

 Périphériques technologiquesIASeulement 10 % des paramètres sont nécessaires pour surpasser SOTA ! L'Université du Zhejiang, Byte et les Chinois de Hong Kong ont proposé conjointement un nouveau cadre pour la tâche « d'estimation de pose au niveau de la catégorie ».
Périphériques technologiquesIASeulement 10 % des paramètres sont nécessaires pour surpasser SOTA ! L'Université du Zhejiang, Byte et les Chinois de Hong Kong ont proposé conjointement un nouveau cadre pour la tâche « d'estimation de pose au niveau de la catégorie ».
Donner aux robots une compréhension 3D des objets du quotidien est un défi majeur dans les applications robotiques.
Lors de l'exploration dans un environnement inconnu, les méthodes d'estimation de pose d'objet existantes sont encore insatisfaisantes en raison de la diversité des formes d'objets.

Récemment, des chercheurs de l'Université du Zhejiang, du laboratoire d'intelligence artificielle ByteDance et de l'Université chinoise de Hong Kong ont proposé conjointement un nouveau cadre pour l'estimation de la forme et de la pose d'un objet au niveau d'une catégorie à partir d'une seule image RVB-D.

Adresse papier : https://arxiv.org/abs/2210.01112
Lien du projet : https://zju3dv.github.io/gCasp
À Pour gérer la variation de forme des objets au sein d'une catégorie, les chercheurs adoptent des représentations sémantiques primitives pour coder différentes formes dans un espace latent unifié. Cette représentation est établie de manière fiable entre nuages de points observés et formes estimées La clé de la correspondance.
Ensuite, en concevant un descripteur de forme qui est invariant aux transformations de similarité de corps rigides, l'estimation de la forme et de la pose de l'objet est découplée, prenant ainsi en charge l'optimisation implicite de la forme de l'objet cible dans n'importe quelle pose. Les expériences montrent que la méthode proposée atteint des performances d'estimation de pose de premier plan dans les ensembles de données publics.
Contexte de rechercheDans le domaine de la perception et du fonctionnement des robots, l'estimation de la forme et de la pose des objets du quotidien est une fonction de base et a une variété d'applications, notamment la compréhension de scènes 3D, le fonctionnement des robots et l'entreposage autonome.
La plupart des premiers travaux sur cette tâche se sont concentrés sur l'estimation de la pose au niveau de l'instance, qui obtient principalement la pose de l'objet en alignant l'objet observé avec un modèle CAO donné.
Cependant, une telle configuration est limitée dans les scénarios du monde réel car il est difficile d'obtenir à l'avance un modèle exact d'un objet donné.
Pour généraliser à des objets invisibles mais sémantiquement familiers, l'estimation de la pose d'objet au niveau de la catégorie attire de plus en plus l'attention des chercheurs car elle peut potentiellement gérer diverses instances de la même catégorie dans des scènes réelles.

Les méthodes d'estimation de pose existantes au niveau de la catégorie tentent généralement de prédire les coordonnées normalisées au niveau des pixels des instances d'une classe, ou utilisent un modèle de référence antérieur après déformation pour estimer la pose de l'objet.
Bien que ces travaux aient fait de grands progrès, ces méthodes de prédiction one-shot se heurtent encore à des difficultés lorsqu'il existe de grandes différences de forme dans une même catégorie.
Afin de gérer la diversité des objets au sein d'une même catégorie, certaines œuvres utilisent une représentation neuronale implicite pour s'adapter à la forme de l'objet cible en optimisant de manière itérative la pose et la forme dans l'espace implicite et obtenir de meilleures performances.
Il existe deux défis principaux dans l'estimation de la pose d'objet au niveau de la catégorie. L'un est l'énorme différence de forme intra-classe, et l'autre est que les méthodes existantes couplent la forme et la pose pour l'optimisation, ce qui peut facilement conduire à des problèmes d'optimisation. Plus complexe.
Dans cet article, les chercheurs dissocient l'estimation de la forme et de la pose des objets en concevant un descripteur de forme qui est invariant aux transformations de similarité de corps rigides, prenant ainsi en charge l'optimisation implicite de la forme des objets cibles dans des poses arbitraires. Enfin, sur la base de l'association sémantique entre la forme estimée et l'observation, l'échelle et la pose de l'objet sont résolues.
Introduction à l'algorithmeL'algorithme se compose de trois modules, Extraction primitive sémantique, Estimation générative de forme et Estimation de la pose d'objet.

L'entrée de l'algorithme est une seule image RVB-D. L'algorithme utilise le masque R-CNN pré-entraîné pour obtenir les résultats de segmentation sémantique de l'image RVB, puis rétroprojete le nuage de points de chaque objet en fonction de cela. les paramètres internes de la caméra. Cette méthode traite principalement les nuages de points et obtient finalement l'échelle et la pose 6DoF de chaque objet.
Semantic Primitive Extraction
DualSDF [1] propose une méthode de représentation de primitives sémantiques pour des objets similaires. Comme le montre le côté gauche de la figure ci-dessous, dans un même type d'objet, chaque instance est divisée en un certain nombre de primitives sémantiques, et le label de chaque primitive correspond à une partie spécifique d'un certain type d'objet.
Afin d'extraire les primitives sémantiques des objets du nuage de points d'observation, l'auteur utilise un réseau de segmentation de nuages de points pour segmenter le nuage de points d'observation en primitives sémantiques avec des étiquettes.

Estimation générative de forme
Les modèles génératifs 3D (tels que DeepSDF) fonctionnent principalement dans un système de coordonnées normalisé.
Cependant, il y aura une transformation de pose similaire (rotation, translation et échelle) entre l'objet dans l'observation du monde réel et le système de coordonnées normalisé.
Afin de résoudre la forme normalisée correspondant à l'observation courante lorsque la pose est inconnue, l'auteur propose un descripteur de forme invariant aux transformations similaires basé sur une représentation sémantique primitive.
Ce descripteur est présenté dans la figure ci-dessous, qui décrit l'angle entre des vecteurs composés de différentes primitives :
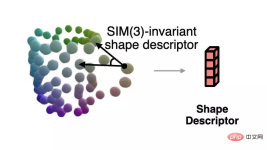
L'auteur utilise ce descripteur pour mesurer la différence entre l'observation actuelle et l'erreur de forme estimée, et utilisez la descente de gradient pour rendre la forme estimée plus cohérente avec l'observation. Le processus est illustré dans la figure ci-dessous.
L'auteur montre également d'autres exemples d'optimisation de forme.

Estimation de la pose
Enfin, à travers la correspondance primitive sémantique entre le nuage de points observé et la forme résolue, l'auteur utilise l'algorithme d'Umeyama pour résoudre la pose de la forme observée.

Résultats expérimentaux
L'auteur a mené des expériences comparatives sur les ensembles de données REAL275 (ensemble de données réelles) et CAMERA25 (ensemble de données synthétiques) fournis par NOCS, et a comparé la précision de l'estimation de la pose avec d'autres méthodes. surpasse de loin les autres méthodes sur plusieurs indicateurs.
Dans le même temps, l'auteur a également comparé la quantité de paramètres qui doivent être entraînés sur l'ensemble d'entraînement fourni par NOCS. L'auteur a besoin d'un minimum de 2,3 millions de paramètres pour atteindre le niveau de pointe. .

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Comment construire votre assistant d'IA personnel avec HuggingFace SmollmApr 18, 2025 am 11:52 AM
Comment construire votre assistant d'IA personnel avec HuggingFace SmollmApr 18, 2025 am 11:52 AMExploiter la puissance de l'IA sur disvise: construire une CLI de chatbot personnelle Dans un passé récent, le concept d'un assistant d'IA personnel semblait être une science-fiction. Imaginez Alex, un passionné de technologie, rêvant d'un compagnon d'IA intelligent et local - celui qui ne dépend pas
 L'IA pour la santé mentale est attentivement analysée via une nouvelle initiative passionnante à l'Université de StanfordApr 18, 2025 am 11:49 AM
L'IA pour la santé mentale est attentivement analysée via une nouvelle initiative passionnante à l'Université de StanfordApr 18, 2025 am 11:49 AMLeur lancement inaugural de l'AI4MH a eu lieu le 15 avril 2025, et le Dr Tom Insel, M.D., célèbre psychiatre et neuroscientifique, a été le conférencier de lancement. Le Dr Insel est réputé pour son travail exceptionnel dans la recherche en santé mentale et la techno
 La classe de draft de la WNBA 2025 entre dans une ligue qui grandit et luttant sur le harcèlement en ligneApr 18, 2025 am 11:44 AM
La classe de draft de la WNBA 2025 entre dans une ligue qui grandit et luttant sur le harcèlement en ligneApr 18, 2025 am 11:44 AM"Nous voulons nous assurer que la WNBA reste un espace où tout le monde, les joueurs, les fans et les partenaires d'entreprise, se sentent en sécurité, appréciés et autonomes", a déclaré Engelbert, abordé ce qui est devenu l'un des défis les plus dommageables des sports féminins. L'anno
 Guide complet des structures de données intégrées Python - Analytics VidhyaApr 18, 2025 am 11:43 AM
Guide complet des structures de données intégrées Python - Analytics VidhyaApr 18, 2025 am 11:43 AMIntroduction Python excelle comme un langage de programmation, en particulier dans la science des données et l'IA générative. La manipulation efficace des données (stockage, gestion et accès) est cruciale lorsqu'il s'agit de grands ensembles de données. Nous avons déjà couvert les nombres et ST
 Premières impressions des nouveaux modèles d'Openai par rapport aux alternativesApr 18, 2025 am 11:41 AM
Premières impressions des nouveaux modèles d'Openai par rapport aux alternativesApr 18, 2025 am 11:41 AMAvant de plonger, une mise en garde importante: les performances de l'IA sont non déterministes et très usagées. En termes plus simples, votre kilométrage peut varier. Ne prenez pas cet article (ou aucun autre) article comme le dernier mot - au lieu, testez ces modèles sur votre propre scénario
 Portfolio AI | Comment construire un portefeuille pour une carrière en IA?Apr 18, 2025 am 11:40 AM
Portfolio AI | Comment construire un portefeuille pour une carrière en IA?Apr 18, 2025 am 11:40 AMConstruire un portefeuille AI / ML hors concours: un guide pour les débutants et les professionnels La création d'un portefeuille convaincant est cruciale pour sécuriser les rôles dans l'intelligence artificielle (IA) et l'apprentissage automatique (ML). Ce guide fournit des conseils pour construire un portefeuille
 Ce que l'IA agentique pourrait signifier pour les opérations de sécuritéApr 18, 2025 am 11:36 AM
Ce que l'IA agentique pourrait signifier pour les opérations de sécuritéApr 18, 2025 am 11:36 AMLe résultat? L'épuisement professionnel, l'inefficacité et un écart d'élargissement entre la détection et l'action. Rien de tout cela ne devrait être un choc pour quiconque travaille en cybersécurité. La promesse d'une IA agentique est devenue un tournant potentiel, cependant. Cette nouvelle classe
 Google contre Openai: la lutte contre l'IA pour les étudiantsApr 18, 2025 am 11:31 AM
Google contre Openai: la lutte contre l'IA pour les étudiantsApr 18, 2025 am 11:31 AMImpact immédiat contre partenariat à long terme? Il y a deux semaines, Openai s'est avancé avec une puissante offre à court terme, accordant aux étudiants des États-Unis et canadiens d'accès gratuit à Chatgpt Plus jusqu'à la fin mai 2025. Cet outil comprend GPT - 4O, un A


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

Listes Sec
SecLists est le compagnon ultime du testeur de sécurité. Il s'agit d'une collection de différents types de listes fréquemment utilisées lors des évaluations de sécurité, le tout en un seul endroit. SecLists contribue à rendre les tests de sécurité plus efficaces et productifs en fournissant facilement toutes les listes dont un testeur de sécurité pourrait avoir besoin. Les types de listes incluent les noms d'utilisateur, les mots de passe, les URL, les charges utiles floues, les modèles de données sensibles, les shells Web, etc. Le testeur peut simplement extraire ce référentiel sur une nouvelle machine de test et il aura accès à tous les types de listes dont il a besoin.

PhpStorm version Mac
Le dernier (2018.2.1) outil de développement intégré PHP professionnel

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

ZendStudio 13.5.1 Mac
Puissant environnement de développement intégré PHP

