
Maison >Périphériques technologiques >IA >Article recommandé : Segmentation et classification des tumeurs du sein dans les images échographiques basées sur un apprentissage contradictoire profond
Article recommandé : Segmentation et classification des tumeurs du sein dans les images échographiques basées sur un apprentissage contradictoire profond

- 王林avant
- 2023-04-15 08:19:03961parcourir
GAN conditionnel (cGAN) + Convolution atreuse (AC) + Attention de canal avec blocs pondérés (CAW).
Cet article propose une méthode de segmentation et de classification des tumeurs du sein pour les images échographiques (cGAN+AC+CAW) basée sur un apprentissage contradictoire profond. Bien que l'article ait été proposé en 2019, la méthode qu'il a proposée pour utiliser le GAN pour la segmentation était à cette époque Mais. c'est une idée très nouvelle. L'article a essentiellement intégré toutes les technologies qui pouvaient être intégrées à l'époque et a obtenu de très bons résultats, il vaut donc la peine d'être lu. De plus, l'article propose également une contre-mesure typique SSIM de perte et l1. perte de norme comme fonction de perte.
Utilisation de cGAN+AC+CAW pour la segmentation sémantique

Générateur G
Le réseau générateur se compose d'une partie encodeur : composée de sept couches convolutives (En1 à En7) et d'un décodeur : sept composé de couches de déconvolution (Dn1 à Dn7).
Insérer un bloc de convolution atreuse entre En3 et En4. Rapports de dilatation 1, 6 et 9, taille du noyau 3×3, foulée 2.
Il existe également une couche d'attention de canal avec un bloc de pondération de canal (CAW) entre En7 et Dn1.
Le bloc CAW est un ensemble de modules d'attention de canal (DAN) et de bloc de pondération de canal (SENet), qui augmentent la capacité de représentation des fonctionnalités de plus haut niveau du réseau de générateurs.
Discriminateur D
C'est une séquence de couches convolutives.
L'entrée du discriminateur est la concaténation de l'image et d'un masque binaire marquant la région tumorale.
La sortie du discriminateur est une matrice 10×10 avec des valeurs allant de 0,0 (complètement faux) à 1,0 (réel).
Fonction de perte
La fonction de perte du générateur G se compose de trois termes : perte contradictoire (perte d'entropie croisée binaire), norme l1 pour faciliter le processus d'apprentissage et perte SSIM pour améliorer la forme des limites du masque de segmentation :
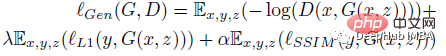
où z est une variable aléatoire. La fonction de perte du discriminateur D est la suivante :
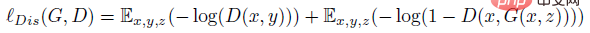
Utilisation d'une forêt aléatoire pour la tâche de classification
Chaque image est entrée dans le réseau génératif entraîné pour obtenir la limite de la tumeur, puis 13 caractéristiques statistiques sont calculées à partir de cette limite : dimension fractale, lacunarité, coque convexe, convexité, circularité, aire, périmètre, centroïde, longueur des axes mineur et majeur, douceur, moments Hu (6) et moments centraux (ordre 3 et inférieur)
Utilisation d'une sélection exhaustive de fonctionnalités), algorithme pour sélectionner l’ensemble de fonctionnalités optimal. L'algorithme EFS montre que la dimension fractale, la lacunarité, l'enveloppe convexe et le centroïde sont les quatre caractéristiques optimales.
Ces caractéristiques sélectionnées sont introduites dans un classificateur forestier aléatoire, qui est ensuite entraîné à différencier les tumeurs bénignes et malignes.
Comparaison des résultats
Segmentation
L'ensemble de données contient 150 tumeurs malignes et 100 tumeurs bénignes contenues dans l'image. Pour entraîner le modèle, l'ensemble de données a été divisé de manière aléatoire en ensemble d'entraînement (70 %), ensemble de validation (10 %) et ensemble de test (20 %).

Ce modèle (cGAN+AC+CAW) surpasse les autres modèles dans tous les indicateurs. Ses scores Dice et IoU sont respectivement de 93,76 % et 88,82 %.
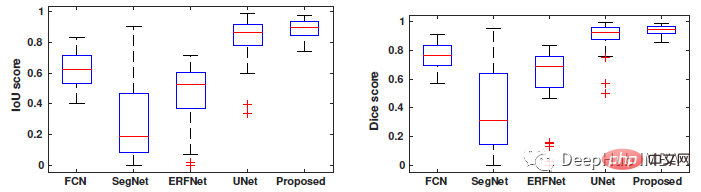
Comparaison de box plots d'IoU et de Dice du modèle papier avec des têtes de segmentation telles que FCN, SegNet, ERFNet et U-Net.

La plage de valeurs de ce modèle pour le coefficient Dice est de 88 % à 94 %, et la plage de valeurs pour IoU est de 80 % à 89 %, tandis que les valeursd'autres méthodes de segmentation profonde FCN, SegNet, ERFNet et U-Net sont La plage de valeurs est plus large.
Résultats de segmentation Comme le montre la figure ci-dessus, SegNet et ERFNet ont produit les pires résultats, avec un grand nombre de zones de faux négatifs (rouges) et quelques zones de faux positifs (verts).
Bien que U-Net, DCGAN et cGAN offrent une bonne segmentation, le modèle proposé dans l'article fournit une segmentation plus précise des limites de la tumeur du sein.
Classification

La méthode de classification des tumeurs du sein proposée est meilleure que [9], avec une précision globale de 85 %.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI