
Maison >base de données >Redis >Explication graphique détaillée du cluster Redis et de son extension
Explication graphique détaillée du cluster Redis et de son extension

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-07-13 13:59:351956parcourir
Cet article vous apporte des connaissances pertinentes sur Redis. Il organise principalement les problèmes liés au clustering et à l'expansion. La manière habituelle d'obtenir une haute disponibilité est de copier plusieurs copies de la base de données à déployer sur différents serveurs, même si une machine est présente. en panne, il peut continuer à fournir des services. Il existe trois modes de déploiement pour atteindre une haute disponibilité : le mode maître-esclave, le mode sentinelle et le mode cluster. J'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo Redis
Haute disponibilité de Redis
1. Pourquoi la haute disponibilité
- Pour éviter des points de défaillance uniques et rendre l'ensemble du cluster indisponible
- La manière habituelle d'atteindre la haute disponibilité consiste à copier plusieurs copies de la base de données sur laquelle déployer. différents serveurs, où même si une machine est en panne, elle peut continuer à fournir des services
- Redis dispose de trois modes de déploiement pour atteindre une haute disponibilité : Mode maître-esclave, mode sentinelle et mode cluster
2. Maître-. mode esclave
- Le nœud maître est responsable de lecture et écriture Opération
- Le nœud esclaveest uniquement responsable delectureopération
- Les données du nœud esclave proviennent du nœud maître. Le principe de mise en œuvre est le mécanisme de réplication maître-esclave
- La réplication maître-esclave comprend la réplication complète et la réplication incrémentielledeux. Ce type de
-
Lorsque l'esclave commence à se connecter au maître pour la première fois, ou s'il est considérée comme la première connexion, elle utilise la réplication complète
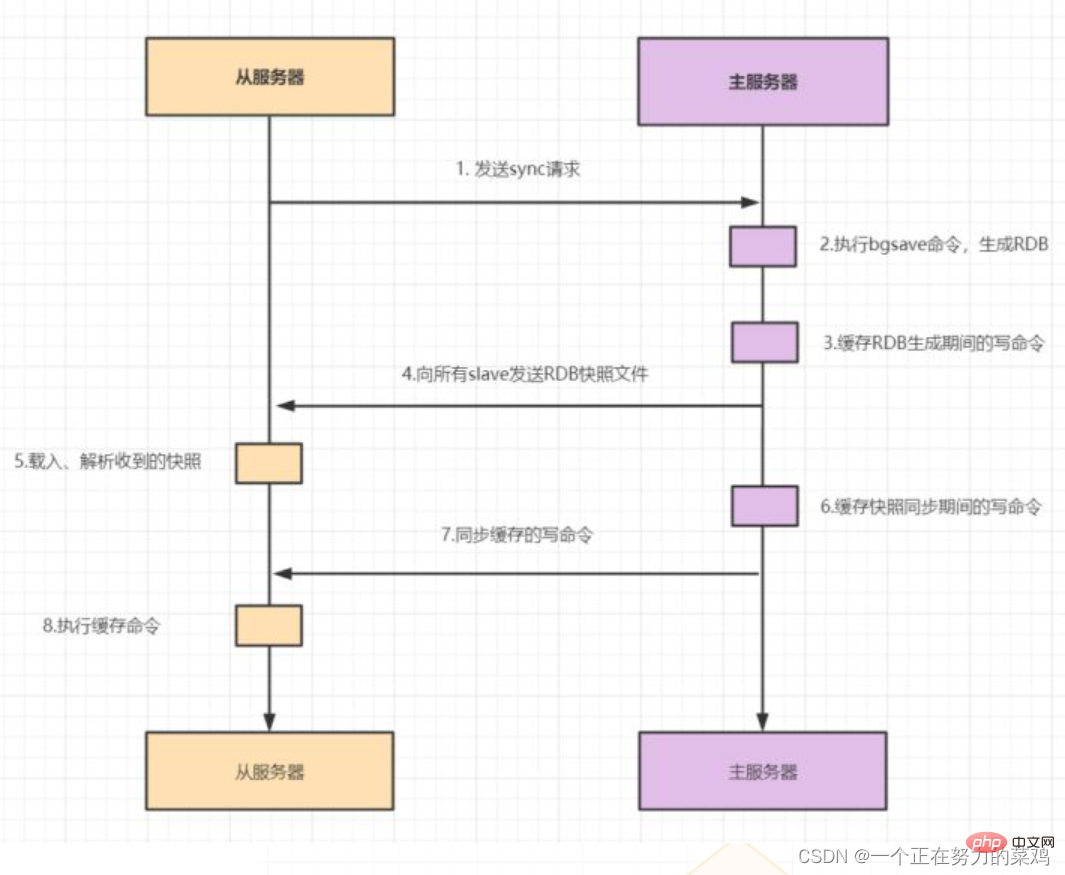
-
Une fois l'esclave entièrement synchronisé avec le maître, si les données sur le maître sont à nouveau mises à jour, cela déclenchera une augmentation du volume
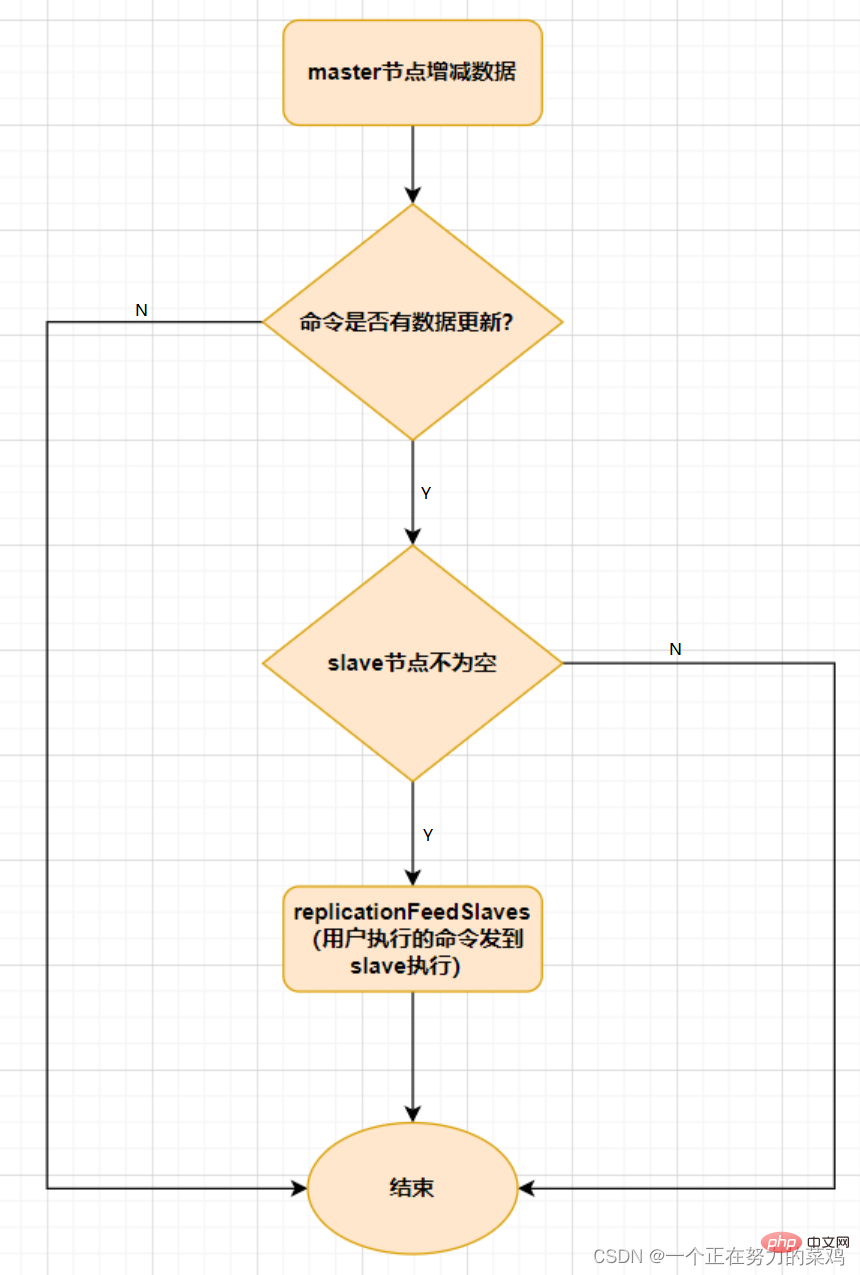 .
.
3. Mode Sentinelle
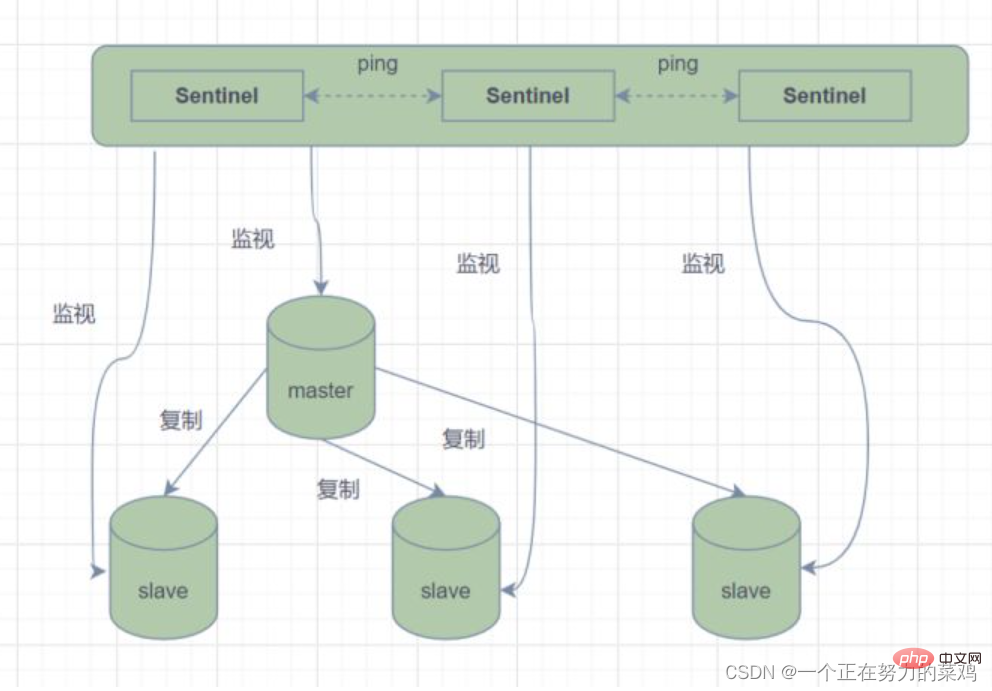
- En mode maître-esclave, une fois que le nœud maître ne peut pas fournir de services en raison d'une panne, il est nécessaire de promouvoir manuellement le nœud esclave au nœud maître, et en même temps, la partie applicative doit être notifié pour mettre à jour l'adresse du nœud maître. Évidemment, la plupart des scénarios commerciaux ne peuvent pas accepter cette méthode de gestion des erreurs. Redis a officiellement fourni l'architecture Redis Sentinel (Sentinel) depuis la version 2.8 pour résoudre ce problème. ou plusieurs instances Sentinel, qui peuvent être surveillées. Tous les nœuds maîtres et nœuds esclaves Redis , et lorsque le nœud maître
- surveillé entre dans l'état hors ligne, un nœud esclave sous le serveur maître hors ligne sera automatiquement mis à niveau vers un nouveau nœud maître . Cependant, un processus sentinelle Lorsque les nœuds Redis sont surveillés, des problèmes (points uniques) peuvent survenir, donc plusieurs sentinelles peuvent être utilisées pour surveiller les nœuds Redis, et chaque sentinelle sera également surveillée. En termes simples, le mode sentinelle a trois fonctions.
1.发送命令,等待Redis服务器(包括主服务器和从服务器)返回监控其运行状态 2.哨兵监测到主节点宕机会自动将从节点切换成主节点,然后通过发布订阅模式通知其他的从节点修改配置文件,让它们切换主机 3.哨兵之间还会相互监控,从而达到高可用
- Le processus de basculement est le suivant
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象称为主观下线 当后面的哨兵也检测到主服务器不可用并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作 切换成功后通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线 这样对于客户端而言,一切都是透明的
- Mode de fonctionnement de Sentinel
每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他Sentinel实例发送一个PING命令 如果实例距离最后一次有效回复PING命令的时间超过down-after-milliseconds选项所指定的值,则这个实例会被Sentinel标记为主观下线 如果一个Master被标记为主观下线,则正在监视这个Master的所有Sentinel要以每秒一次的频率确认Master的确进入了主观下线状态 当有足够数量的Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态,则Master会被标记为客观下线 一般情况下,每个Sentinel会以每10秒一次的频率向它已知的所有Master,Slave发送INFO命令 当Master被Sentinel标记为客观下线时,Sentinel向下线的Master的所有Slave发送INFO命令的频率会从10秒一次改为每秒一次 若没有足够数量的Sentinel同意Master已经下线,Master的客观下线状态就会被移除;若Master重新向Sentinel的PING命令返回有效回复,Master 的主观下线状态就会被移除
- 4. Mode cluster cluster
- Le partage des données, c'est-à-dire le stockage de contenus différents sur chaque nœud Redis, peut résoudre le problème de l'expansion en ligne et fournit également des fonctions de réplication et de basculement. , et les nœuds échangent en permanence des informations. Les informations échangées incluent
- l'échec du nœud, l'adhésion d'un nouveau nœud, les informations de changement de nœud maître-esclave, les informations sur les emplacements, etc. Les messages de potins couramment utilisés sont ping, pong, meet, fail
ping消息:集群内交换最频繁的消息,集群内每个节点每秒向多个其他节点发送ping消息,用于检测节点是否在线和交换彼此状态信息
meet消息:通知新节点加入,消息发送者通知接收者加入到当前集群,meet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong消息交换
pong消息:当接收到ping、meet消息时,作为响应消息回复给发送方确认消息正常通信;pong消息内部封装了自身状态数据,节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新
fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新为下线状态
- . Algorithme de slot Hash Slot
既然是分布式存储,Cluster集群使用的分布式算法是一致性Hash嘛?并不是,而是Hash Slot插槽算法 插槽算法把整个数据库被分为16384个slot(槽),每个进入Redis的键值对根据key进行散列,分配到这16384插槽中的一个 使用的哈希映射也比较简单,用CRC16算法计算出一个16位的值,再对16384取模,数据库中的每个键都属于这16384个槽的其中一个,集群中的每个节点都可以处理这16384个槽 集群中的每个节点负责一部分的hash槽,比如当前集群有A、B、C个节点,每个节点上的哈希槽数 =16384/3,那么就有: 节点A负责0~5460号哈希槽 节点B负责5461~10922号哈希槽 节点C负责10923~16383号哈希槽Redis Cluster集群中,需要确保16384个槽对应的node都正常工作,如果某个node出现故障,它负责的slot也会失效,整个集群将不能工作 为了保证高可用,Cluster集群引入了主从复制,一个主节点对应一个或者多个从节点,当其它主节点ping一个主节点A时,如果半数以上的主节点与 A通信超时,那么认为主节点A宕机,如果主节点宕机时,就会启用从节点Redis的每一个节点上都有两个玩意,一个是插槽slot(0~16383),另外一个是cluster,可以理解为一个集群管理的插件,当我们存取的key到达时,Redis会根据Hash Slot插槽算法取到编号在0~16383之间的哈希槽,通过这个值去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
- : Une fois la panne découverte, si le nœud hors ligne est le nœud maître, il doit être Choisissez l'un des nœuds à remplacez-le pour garantir la haute disponibilité du cluster
- 1 Redisson
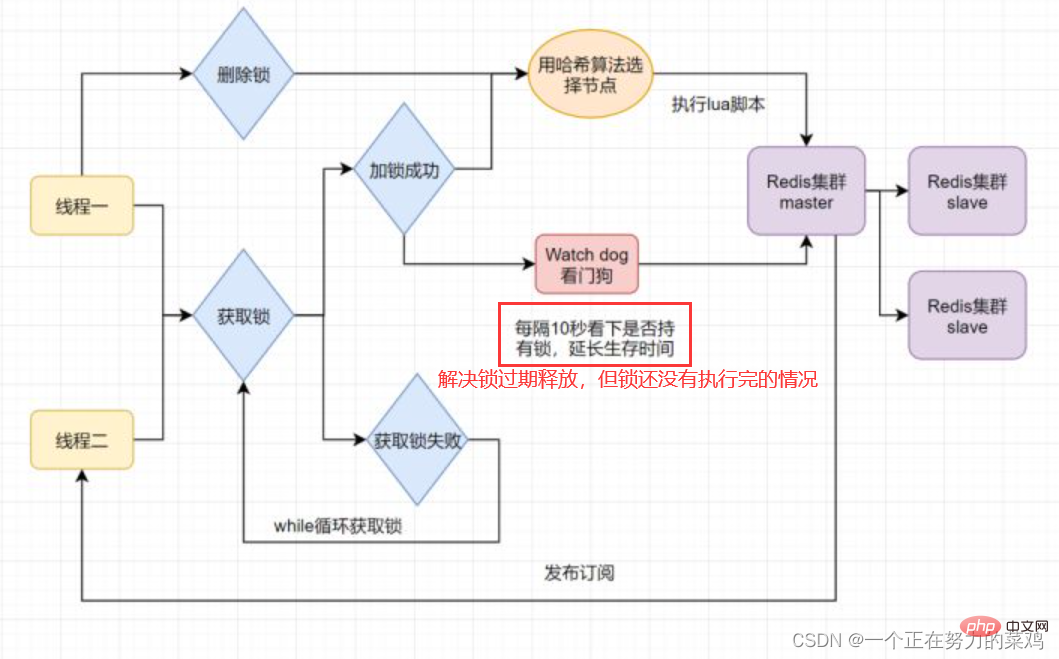
Des verrous distribués peuvent exister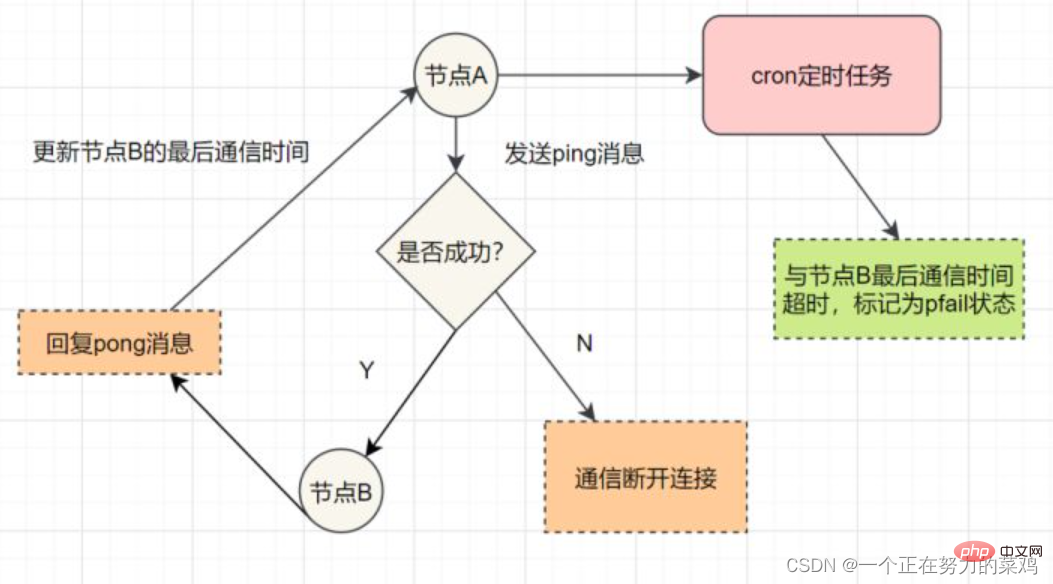 Le verrou a expiré et libéré, et l'entreprise est. n'est plus disponible Question après l'exécution
Le verrou a expiré et libéré, et l'entreprise est. n'est plus disponible Question après l'exécution -
Le délai d'expiration du verrou peut-il être réglé plus longtemps pour résoudre ce problème ? Évidemment, ce n'est pas bon. Le temps d'exécution de l'entreprise est incertain
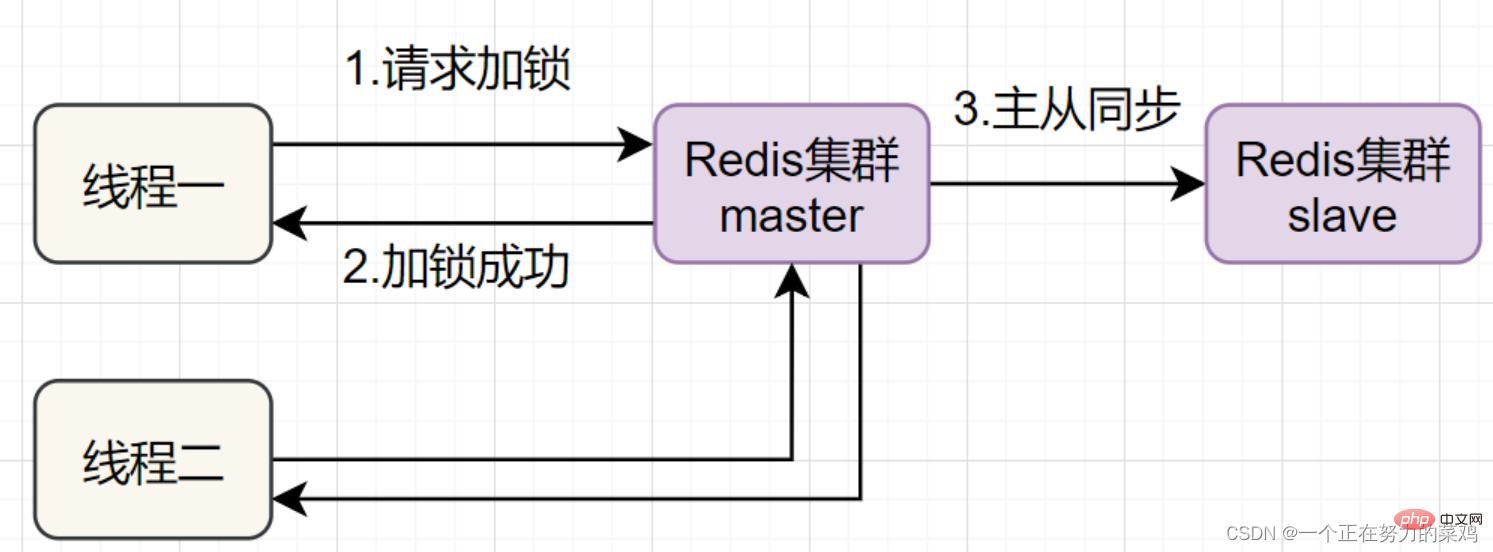
Redisson résout ce problème en ouvrant un thread démon temporisé pour le thread qui obtient le verrou de temps en temps. il prolonge le délai d'expiration du verrou pour éviter que le verrou n'expire et ne soit libéré plus tôt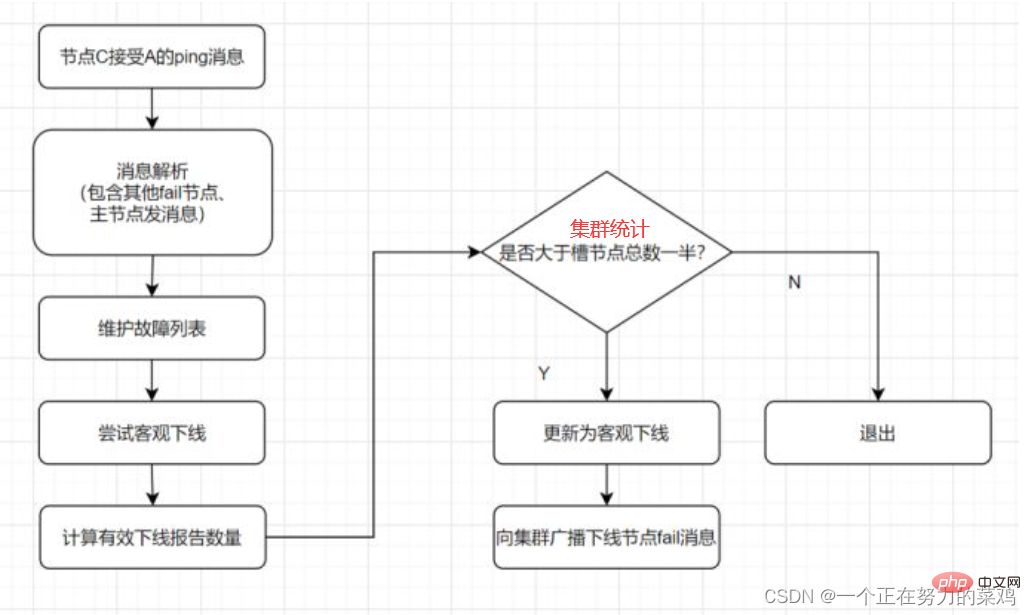
2. Algorithme Redlock
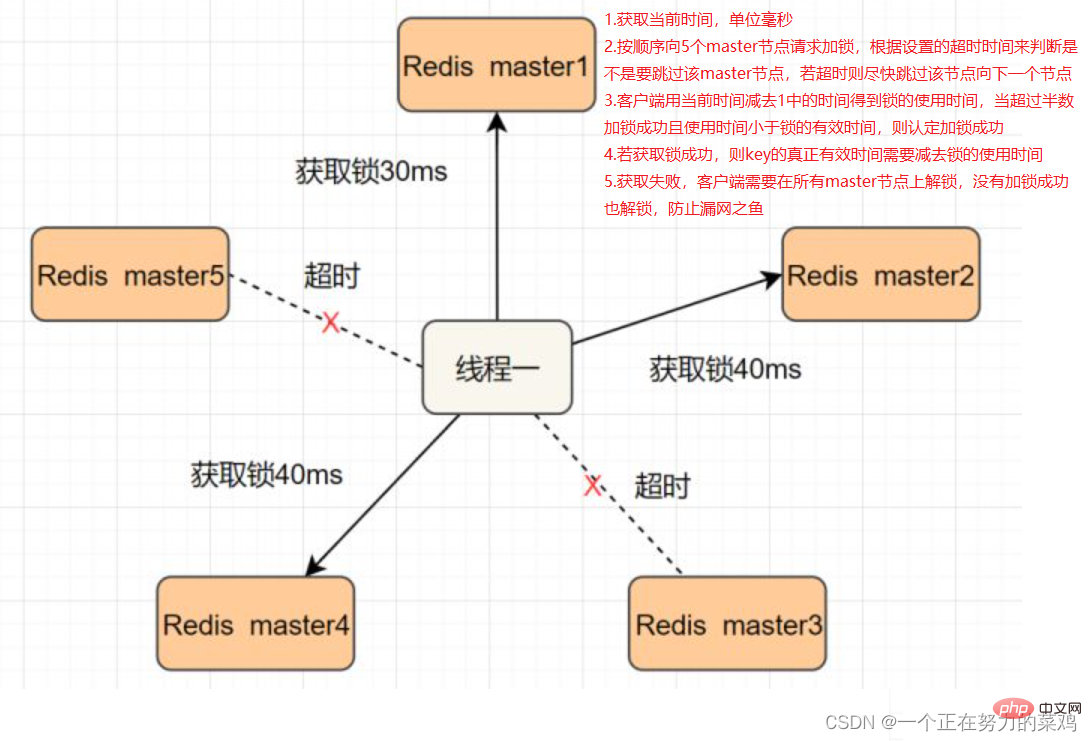
- Dès que le thread obtient le verrou sur le nœud maître Redis, mais que la clé verrouillée n'a pas été synchronisée avec le nœud esclave, juste à ce moment-là, le nœud maître échoue et un esclave le nœud sera mis à niveau vers Sur le nœud maître, le thread deux peut obtenir le verrou de la même clé, mais le thread un a également obtenu le verrou, et la sécurité du verrou a disparu
-
RedlockPour résoudre ce problème, déployez plusieurs maîtres Redis pour vous assurer qu'ils ne tomberont pas en panne en même temps, et ces nœuds maîtres sont complètement indépendants les uns des autres, et il n'y a pas de synchronisation des données entre eux Les étapes de mise en œuvre sont les suivantes
 .
.
- Après la mise à jour de la base de données, retardez la mise en veille pendant un moment, puis supprimez le cache
- Cette solution est correcte uniquement pendant la période de veille, il peut y avoir des données sales, et l'entreprise en général les acceptera également
- Mais si vous les supprimez pour la deuxième fois, qu'en est-il de l'échec du cache ? Les données dans le cache et dans la base de données peuvent toujours être incohérentes. Que diriez-vous de définir un délai d'expiration naturel pour la clé et de la laisser expirer automatiquement ? Que dois-je faire si les données acceptées par l'entreprise dans le délai d'expiration sont incohérentes ? Il existe encore d'autres meilleures solutions
-
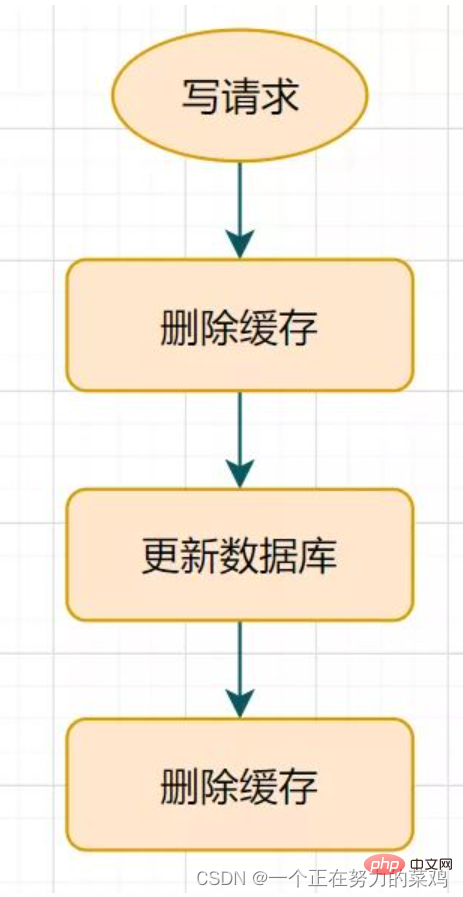 2. Mécanisme de nouvelle tentative de suppression du cache
2. Mécanisme de nouvelle tentative de suppression du cache
Une double suppression retardée peut entraîner l'échec de la deuxième étape de suppression du cache, entraînant des problèmes d'incohérence des données
- Si la suppression échoue, supprimez-la plusieurs fois. fois plus Oui, assurez-vous simplement que la suppression du cache est réussie, afin que vous puissiez introduire le
- mécanisme de nouvelle tentative de suppression du cache
-
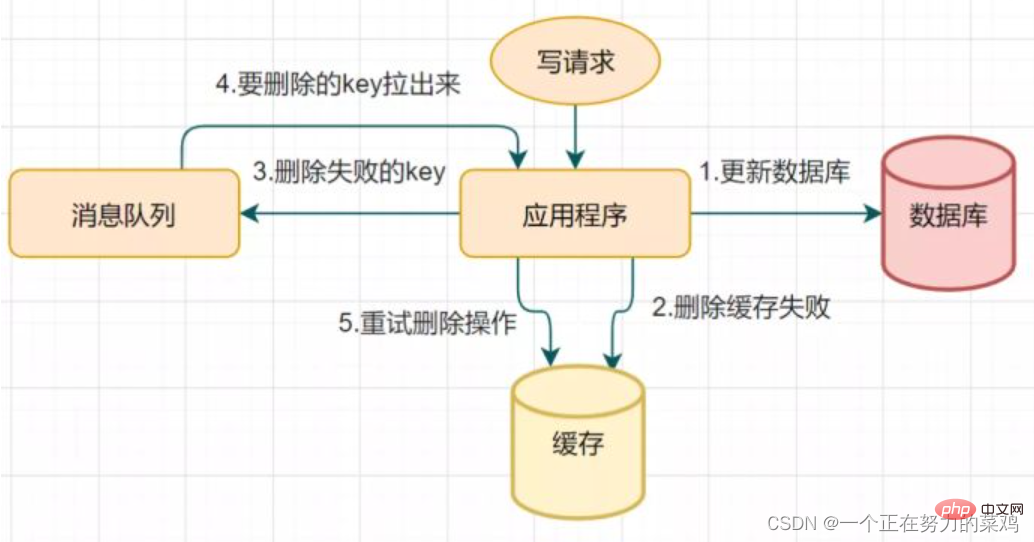 3 Lisez le biglog et supprimez le cache de manière asynchrone
3 Lisez le biglog et supprimez le cache de manière asynchrone
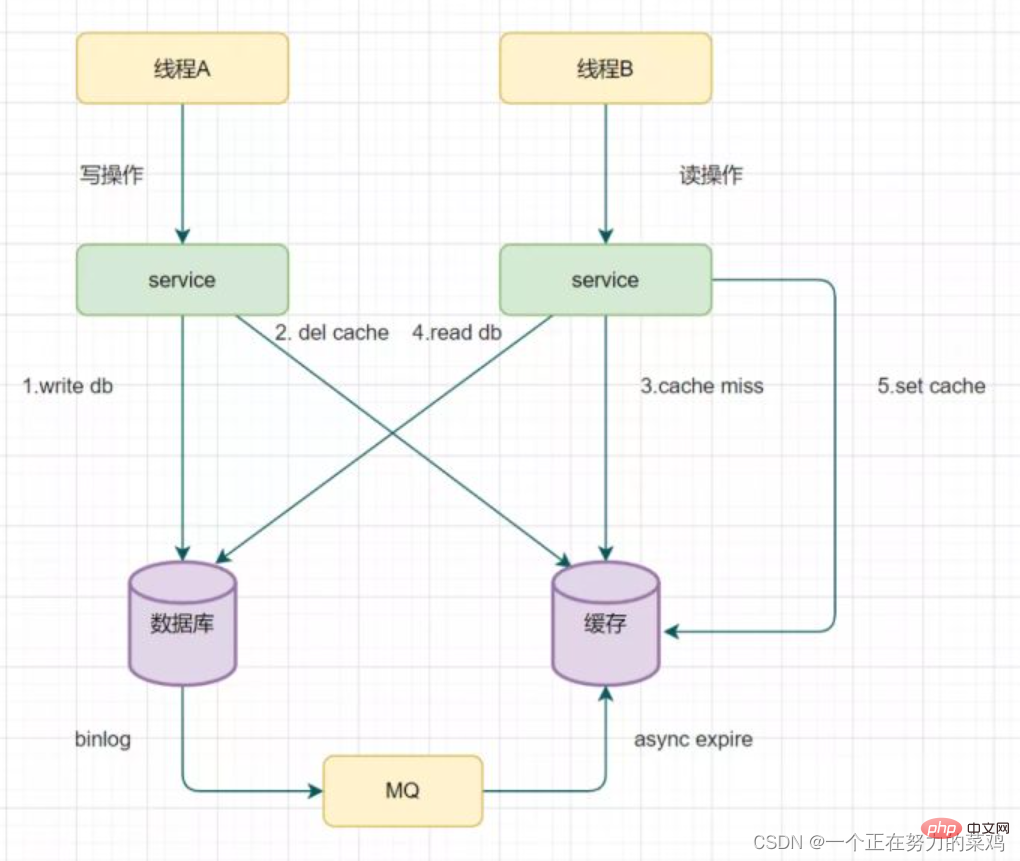
Le mécanisme de nouvelle tentative de suppression du cache provoquera une erreur. beaucoup d'intrusions dans le code métier, donc Présentation de la lecture du biglog et de la suppression asynchrone du cache
-
 Apprentissage recommandé : Tutoriel vidéo Redis
Apprentissage recommandé : Tutoriel vidéo Redis
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles sont les différences entre MySQL et Redis ?
- Maîtriser pleinement la persistance Redis : RDB et AOF
- Explication détaillée des exemples de fonctionnement du cluster Redis
- Résumer les points de connaissance de l'ensemble ordonné Redis zset
- Redis de la construction de l'environnement à une utilisation compétente (partage de résumé)