

 Périphériques technologiquesIAInterprétation de CRISP-ML(Q) : processus du cycle de vie de l'apprentissage automatique
Périphériques technologiquesIAInterprétation de CRISP-ML(Q) : processus du cycle de vie de l'apprentissage automatiqueInterprétation de CRISP-ML(Q) : processus du cycle de vie de l'apprentissage automatique

Traducteur | Bugatti
Reviewer | Sun Shujuan
Actuellement, il n'existe pas de pratiques standard pour la création et la gestion d'applications d'apprentissage automatique (ML). Les projets d’apprentissage automatique sont mal organisés, manquent de répétabilité et ont tendance à échouer à long terme. Par conséquent, nous avons besoin d’un processus qui nous aide à maintenir la qualité, la durabilité, la robustesse et la gestion des coûts tout au long du cycle de vie de l’apprentissage automatique.
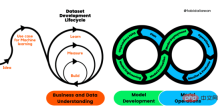
Figure 1. Processus du cycle de vie du développement de l'apprentissage automatique
Le processus standard intersectoriel pour le développement d'applications d'apprentissage automatique à l'aide de méthodes d'assurance qualité (CRISP-ML(Q)) est une version améliorée de CRISP-DM pour garantir que la machine apprendre la qualité des produits.
CRISP-ML (Q) comporte six étapes distinctes :
1. Compréhension de l'activité et des données
2 Préparation des données
3. Évaluation du modèle
5. et Maintenance
Ces étapes nécessitent une itération et une exploration constantes pour créer de meilleures solutions. Même si le cadre est ordonné, les résultats d’une étape ultérieure peuvent déterminer si nous devons réexaminer l’étape précédente.
Figure 2. Assurance qualité à chaque étape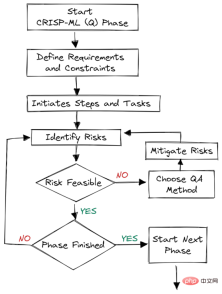 Des méthodes d'assurance qualité sont introduites à chaque étape du cadre. Cette approche comporte des exigences et des contraintes, telles que des mesures de performances, des exigences en matière de qualité des données et de robustesse. Cela permet de réduire les risques qui ont un impact sur le succès des applications d’apprentissage automatique. Cela peut être réalisé en surveillant et en entretenant en permanence l’ensemble du système.
Des méthodes d'assurance qualité sont introduites à chaque étape du cadre. Cette approche comporte des exigences et des contraintes, telles que des mesures de performances, des exigences en matière de qualité des données et de robustesse. Cela permet de réduire les risques qui ont un impact sur le succès des applications d’apprentissage automatique. Cela peut être réalisé en surveillant et en entretenant en permanence l’ensemble du système.
Par exemple : dans les entreprises de commerce électronique, la dérive des données et des concepts entraînera une dégradation du modèle ; si nous ne déployons pas de systèmes pour surveiller ces changements, l'entreprise subira des pertes, c'est-à-dire des clients.
Compréhension des affaires et des données
Au début du processus de développement, nous devons déterminer la portée du projet, les critères de réussite et la faisabilité de l'application ML. Après cela, nous avons commencé le processus de collecte de données et de vérification de la qualité. Le processus est long et difficile.
Portée :Ce que nous espérons réaliser en utilisant un processus d'apprentissage automatique. Est-ce pour fidéliser les clients ou réduire les coûts d’exploitation grâce à l’automatisation ?
Critères de réussite : Nous devons définir des indicateurs de réussite commerciaux, d'apprentissage automatique (indicateurs statistiques) et économiques (KPI) clairs et mesurables.
Faisabilité : Nous devons garantir la disponibilité des données, l'adéquation aux applications d'apprentissage automatique, les contraintes juridiques, la robustesse, l'évolutivité, l'interprétabilité et les besoins en ressources.
Collecte de données : Activez la reproductibilité en collectant des données, en les versionnant et en assurant un flux constant de données réelles et générées.
Vérification de la qualité des données : Assurez la qualité en maintenant les descriptions, les exigences et les validations des données.
Pour garantir la qualité et la reproductibilité, nous devons enregistrer les propriétés statistiques des données et le processus de génération des données. Préparation des données
La deuxième étape est très simple. Nous préparerons les données pour la phase de modélisation. Cela comprend la sélection des données, le nettoyage des données, l'ingénierie des fonctionnalités, l'amélioration et la normalisation des données.
1. Nous commençons par la sélection des fonctionnalités, la sélection des données et la gestion des classes déséquilibrées par suréchantillonnage ou sous-échantillonnage.
2. Ensuite, concentrez-vous sur la réduction du bruit et la gestion des valeurs manquantes. À des fins d'assurance qualité, nous ajouterons des tests unitaires de données pour réduire les valeurs erronées.
3. Selon le modèle, nous effectuons l'ingénierie des fonctionnalités et l'augmentation des données telles que l'encodage à chaud et le clustering.
4. Normalisez et étendez les données. Cela réduit le risque de fonctionnalités biaisées.
Pour garantir la reproductibilité, nous avons créé des pipelines de modélisation, de transformation et d'ingénierie de fonctionnalités.
Ingénierie des modèles
Les contraintes et exigences des phases métier et de compréhension des données détermineront la phase de modélisation. Nous devons comprendre les problèmes commerciaux et comment nous développerons des modèles d’apprentissage automatique pour les résoudre. Nous nous concentrerons sur la sélection, l'optimisation et la formation des modèles, en garantissant les mesures de performances, la robustesse, l'évolutivité, l'interprétabilité du modèle et en optimisant les ressources de stockage et de calcul.
1. Recherche sur l'architecture des modèles et problèmes commerciaux similaires.
2. Définir les indicateurs de performance du modèle.
3. Sélection du modèle.
4. Comprendre les connaissances du domaine en intégrant des experts.
5. Formation de modèle.
6. Compression et intégration du modèle.
Pour garantir la qualité et la reproductibilité, nous stockerons et contrôlerons les métadonnées du modèle, telles que l'architecture du modèle, les données de formation et de validation, les hyperparamètres et les descriptions d'environnement.
Enfin, nous suivrons les expériences de ML et créerons des pipelines de ML pour créer des processus de formation reproductibles.
Évaluation du modèle
C'est l'étape où nous testons et nous assurons que le modèle est prêt à être déployé.
- Nous testerons les performances du modèle sur l'ensemble de données de test.
- Évaluez la robustesse du modèle en fournissant des données aléatoires ou fausses.
- Améliorez l'interprétabilité du modèle pour répondre aux exigences réglementaires.
- Comparez les résultats aux mesures de réussite initiales automatiquement ou avec des experts du domaine.
Chaque étape de la phase d'évaluation est enregistrée pour l'assurance qualité.
Déploiement de modèles
Le déploiement de modèles est l'étape où nous intégrons des modèles d'apprentissage automatique dans les systèmes existants. Le modèle peut être déployé sur des serveurs, des navigateurs, des logiciels et des appareils périphériques. Les prédictions du modèle sont disponibles dans les tableaux de bord BI, les API, les applications Web et les plug-ins.
Processus de déploiement du modèle :
- Définir l'inférence matérielle.
- Évaluation de modèles en environnement de production.
- Assurer l'acceptation et la convivialité des utilisateurs.
- Fournissez des plans de sauvegarde pour minimiser les pertes.
- Stratégie de déploiement.
Surveillance et maintenance
Les modèles dans les environnements de production nécessitent une surveillance et une maintenance continues. Nous surveillerons la rapidité du modèle, les performances matérielles et les performances logicielles.
La surveillance continue est la première partie du processus ; si les performances descendent en dessous d'un seuil, une décision est prise automatiquement pour recycler le modèle sur de nouvelles données. De plus, la partie maintenance ne se limite pas au recyclage des modèles. Cela nécessite des mécanismes de prise de décision, l’acquisition de nouvelles données, la mise à jour des logiciels et du matériel et l’amélioration des processus de ML en fonction de cas d’utilisation métier.
En bref, c'est l'intégration, la formation et le déploiement continus de modèles ML.
Conclusion
La formation et la validation des modèles ne représentent qu'une petite partie des applications ML. Transformer une idée initiale en réalité nécessite plusieurs processus. Dans cet article, nous présentons CRISP-ML(Q) et comment il se concentre sur l'évaluation des risques et l'assurance qualité.
Nous définissons d'abord les objectifs commerciaux, collectons et nettoyons les données, construisons le modèle, vérifions le modèle avec des ensembles de données de test, puis le déployons dans l'environnement de production.
Les éléments clés de ce cadre sont la surveillance et la maintenance continues. Nous surveillerons les données et les mesures logicielles et matérielles pour déterminer s'il convient de recycler le modèle ou de mettre à niveau le système.
Si vous débutez dans les opérations d'apprentissage automatique et souhaitez en savoir plus, lisez le cours MLOps gratuit examiné par DataTalks.Club. Vous acquerrez une expérience pratique des six phases et comprendrez la mise en œuvre pratique de CRISP-ML.
Titre original : Making Sense of CRISP-ML(Q): The Machine Learning Lifecycle Process, auteur : Abid Ali Awan
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Comment construire votre assistant d'IA personnel avec HuggingFace SmollmApr 18, 2025 am 11:52 AM
Comment construire votre assistant d'IA personnel avec HuggingFace SmollmApr 18, 2025 am 11:52 AMExploiter la puissance de l'IA sur disvise: construire une CLI de chatbot personnelle Dans un passé récent, le concept d'un assistant d'IA personnel semblait être une science-fiction. Imaginez Alex, un passionné de technologie, rêvant d'un compagnon d'IA intelligent et local - celui qui ne dépend pas
 L'IA pour la santé mentale est attentivement analysée via une nouvelle initiative passionnante à l'Université de StanfordApr 18, 2025 am 11:49 AM
L'IA pour la santé mentale est attentivement analysée via une nouvelle initiative passionnante à l'Université de StanfordApr 18, 2025 am 11:49 AMLeur lancement inaugural de l'AI4MH a eu lieu le 15 avril 2025, et le Dr Tom Insel, M.D., célèbre psychiatre et neuroscientifique, a été le conférencier de lancement. Le Dr Insel est réputé pour son travail exceptionnel dans la recherche en santé mentale et la techno
 La classe de draft de la WNBA 2025 entre dans une ligue qui grandit et luttant sur le harcèlement en ligneApr 18, 2025 am 11:44 AM
La classe de draft de la WNBA 2025 entre dans une ligue qui grandit et luttant sur le harcèlement en ligneApr 18, 2025 am 11:44 AM"Nous voulons nous assurer que la WNBA reste un espace où tout le monde, les joueurs, les fans et les partenaires d'entreprise, se sentent en sécurité, appréciés et autonomes", a déclaré Engelbert, abordé ce qui est devenu l'un des défis les plus dommageables des sports féminins. L'anno
 Guide complet des structures de données intégrées Python - Analytics VidhyaApr 18, 2025 am 11:43 AM
Guide complet des structures de données intégrées Python - Analytics VidhyaApr 18, 2025 am 11:43 AMIntroduction Python excelle comme un langage de programmation, en particulier dans la science des données et l'IA générative. La manipulation efficace des données (stockage, gestion et accès) est cruciale lorsqu'il s'agit de grands ensembles de données. Nous avons déjà couvert les nombres et ST
 Premières impressions des nouveaux modèles d'Openai par rapport aux alternativesApr 18, 2025 am 11:41 AM
Premières impressions des nouveaux modèles d'Openai par rapport aux alternativesApr 18, 2025 am 11:41 AMAvant de plonger, une mise en garde importante: les performances de l'IA sont non déterministes et très usagées. En termes plus simples, votre kilométrage peut varier. Ne prenez pas cet article (ou aucun autre) article comme le dernier mot - au lieu, testez ces modèles sur votre propre scénario
 Portfolio AI | Comment construire un portefeuille pour une carrière en IA?Apr 18, 2025 am 11:40 AM
Portfolio AI | Comment construire un portefeuille pour une carrière en IA?Apr 18, 2025 am 11:40 AMConstruire un portefeuille AI / ML hors concours: un guide pour les débutants et les professionnels La création d'un portefeuille convaincant est cruciale pour sécuriser les rôles dans l'intelligence artificielle (IA) et l'apprentissage automatique (ML). Ce guide fournit des conseils pour construire un portefeuille
 Ce que l'IA agentique pourrait signifier pour les opérations de sécuritéApr 18, 2025 am 11:36 AM
Ce que l'IA agentique pourrait signifier pour les opérations de sécuritéApr 18, 2025 am 11:36 AMLe résultat? L'épuisement professionnel, l'inefficacité et un écart d'élargissement entre la détection et l'action. Rien de tout cela ne devrait être un choc pour quiconque travaille en cybersécurité. La promesse d'une IA agentique est devenue un tournant potentiel, cependant. Cette nouvelle classe
 Google contre Openai: la lutte contre l'IA pour les étudiantsApr 18, 2025 am 11:31 AM
Google contre Openai: la lutte contre l'IA pour les étudiantsApr 18, 2025 am 11:31 AMImpact immédiat contre partenariat à long terme? Il y a deux semaines, Openai s'est avancé avec une puissante offre à court terme, accordant aux étudiants des États-Unis et canadiens d'accès gratuit à Chatgpt Plus jusqu'à la fin mai 2025. Cet outil comprend GPT - 4O, un A


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

PhpStorm version Mac
Le dernier (2018.2.1) outil de développement intégré PHP professionnel

Adaptateur de serveur SAP NetWeaver pour Eclipse
Intégrez Eclipse au serveur d'applications SAP NetWeaver.

SublimeText3 version anglaise
Recommandé : version Win, prend en charge les invites de code !

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

Dreamweaver Mac
Outils de développement Web visuel

