
Maison >Périphériques technologiques >IA >Un vétéran de l'informatique de 20 ans explique comment utiliser ChatGPT pour créer des connaissances de domaine
Un vétéran de l'informatique de 20 ans explique comment utiliser ChatGPT pour créer des connaissances de domaine

- 王林avant
- 2023-04-20 19:07:182507parcourir
Auteur | Cui Hao
Critique | Mise à niveau de la technologie révolutionnaire, la sortie de ChatGPT 4.0 choque tout le monde Industrie de l'IA. Désormais, non seulement les ordinateurs peuvent reconnaître et répondre aux questions quotidiennes en langage naturel, mais ChatGPT peut également fournir des solutions plus précises en modélisant les données de l'industrie. Cet article vous donnera une compréhension approfondie des principes architecturaux de ChatGPT et de ses
perspectives de développement. Il présentera également comment utiliser l'API de ChatGPT pour former les données de l'industrie. Explorons ensemble ce domaine nouveau et prometteur et créons une nouvelle ère de l’IA.
Sortie de ChatGPT 4.0ChatGPT 4.0 est officiellement publié ! Cette version de ChatGPT introduit des pas de géant en matière d'innovation Par rapport au précédent ChatGPT 3.5, elle présente une énorme amélioration des performances et de la vitesse du modèle.
Avant la sortie de ChatGPT 4.0, de nombreuses personnes avaient prêté attention à ChatGPT et réalisé son importance dans le domaine du traitement du langage naturel. Cependant, dans les versions 3.5
et précédentes , des limitations de ChatGPT existent toujours, car ses données de formation sont principalement concentrées dans des modèles de langage dans des domaines généraux, ce qui rend difficile la génération de contenu lié à des secteurs spécifiques. Cependant, avec la sortie de ChatGPT 4.0, de plus en plus de personnes ont commencé à l'utiliser pour former leurs propres données industrielles, et il a été largement utilisé dans diverses industries. Cela incite de plus en plus de personnes à prêter attention à ChatGPT. Ensuite, je vous présenterai les principes architecturaux, les perspectives de développement et l'application de ChatGPT dans la formation des données de l'industrie. Capacités de ChatGPTChatGPT est basé sur un réseau neuronal d'apprentissage profond, qui est une technologie de traitement du langage naturel. Son principe est d'utiliser de grands réseaux pré-entraînés. modèles de langage à grande échelle Pour générer du texte afin que les machines puissent comprendre et générer du langage naturel. Le principe du modèle de ChatGPT est basé sur le réseau Transformer, qui est formé à l'aide d'une technologie de modélisation linguistique non supervisée pour prédire la distribution de probabilité du mot suivant afin de générer un texte continu. Les paramètres utilisés incluent le nombre de couches du réseau, le nombre de neurones dans chaque couche, la probabilité d'abandon, la taille du lot, etc. La portée de l’apprentissage implique des modèles linguistiques généraux et des modèles linguistiques spécifiques à un domaine. Les modèles généraux du domaine peuvent être utilisés pour générer une variété de textes, tandis que les modèles spécifiques au domaine peuvent être affinés et optimisés pour des tâches spécifiques.
OpenAI utilise des données textuelles massives comme données de formation pour GPT-3. Plus précisément, ils ont utilisé plus de 45 To de données textuelles en anglais et certaines autres données linguistiques, notamment des textes Web, des livres électroniques, des encyclopédies, Wikipédia, des forums, des blogs, etc. Ils ont également utilisé de très grands ensembles de données tels que Common Crawl, WebText, BooksCorpus, etc. Ces ensembles de données contiennent des milliards de mots et des milliards de phrases différentes, fournissant des informations très riches pour la formation des modèles.
Comme il faut apprendre autant de contenu, la puissance de calcul utilisée est également considérable. ChatGPT consomme beaucoup de puissance de calcul et nécessite beaucoup de ressources GPU pour la formation. Selon un rapport technique d'OpenAI en 2020, GPT-3 a consommé environ 17,5 milliards de paramètres et 28 500 processeurs TPU v3 pendant la formation.
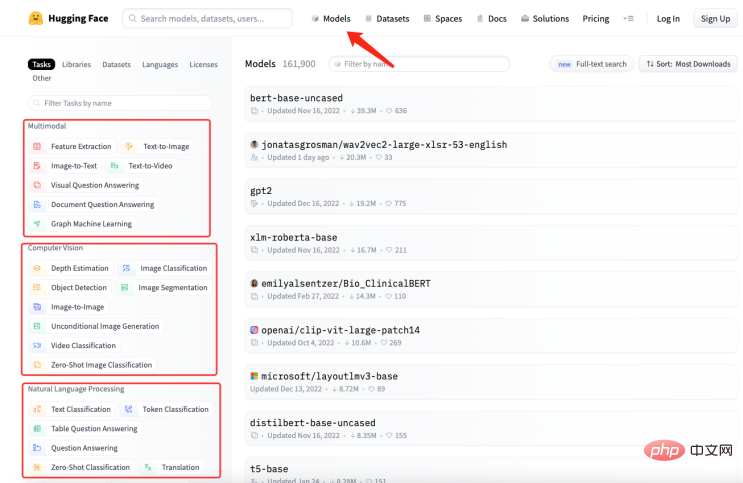
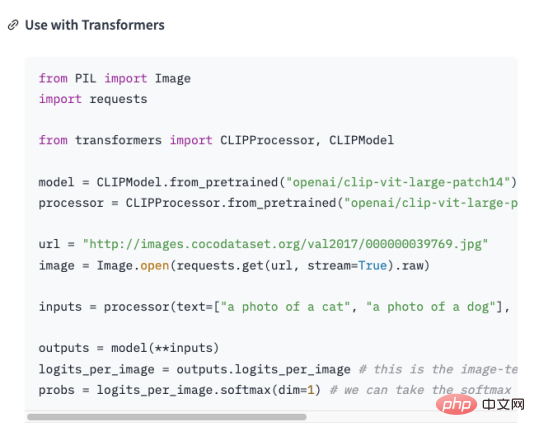
de la introduction ci-dessus Nous savons que Chatgpt a des capacités puissantes, mais nécessite également une énorme quantité de calcul et de consommation de ressources, de formation Cis Les grands modèles linguistiques entraînent des coûts élevés. Mais l'outil AIGC produit à un coût aussi élevé a ses limites , connaissances dans certains domaines professionnels. Je ne me suis pas impliqué. Par exemple, lorsqu’il s’agit de domaines professionnels comme la médecine ou le droit, ChatGPT est incapable de générer des réponses précises. En effet, les données d'apprentissage de ChatGPT proviennent du corpus général sur Internet, et ces données n'incluent pas les termes professionnels et les connaissances dans certains domaines spécifiques. Ainsi, pour que ChatGPT soit plus performant dans certains domaines professionnels, il est nécessaire d'utiliser des corpus professionnels dans ce domaine pour la formation, c'est-à-dire les connaissances d'experts en le domaine professionnel sera enseigné Donnez "ChatGPT pour apprendre. Cependant, ChatGPT ne nous a pas déçus. Si vous appliquez ChatGPT à un certain secteur, vous devez d'abord extraire les données professionnelles du secteur et effectuer un prétraitement. Plus précisément, une série de processus tels que le nettoyage, la déduplication, la segmentation et l'étiquetage des données doivent être effectués. Ensuite, les données traitées sont formatées et converties dans un format de données qui répond aux exigences d'entrée du modèle ChatGPT. Ensuite, vous pouvez utiliser l'interface API de ChatGPT pour saisir les données traitées dans le modèle à des fins de formation. La durée et le coût de la formation dépendent de la quantité de données et de la puissance de calcul. Une fois la formation terminée, le modèle peut être appliqué à des scénarios réels pour répondre aux questions des utilisateurs. En fait, il n'est pas difficile de construire une base de connaissances dans le domaine professionnel. L'opération spécifique est de convertir des données de l'industrie en un format de questions et réponses , . puis Le format des questions et réponses est modélisé grâce à la technologie de traitement du langage naturel (NLP) pour répondre à la question. En utilisant l'API GPT-3 d'OpenAI (en prenant GPT3 comme exemple) vous pouvez créer un modèle de questions et réponses, fournissez simplement quelques exemples et cela sera travailler basé sur Les questions que vous posez génèrent des réponses. Les étapes approximatives pour créer un modèle de questions et réponses à l'aide de l'API GPT-3 sont les suivantes : Parce que n'est pas le sujet de cet article, je ne développerai pas ici. Créer un ensemble de donnéesÀ partir des étapes ci-dessus, convertir l'étape 2 en format de questions et réponses est un défi pour nous. En supposant il existe des connaissances de domaine sur l'histoire de l'intelligence artificielle qui doivent être enseignées au GPT , et utiliser ces connaissances transformées en modèles qui répondent à des questions pertinentes. Ensuite il doit être converti sous la forme suivante : Quelle est l'histoire de l'intelligence artificielle ? nnL'intelligence artificielle est née dans les années 1950 et est une branche de l'informatique qui vise à étudier comment permettre aux ordinateurs de penser et d'agir comme des humains. n En fait, j'ai ajouté "nn", après la question et "n" après la réponse. ” . Résoudre le problème du format de questions et réponses, une nouvelle question revient, comment organiser la connaissance de l'industrie en une question et réponse format ? Dans la plupart des cas, nous explorons de nombreuses connaissances de domaine sur Internet ou trouvons de nombreux documents de domaine. Quel que soit le cas, la saisie de documents est la plus pratique pour nous. Cependant, il est évidemment irréaliste d’utiliser des expressions régulières ou des méthodes manuelles pour traiter une grande quantité de texte sous forme de questions et réponses. Par conséquent, il est nécessaire d'introduire une technologie appelée résumé automatique (Automatic Summarization), qui peut extraire les informations clés d'un article et générer un court résumé. Il existe deux types de résumé automatique : le résumé automatique extractif et le résumé automatique génératif. Le résumé automatique extractif extrait les phrases les plus représentatives du texte original pour générer un résumé, tandis que le résumé automatique génératif extrait des informations importantes du texte original grâce à l'apprentissage de modèles et génère un résumé basé sur ces informations. En fait, le résumé automatique consiste à générer un mode question et réponse à partir du texte saisi. Une fois le problème clarifié, l'étape suivante consiste à obtenir les outils. Nous utilisons NLTK pour faire des choses. NLTK est l'abréviation de Natural Language Toolkit. C'est une bibliothèque Python principalement utilisée dans. le domaine du traitement du langage naturel. Il comprend divers outils et bibliothèques pour le traitement du langage naturel, tels que le prétraitement de texte, le balisage de parties du discours, la reconnaissance d'entités nommées, l'analyse syntaxique, l'analyse des sentiments, etc. Il nous suffit de remettre le texte à NLTK, qui effectuera des opérations de prétraitement des données sur le texte, notamment la suppression des mots vides, la segmentation des mots, le marquage d'une partie du discours, etc. Après le prétraitement, le module de génération de résumé de texte dans NLTK peut être utilisé pour générer des résumés. Vous pouvez choisir différents algorithmes, par exemple basés sur la fréquence des mots, basés sur TF-IDF, etc. Lors de la génération du résumé, le modèle de question peut être combiné pour générer un résumé de questions et réponses, rendant le résumé généré plus lisible et compréhensible. Dans le même temps, le résumé peut également être affiné, comme des phrases qui ne sont pas cohérentes, des réponses inexactes, etc. Regardez le code ci-dessous: à partir des transformateurs importent AutoTokenizer, AutoModelForSeq2SeqLM, pipeline importer nltk # Entrer le texte text = """Boîte à outils en langage naturel (Natural Language Processing Toolkit, en abrégé NLTK) est un ensemble de bibliothèques Python utilisées pour résoudre des problèmes de traitement de données en langage humain, tels que : Marquage POS Analyse syntaxique Analyse des sentiments Analyse sémantique Reconnaissance vocale Génération de texte et plus """ Générer un résumé sentences = nltk.sent_tokenize(texte ) summary = " ".join(sentences[:2]) # Prendre les deux premières phrases comme résumé print("résumé :", résumé) # Utiliser le résumé généré pour Fine-t uning, procure-toi le modèle tokenizer = AutoTokenizer.from_pretrained("t5-base") model = AutoModelForSeq2SeqLM.from_pre entraîné ("base t5") text = "summarize: " + résumé # Construire le format d'entrée inputs = tokenizer(texte, return_tensors="pt" , padding=True) # Modèle d'entraînement model_name = "premier-modèle" model.save_pretrained(model_name) # Modèle de test # To ? obtenir une réponse à la question answer = qa(questinotallow=context, cnotallow=text["input_ids"]) print( "Question :", contexte) print("Réponse :", réponse["réponse"]) Les résultats de sortie sont les suivants : Résumé : Natural Language Toolkit (Natural Language Processing Toolkit, en abrégé NLTK) est un ensemble de bibliothèques Python pour résoudre des problèmes de traitement de données en langage humain, tels que : - Segmentation de mots - Marquage de parties du discours À quoi sert-il Réponse : Traitement du langage naturel Boîte à outils Le code ci-dessus utilise la méthode nltk.sent_tokenize pour extraire le résumé du texte saisi, c'est-à-dire pour formater la question et la réponse. Ensuite, , appelle Fine-tuning la méthode AutoModelForSeq2SeqLM.from_pretrained pour le modéliser, encore une fois Changez le nom en modèle « premier modèle » est sauvegardé. Enfin, appelez le modèle entraîné pour tester les résultats. Ce qui précède génère non seulement le résumé de la question et de la réponse via NLTK, mais doit également utiliser F ine- t fonction de synchronisation. Fine-tuning est basé sur le modèle pré-entraîné et affine le modèle grâce à une petite quantité de données étiquetées pour s'adapter à des tâches spécifiques. En fait consiste à utiliser le modèle d'origine pour installer vos données afin de former votre modèle. Bien sûr, vous pouvez également ajuster les résultats internes du modèle, tels que les réglages et paramètres de la couche cachée, etc. Ici, nous utilisons simplement sa fonction la plus simple , Vous pouvez en apprendre davantage sur Fine-tuning à travers l'image ci-dessous . Ce qui doit être expliqué est : la classe AutoModelForSeq2SeqLM, chargée à partir du modèle pré-entraîné "t5-base" T okenizer et modèle . AutoTokenizer est une classe de la bibliothèque Hugging Face Transformers qui sélectionne et charge automatiquement le Tokenizer approprié en fonction du modèle pré-entraîné. La fonction de Tokenizer est d'encoder le texte saisi dans un format que le modèle peut comprendre pour une saisie ultérieure du modèle. AutoModelForSeq2SeqLM est également une classe de la bibliothèque Hugging Face Transformers qui sélectionne et charge automatiquement le modèle séquence à séquence approprié en fonction du modèle pré-entraîné. Ici, un modèle séquence à séquence basé sur l'architecture T5 est utilisé pour des tâches telles que la génération d'un résumé ou d'une traduction. Après avoir chargé un modèle pré-entraîné, vous pouvez utiliser ce modèle pour le réglage F ou pour générer une sortie liée à une tâche. Nous avons expliqué le code de modélisation ci-dessus, qui implique les parties Fine-tunning et Hugging , ce qui peut sembler déroutant. Voici un exemple pour vous aider à comprendre. Supposons que vous vouliez cuisiner, même si vous avez déjà les ingrédients (connaissance du secteur), mais que vous ne savez pas comment le cuisiner. Alors vous demandez à votre ami chef, vous lui dites quels ingrédients vous avez (connaissance du secteur) et quel plat vous souhaitez cuisiner (problème à résoudre), votre ami se base sur son expérience et les connaissances (modèle général) vous fournissent quelques suggestions , ce processus est Fine-tuning (mettre transformer la connaissance de l’industrie en un outil universel modèle pour la formation). L'expérience et les connaissances de votre ami est un modèle pré-formé, vous devez saisir les connaissances de l'industrie et le problème à résoudre, et utiliser le pré - Le modèle formé, , peut bien sûr être affiné, comme la teneur en condiments et la chaleur de cuisson. Le but est de résoudre les problématiques de votre industrie. And Hugging Face est un entrepôt de recettes ("t5-base" dans le code est une recette), qui contient de nombreuses recettes définies (modèles), telles que : Râpé de porc au goût de poisson , Comment faire du poulet Kung Pao et des tranches de porc bouillies. Ces recettes toutes faites peuvent être utilisées pour créer nos recettes en fonction des ingrédients que nous fournissons et des plats que nous devons cuisiner. Il nous suffit d’ajuster ces recettes puis de les entraîner, et elles deviendront nos propres recettes. Désormais, nous pouvons utiliser nos propres recettes pour cuisiner (résoudre les problèmes de l'industrie). Comment choisir un modèle qui vous convient ? Vous pouvez rechercher le modèle dont vous avez besoin dans la bibliothèque de modèles de Hugging Face. Comme le montre la figure ci-dessous, sur le site officiel de Hugging Face, cliquez sur « Modèles » pour voir la classification des modèles, et vous pouvez également utiliser le champ de recherche pour rechercher des noms de modèles. Comme le montre la figure ci-dessous, chaque page de modèle fournira des informations pertinentes telles que la description du modèle, des exemples d'utilisation, des liens de téléchargement de poids pré-entraînement, etc. Ici, nous passerons en revue l'ensemble du processus de connaissance de l'industrie depuis la collecte, la transformation, la formation et l'utilisation avec tout le monde. Comme le montre la figure ci-dessous : Quelle est l'application de ChatGPT dans le domaine professionnel ?
Utilisez ChatGPT pour former des connaissances professionnelles dans le domaine !

Quelle est la technologie d'intelligence artificielle la plus avancée actuellement ? nnL'une des technologies d'intelligence artificielle les plus avancées actuellement est l'apprentissage profond, qui est un algorithme basé sur un réseau neuronal qui peut entraîner de grandes quantités de données et en extraire des caractéristiques et des modèles. n
Générer rapidement un modèle pour le format de questions et réponses
Quelle est la relation entre le réglage fin et le câlin du visage ?
Résumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI