
Maison >Périphériques technologiques >IA >« Du GAN à ChatGPT : l'Université de Lehigh détaille le développement du contenu généré par l'IA »
« Du GAN à ChatGPT : l'Université de Lehigh détaille le développement du contenu généré par l'IA »

- 王林avant
- 2023-04-20 17:55:081243parcourir
ChatGPT et d'autres technologies d'IA générative (GAI) entrent dans la catégorie du contenu généré par l'intelligence artificielle (AIGC), qui implique la création de contenu numérique tel que des images, de la musique et un langage naturel via des modèles d'IA. L'objectif de l'AIGC est de rendre le processus de création de contenu plus efficace et plus accessible, permettant ainsi la production plus rapide de contenu de haute qualité. L'AIGC est obtenu en extrayant et en comprenant les informations d'intention à partir d'instructions fournies par des humains et en générant du contenu basé sur leurs connaissances et leurs informations d'intention.
Ces dernières années, les modèles à grande échelle sont devenus de plus en plus importants dans AIGC car ils permettent une meilleure extraction d'intention, améliorant ainsi les résultats de génération. À mesure que la taille des données et des modèles augmente, les distributions que les modèles peuvent apprendre deviennent plus complètes et plus proches de la réalité, ce qui donne lieu à un contenu plus réaliste et de haute qualité.
Cet article passe en revue de manière exhaustive l'historique, les composants de base et les progrès récents de l'AIGC, de l'interaction monomodale à l'interaction multimodale. Dans une perspective à modalité unique, les tâches de génération de texte et d'images et les modèles associés sont présentés. D'un point de vue multimodal, les applications croisées entre les modalités ci-dessus sont introduites. Enfin, les questions ouvertes et les défis futurs de l'AIGC sont discutés.

Adresse papier : https://arxiv.org/abs/2303.04226
Introduction
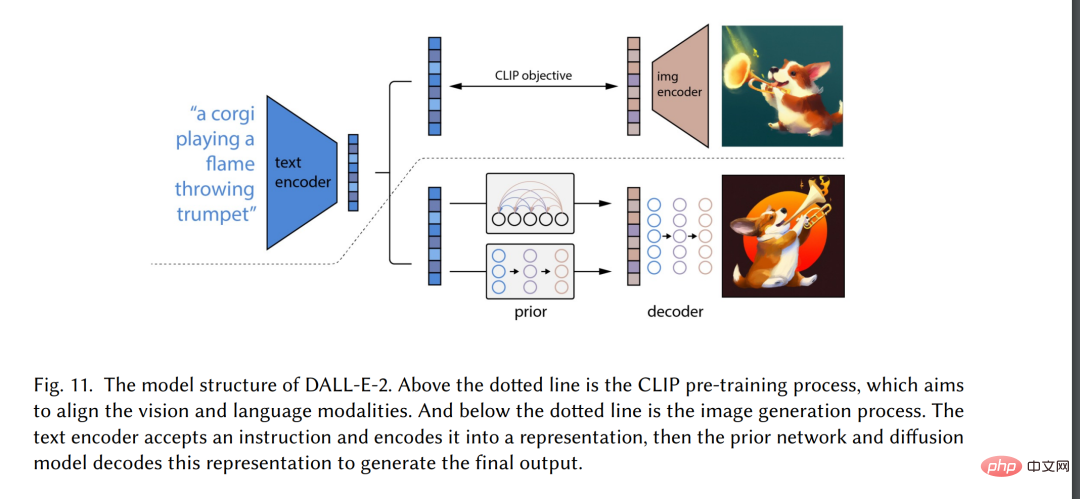
Ces dernières années, le contenu généré par l'intelligence artificielle (AIGC) a été influencé par les ordinateurs avec une large diffusion En dehors de la communauté scientifique, la société dans son ensemble a commencé à s'intéresser à divers produits de génération de contenu construits par de grandes entreprises technologiques [3], tels que ChatGPT [4] et DALL-E2 [5]. AIGC fait référence au contenu généré à l'aide de la technologie avancée d'IA générative (GAI), plutôt qu'au contenu créé par des auteurs humains. AIGC peut créer automatiquement de grandes quantités de contenu en peu de temps. Par exemple, ChatGPT est un modèle de langage développé par OpenAI pour créer des systèmes d’intelligence artificielle conversationnelle capables de comprendre efficacement et de répondre de manière significative aux entrées du langage humain. De plus, DALL-E-2 est un autre modèle GAI de pointe, également développé par OpenAI, capable de créer des images uniques de haute qualité à partir de descriptions textuelles en quelques minutes, comme le montre la figure 1 « Un astronaute avec une équitation dans un style réaliste". Grâce aux réalisations exceptionnelles de l’AIGC, de nombreuses personnes pensent que ce sera une nouvelle ère de l’intelligence artificielle et qu’elle aura un impact significatif sur le monde entier.
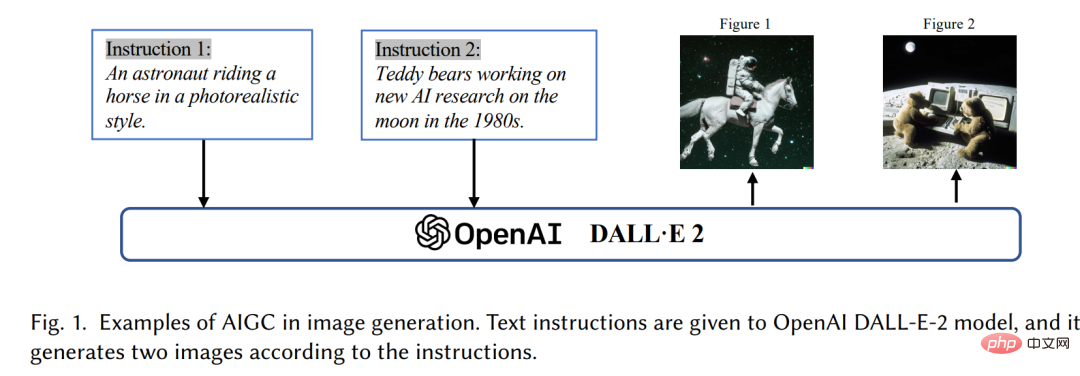
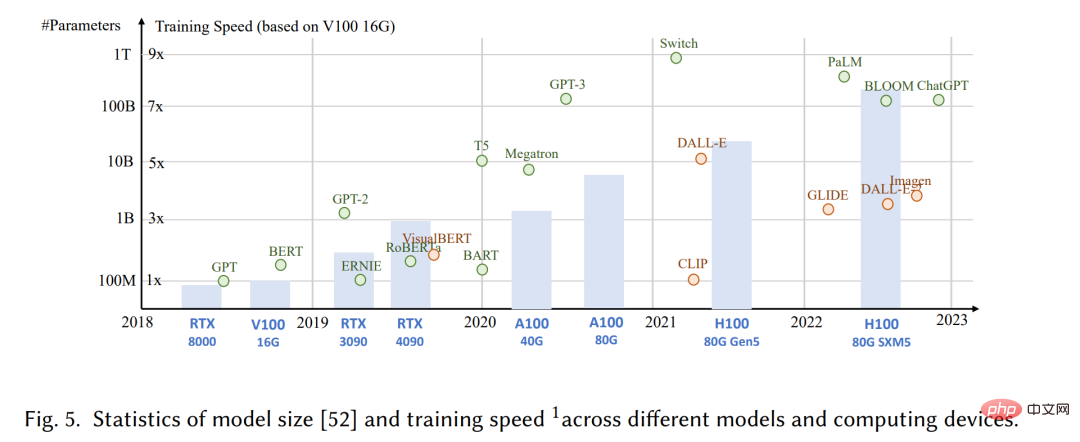
Techniquement parlant, AIGC fait référence à des instructions humaines données, qui peuvent aider à enseigner et à guider le modèle pour accomplir des tâches, et à utiliser l'algorithme GAI pour générer un contenu qui satisfait aux instructions. Le processus de génération comprend généralement deux étapes : extraire les informations d'intention à partir d'instructions humaines et générer du contenu basé sur l'intention extraite. Cependant, comme le montrent des études précédentes [6,7], le paradigme du modèle GAI contenant les deux étapes ci-dessus n'est pas entièrement nouveau. Par rapport aux travaux précédents, les principaux progrès du récent AIGC consistent à former des modèles génératifs plus complexes sur des ensembles de données plus vastes, à utiliser des architectures de modèles de base plus vastes et à avoir accès à un large éventail de ressources informatiques. Par exemple, le framework principal de GPT-3 reste le même que celui de GPT-2, mais la taille des données de pré-formation augmente de WebText [8] (38 Go) à CommonCrawl [9] (570 Go après filtrage), et la taille du modèle de base passe de 1,5 milliard à 175 milliards. Par conséquent, GPT-3 a une meilleure capacité de généralisation que GPT-2 sur des tâches telles que l’extraction d’intention humaine.
En plus des avantages d'un volume de données et d'une puissance de calcul accrus, les chercheurs explorent également les moyens d'intégrer les nouvelles technologies aux algorithmes GAI. Par exemple, ChatGPT utilise l'apprentissage par renforcement à partir de la rétroaction humaine (RLHF) [10-12] pour déterminer la réponse la plus appropriée à une instruction donnée, améliorant ainsi la fiabilité et la précision du modèle au fil du temps. Cette approche permet à ChatGPT de mieux comprendre les préférences humaines dans les longues conversations. Parallèlement, dans le domaine de la vision par ordinateur, la diffusion stable a été proposée par Stability [13]. L’IA a également connu un grand succès dans la génération d’images en 2022. Contrairement aux méthodes précédentes, les modèles de diffusion générative peuvent aider à générer des images haute résolution en contrôlant le compromis entre exploration et exploitation, combinant ainsi harmonieusement la diversité des images générées et leur similarité avec les données d'entraînement.
En combinant ces avancées, le modèle a fait des progrès significatifs sur les tâches AIGC et a été appliqué à diverses industries, notamment l'art [14], la publicité [15], l'éducation [16], etc. Dans un avenir proche, l’AIGC continuera de devenir un domaine de recherche important en apprentissage automatique. Il est donc crucial de mener une étude approfondie des recherches antérieures et d’identifier les questions ouvertes dans le domaine. Les technologies et applications de base dans le domaine de l’AIGC sont passées en revue.
Il s'agit de la première revue complète de l'AIGC, résumant le GAI du point de vue technologique et applicatif. Des recherches antérieures se sont concentrées sur le GAI sous différents angles, notamment la génération de langage naturel [17], la génération d'images [18] et la génération dans l'apprentissage automatique multimodal [7, 19]. Cependant, les travaux antérieurs se sont concentrés uniquement sur des parties spécifiques de l'AIGC. Cet article passe d’abord en revue les techniques de base couramment utilisées dans AIGC. Un résumé complet de l'algorithme GAI avancé est en outre fourni, y compris la génération à pic unique et la génération à pics multiples, comme le montre la figure 2. De plus, les applications et les défis potentiels de l’AIGC sont discutés. Enfin, les problèmes existants et les orientations futures de la recherche dans ce domaine sont soulignés. En résumé, les principales contributions de cet article sont les suivantes :
- Au meilleur de nos connaissances, nous sommes les premiers à fournir une définition formelle et une enquête approfondie sur les processus de génération AIGC et améliorés par l'IA.
- Passe en revue l'histoire et la technologie de base de l'AIGC et effectue une analyse complète des derniers progrès des tâches et des modèles GAI du point de vue de la génération monomodale et de la génération multimodale.
- Discuté des principaux défis auxquels est confronté l'AIGC et des futures tendances de recherche de l'AIGC.
La suite de l'enquête est organisée comme suit. La section 2 passe principalement en revue l’histoire de l’AIGC sous deux aspects : la modalité visuelle et la modalité linguistique. La section 3 présente les composants de base actuellement largement utilisés dans la formation du modèle GAI. La section 4 résume les progrès récents des modèles GAI, dans laquelle la section 4.1 examine les progrès d'un point de vue monomodal et la section 4.2 examine les progrès d'un point de vue de génération multimodale. Dans la génération multimodale, des modèles de langage visuel, des modèles de texte audio, des modèles de graphique de texte et des modèles de code de texte sont introduits. Les sections 5 et 6 présentent l'application du modèle GAI dans l'AIGC et quelques recherches importantes liées à ce domaine. Les sections 7 et 8 révèlent les risques, les problèmes existants et les orientations de développement futures de la technologie AIGC. Enfin, nous résumons notre étude en 9.
Histoire de l'intelligence artificielle générative
Les modèles génératifs ont une longue histoire dans le domaine de l'intelligence artificielle, remontant aux années 1950, avec les modèles de Markov cachés (HMM) [20] et les modèles de mélange gaussien (GMM) [ 21] développement. Ces modèles génèrent des données séquentielles telles que la parole et des séries chronologiques. Cependant, il a fallu attendre l’avènement du deep learning pour que les modèles génératifs connaissent des améliorations significatives de leurs performances.
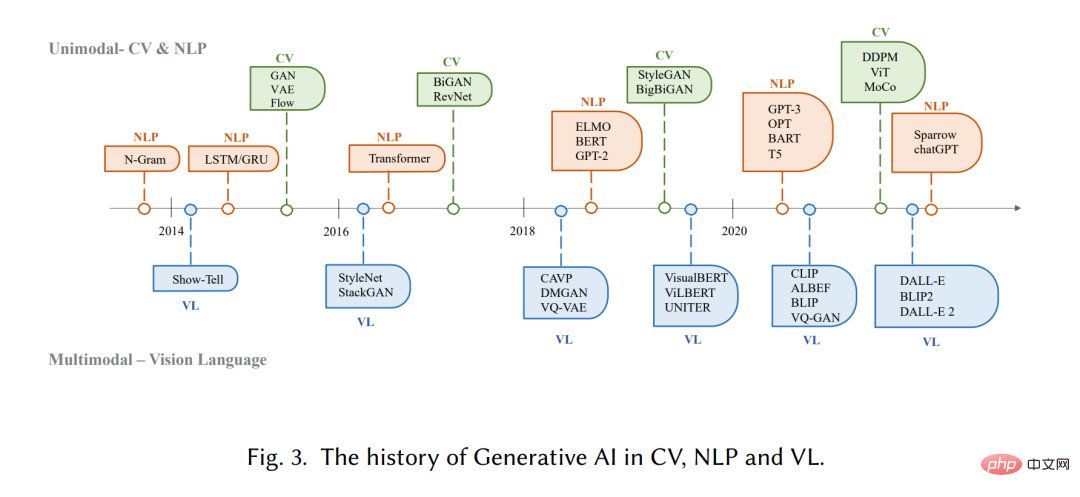
Dans les premiers modèles génératifs profonds, les différents domaines ne se chevauchaient généralement pas beaucoup. Dans le traitement du langage naturel (NLP), la méthode traditionnelle de génération de phrases consiste à utiliser la modélisation du langage N-gram [22] pour apprendre la distribution des mots, puis rechercher la meilleure séquence. Cependant, cette méthode ne peut pas s’adapter efficacement aux peines longues. Pour résoudre ce problème, les réseaux de neurones récurrents (RNN) [23] ont ensuite été introduits dans les tâches de modélisation du langage, permettant de modéliser des dépendances relativement longues. Par la suite, le développement de la mémoire à long terme (LSTM) [24] et des unités récurrentes fermées (GRU) [25], qui utilisent des mécanismes de déclenchement pour contrôler la mémoire pendant l'entraînement. Ces méthodes sont capables de gérer environ 200 jetons dans l'échantillon [26], ce qui constitue une amélioration significative par rapport aux modèles de langage N-gram.
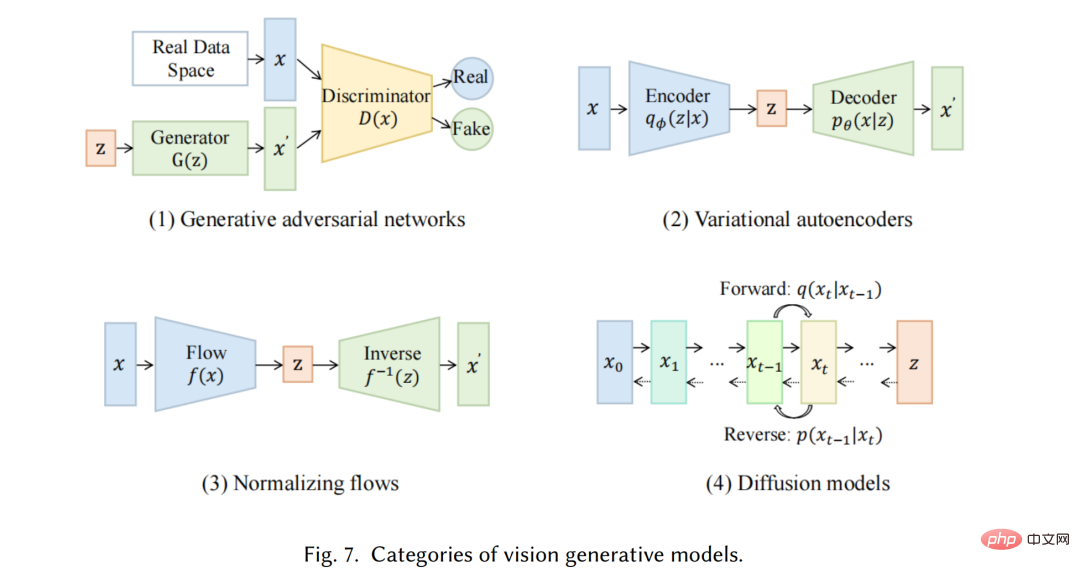
Pendant ce temps, dans le domaine de la vision par ordinateur (CV), avant l'émergence de méthodes basées sur l'apprentissage profond, les algorithmes traditionnels de génération d'images utilisaient des techniques telles que la synthèse de textures [27] et le mappage de textures [28]. Ces algorithmes sont basés sur des fonctionnalités conçues à la main et ont des capacités limitées pour générer des images complexes et diverses. En 2014, les réseaux contradictoires génératifs (GAN) [29] ont été proposés pour la première fois et ont obtenu des résultats impressionnants dans diverses applications, ce qui constitue une étape importante dans le domaine. Des auto-encodeurs variationnels (VAE) [30] et d'autres méthodes, telles que des modèles génératifs de diffusion [31], ont également été développés pour un contrôle plus fin du processus de génération d'images et la capacité de générer des images de haute qualité
Le développement de modèles génératifs dans différents domaines suit des chemins différents, mais finalement un problème transversal se pose : l'architecture du transformateur [32]. Vaswani et al. ont introduit la tâche PNL en 2017, et Transformer a ensuite été appliqué au CV, puis est devenu l'épine dorsale de nombreux modèles génératifs dans différents domaines [9, 33, 34]. Dans le domaine du NLP, de nombreux modèles de langage à grande échelle bien connus, tels que BERT et GPT, adoptent l'architecture du transformateur comme élément de base principal, ce qui présente des avantages par rapport aux éléments de base précédents tels que LSTM et GRU. Dans CV, Vision Transformer (ViT) [35] et Swin Transformer [36] ont ensuite développé ce concept en combinant l'architecture Transformer avec un composant de vision afin qu'il puisse être appliqué en aval basé sur l'image. Outre les améliorations apportées par les transformateurs aux modalités individuelles, ce croisement permet également de fusionner des modèles de différents domaines pour accomplir des tâches multimodales. Un exemple de modèle multimodal est CLIP [37]. CLIP est un modèle de langage vision commun qui combine une architecture de transformateur avec un composant de vision, lui permettant d'être formé sur de grandes quantités de données texte et image. Puisqu’il combine des connaissances visuelles et linguistiques lors de la pré-formation, il peut également être utilisé comme encodeur d’images dans la génération de signaux multimodaux. Dans l’ensemble, l’émergence de modèles basés sur des transformateurs a révolutionné la production d’intelligence artificielle et a ouvert la voie à une formation à grande échelle.
Ces dernières années, les chercheurs ont également commencé à introduire de nouvelles technologies basées sur ces modèles. Par exemple, en PNL, les gens préfèrent parfois les conseils en quelques coups [38] au réglage fin, qui fait référence à l'inclusion dans l'indice de quelques exemples sélectionnés dans l'ensemble de données pour aider le modèle à mieux comprendre les exigences de la tâche. Dans les langages visuels, les chercheurs combinent souvent des modèles spécifiques à une modalité avec des objectifs d’apprentissage contrastifs auto-supervisés pour fournir des représentations plus robustes. À l'avenir, à mesure que l'AIGC deviendra de plus en plus important, de plus en plus de technologies seront introduites, rendant ce domaine plein de vitalité.
Intelligence artificielle générative
Nous présenterons le modèle génératif monomodal de pointe. Ces modèles sont conçus pour accepter une modalité de données brutes spécifique en entrée, telle que du texte ou des images, puis générer des prédictions dans la même modalité que l'entrée. Nous discuterons de certaines des méthodes et techniques les plus prometteuses utilisées dans ces modèles, notamment des modèles de langage génératifs tels que GPT3 [9], BART [34], T5 [56] et des modèles de vision générative tels que GAN [29], VAE [ 30 ] et débit normalisé [57].
Modèle multimodal
La génération multimodale est une partie importante de l'AIGC d'aujourd'hui. Le but de la génération multimodale est d'apprendre à générer des modèles de modalités originales en apprenant les connexions multimodales et les interactions de données [7]. De telles connexions et interactions entre modalités sont parfois très complexes, ce qui rend les espaces de représentation multimodaux difficiles à apprendre par rapport aux espaces de représentation monomodaux. Cependant, avec l’émergence de la puissante infrastructure spécifique aux modèles mentionnée précédemment, de plus en plus de méthodes sont proposées pour relever ce défi. Dans cette section, nous présentons des modèles multimodaux de pointe en matière de génération de langage visuel, de génération audio textuelle, de génération de graphiques textuels et de génération de code textuel. Étant donné que la plupart des modèles génératifs multimodaux sont toujours très pertinents pour les applications pratiques, cette section les présente principalement du point de vue des tâches en aval.
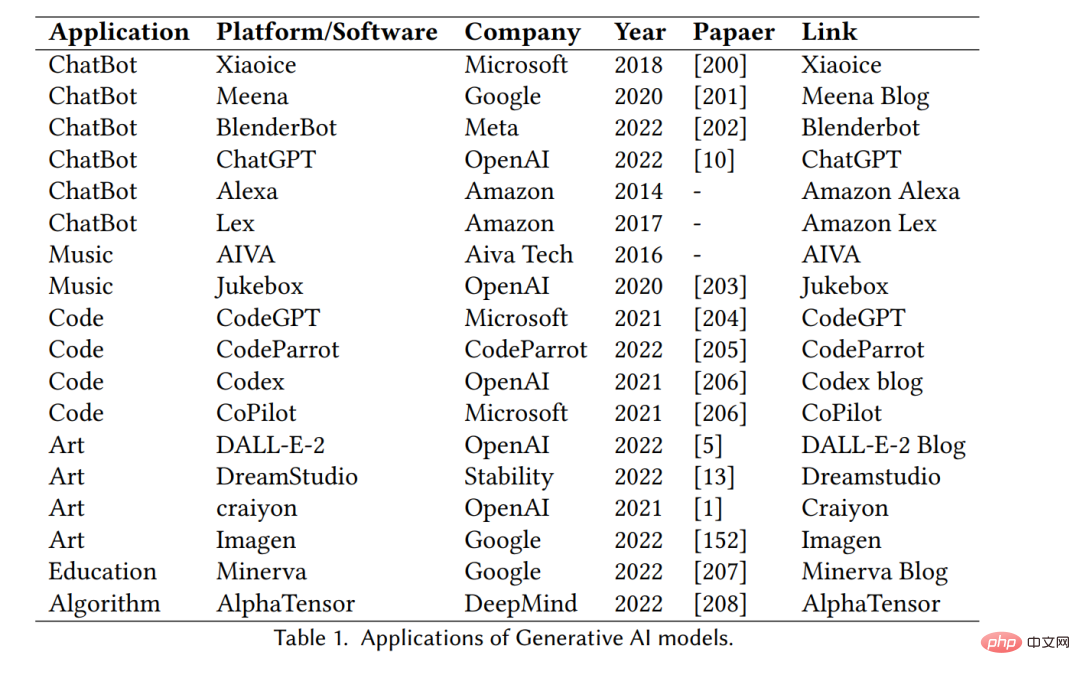
Applications
Efficacité
Au cours de la dernière décennie, les modèles d'IA génératifs profonds avec des réseaux de neurones ont dominé le domaine de l'apprentissage automatique, et leur essor est attribué à Lors du concours ImageNet de 2012 [210], cela a conduit à un concours pour créer des modèles plus profonds et plus complexes. Cette tendance est également apparue dans le domaine de la compréhension du langage naturel, où des modèles comme BERT et GPT-3 ont développé un grand nombre de paramètres. Cependant, l'empreinte et la complexité croissantes du modèle, ainsi que le coût et les ressources nécessaires à la formation et au déploiement, posent des défis pour un déploiement pratique dans le monde réel. Le principal défi est l’efficacité, qui peut se décomposer comme suit :
- Efficacité de l'inférence : cela concerne les considérations pratiques liées au déploiement d'un modèle d'inférence, c'est-à-dire le calcul de la sortie du modèle pour une entrée donnée. L'efficacité de l'inférence est principalement liée à la taille du modèle, à la vitesse et à la consommation de ressources (par exemple, utilisation du disque et de la RAM) pendant l'inférence.
- Efficacité de la formation : cela couvre les facteurs qui affectent la vitesse et les besoins en ressources de la formation d'un modèle, tels que le temps de formation, l'empreinte mémoire et l'évolutivité sur plusieurs appareils. Cela peut également inclure la prise en compte de la quantité de données requise pour obtenir des performances optimales sur une tâche donnée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI