
Maison >Périphériques technologiques >IA >Nouvelle recherche DeepMind : le transformateur peut s'améliorer sans intervention humaine
Nouvelle recherche DeepMind : le transformateur peut s'améliorer sans intervention humaine

- 王林avant
- 2023-04-20 19:07:071184parcourir
Actuellement, les Transformers sont devenus une puissante architecture de réseau neuronal pour la modélisation de séquences. Une propriété notable des transformateurs pré-entraînés est leur capacité à s'adapter aux tâches en aval grâce au conditionnement des signaux ou à l'apprentissage contextuel. Après une pré-formation sur de grands ensembles de données hors ligne, il a été démontré que les transformateurs à grande échelle se généralisent efficacement aux tâches en aval de complétion de texte, de compréhension du langage et de génération d'images.
Des travaux récents ont montré que les transformateurs peuvent également apprendre des politiques à partir de données hors ligne en traitant l'apprentissage par renforcement (RL) hors ligne comme un problème de prédiction séquentielle. Les travaux de Chen et al. (2021) ont montré que les transformateurs peuvent apprendre des politiques à tâche unique à partir de données RL hors ligne grâce à l'apprentissage par imitation, et des travaux ultérieurs ont montré que les transformateurs peuvent extraire des politiques multitâches dans des contextes de même domaine et inter-domaines. Ces travaux démontrent tous le paradigme d'extraction de politiques générales multitâches, qui consiste d'abord à collecter des ensembles de données d'interaction environnementale diversifiées et à grande échelle, puis à extraire des politiques à partir des données via une modélisation séquentielle. Cette méthode d'apprentissage des politiques à partir de données RL hors ligne via l'apprentissage par imitation est appelée distillation des politiques hors ligne (Offline Policy Distillation) ou distillation des politiques (Policy Distillation, PD).
PD offre simplicité et évolutivité, mais l'un de ses gros inconvénients est que les politiques générées ne s'améliorent pas progressivement avec des interactions supplémentaires avec l'environnement. Par exemple, l'agent généraliste Multi-Game Decision Transformers de Google a appris une politique de retour conditionnée qui peut jouer à de nombreux jeux Atari, tandis que l'agent généraliste de DeepMind, Gato, a appris une solution à divers problèmes grâce à des stratégies de raisonnement contextuel pour les tâches dans l'environnement. Malheureusement, aucun des deux agents ne peut améliorer la politique dans son contexte par essais et erreurs. Par conséquent, la méthode PD apprend les politiques plutôt que les algorithmes d’apprentissage par renforcement.
Dans un récent article de DeepMind, les chercheurs ont émis l'hypothèse que la raison pour laquelle la PD n'a pas réussi à s'améliorer par essais et erreurs était que les données utilisées pour la formation ne pouvaient pas montrer les progrès de l'apprentissage. Les méthodes actuelles apprennent soit une politique à partir de données qui ne contiennent pas d'apprentissage (par exemple une politique d'expert fixe via distillation), soit apprennent une politique à partir de données qui contiennent de l'apprentissage (par exemple le tampon de relecture d'un agent RL), mais la taille du contexte de ce dernier ( trop petit) Incapacité à prendre en compte les améliorations politiques.

Adresse papier : https://arxiv.org/pdf/2210.14215.pdf
La principale observation du chercheur est que la nature séquentielle de l'apprentissage dans la formation aux algorithmes RL peut en principe être un apprentissage par renforcement lui-même est modélisé comme un problème de prédiction de séquence causale. Plus précisément, si le contexte d'un transformateur est suffisamment long pour inclure les améliorations de politique apportées par les mises à jour d'apprentissage, alors il devrait non seulement être capable de représenter une politique fixe, mais également être capable de représenter un algorithme d'amélioration de politique en se concentrant sur les états. , actions et récompenses des épisodes précédents. Cela ouvre la possibilité que n'importe quel algorithme RL puisse être distillé en modèles de séquence suffisamment puissants tels que des transformateurs grâce à l'apprentissage par imitation, et ces modèles peuvent être convertis en algorithmes RL contextuels.
Les chercheurs ont proposé la distillation d'algorithmes (AD), qui est une méthode d'apprentissage des opérateurs d'amélioration des politiques contextuelles en optimisant la perte de prédiction de séquence causale dans l'historique d'apprentissage des algorithmes RL. Comme le montre la figure 1 ci-dessous, AD se compose de deux parties. Un grand ensemble de données multitâches est d'abord généré en enregistrant l'historique d'entraînement d'un algorithme RL sur un grand nombre de tâches individuelles, puis le modèle de transformateur modélise de manière causale les actions en utilisant l'historique d'apprentissage précédent comme contexte. Étant donné que la politique continue de s'améliorer au cours de la formation de l'algorithme RL source, AD doit apprendre des opérateurs améliorés afin de modéliser avec précision les actions à tout moment donné de l'historique de formation. Il est essentiel que le contexte du transformateur soit suffisamment vaste (c'est-à-dire sur plusieurs épisodes) pour capturer les améliorations des données d'entraînement.
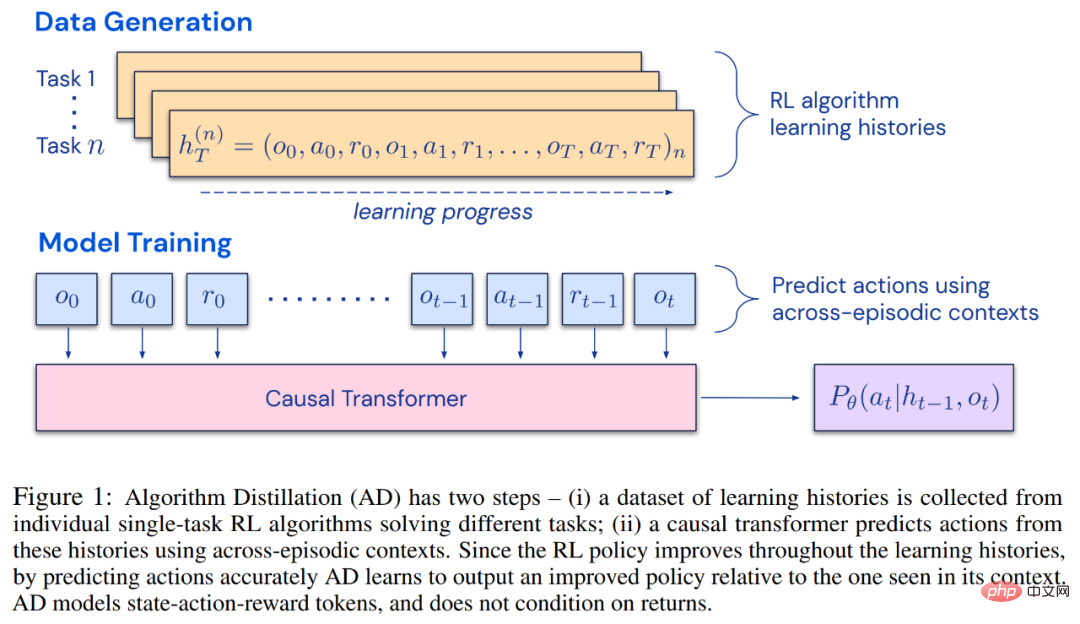
Les chercheurs ont déclaré qu'en utilisant un transformateur causal avec un contexte suffisamment grand pour imiter l'algorithme RL basé sur le gradient, AD peut renforcer pleinement l'apprentissage de nouvelles tâches dans le contexte. Nous avons évalué AD dans un certain nombre d'environnements partiellement observables nécessitant une exploration, y compris Watermaze basé sur des pixels de DMLab, et avons montré qu'AD est capable d'exploration de contexte, d'attribution de confiance temporelle et de généralisation. De plus, l’algorithme appris par AD est plus efficace que l’algorithme qui a généré les données sources d’entraînement du transformateur.
Enfin, il convient de noter que AD est la première méthode pour démontrer l'apprentissage par renforcement contextuel en modélisant séquentiellement des données hors ligne avec perte d'imitation.
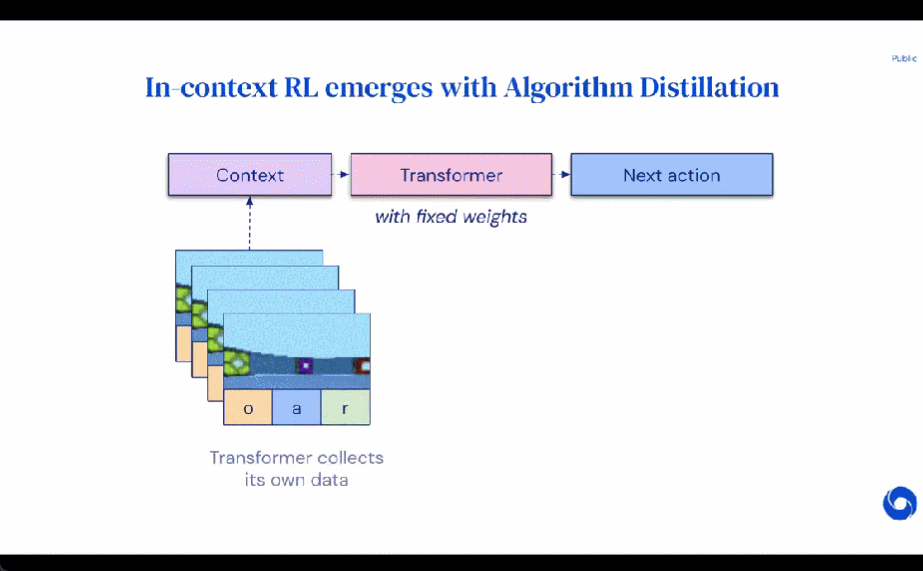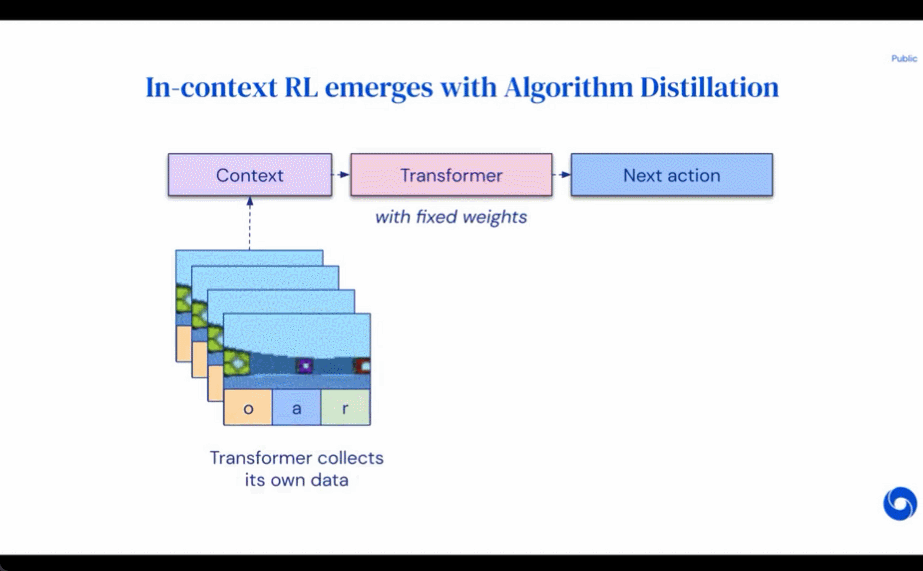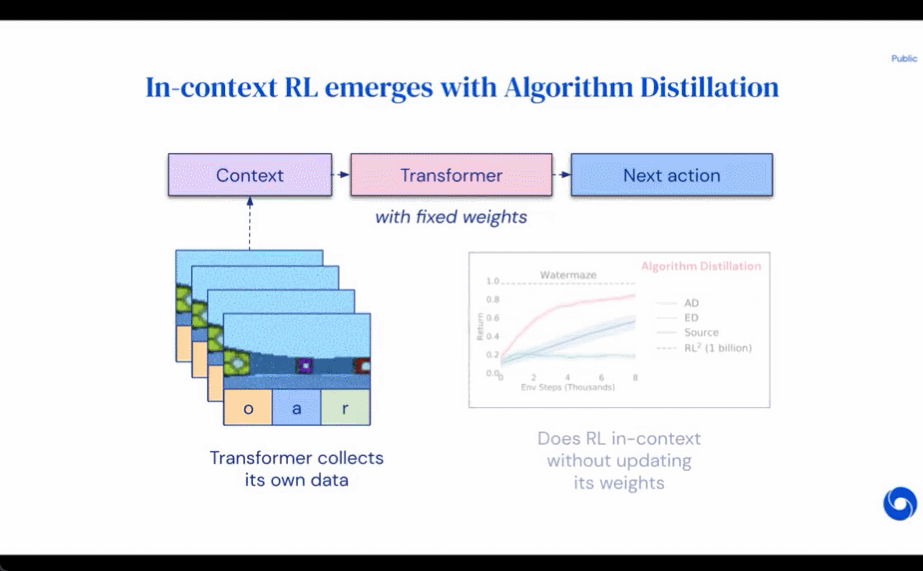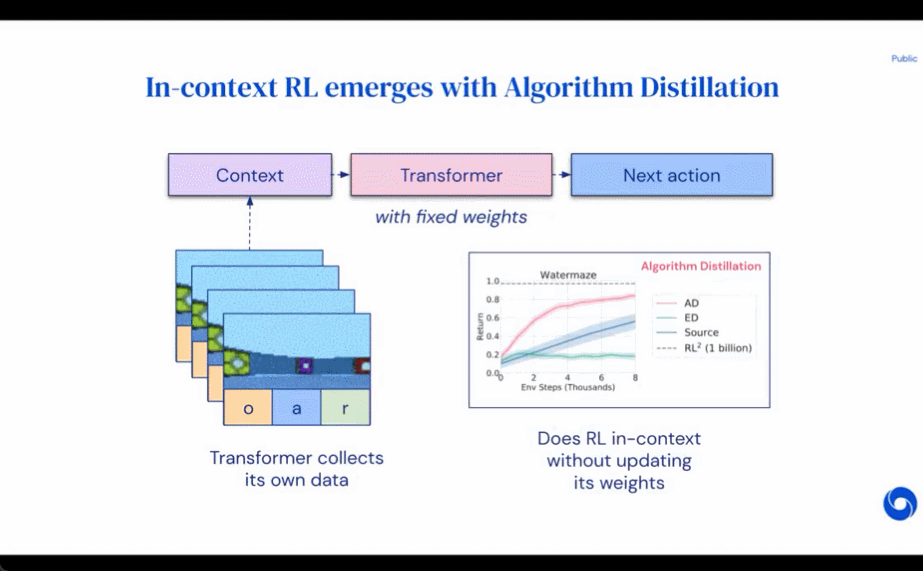
Méthode
Au cours de son cycle de vie, un agent d'apprentissage par renforcement doit être performant dans l'exécution d'actions complexes. Pour un agent intelligent, quels que soient son environnement, sa structure interne et son exécution, il peut être considéré comme achevé sur la base de l'expérience passée. Elle peut s'exprimer sous la forme suivante :
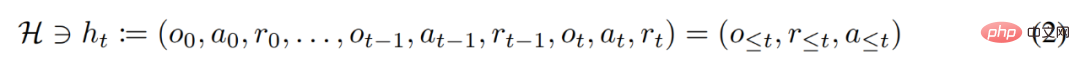
Le chercheur a également considéré la stratégie « conditionnée par une longue histoire » comme un algorithme et en est arrivé à :

où Δ(A) représente l'action Espace de distribution de probabilité sur l'espace A. L'équation (3) montre que l'algorithme peut être déployé dans l'environnement pour générer des séquences d'observations, de récompenses et d'actions. Par souci de simplicité, cette étude désigne l'algorithme par P et l'environnement (c'est-à-dire la tâche) par  . L'historique d'apprentissage est désigné par l'algorithme
. L'historique d'apprentissage est désigné par l'algorithme  , de sorte que pour toute tâche donnée
, de sorte que pour toute tâche donnée  est généré. Il peut être obtenu
est généré. Il peut être obtenu
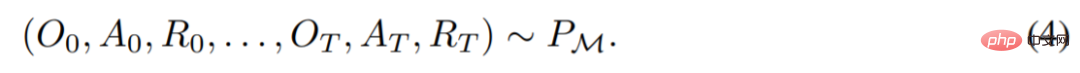
Les chercheurs utilisent des lettres latines majuscules pour représenter des variables aléatoires, telles que O, A, R et leurs formes minuscules correspondantes o, α, r. En considérant les algorithmes comme des politiques à long terme conditionnées par l’histoire, ils ont émis l’hypothèse que tout algorithme générant un historique d’apprentissage peut être converti en un réseau neuronal en effectuant un clonage comportemental d’actions. Ensuite, l'étude propose une approche qui fournit aux agents un apprentissage à vie de modèles de séquence avec des clones comportementaux pour mapper l'historique à long terme aux distributions d'actions.
Mise en œuvre réelle
En pratique, cette recherche met en œuvre la distillation algorithmique (AD) en deux étapes. Premièrement, un ensemble de données d’historique d’apprentissage est collecté en exécutant des algorithmes RL individuels basés sur un gradient sur de nombreuses tâches différentes. Ensuite, un modèle de séquence avec un contexte multi-épisodes est formé pour prédire les actions dans l'histoire. L'algorithme spécifique est le suivant :

Expériences
Les expériences nécessitent que l'environnement utilisé prenne en charge de nombreuses tâches qui ne peuvent pas être facilement déduites des observations, et les épisodes sont suffisamment courts pour former efficacement des transformateurs causals inter-épisodiques. L'objectif principal de ce travail était d'étudier dans quelle mesure le renforcement AD est appris dans son contexte par rapport aux travaux antérieurs. L'expérience a comparé AD, ED (Expert Distillation), RL^2, etc.
Les résultats de l'évaluation de AD, ED et RL^2 sont présentés dans la figure 3. L'étude a révélé que AD et RL^2 peuvent apprendre contextuellement sur des tâches échantillonnées dans la distribution de formation, alors que ED ne le peuvent pas, bien que ED fasse mieux que les suppositions aléatoires lorsqu'il est évalué au sein d'une distribution.
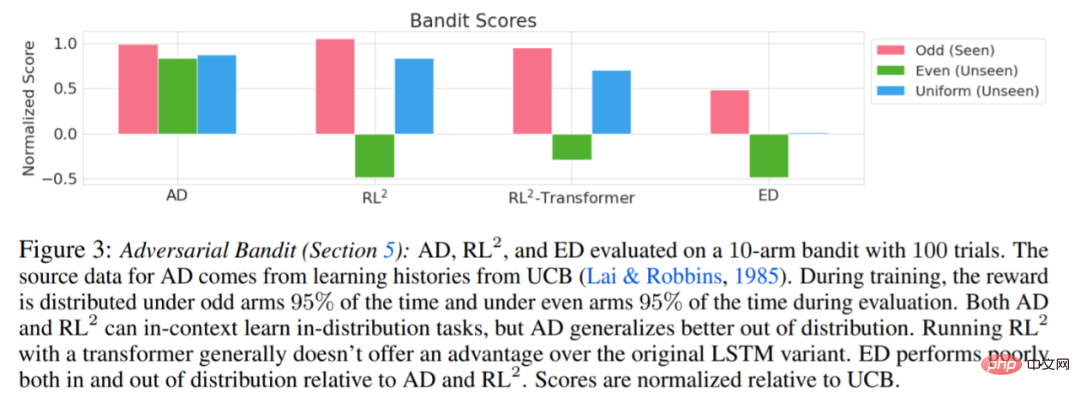
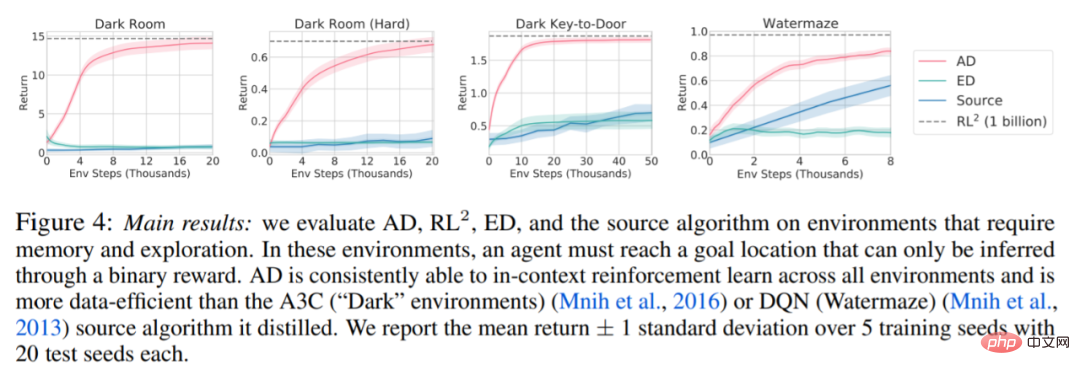
Concernant la figure 4 ci-dessous, le chercheur a répondu à une série de questions. AD présente-t-il un apprentissage par renforcement contextuel ? Les résultats montrent que l’apprentissage par renforcement contextuel AD peut apprendre dans tous les environnements, en revanche, ED ne peut pas explorer et apprendre en contexte dans la plupart des situations.
AD peut-il apprendre des observations basées sur les pixels ? Les résultats montrent que AD maximise la régression épisodique via RL contextuelle, tandis que ED ne parvient pas à apprendre.
AD Est-il possible d'apprendre un algorithme RL plus efficace que l'algorithme qui a généré les données sources ? Les résultats montrent que l’efficacité des données d’AD est nettement supérieure à celle des algorithmes sources (A3C et DQN).
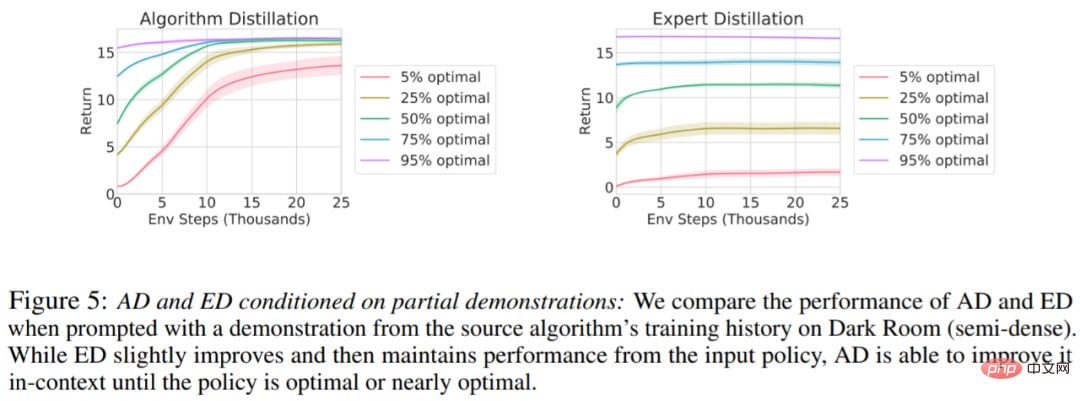
Est-il possible d'accélérer AD via des démos ? Pour répondre à cette question, cette étude conserve la stratégie d'échantillonnage à différents moments de l'historique de l'algorithme source dans les données de l'ensemble de test, puis utilise ces données de stratégie pour pré-remplir le contexte de AD et ED, et exécute les deux méthodes dans le contexte de Dark Room, les résultats sont tracés dans la figure 5. Tandis que ED maintient les performances de la stratégie d’entrée, AD améliore chaque stratégie dans son contexte jusqu’à ce qu’elle soit proche de l’optimum. Il est important de noter que plus la stratégie d’entrée est optimisée, plus AD l’améliore rapidement jusqu’à atteindre l’optimalité.
Pour plus de détails, veuillez vous référer au document original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI