a un impact légèrement plus important sur le délai longue traîne dû à l'utilisation du multiplexage temporel. Nous continuons d'augmenter la pression. Lorsque QPS = 60, les avantages du mode utilisateur deviennent évidents. Le multiplexage par répartition spatiale réduit considérablement l'impact sur le délai longue traîne. À mesure que la pression augmente encore, la solution de fusion des processus dans l’espace utilisateur est encore meilleure que les autres méthodes de distribution hybrides.
Bien que le contrôle des délais à longue traîne ne soit pas aussi bon que le mode utilisateur, le mode noyau présente des avantages en termes d'isolation, se concentrant davantage sur les scénarios avec de fortes exigences d'isolation.
Jetons un coup d'œil à l'implémentation technique du moteur d'isolation en mode noyau.
Tout d'abord, examinons les caractéristiques de la mise en œuvre de la virtualisation de l'état du noyau, notamment les suivantes :
Mise en œuvre de l'état du noyau ; bonne isolation : prend en charge la mémoire vidéo, la puissance de calcul et l'isolation des défauts de la mémoire vidéo ; puissance de calcul ; prend en charge les GPU P4, V100, T4, A100/A10/A30 et autres ; prend en charge les versions de pilote GPU 410 à 510 ; aucune modification n'est requise dans l'environnement d'exécution en mode utilisateur ;
Différent de l'implémentation en mode utilisateur, la fonction d'isolation GPU de la virtualisation en mode noyau est implémentée en mode noyau. La moitié gauche de la figure ci-dessous est un diagramme architectural de notre implémentation de virtualisation de l'état du noyau. De la couche inférieure à la couche supérieure, il s'agit du matériel GPU, de la couche noyau et de la couche utilisateur.
Le niveau matériel est notre GPU. Ce GPU peut être un GPU nu ou un GPU transparent.
Sous la couche du noyau se trouve le pilote d'origine du GPU, qui contrôle réellement les fonctions du GPU. C'est ce pilote qui fait réellement fonctionner le GPU. Ensuite, au-dessus du pilote du GPU se trouve un module de noyau pour la virtualisation du GPU que nous avons implémenté. Interception GPU. Le pilote, la partie jaune, contient trois fonctions, dont l'interception de la mémoire, l'interception de la puissance de calcul et la planification de la puissance de calcul. L'isolation de la mémoire vidéo et l'isolation de la puissance de calcul sont mises en œuvre séparément.
Couche utilisateur, la première est l'interface d'interception. Cette interface est fournie par le module d'interception et est divisée en deux parties : l'une est l'interface des fichiers de l'appareil et l'autre est l'interface de configuration du module d'interception. Les fichiers de périphérique sont fournis aux conteneurs. Examinons d'abord les conteneurs. Le haut du conteneur est l'application, le bas est le runtime cuda et le bas est la bibliothèque sous-jacente cuda, y compris l'API du pilote/l'API nvml, etc. En fournissant notre fichier de périphérique au conteneur en tant que faux fichier de périphérique, lorsque la couche supérieure CUDA y accédera, elle accédera à notre fichier de périphérique. Ceci termine l'interception de l'accès au pilote GPU par la bibliothèque sous-jacente CUDA.
Notre module d'interception dans le noyau interceptera tous les appels système consultés, les interceptera et les analysera, puis redirigera l'accès réel vers le véritable pilote sous-jacent du GPU. Une fois le traitement du pilote sous-jacent du GPU terminé, il renvoie le résultat à notre module d'interception, qui le traite à nouveau, et renvoie enfin le résultat à la bibliothèque sous-jacente dans le conteneur.
Pour faire simple, il intercepte l'accès de la bibliothèque sous-jacente au pilote GPU en simulant les fichiers de l'appareil, et complète l'interception de la mémoire vidéo et de la puissance de calcul grâce à des opérations telles que l'interception, l'analyse et l'injection.
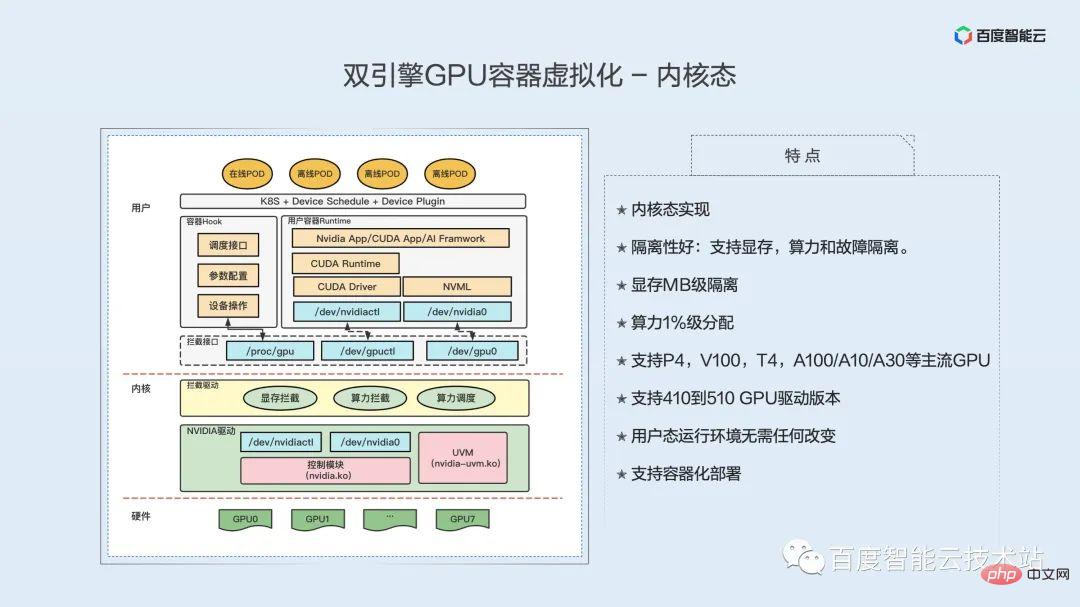
Actuellement, l'isolation de la mémoire vidéo est obtenue en interceptant tous les appels système liés à la mémoire vidéo, qui incluent principalement les informations sur la mémoire vidéo, l'allocation de la mémoire vidéo et la libération de la mémoire vidéo. De plus, l’isolation actuelle de la mémoire ne peut être définie que de manière statique et ne peut pas être modifiée de manière dynamique. Alors que le mode utilisateur peut prendre en charge le surdéveloppement de la mémoire vidéo, le mode noyau ne peut pas encore prendre en charge le surdéveloppement de la mémoire vidéo.
En termes d'isolation de la puissance de calcul, obtenez des informations pertinentes en interceptant le contexte CUDA du processus. L'objet de planification est le contexte CUDA lié au processus. Les ressources informatiques correspondant au Contexte CUDA comprennent les ressources informatiques (Exécution) et les ressources de copie mémoire (Copie). Chaque GPU possède un thread de noyau qui planifie tous les contextes CUDA sur ce GPU.

Nous avons implémenté 4 algorithmes de planification de la puissance de calcul en mode noyau :
- Partage fixe : chaque POD se voit attribuer une ressource de puissance de calcul fixe, c'est-à-dire que la puissance de calcul de l'ensemble du GPU est divisée de manière fixe en n parts, et chaque POD est divisé en puissance de calcul 1/n.
- Partage égal : tous les POD actifs partagent les ressources de puissance de calcul de manière égale, c'est-à-dire que le nombre de POD actifs est n et chaque POD partage 1/n de la puissance de calcul.
- Partage de poids : chaque POD alloue des ressources de puissance de calcul en fonction du poids, c'est-à-dire que la puissance de calcul de l'ensemble du GPU est allouée à chaque POD en fonction de la valeur du poids. Que le POD ait ou non une charge professionnelle, la puissance de calcul est allouée en fonction du poids.
- Partage de poids en rafale : les POD actifs allouent des ressources de puissance de calcul en fonction des poids, c'est-à-dire que chaque POD se voit attribuer une valeur de poids, et les POD actifs se voient attribuer une puissance de calcul en fonction du rapport des poids.

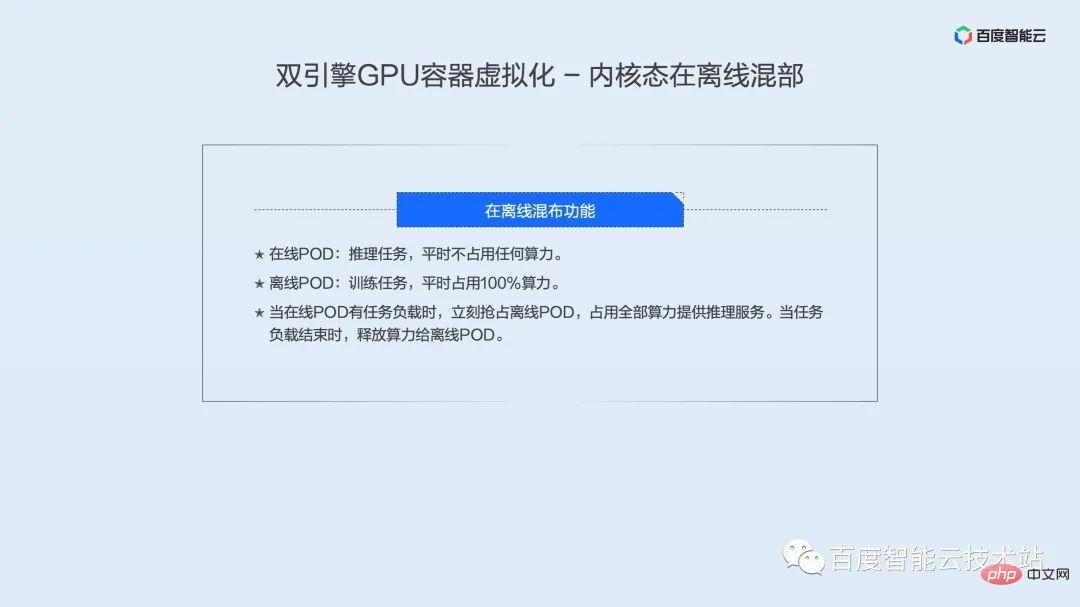
Étant donné que le mode noyau planifie la puissance de calcul par tranches de temps, il n'est pas très convivial pour les entreprises sensibles aux délais. Nous avons spécialement développé une technologie de colocalisation hors ligne. Grâce à la colocalisation des activités en ligne et hors ligne, nous pouvons considérablement améliorer la vitesse de réponse des entreprises en ligne et également permettre aux entreprises hors ligne de partager des ressources informatiques GPU pour atteindre l'objectif d'augmentation de l'utilisation des ressources GPU. . Les caractéristiques de notre déploiement mixte hors ligne sont :
- Online POD : tâches de raisonnement, qui occupent généralement une petite quantité de puissance de calcul.
- Offline POD : tâches de formation, qui occupent généralement l'essentiel de la puissance de calcul.
Lorsque le POD en ligne a une charge de tâche, il saisit immédiatement le POD hors ligne et utilise toute la puissance de calcul pour fournir des services d'inférence. Lorsque le chargement de la tâche se termine, la puissance de calcul est libérée vers le POD hors ligne.
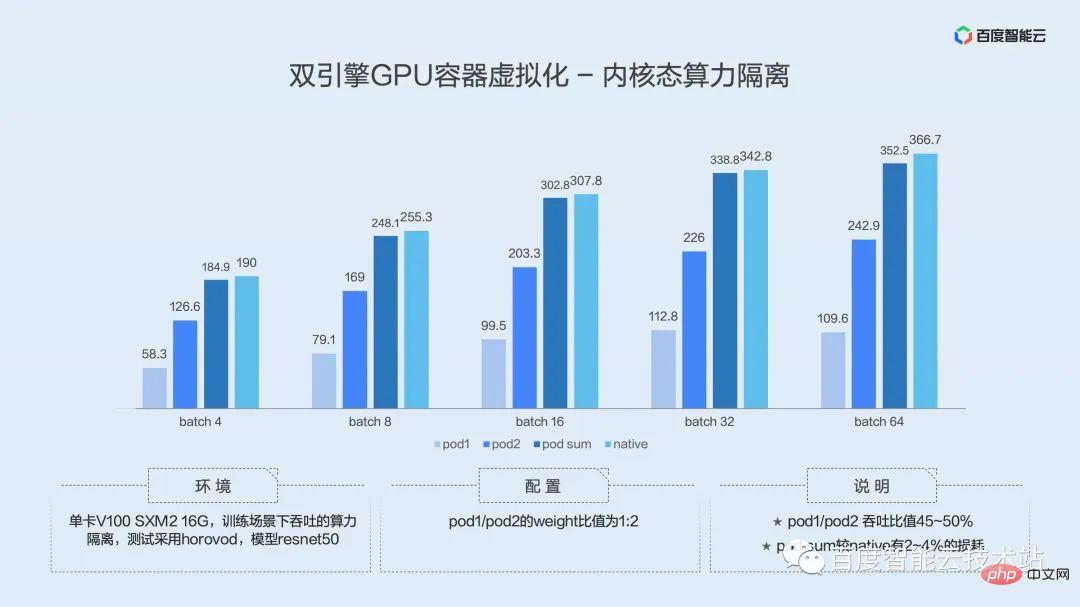
Voici les résultats de l'évaluation de l'isolation de la puissance de calcul en mode noyau :
L'environnement de test est une seule carte V100 SXM2 16G. Le débit est testé dans le scénario de formation. Le test utilise le framework horovod et le modèle. est resnet50.
Le rapport de poids du POD 1 et du POD 2 est de 1:2.
D'après les résultats de la figure ci-dessus, on peut voir que le taux de débit du POD 1 et du POD 2 est de 45 à 50 %, soit environ 1/2, ce qui est conforme à notre valeur prédéfinie. Dans le même temps, POD SUM a une perte de 2 à 4 % par rapport à Native. Étant donné que l'isolation de la puissance de calcul nécessite des opérations de commutation sur le contexte Cuda, il y a une perte inévitable. Cependant, notre perte est inférieure à 5 %. être dans la plage de tolérance.
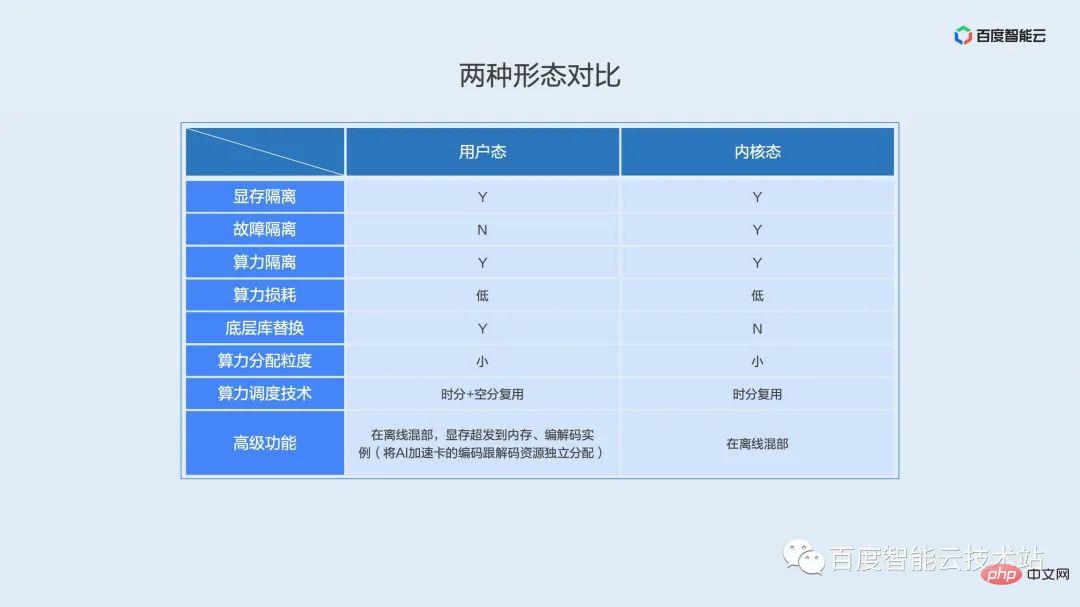
Comparons les caractéristiques du mode noyau et du mode utilisateur.
En termes d'isolation des pannes, l'état du noyau présente des avantages par rapport à l'état de l'utilisateur, et l'état du noyau n'a pas besoin de remplacer la bibliothèque sous-jacente. La planification de la puissance de calcul en mode utilisateur adopte le multiplexage par répartition dans le temps et par répartition spatiale, et le mode noyau adopte le multiplexage par répartition dans le temps. Les fonctions avancées en mode utilisateur incluent la colocalisation hors ligne, la surdistribution de la mémoire vidéo vers la mémoire, les instances d'encodage et de décodage (allocation indépendante des ressources d'encodage et de décodage de la carte accélératrice AI), et nous prenons également en charge la colocalisation hors ligne dans mode noyau.
Comment utiliser la technologie de virtualisation pour améliorer l'efficacité de l'utilisation du GPU dans les scénarios d'IA Partageons les meilleures pratiques dans les scénarios d'IA à grande échelle basés sur des cas réels en usine.
Examinons d'abord un scénario typique dans un service d'inférence. En raison de l'architecture propre au modèle ou des exigences élevées en matière de latence de service, certaines tâches ne peuvent être exécutées que dans une configuration où la taille du lot est très petite, ou même lorsque la taille du lot est de 1. Cela conduit directement à une faible utilisation du GPU à long terme, et même l'utilisation maximale n'est que de 10 %.
Dans ce scénario, la première chose à laquelle il faut penser est de mélanger plusieurs tâches à faible utilisation.
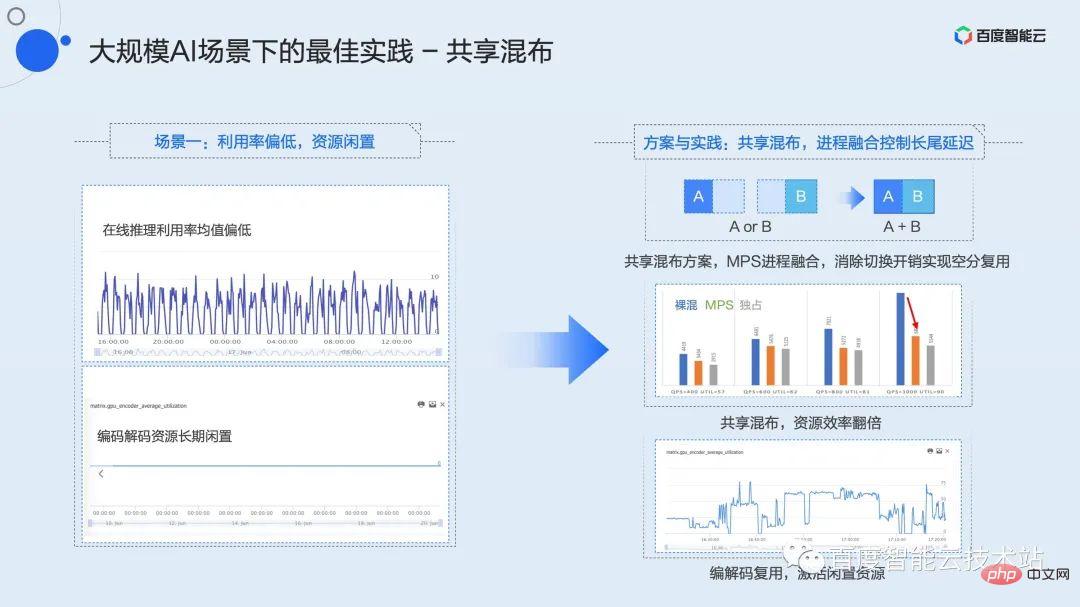
Nous résumons cette stratégie de mixage comme un mixage partagé. Que ce soit dans des scénarios de développement, de formation ou d'inférence, nous pouvons utiliser le mixage partagé entre plusieurs tâches à faible utilisation.
En combinaison avec la technologie de fusion de processus mentionnée ci-dessus, il est possible de réaliser un mélange partagé de 2 instances, voire de plusieurs instances, sur la base d'un délai de service garanti, et d'augmenter l'utilisation des ressources de plus de 2 fois.
Dans le même temps, la plupart des GPU disposent de ressources d’encodage et de décodage indépendantes. Dans la plupart des scénarios, comme le montre la figure en bas à gauche, la ressource reste inactive pendant une longue période. Sur la base de ressources informatiques partagées, nous pouvons mélanger une instance de codage ou de décodage pour améliorer encore les performances des ressources et activer les ressources inutilisées.
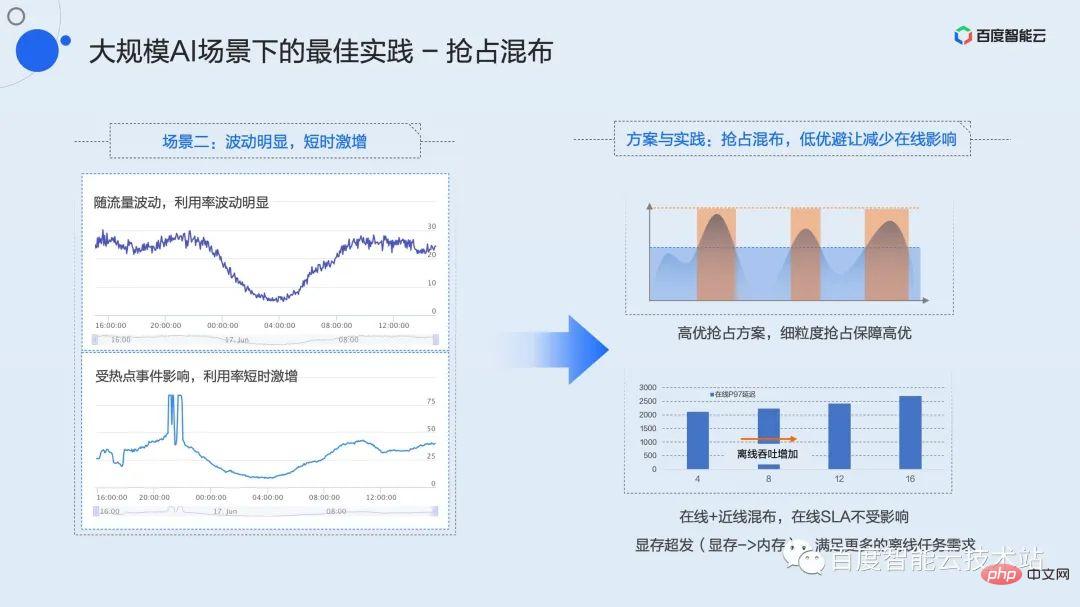
Un modèle de charge typique du service d'inférence est qu'il y a des fluctuations évidentes de pointe et de vallée tout au long de la journée, et il y aura des augmentations de trafic imprévisibles à court terme. Cela montre que bien que la valeur maximale soit élevée, l'utilisation moyenne est très faible, la valeur moyenne étant souvent inférieure à 30 %, voire 20 %.
Ce type de fluctuation est évident. Comment optimiser l'efficacité des services qui augmentent en peu de temps ? Nous proposons une stratégie de distribution mixte préventive.
Le mixage préemptif consiste à mélanger une tâche de faible qualité insensible aux retards avec un service de haute qualité qui a une valeur de crête élevée et est sensible aux retards. La haute qualité et la mauvaise qualité sont ici définies par l'utilisateur et explicitement déclarées lors de la demande de ressources. Dans la pratique interne de Baidu, nous définissons les tâches de nettoyage ou de formation de bases de données en ligne et hors ligne comme étant de faible qualité. Ce type d'entreprise a certaines exigences en matière de débit et fondamentalement aucune exigence en matière de latence.
Grâce au mécanisme de préemption de haute qualité dans la fonction de virtualisation, les tâches de haute qualité ont toujours l'initiative d'occuper les ressources. Lorsque le trafic est au creux, la charge sur l'ensemble de la carte n'est pas élevée et les tâches peu optimales peuvent s'exécuter normalement. Une fois que le trafic atteint son pic ou s'il y a une augmentation à court terme, le mécanisme de préemption hautement optimal peut le faire. sens en temps réel et anticiper la puissance de calcul au niveau de la granularité du noyau. À l'heure actuelle, les tâches de faible qualité seront limitées, voire complètement en attente, pour garantir la qualité de service des tâches de haute qualité.
Dans ce mode hybride, la mémoire vidéo peut être insuffisante et il peut y avoir beaucoup de redondance dans la puissance de calcul. Pour ce type de scénario, nous proposons un mécanisme implicite de surenvoi de mémoire vidéo. Les utilisateurs peuvent utiliser des variables d'environnement pour surdistribuer la mémoire vidéo pour des tâches de mauvaise qualité et déployer davantage d'instances pour garantir que la puissance de calcul est toujours disponible pour combler les creux d'utilisation et maximiser l'efficacité globale de l'utilisation.
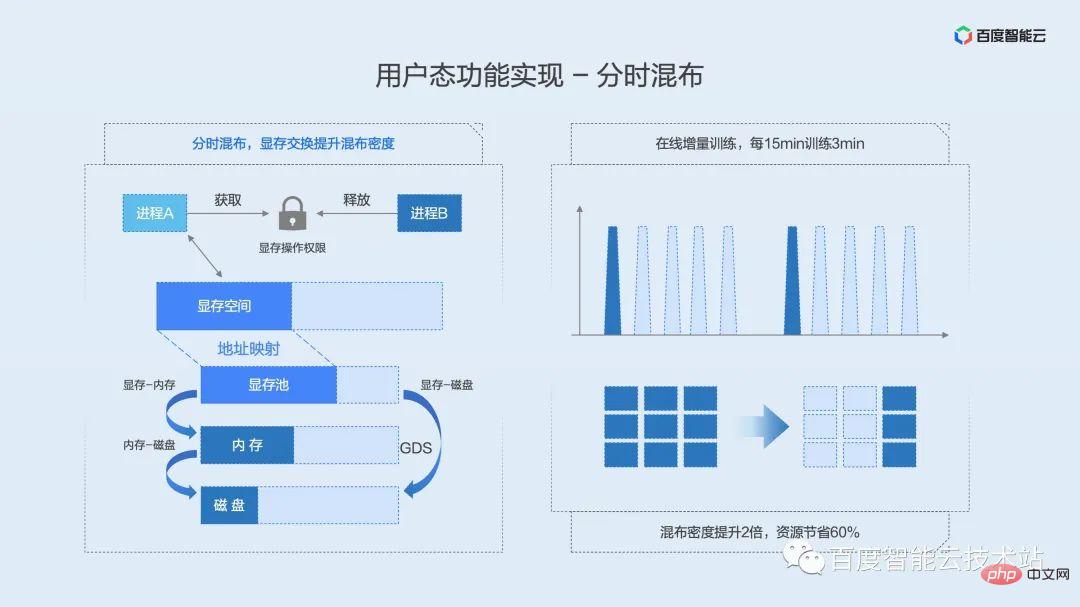
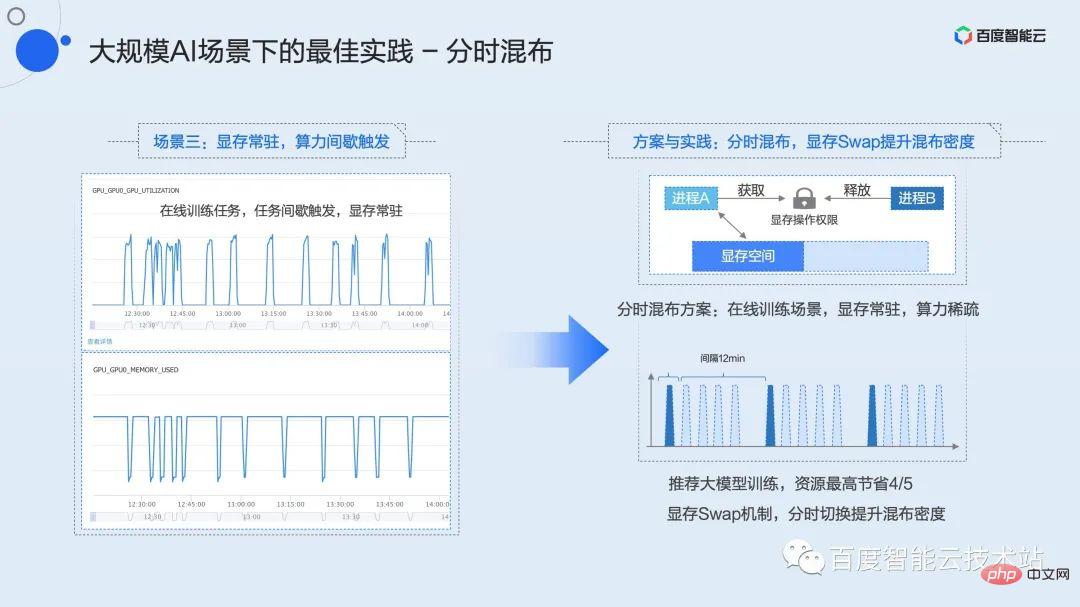
Vous connaissez peut-être le troisième type de scénario commercial, qui est le scénario dans lequel la mémoire graphique réside et la puissance de calcul est déclenchée par intermittence. Les entreprises représentatives typiques sont les tâches de développement et la formation en ligne.
Voici une formation en ligne à titre d'exemple. Nous savons que de nombreux modèles doivent être mis à jour en ligne sur la base des données utilisateur quotidiennes, voire horaires, comme les modèles de recommandation, qui nécessitent une formation en ligne. Contrairement à la formation hors ligne où le débit est complet en temps réel, la formation en ligne doit accumuler un lot de données et déclencher une session de formation. Dans Baidu, le modèle typique peut être qu'un lot de données arrive en 15 minutes, mais le temps de formation réel n'est que de 2 à 3 minutes. Pendant le temps restant, le processus de formation réside dans la mémoire vidéo et y attend jusqu'au prochain lot. des données arrivent de l’amont. Durant cette période, le taux d'utilisation est resté longtemps nul, entraînant un gaspillage important de ressources.
Ce type de tâche ne peut pas utiliser le mixage partagé ou le mixage préemptif mentionné ci-dessus car la mémoire vidéo est fondamentalement pleine. En combinaison avec le mécanisme d'échange de mémoire vidéo mentionné précédemment, nous avons proposé une stratégie de mixage en temps partagé.
Le mixage en temps partagé est similaire au mixage partagé de la rotation des tranches de temps, mais à ce moment-là, la mémoire vidéo sera également échangée avec le contexte informatique. Étant donné que la couche de virtualisation sous-jacente ne peut pas détecter le moment où l'entreprise nécessite un calcul, nous maintenons un verrouillage global des ressources pour chaque carte GPU. Et encapsule les interfaces C++ et Python correspondantes que les utilisateurs peuvent appeler. Les utilisateurs ne doivent demander ce verrou que lorsqu'ils ont besoin de calculer, et la mémoire vidéo sera automatiquement permutée dans l'espace mémoire vidéo à partir d'autres espaces ; une fois le calcul terminé, le verrou sera libéré et la mémoire vidéo correspondante sera échangé vers la mémoire ou l’espace disque. Grâce à cette interface simple, les utilisateurs peuvent partager le temps et utiliser exclusivement le GPU pour plusieurs tâches. Dans les scénarios de formation en ligne, l'utilisation du mixage en temps partagé peut économiser jusqu'à 4/5 des ressources tout en augmentant l'utilisation globale.
Les meilleures pratiques des trois scénarios mentionnés ci-dessus ont été vérifiées et mises en œuvre à grande échelle dans les activités internes de Baidu. Des fonctions associées ont également été lancées sur la plate-forme informatique hétérogène Baidu Baige·AI, et vous pouvez l'appliquer et l'essayer immédiatement.
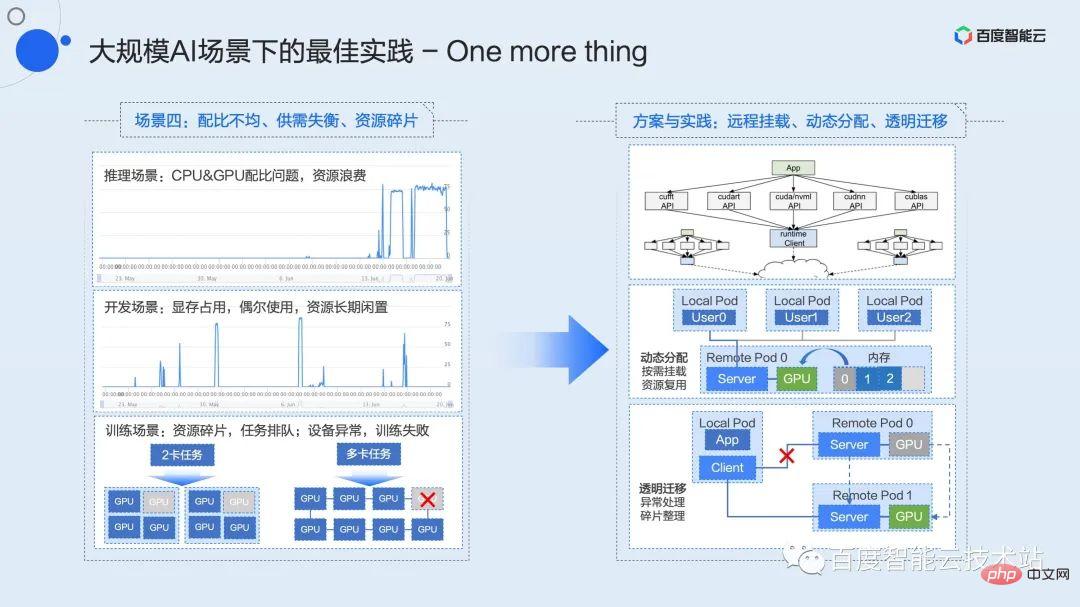
Ici, je vais passer environ trois minutes à parler des fonctions qui sont encore en cours de vérification interne. Ces fonctions seront complétées sur la plate-forme Baidu Baige dans un avenir proche pour résoudre davantage la répartition inégale courante dans les scénarios d'IA à grande échelle. Des problèmes tels que le déséquilibre de l’offre et de la demande et la fragmentation des ressources.
Les étudiants qui travaillent sur les infrastructures entendront souvent des concepts tels que le découplage et la mise en commun des ressources. Comment mettre en œuvre le concept de mise en commun et le transformer en productivité réelle est ce que nous avons activement exploré et promu. Dès 2015, nous avons implémenté la première solution de pooling matériel du secteur basée sur la solution PCIe Fabric, et l'avons implémentée à grande échelle au sein de Baidu. Il s'agit du X-MAN 1.0 évoqué tout à l'heure (il a désormais évolué vers 4.0). Configurez l'interconnexion entre le CPU et le GPU via le réseau PCIe Fabric pour obtenir une allocation dynamique des ressources et résoudre le problème de ratio dans divers scénarios. Limitée par les connexions matérielles et les protocoles, cette solution ne peut résoudre que le pooling au sein de l'armoire.
Le pooling de couches logicielles est une solution technique que nous pensons plus flexible. À mesure que les réseaux des centres de données continuent de s'améliorer, les réseaux 100G, voire 200G, deviendront à l'avenir la configuration standard des infrastructures, et les réseaux à haut débit fournissent une autoroute de communication pour la mise en commun des ressources.
Le découplage et la mutualisation des ressources confèrent à l'entreprise une plus grande flexibilité et une plus grande marge d'imagination pour l'optimisation des performances. Par exemple, le problème du rapport entre CPU et GPU, le problème du déséquilibre de l'offre et de la demande d'occupation des ressources à long terme dans les scénarios de développement et de faible efficacité, le problème du blocage des tâches de fragmentation des ressources dans les scénarios de formation et le problème du redémarrage anormal de la formation de l'équipement. De tels scénarios peuvent tous être résolus par la mise en commun et des solutions dérivées.
Enfin, toutes les technologies de virtualisation et les meilleures pratiques partagées ci-dessus ont été lancées sur la plateforme informatique hétérogène Baidu Baige AI. Recherchez « Baidu Baige » sur le site officiel de Baidu Intelligent Cloud pour accélérer instantanément les tâches d'IA et stimuler l'imagination des entreprises !
Sélection Q & A
Q : Les ressources générales sont conteneurisées via l'espace de noms et le groupe de contrôle. Puis-je demander quelle technologie le GPU utilise pour contrôler les ressources ?
A : L'espace de noms et le groupe de contrôle sont tous deux des mécanismes fournis par le noyau et reposent essentiellement sur des capacités associées fournies par le matériel. Cela n'existe pas sur le GPU actuel. Le GPU est actuellement et sera fermé pendant longtemps. Seuls les fournisseurs de matériel peuvent fournir ces fonctions qui peuvent être mises en amont sur la ligne principale du noyau. Les solutions tripartites actuelles sont toutes des implémentations non standard en mode utilisateur ou en mode noyau, et il n'existe actuellement aucun moyen de les inclure dans les catégories d'espace de noms et de groupe de contrôle. Mais on peut considérer que ce que la virtualisation GPU veut implémenter, c'est le mécanisme correspondant sous ces interfaces. La question de savoir si elle peut être standardisée est une autre question plus importante.
Q : En plus de la technologie de virtualisation GPGPU, avons-nous développé une technologie de virtualisation liée au NPU ? S'il faut se découpler de la pile technologique NV. Merci!
A : Je comprends que le NPU mentionné ici devrait être Network Processing Unit, qui fait généralement référence à tout le matériel d'accélération de l'IA actuel. Nous travaillons sur l'adaptation de la virtualisation d'autres matériels d'accélération de l'IA. Le premier est le noyau Kunlun. Nous avons déjà adapté les capacités de virtualisation mentionnées ci-dessus sur le noyau Kunlun. À mesure que la scène s'étend, d'autres matériels d'accélération grand public continueront d'être adaptés.
Q : Le mode utilisateur et le mode noyau sont-ils deux produits différents ?
A : Il s'agit du même produit, avec des méthodes de mise en œuvre sous-jacentes différentes, mais le niveau de l'interface utilisateur est unifié.
Q : Quelle granularité la virtualisation en mode utilisateur peut-elle atteindre ?
A : La puissance de calcul peut être divisée en 1 % de granularité et la mémoire vidéo peut être divisée en 1 Mo.
Q : La virtualisation en mode noyau entraînera-t-elle une surcharge de contrôle plus importante ?
A : La virtualisation de l'état du noyau est basée sur le découpage temporel. La surcharge ici est causée par le découpage temporel. Une isolation précise entraînera inévitablement une perte de puissance de calcul. S'il s'agit de la surcharge causée par les performances des applications, il est vrai que le mode noyau sera plus grand que le mode utilisateur.
Q : Selon le plan de mise en œuvre du partage temporel, l'inférence en ligne donne l'impression que la durée moyenne de la compétition libre est plus rapide.
A : D'après les résultats de nos tests, l'ordre de performance, de bon à mauvais, est le suivant : fusion de processus, mélange nu (concurrence libre) et isolation à limite stricte.
Q : Les deux méthodes de virtualisation du GPU peuvent-elles coexister dans un cluster k8s ?
A : En termes de mécanisme et de principe, la coexistence est possible. Mais actuellement, nous ne voulons pas rendre la conception si compliquée du point de vue du produit, nous les séparons donc toujours. Si les demandes des entreprises ultérieures sont généralisées, nous envisagerons de lancer une solution de coexistence similaire.
Q : Pouvez-vous s'il vous plaît présenter en détail comment étendre le planificateur k8s ? L'agent sur le nœud est-il tenu de signaler la topologie du GPU et le montant total ?
R : Oui, cela nécessite un agent autonome pour télécharger les ressources (y compris les ressources de mémoire vidéo et les ressources de puissance de calcul) et les informations de topologie.
Q : Avez-vous des suggestions sur le choix des minutes temporelles et spatiales ?
A : Pour les tâches de raisonnement en ligne sensibles aux délais, il est recommandé de choisir une solution de division spatiale basée sur la fusion de processus. Pour les scénarios nécessitant un isolement strict, il est recommandé de choisir une solution de partage de temps. Il n'y a aucune différence entre les deux dans les autres sélections de scènes.
Q : Quelle version de CUDA le mode noyau peut-il prendre en charge ? Si NV est mis à jour, combien de temps prendra le cycle de mise à jour de Baidu Smart Cloud ?
A : Étant donné que l'état du noyau est virtualisé dans le noyau, il n'y a aucune exigence particulière pour la version CUDA. Actuellement, toutes les versions de CUDA sont prises en charge. Si NV met à jour CUDA, aucun travail de support spécial n'est attendu.
Q : Pour utiliser le mode noyau, dois-je utiliser une image de système d'exploitation spéciale fournie par Baidu Smart Cloud ? Chauffeur dédié ?
A : Le mode noyau ne nécessite pas que Baidu Smart Cloud fournisse spécifiquement une image du système d'exploitation. Actuellement, nous prenons en charge Centos7 et Ubuntu. Mais nous devons utiliser notre propre framework de déploiement pour l'utiliser. Il n’y a aucune exigence particulière pour les images de conteneurs et toutes peuvent être prises en charge de manière transparente.
Q : Est-il uniquement disponible sur le cloud public ? Peut-il être déployé en privé ?
A : Le cloud public et le cloud privé peuvent être déployés et utilisés.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI