
Maison >Problème commun >Quelle redondance est généralement utilisée pour compresser les fichiers image ?
Quelle redondance est généralement utilisée pour compresser les fichiers image ?

- 青灯夜游original
- 2022-07-26 11:46:513832parcourir
Les fichiers image sont généralement compressés en utilisant la redondance de codage, la redondance inter-pixels et la redondance psychovisuelle. La redondance des données est le principal problème de la compression d'images numériques. Dans la compression d'images numériques, trois redondances de données de base peuvent être déterminées et utilisées : la redondance de codage, la redondance inter-pixels et la redondance psychovisuelle lorsque ces trois types de redondance sont compressés. données nécessaires pour représenter une quantité donnée d’informations) est obtenu lorsqu’un ou plusieurs d’entre eux sont réduits ou éliminés.

L'environnement d'exploitation de ce tutoriel : système Windows 7, ordinateur Dell G3.
Le problème résolu par la compression d'image est de minimiser la quantité de données nécessaire pour représenter les images numériques, et le principe de base de la réduction de la quantité de données est de supprimer les données excédentaires.
1. Introduction de base
Modèle de compression d'image : présente principalement l'encodage et le décodage des sources de signaux, et ne discute pas du canal de signal du processus de transmission.

La compression des données fait référence à la réduction de la quantité de données nécessaire pour représenter une quantité donnée d'informations.
Les données sont le moyen de transmission de l'information. La même quantité d’informations peut être représentée par différentes quantités de données.
Information : utilisé pour représenter les informations de l'image elle-même.
La redondance des données est un problème majeur dans la compression d'images numériques. Si n1 et n2 représentent le nombre d'unités d'information contenues dans deux ensembles de données représentant la même information, alors la redondance relative des données RD du premier ensemble de données (l'ensemble représenté par n1) peut être définie comme :

Ici, C est souvent appelé taux de compression et est défini comme :
Dans la compression d'images numériques, trois types fondamentaux de redondance de données peuvent être identifiés et exploités : la redondance de codage, la redondance inter-pixels et la redondance de la vision psychologique. La compression des données est obtenue lorsqu'une ou plusieurs de ces trois redondances sont réduites ou éliminées.
2. Redondance du codage
Pour les images, on peut supposer qu'une variable aléatoire discrète représente le niveau de gris de l'image, et la probabilité que chaque niveau de gris (rk) apparaisse est pr
Ici L est le nombre de niveaux de gris, nk est le nombre de fois que le kème niveau de gris apparaît dans l'image et n est le nombre total de pixels dans l'image. Si le nombre de bits utilisés pour représenter chaque valeur rk est l(rk), alors le nombre moyen de bits requis pour exprimer chaque pixel est :
C'est-à-dire que chaque échelle de gris sera représentée. le nombre de bits utilisés dans la valeur de niveau est multiplié par la probabilité d'apparition du niveau de gris, et les produits résultants sont ajoutés pour obtenir la longueur moyenne du mot de code de différentes valeurs de niveau de gris. Si le nombre moyen de bits d'un certain codage est plus proche de l'entropie, la redondance du codage est plus petite.
【Remarque】
Entropie : Il définit la quantité moyenne d'informations obtenues en observant la sortie d'une seule source

Par exemple :
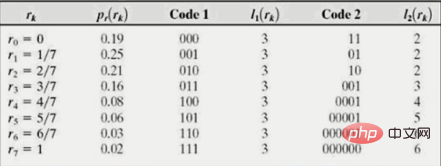
L'entropie de l'image originale est : 2,588
En utilisant l'encodage binaire naturel, la longueur moyenne est : 3
Si vous utilisez l'encodage 2 dans le tableau, le nombre moyen de bits est :

Pour réaliser la compression de l'encodage, les deux fonctions pr(r k) et l(rk) Multipliez le rapport inverse. En d'autres termes, plus la probabilité pr (rk) d'un certain niveau de gris rk est grande, plus la longueur de codage l (rk) doit être petite, ce qui peut réduire le nombre moyen de bits pour que proche de l'entropie. Comme indiqué ci-dessous :

3. La redondance inter-pixel
La redondance inter-pixel est une sorte de redondance des données qui est directement liée à la corrélation entre les pixels.
Pour une image statique, il existe une redondance spatiale (redondance géométrique) En effet, la contribution visuelle d'un seul pixel à l'image dans une image est souvent redondante, ce qui peut être déterminé à l'aide des valeurs en niveaux de gris de. ses pixels adjacents en déduisent.
Pour les images ou vidéos continues, il y aura également une redondance temporelle (redondance inter-images). La plupart des pixels correspondants entre images adjacentes sont lentement excessifs.

3. Redondance psychovisuelle
La redondance psychovisuelle est liée à des informations visuelles réelles. Elle varie d'une personne à l'autre pour une même photo. Supprimer les données psychovisuelles redondantes entraînera inévitablement la perte d’informations quantitatives, et cette perte d’informations visuelles est une opération irréversible. Tout comme une image (qui ne peut pas être agrandie) est relativement petite, l'œil humain ne peut pas juger directement sa résolution. Afin de compresser le volume de données de l'image, certaines informations qui ne peuvent pas être directement observées par l'œil humain peuvent être supprimées, mais. lorsqu'elle est agrandie, elle n'est pas supprimée. Une image avec redondance psychovisuelle sera significativement différente d'une image avec redondance psychovisuelle supprimée.

La figure C montre que le processus de quantification qui utilise pleinement les caractéristiques du système visuel humain peut améliorer considérablement les performances de l'image. Bien que le taux de compression de ce processus de quantification ne soit encore que de 2 : 1, une surcharge supplémentaire est ajoutée. pour réduire les faux contours, mais en réduisant la texture granuleuse gênante. La méthode utilisée pour produire ce résultat est la méthode de quantification améliorée de l'échelle de gris (IGS). Le tableau suivant illustre cette méthode. Tout d'abord, la valeur actuelle de l'échelle de gris de 8 bits et la 4. les bits de poids faible générés précédemment forment une somme avec une valeur initiale de zéro. Si les 4 bits de poids fort de la valeur actuelle sont 1111, ajoutez-y 0000. La valeur des 4 bits les plus significatifs de la somme obtenue est utilisée comme valeur de pixel codée.
4 Critère de fidélité
4.1 Critère de fidélité objectif
Quand le degré de perte d'informations peut être exprimé. Une fonction est dite basée sur des critères objectifs de fidélité lorsqu'elle est fonction d'une image initiale ou image d'entrée et d'une image de sortie qui est d'abord compressée puis décompressée.
-
Erreur quadratique moyenne (rms)
L'erreur globale des deux images :
Où, f(x,y) représente l'image d'entrée, f(x,y) représente la compression de l'image image d'entrée puis L'estimateur ou approximation décompressé
L'erreur quadratique moyenne des deux images
- Rapport signal/bruit carré moyen

FAQ !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- mpeg est la norme de codage de compression d'image et de codage audio pour le stockage numérique
- Parlons de la façon d'utiliser Node pour réaliser la compression de contenu grâce à la pratique
- Vous guidez étape par étape pour développer un outil de compression en ligne de commande à l'aide de node
- Quel est l'objectif principal de la compression des données d'image
- Quels sont les indicateurs importants pour mesurer les performances de la technologie de compression de données ?