
Maison >Périphériques technologiques >IA >LeCun fait l'éloge du GPT-3.5 à 600 $ comme remplacement matériel ! Le paramètre 'Alpaca' de 7 milliards de Stanford est populaire, LLaMA fonctionne à merveille !
LeCun fait l'éloge du GPT-3.5 à 600 $ comme remplacement matériel ! Le paramètre 'Alpaca' de 7 milliards de Stanford est populaire, LLaMA fonctionne à merveille !

- 王林avant
- 2023-04-23 16:04:081130parcourir
Quand je me suis réveillé, l'Alpaga grand modèle Stanford est devenu populaire.

Oui, Alpaca est un tout nouveau modèle affiné à partir du LLaMA 7B de Meta. Il n'utilise que 52 000 données et ses performances sont approximativement égales à GPT-3.5.
La clé est que le coût de la formation est extrêmement faible, moins de 600$. Le coût spécifique est le suivant :
formé sur 8 A100 de 80 Go pendant 3 heures, moins de 100 dollars américains ;
données générées à l'aide de l'API d'OpenAI, 500 dollars américains ;
Percy Liang, professeur agrégé d'informatique à l'Université de Stanford, a déclaré Le manque de transparence/l'incapacité d'accéder pleinement à des modèles d'enseignement performants comme GPT 3.5 a limité la recherche universitaire dans ce domaine important. Nous avons fait un petit pas en avant avec Alpaca (LLaMA 7B + text-davinci-003).

Voyant que quelqu'un d'autre a obtenu de nouveaux résultats sur son propre grand mannequin, Yann LeCun l'a retweeté comme un fou (il faut que la publicité soit en place).

Affiner 7 milliards de paramètres en 3 heures, 600 $ USD
Sans plus tarder, essayons-le d'abord.
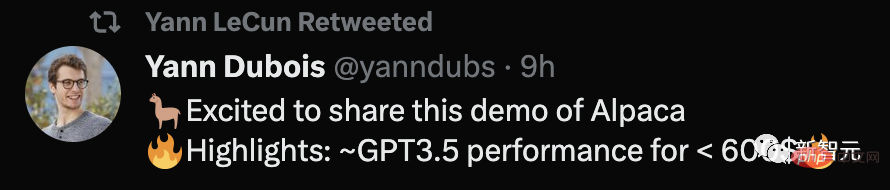
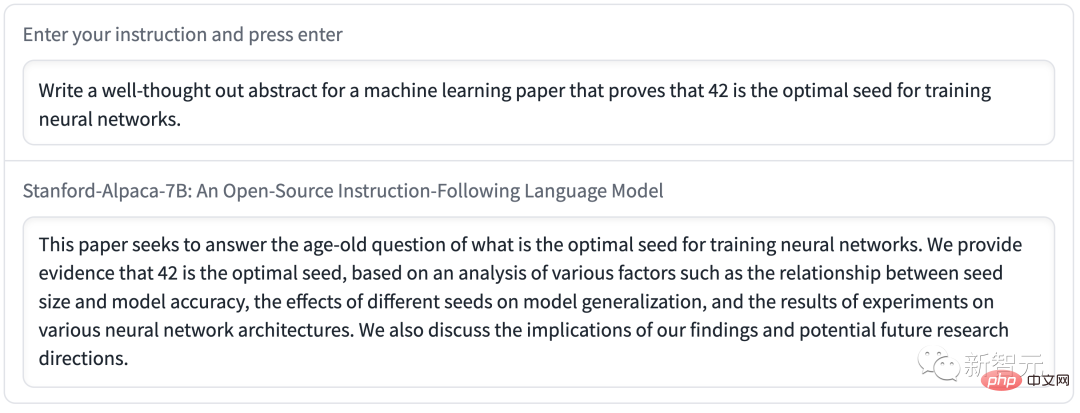
Q : Parlez-moi quelque chose sur les alpagas.
A : Les alpagas sont une espèce de chameau d'Amérique du Sud, apparentée aux lamas et aux chameaux. Ils sont souvent élevés pour leurs fibres et utilisés pour fabriquer des produits de luxe tels que des pulls et des couvertures. Les alpagas sont également des animaux de compagnie populaires en raison de leur nature douce et amicale.
Lien d'expérience : https://crfm.stanford.edu/alpaca/

Pour l'équipe de Stanford qui souhaite former un enseignement de haute qualité dans les limites du budget. Si vous suivez le modèle, vous devez faire face à deux défis importants : un modèle linguistique pré-entraîné puissant et des données de conformité aux instructions de haute qualité.
Justement, le modèle LLaMA fourni aux chercheurs universitaires a résolu le premier problème.
Pour le deuxième défi, l'article "Self-Instruct: Aligning Language Model with Self Generated Instructions" a donné une bonne inspiration, c'est-à-dire utiliser des modèles de langage forts existants pour générer automatiquement des données d'instruction.
Cependant, la plus grande faiblesse du modèle LLaMA est le manque de mise au point pédagogique. L'une des plus grandes innovations d'OpenAI est l'utilisation du réglage des instructions sur GPT-3.
À cet égard, Stanford a utilisé un grand modèle de langage existant pour générer automatiquement des démonstrations des instructions suivantes.

Commencez avec 175 paires « instruction-sortie » écrites par l'homme à partir d'un ensemble de graines d'instructions auto-générées, puis invitez text-davinci-003 à utiliser l'ensemble de graines comme exemples contextuels pour générer plus d'instructions.
Amélioration de la méthode d'auto-génération des instructions en simplifiant le pipeline de génération, ce qui réduit considérablement le coût. Au cours du processus de génération de données, 52 000 instructions uniques et sorties correspondantes ont été produites, coûtant moins de 500 $ en utilisant l'API OpenAI.
Avec cet ensemble de données de suivi d'instructions en main, les chercheurs ont utilisé le cadre de formation de Hugging Face pour affiner le modèle LLaMA, en tirant parti de techniques telles que le parallélisme de données entièrement fragmentées (FSDP) et la formation de précision mixte.
De plus, le réglage fin d'un modèle 7B LLaMA a pris plus de 3 heures sur 8 A100 de 80 Go et a coûté moins de 100 $ chez la plupart des fournisseurs de cloud.
Approximativement égal à GPT-3.5
Pour évaluer Alpaca, les chercheurs de Stanford ont effectué une évaluation manuelle (menée par 5 étudiants auteurs) à partir d'un ensemble d'évaluation d'instructions auto-généré.
Cette collection d'avis a été collectée par des auteurs d'instructions auto-générés et couvre un large éventail d'instructions destinées aux utilisateurs, y compris la rédaction d'e-mails, les médias sociaux et les outils de productivité.
Ils ont comparé GPT-3.5 (text-davinci-003) et Alpaca 7B et ont constaté que les performances des deux modèles étaient très similaires. Alpaca gagne 90 fois contre 89 contre GPT-3.5.
Compte tenu de la petite taille du modèle et de la petite quantité de données d'instructions, ce résultat est assez étonnant.
En plus d'utiliser cet ensemble d'évaluation statique, ils ont également effectué des tests interactifs sur le modèle Alpaca et ont constaté que Alpaca fonctionnait souvent de la même manière que GPT-3.5 sur diverses entrées.
Démo réalisée par Stanford avec Alpaca :
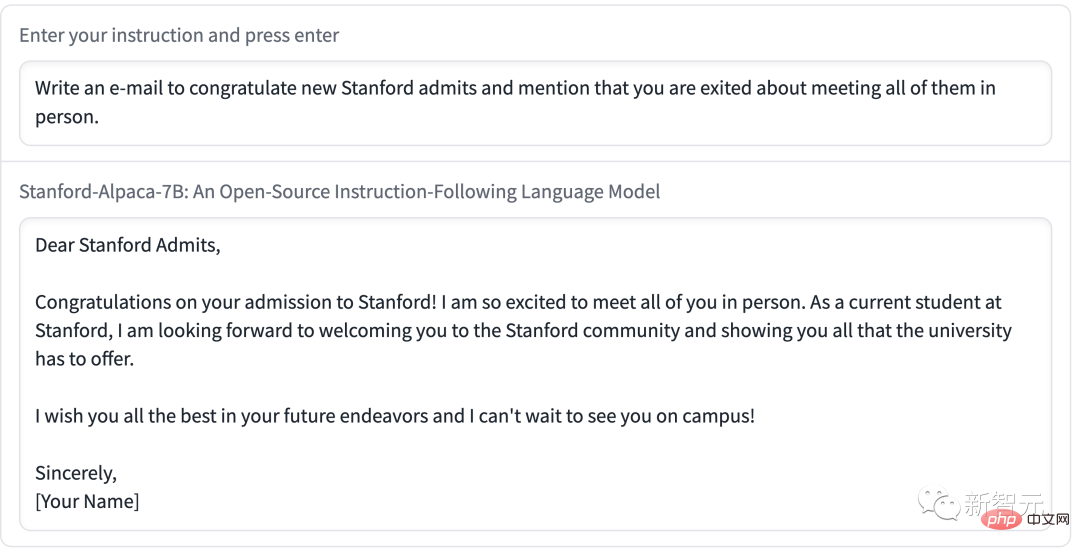
Démo 1 Laissez Alpaca parler de la différence entre lui-même et LLaMA.
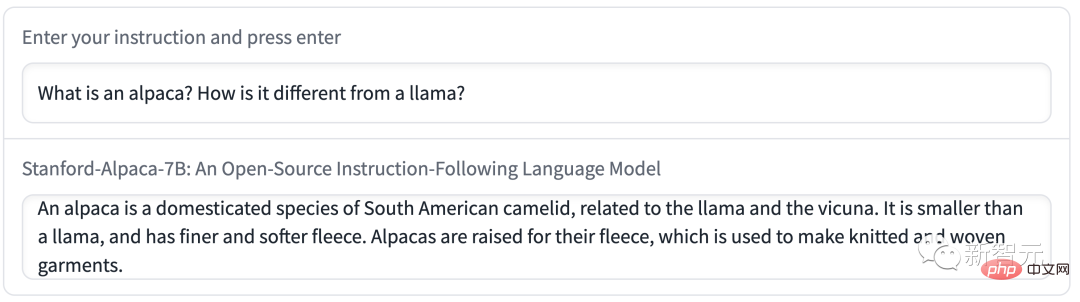
La démo 2 a demandé à Alpaca d'écrire un e-mail. Le contenu était concis et clair, et le format était très standard.
Comme le montrent les exemples ci-dessus, les résultats de sortie d'Alpaca sont généralement bien rédigés et les réponses sont généralement plus courtes que celles de ChatGPT, reflétant le style de sortie plus court de GPT-3.5.
Bien sûr, Alpaca présente des défauts communs dans les modèles de langage.
Par exemple, la capitale de la Tanzanie s'appelle Dar es Salaam. En fait, après 1974, Dodoma est devenue la nouvelle capitale de la Tanzanie, et Dar es Salaam n'était que la plus grande ville du pays.
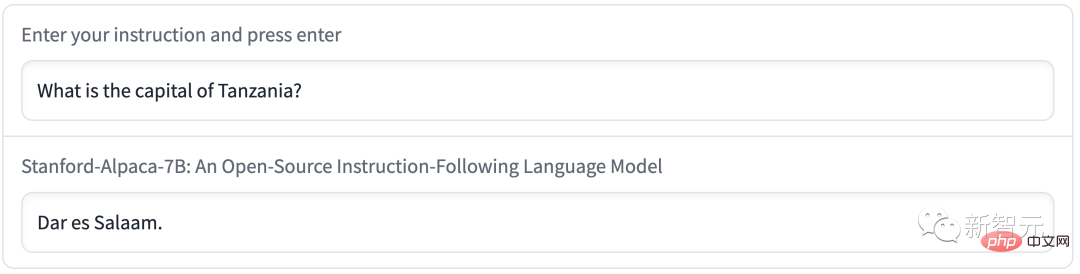
Alpaca propage de la désinformation lorsqu'il s'agit de rédiger un résumé réfléchi.
De plus, Alpaca peut avoir de nombreuses limitations liées au modèle de langage sous-jacent et aux données de réglage fin de l'instruction. Cependant, Alpaca nous fournit un modèle relativement léger qui peut servir de base à de futures études sur les défauts importants de modèles plus grands.
Actuellement, Stanford a seulement annoncé les méthodes et les données d'entraînement de l'Alpaga, et prévoit de publier les poids du modèle à l'avenir.
Cependant, l'Alpaga ne peut pas être utilisé à des fins commerciales et ne peut être utilisé qu'à des fins de recherche universitaire. Il y a trois raisons spécifiques :
1. LLaMA est un modèle sous licence non commerciale, et Alpaca est généré sur la base de ce modèle
2. Les données d'instruction sont basées sur le texte-davinci d'OpenAI ; -003, qui Les conditions d'utilisation interdisent le développement de modèles concurrents d'OpenAI
3 Pas suffisamment de mesures de sécurité ont été conçues, Alpaca n'est donc pas prêt pour une utilisation généralisée
De plus, Chercheurs de Stanford Il résume trois orientations pour les recherches futures sur l'alpaga.
- Évaluation :
Commencez par HELM (évaluation holistique des modèles de langage) pour capturer des scénarios plus génératifs et suivis d'instructions.
- Sécurité :
Approfondir les recherches sur les risques d'Alpaca et améliorer sa sécurité à l'aide de méthodes telles que l'équipe rouge automatisée, l'audit et les tests adaptatifs.
- Compréhension :
J'espère que nous pourrons mieux comprendre comment les capacités des modèles découlent des méthodes de formation. Quelles propriétés du modèle de base sont requises ? Que se passe-t-il lorsque vous agrandissez votre modèle ? Quels attributs des données d'instruction sont requis ? Sur GPT-3.5, quelles sont les alternatives à l'utilisation de directives auto-générées ?
Diffusion stable de grands modèles
Maintenant, Stanford "Alpaca" est directement considéré par les internautes comme "Diffusion stable de grands modèles de texte".
Le modèle LLaMA de Meta peut être utilisé gratuitement par les chercheurs (après avoir postulé, bien sûr), ce qui constitue un grand avantage pour les cercles d'IA.
Depuis l'émergence de ChatGPT, de nombreuses personnes ont été frustrées par les limitations intégrées des modèles d'IA. Ces restrictions empêchent ChatGPT de discuter de sujets qu'OpenAI juge sensibles.
Par conséquent, la communauté de l'IA espère disposer d'un grand modèle de langage (LLM) open source que n'importe qui peut exécuter localement sans censure ni payer de frais d'API à OpenAI.
De tels grands modèles open source sont désormais disponibles, comme le GPT-J, mais le seul inconvénient est qu'ils nécessitent beaucoup de mémoire GPU et d'espace de stockage.
D'un autre côté, d'autres alternatives open source ne peuvent pas atteindre des performances de niveau GPT-3 sur du matériel grand public disponible dans le commerce.
Fin février, Meta a lancé le dernier modèle de langage LLaMA, avec des montants de paramètres de 7 milliards (7B), 13 milliards (13B), 33 milliards (33B) et 65 milliards (65B). Les résultats de l'évaluation montrent que sa version 13B est comparable à GPT-3.

Adresse papier : https://research.facebook.com/publications/llama-open-and-efficient-foundation-lingual-models/
Bien que Meta soit un code open source pour les chercheurs qui postulent, mais De manière inattendue, les internautes ont d'abord divulgué le poids de LLaMA sur GitHub.
Depuis, le développement autour du modèle de langage LLaMA a explosé.
En règle générale, l'exécution de GPT-3 nécessite plusieurs GPU A100 de qualité centre de données, et les poids de GPT-3 ne sont pas publics.
Les internautes ont commencé à utiliser eux-mêmes le modèle LLaMA, ce qui a fait sensation.
En optimisant la taille du modèle grâce à des techniques de quantification, LLaMA peut désormais fonctionner sur des Mac M1, des GPU grand public Nvidia plus petits, des téléphones Pixel 6 et même des Raspberry Pi.
Les internautes ont résumé certains des résultats que tout le monde a obtenus en utilisant LLaMA depuis la sortie de LLaMA jusqu'à aujourd'hui :
Le 24 février, LLaMA a été publiée et fournie au gouvernement et au gouvernement sous un accord non- licence commerciale. Chercheurs et travailleurs d'entités dans la communauté et le monde universitaire
Le 2 mars, les internautes de 4chan ont divulgué l'intégralité du modèle LLaMA
Le 10 mars, Georgi Gerganov a créé llama.cpp Tool, vous peut exécuter LLaMA sur Mac équipé d'une puce M1/M2
11 mars : vous pouvez exécuter le modèle 7B sur un RaspberryPi de 4 Go via lama.cpp, mais la vitesse est relativement lente, seulement 10 secondes/jeton
;12 mars : LLaMA 7B a été exécuté avec succès sur un outil d'exécution node.js NPX ; Alpaga" est libéré.
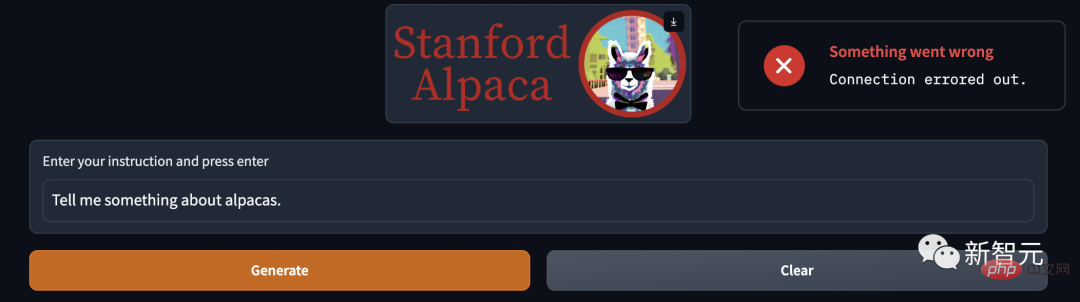
One More ThingPeu de temps après la sortie du projet, Alpaca est devenu si populaire qu'il n'était plus utilisable....
De nombreux internautes étaient bruyants, et il n'y a eu aucune réponse lorsqu'ils ont cliqué sur "Générer". Certains font la queue pour jouer.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI