
Maison >Périphériques technologiques >IA >Le langage de programmation OpenAI accélère le raisonnement de Bert 12 fois et le moteur attire l'attention
Le langage de programmation OpenAI accélère le raisonnement de Bert 12 fois et le moteur attire l'attention

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-23 15:19:071478parcourir
Quelle est la puissance d'une ligne de code ? La bibliothèque Kernl que nous allons présenter aujourd'hui permet aux utilisateurs d'exécuter le modèle de transformateur Pytorch plusieurs fois plus rapidement sur le GPU avec une seule ligne de code, accélérant ainsi considérablement la vitesse d'inférence du modèle.
Plus précisément, avec la bénédiction de Kernl, la vitesse d'inférence de Bert est 12 fois plus rapide que la ligne de base de Hugging Face. Cette réussite est principalement due au fait que Kernl a écrit des noyaux GPU personnalisés dans le nouveau langage de programmation OpenAI Triton et TorchDynamo. L'auteur du projet est originaire de Lefebvre Sarrut.
Adresse GitHub : https://github.com/ELS-RD/kernl/
Ce qui suit est une comparaison entre Kernl et d'autres moteurs d'inférence. Les nombres entre parenthèses dans le. l'abscisse indique respectivement la taille du lot et la longueur de la séquence, et l'ordonnée est l'accélération d'inférence.
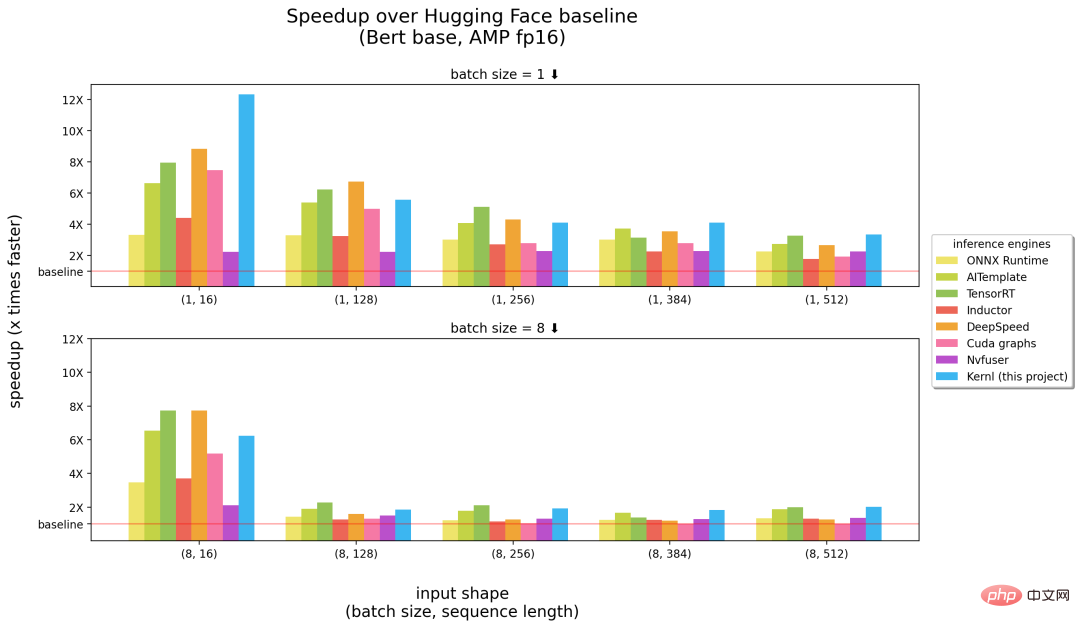
Les benchmarks fonctionnent sur un GPU 3090 RTX et un processeur Intel à 12 cœurs.
Les résultats ci-dessus montrent que Kernl peut être considéré comme le moteur d'inférence le plus rapide (moitié droite de l'image ci-dessus) en ce qui concerne l'entrée de séquences longues, et est proche du TensorRT de NVIDIA sur de courtes séquences d'entrée ((moitié gauche de l'image ci-dessus). Sinon, le code du noyau Kernl est très court et facile à comprendre et à modifier. Le projet ajoute même le débogueur Triton et des outils (basés sur Fx) pour simplifier le remplacement du noyau, donc aucune modification du code source du modèle PyTorch n'est requise.
L'auteur du projet Michaël Benesty a résumé cette recherche. Ils ont publié Kernl, une bibliothèque pour accélérer l'inférence de transformateur. Elle est très rapide, atteint parfois les performances SOTA et peut être crackée pour correspondre à la plupart des architectures de transformateur.
Ils l'ont également testé sur T5 et il était 6 fois plus rapide, Benesty a déclaré que ce n'était que le début.
Pourquoi Kernl a-t-il été créé ?
Chez Lefebvre Sarrut, l'auteur du projet exécute plusieurs modèles de transformateurs en production, dont certains sont sensibles à la latence, principalement du search et du recsys. Ils utilisent également OnnxRuntime et TensorRT, et ont même créé la bibliothèque OSS de déploiement de transformateur pour partager leurs connaissances avec la communauté.
Récemment, l'auteur a testé des langages génératifs et a travaillé dur pour les accélérer. Cependant, y parvenir à l’aide d’outils traditionnels s’est avéré très difficile. À leur avis, Onnx est un autre format intéressant. Il s'agit d'un format de fichier ouvert conçu pour l'apprentissage automatique, il est utilisé pour stocker des modèles formés et dispose d'un support matériel étendu.
Cependant, l'écosystème Onnx (principalement le moteur d'inférence) présente les limitations suivantes car il traite la nouvelle architecture LLM :
- L'exportation de modèles sans flux de contrôle vers Onnx est simple, car vous pouvez compter sur suivi. Mais le comportement dynamique est plus difficile à obtenir ;
- Contrairement à PyTorch, ONNX Runtime/TensorRT n'a pas encore de support natif pour les tâches multi-GPU qui implémentent le parallélisme tensoriel
- TensorRT ne peut pas gérer 2 dynamiques pour les modèles de transformateur avec la même ; axe du fichier de configuration. Mais comme vous souhaitez généralement pouvoir fournir des entrées de différentes longueurs, vous devez créer 1 modèle par taille de lot
- Les très gros modèles sont courants, mais Onnx (en tant que fichier protobuff) a certaines limitations en termes de fichier ; taille et doit être. Les poids sont stockés en dehors du modèle pour résoudre le problème.
Un fait très ennuyeux est que les nouveaux modèles ne seront jamais accélérés, vous devez attendre que quelqu'un d'autre écrive un noyau CUDA personnalisé pour cela. Ce n’est pas que les solutions existantes soient mauvaises, l’un des avantages d’OnnxRuntime est sa prise en charge multi-matériel, et TensorRT est connu pour être très rapide.
Les auteurs du projet voulaient donc avoir un optimiseur aussi rapide que TensorRT sur Python/PyTorch, c'est pourquoi ils ont créé Kernl.
Comment faire ?
La bande passante mémoire est généralement le goulot d'étranglement du deep learning. Afin d'accélérer l'inférence, réduire l'accès à la mémoire est souvent une bonne stratégie. Sur les séquences d'entrée courtes, le goulot d'étranglement est généralement lié à la surcharge du processeur, qui doit être éliminée. Les auteurs du projet utilisent principalement les 3 technologies suivantes :
La première est OpenAI Triton, qui est un langage d'écriture de noyaux GPU tel que CUDA. A ne pas confondre avec le serveur d'inférence Nvidia Triton, plus performant. . Des améliorations ont été obtenues par la fusion de plusieurs opérations de telle sorte qu'elles enchaînent les calculs sans conserver les résultats intermédiaires dans la mémoire GPU. L'auteur l'utilise pour réécrire l'attention (remplacée par Flash Attention), les couches et activations linéaires, et Layernorm/Rmsnorm.
Le second est le graphique CUDA. Pendant l'étape de préchauffage, il enregistre chaque cœur lancé et ses paramètres. Les auteurs du projet ont ensuite reconstitué l'intégralité du processus de raisonnement.
Enfin, il y a TorchDynamo, un prototype proposé par Meta pour aider les auteurs de projets à gérer le comportement dynamique. Pendant l'étape d'échauffement, il suit le modèle et fournit un graphique Fx (graphique de calcul statique). Ils ont remplacé certaines opérations du graphe Fx par leur propre noyau, recompilé en Python.
À l'avenir, la feuille de route du projet couvrira un échauffement plus rapide, une inférence irrégulière (pas de calcul de perte dans le remplissage), un support de formation (support de séquences longues), un support multi-GPU (plusieurs modes de parallélisation), une quantification (PTQ) , Tests du noyau Cutlass de nouveaux lots et prise en charge matérielle améliorée, etc.
Veuillez vous référer au projet original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI