
Maison >base de données >Redis >Maîtriser pleinement la persistance Redis : RDB et AOF
Maîtriser pleinement la persistance Redis : RDB et AOF

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-06-16 12:10:462090parcourir
Cet article vous apporte des connaissances pertinentes sur Redis, qui présente principalement les problèmes liés à la persistance, notamment pourquoi la persistance est nécessaire, la persistance RDB, la persistance AOF, etc.

Apprentissage recommandé : Tutoriel vidéo Redis
1. Pourquoi la persévérance est-elle nécessaire ?
Redis exploite les données en fonction de la mémoire. En cas de situations inattendues telles qu'une sortie de processus et un temps d'arrêt du serveur, s'il n'y a pas de mécanisme de persistance, les données dans Redis seront perdues et ne pourront pas être récupérées. Grâce au mécanisme de persistance, Redis peut utiliser des fichiers précédemment persistants pour la récupération de données au prochain redémarrage. Deux mécanismes de persistance supportés par Redis :
RDB : génère un instantané des données actuelles et enregistre-le sur le disque dur.
AOF : Enregistrez chaque opération sur les données sur le disque dur.
2. Persistance RDB
écrit l'instantané de l'ensemble de données dans la mémoire sur le disque dans l'intervalle de temps spécifié. Lorsqu'il est restauré, le fichier d'instantané est lu directement dans la mémoire. La persistance RDB (Redis DataBase) consiste à générer un instantané de toutes les données actuelles dans Redis et à l'enregistrer sur le disque dur. La persistance RDB peut être déclenchée manuellement ou automatiquement.
1. Comment la sauvegarde est-elle effectuée ?
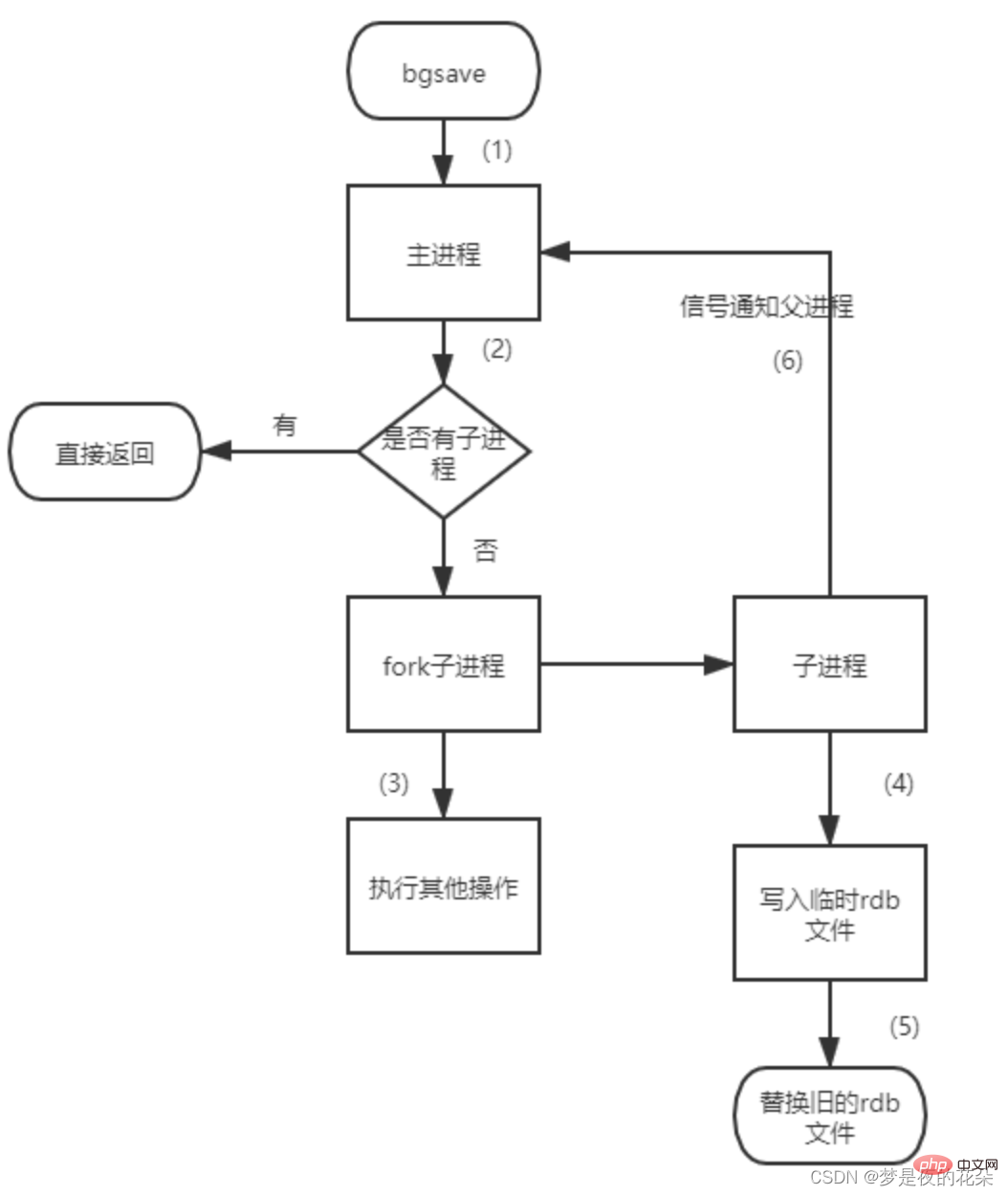
redis créera (fork) un sous-processus distinct pour la persistance. Il écrira d'abord les données dans un fichier temporaire une fois le processus de persistance terminé, ce fichier temporaire sera utilisé pour remplacer le dernier fichier persistant. Pendant tout le processus, le processus principal n'effectue aucune opération d'E/S, ce qui garantit des performances extrêmement élevées. Si une récupération de données à grande échelle est requise et que l'intégrité de la récupération des données n'est pas très sensible, alors la méthode RDB est plus efficace que la méthode AOF. L'inconvénient de RDB est que les dernières données persistantes peuvent être perdues.
2. Processus de persistance RDB
3. Déclenchement manuel
Les commandes save et bgsave peuvent déclencher manuellement la persistance RDB. save和 bgsave命令都可以手动触发RDB持久化。
-
save
执行save命令会手动触发RDB持久化,但是save命令会阻塞Redis服务,直到RDB持久化完成。当Redis服务储存大量数据时,会造成较长时间的阻塞,不建议使用。 -
bgsave
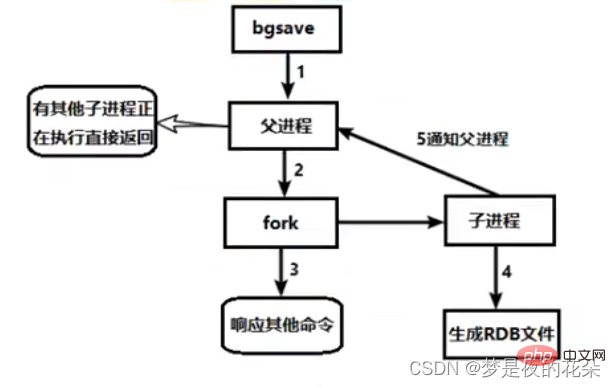
执行bgsave命令也会手动触发RDB持久化,和save命令不同是:Redis服务一般不会阻塞。Redis进程会执行fork操作创建子进程,RDB持久化由子进程负责,不会阻塞Redis服务进程。Redis服务的阻塞只发生在fork阶段,一般情况时间很短。bgsave命令的具体流程如下图:
1、执行bgsave命令,Redis进程先判断当前是否存在正在执行的RDB或AOF子线程,如果存在就是直接结束。
2、Redis进程执行fork操作创建子线程,在fork操作的过程中Redis进程会被阻塞。
3、Redis进程fork完成后,bgsave命令就结束了,自此Redis进程不会被阻塞,可以响应其他命令。
4、子进程根据Redis进程的内存生成快照文件,并替换原有的RDB文件。
5、同时发送信号给主进程,通知主进程rdb持久化完成,主进程更新相关的统计信息(info Persitence下的rdb_*相关选项)。
4、自动触发
除了执行以上命令手动触发以外,Redis内部可以自动触发RDB持久化。自动触发的RDB持久化都是采用bgsave的方式,减少Redis进程的阻塞。那么,在什么场景下会自动触发呢?
- 在配置文件中设置了
save的相关配置,如sava m n,它表示在m秒内数据被修改过n次时,自动触发bgsave操作。 - 当从节点做全量复制时,主节点会自动执行
bgsave操作,并且把生成的RDB文件发送给从节点。 - 执行
debug reload命令时,也会自动触发bgsave操作。 - 执行
shutdown命令时,如果没有开启AOF持久化也会自动触发bgsave
-
saveL'exécution de la commande
savedéclenchera manuellement la persistance RDB, mais la commandesavebloquera Redis Serve jusqu'à ce que la persistance RDB soit terminée. Lorsque le service Redis stocke une grande quantité de données, cela entraînera une congestion à long terme et n'est pas recommandé. - 🎜
bgsave🎜🎜 L'exécution de la commandebgsavedéclenchera également manuellement la persistance RDB. Différent de la commandesave: le service Redis en général. ne bloquera pas. Le processus Redis effectuera une opération fork pour créer un processus enfant. Le processus enfant est responsable de la persistance RDB et ne bloquera pas le processus du service Redis. Le blocage du service Redis n'intervient qu'en phase fork, et généralement le temps est très court. 🎜🎜bgsaveLe processus spécifique de la commande est le suivant : 🎜🎜🎜 1. Exécutez la commande bgsave. Le processus Redis détermine d'abord s'il existe actuellement un sous-thread RDB ou AOF en cours d'exécution. S'il existe, cela se terminera directement. 🎜 2. Le processus Redis effectue une opération fork pour créer un thread enfant. Le processus Redis sera bloqué pendant l'opération fork. 🎜 3. Une fois le fork du processus Redis terminé, la commandebgsavese termine. À partir de ce moment-là, le processus Redis ne sera pas bloqué et pourra répondre à d'autres commandes. 🎜 4. Le processus enfant génère un fichier instantané basé sur la mémoire du processus Redis et remplace le fichier RDB d'origine. 🎜 5. En même temps, envoyez un signal au processus principal pour l'informer que la persistance de rdb est terminée et que le processus principal met à jour les informations statistiques pertinentes (options liées à rdb_* sous info Persistance). 🎜🎜🎜4. Déclenchement automatique🎜🎜En plus du déclenchement manuel en exécutant la commande ci-dessus, la persistance RDB peut être automatiquement déclenchée dans Redis. La persistance RDB déclenchée automatiquement utilise la méthodebgsavepour réduire le blocage du processus Redis. Alors, dans quelles circonstances se déclenchera-t-il automatiquement ? 🎜- La configuration associée de
saveest définie dans le fichier de configuration, telle quesava m n, ce qui signifie que lorsque les données sont modifiées n fois en m secondes, Déclenche automatiquement l'opérationbgsave. 🎜 - Lorsque le nœud esclave effectue une réplication complète, le nœud maître effectuera automatiquement l'opération
bgsaveet enverra le fichier RDB généré au nœud esclave. 🎜 - Lors de l'exécution de la commande
debug reload, l'opérationbgsavesera également automatiquement déclenchée. 🎜 - Lors de l'exécution de la commande
shutdown, si la persistance AOF n'est pas activée, l'opérationbgsavesera automatiquement déclenchée. 🎜🎜🎜5. Avantages RDB🎜🎜Le fichier RDB est un fichier compressé binaire compact, qui est un instantané de toutes les données Redis à un moment donné. Par conséquent, la vitesse de récupération des données à l'aide de RDB est beaucoup plus rapide que celle d'AOF, ce qui est très approprié pour la sauvegarde, la réplication complète, la reprise après sinistre et d'autres scénarios. 🎜6. Inconvénients de RDB
Chaque fois que vous effectuez une opération
bgsave, vous devez effectuer une opération fork pour créer un enfant. C'est une opération lourde. Le coût d'une exécution fréquente est trop élevé. la persistance en temps réel ne peut pas être obtenue, ou au deuxième niveau.bgsave操作都要执行fork操作创建子经常,属于重量级操作,频繁执行成本过高,所以无法做到实时持久化,或者秒级持久化。另外,由于Redis版本的不断迭代,存在不同格式的RDB版本,有可能出现低版本的RDB格式无法兼容高版本RDB文件的问题。
7、dump.rdb中配置RDB
快照周期:内存快照虽然可以通过技术人员手动执行
De plus, en raison de l'itération continue des versions Redis, il existe des versions RDB dans différents formats, et il peut y avoir un problème selon lequel les formats RDB de version inférieure ne sont pas compatibles avec les fichiers RDB de version supérieure.SAVE或BGSAVE- 7. Configurez RDB dans dump.rdb Snapshot cycle
SAVEouBGSAVE, l'environnement de production Dans la plupart des cas, des conditions d’exécution périodiques seront fixées. 🎜🎜Nouveaux paramètres de cycle par défaut dans Redis🎜🎜🎜# 周期性执行条件的设置格式为 save <seconds> <changes> # 默认的设置为: save 900 1 save 300 10 save 60 10000 # 以下设置方式为关闭RDB快照功能 save ""</changes></seconds>
🎜La signification des trois paramètres d'informations par défaut ci-dessus est :🎜- 如果900秒内有1条Key信息发生变化,则进行快照;
- 如果300秒内有10条Key信息发生变化,则进行快照;
- 如果60秒内有10000条Key信息发生变化,则进行快照。读者可以按照这个规则,根据自己的实际请求压力进行设置调整。
- 其它相关配置
# 文件名称 dbfilename dump.rdb # 文件保存路径 dir ./ # 如果持久化出错,主进程是否停止写入 stop-writes-on-bgsave-error yes # 是否压缩 rdbcompression yes # 导入时是否检查 rdbchecksum yes
- dbfilename:RDB文件在磁盘上的名称。
- dir:RDB文件的存储路径。默认设置为“./”,也就是Redis服务的主目录。
- stop-writes-on-bgsave-error:上文提到的在快照进行过程中,主进程照样可以接受客户端的任何写操作的特性,是指在快照操作正常的情况下。如果快照操作出现异常(例如操作系统用户权限不够、磁盘空间写满等等)时,Redis就会禁止写操作。这个特性的主要目的是使运维人员在第一时间就发现Redis的运行错误,并进行解决。一些特定的场景下,您可能需要对这个特性进行配置,这时就可以调整这个参数项。该参数项默认情况下值为yes,如果要关闭这个特性,指定即使出现快照错误Redis一样允许写操作,则可以将该值更改为no。
- rdbcompression:该属性将在字符串类型的数据被快照到磁盘文件时,启用LZF压缩算法。Redis官方的建议是请保持该选项设置为yes,因为“it’s almost always a win”。
- rdbchecksum:从RDB快照功能的version 5 版本开始,一个64位的CRC冗余校验编码会被放置在RDB文件的末尾,以便对整个RDB文件的完整性进行验证。这个功能大概会多损失10%左右的性能,但获得了更高的数据可靠性。所以如果您的Redis服务需要追求极致的性能,就可以将这个选项设置为no。
8、 RDB 更深入理解
-
由于生产环境中我们为Redis开辟的内存区域都比较大(例如6GB),那么将内存中的数据同步到硬盘的过程可能就会持续比较长的时间,而实际情况是这段时间Redis服务一般都会收到数据写操作请求。那么如何保证数据一致性呢?
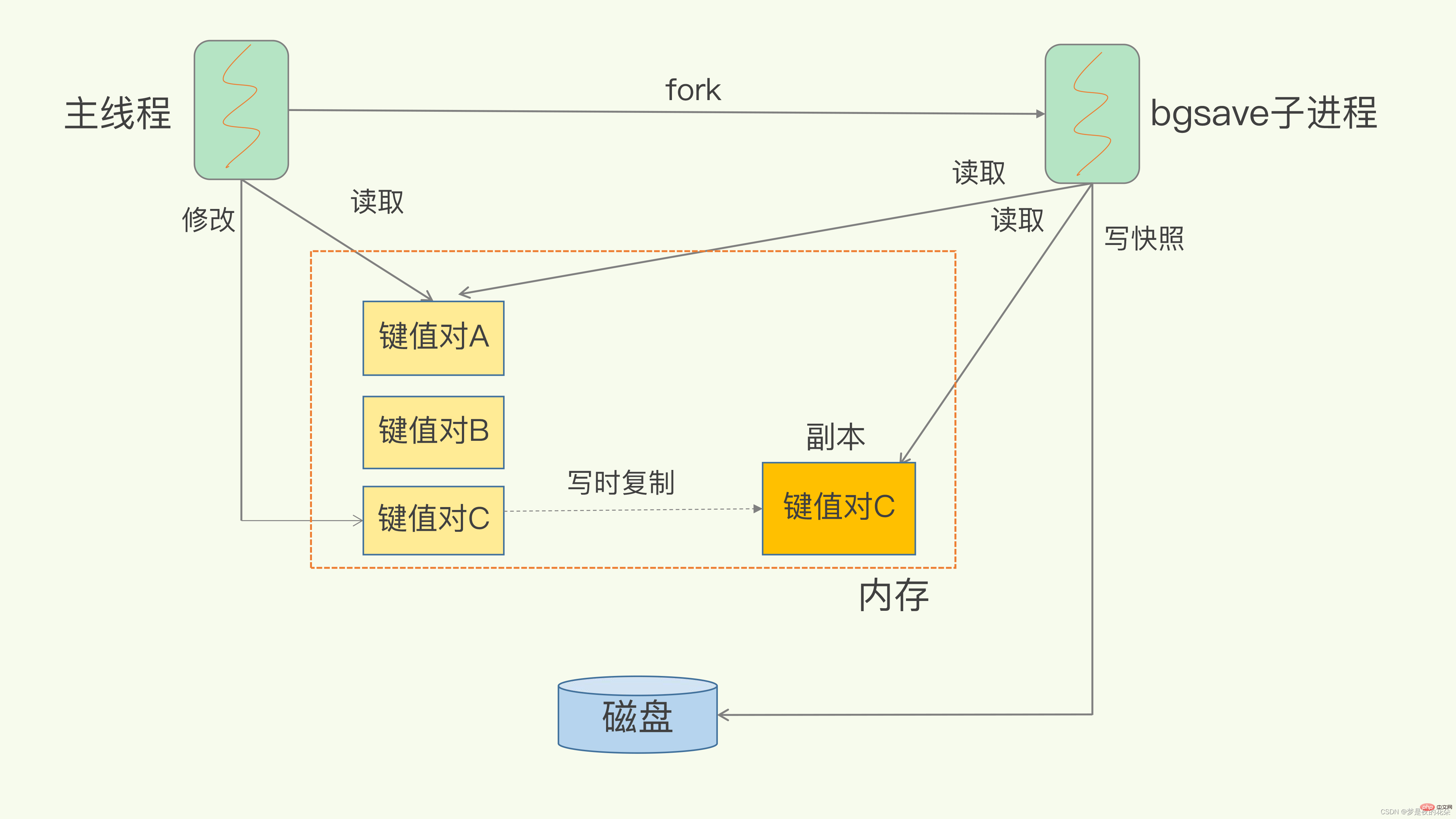
RDB中的核心思路是Copy-on-Write,来保证在进行快照操作的这段时间,需要压缩写入磁盘上的数据在内存中不会发生变化。在正常的快照操作中,一方面Redis主进程会fork一个新的快照进程专门来做这个事情,这样保证了Redis服务不会停止对客户端包括写请求在内的任何响应。另一方面这段时间发生的数据变化会以副本的方式存放在另一个新的内存区域,待快照操作结束后才会同步到原来的内存区域。
举个例子:如果主线程对这些数据也都是读操作(例如图中的键值对 A),那么,主线程和bgsave子进程相互不影响。但是,如果主线程要修改一块数据(例如图中的键值对 C),那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
-
在进行快照操作的这段时间,如果发生服务崩溃怎么办?
很简单,在没有将数据全部写入到磁盘前,这次快照操作都不算成功。如果出现了服务崩溃的情况,将以上一次完整的RDB快照文件作为恢复内存数据的参考。也就是说,在快照操作过程中不能影响上一次的备份数据。Redis服务会在磁盘上创建一个临时文件进行数据操作,待操作成功后才会用这个临时文件替换掉上一次的备份。 -
可以每秒做一次快照吗?
对于快照来说,所谓“连拍”就是指连续地做快照。这样一来,快照的间隔时间变得很短,即使某一时刻发生宕机了,因为上一时刻快照刚执行,丢失的数据也不会太多。但是,这其中的快照间隔时间就很关键了。
如下图所示,我们先在 T0 时刻做了一次快照,然后又在 T0+t 时刻做了一次快照,在这期间,数据块 5 和 9 被修改了。如果在 t 这段时间内,机器宕机了,那么,只能按照 T0 时刻的快照进行恢复。此时,数据块 5 和 9 的修改值因为没有快照记录,就无法恢复了。
针对RDB不适合实时持久化的问题,Redis提供了AOF持久化方式来解决
三、AOF持久化
AOF(Append Only File)持久化是把每次写命令追加写入日志中,当需要恢复数据时重新执行AOF文件中的命令就可以了。AOF解决了数据持久化的实时性,也是目前主流的Redis持久化方式。
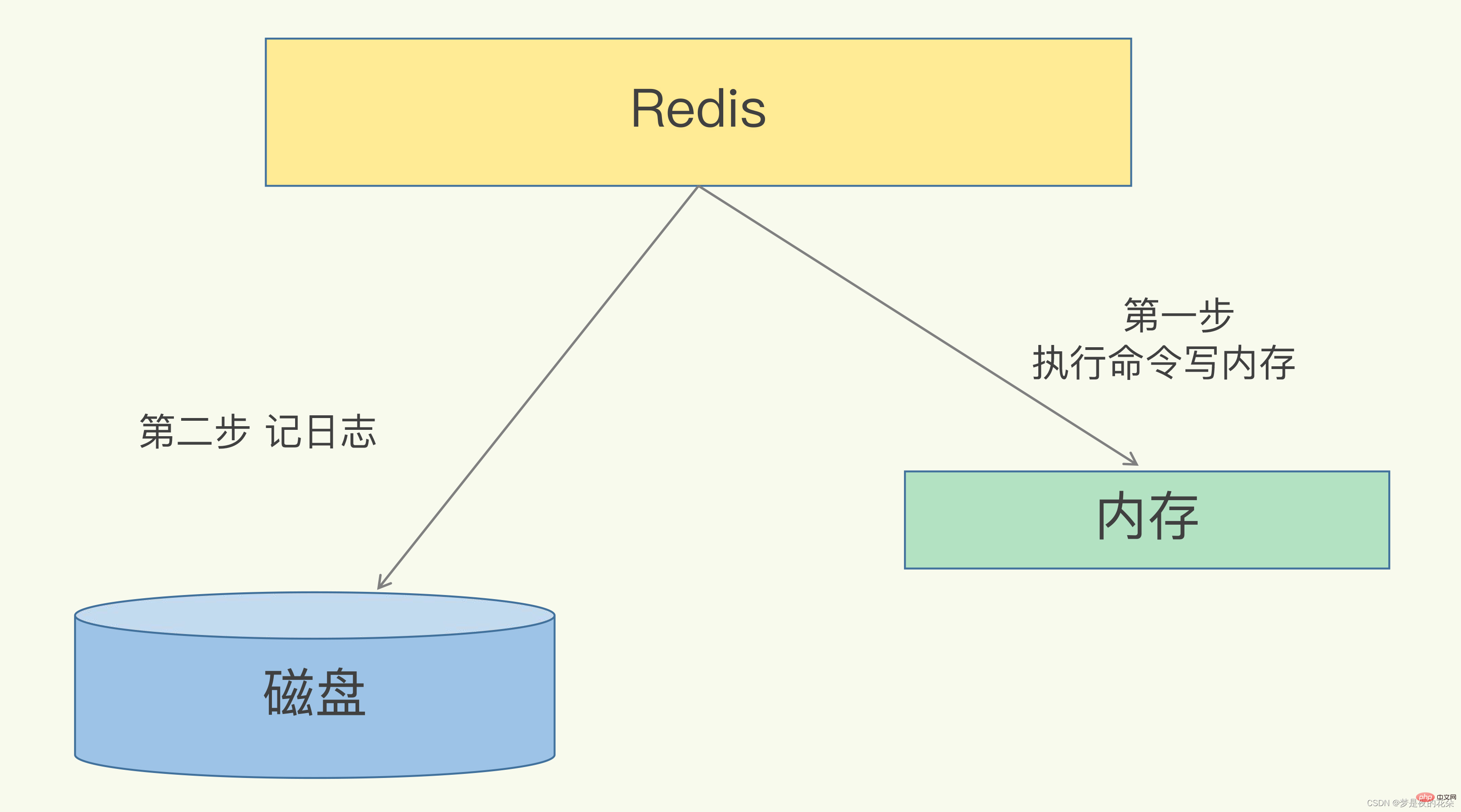
Redis是“写后”日志,Redis先执行命令,把数据写入内存,然后才记录日志。日志里记录的是Redis收到的每一条命令,这些命令是以文本形式保存。PS: 大多数的数据库采用的是写前日志(WAL),例如MySQL,通过写前日志和两阶段提交,实现数据和逻辑的一致性。
而AOF日志采用写后日志,即先写内存,后写日志。
为什么采用写后日志?
Redis要求高性能,采用写日志有两方面好处:- 避免额外的检查开销:Redis 在向 AOF 里面记录日志的时候,并不会先去对这些命令进行语法检查。所以,如果先记日志再执行命令的话,日志中就有可能记录了错误的命令,Redis 在使用日志恢复数据时,就可能会出错。
- 不会阻塞当前的写操作
但这种方式存在潜在风险:
- 如果命令执行完成,写日志之前宕机了,会丢失数据。
- 主线程写磁盘压力大,导致写盘慢,阻塞后续操作。
1、如何实现AOF?
AOF日志记录Redis的每个写命令,步骤分为:命令追加(append)、文件写入(write)和文件同步(sync)。
- 命令追加 当AOF持久化功能打开了,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器的 aof_buf 缓冲区。
-
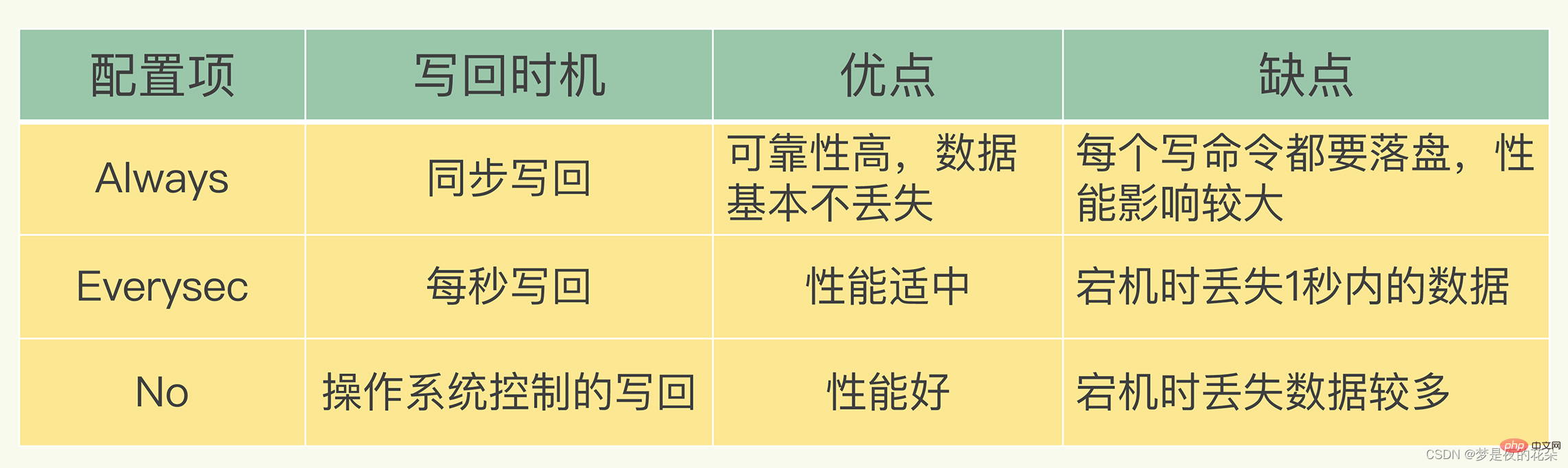
文件写入和同步 关于何时将 aof_buf 缓冲区的内容写入AOF文件中,Redis提供了三种写回策略:
- Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
- Everysec,每秒写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
- No,操作系统控制的写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
2、redis.conf中配置AOF
默认情况下,Redis是没有开启AOF的,可以通过配置redis.conf文件来开启AOF持久化,关于AOF的配置如下:
# appendonly参数开启AOF持久化 appendonly no # AOF持久化的文件名,默认是appendonly.aof appendfilename "appendonly.aof" # AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的 dir ./ # 同步策略 # appendfsync always appendfsync everysec # appendfsync no # aof重写期间是否同步 no-appendfsync-on-rewrite no # 重写触发配置 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb # 加载aof出错如何处理 aof-load-truncated yes # 文件重写策略 aof-rewrite-incremental-fsync yes
以下是Redis中关于AOF的主要配置信息:
appendfsync:这个参数项是AOF功能最重要的设置项之一,主要用于设置“真正执行”操作命令向AOF文件中同步的策略。什么叫“真正执行”呢?还记得Linux操作系统对磁盘设备的操作方式吗? 为了保证操作系统中I/O队列的操作效率,应用程序提交的I/O操作请求一般是被放置在linux Page Cache中的,然后再由Linux操作系统中的策略自行决定正在写到磁盘上的时机。而Redis中有一个fsync()函数,可以将Page Cache中待写的数据真正写入到物理设备上,而缺点是频繁调用这个fsync()函数干预操作系统的既定策略,可能导致I/O卡顿的现象频繁 。
与上节对应,appendfsync参数项可以设置三个值,分别是:always、everysec、no,默认的值为everysec。
no-appendfsync-on-rewrite:always和everysec的设置会使真正的I/O操作高频度的出现,甚至会出现长时间的卡顿情况,这个问题出现在操作系统层面上,所有靠工作在操作系统之上的Redis是没法解决的。为了尽量缓解这个情况,Redis提供了这个设置项,保证在完成fsync函数调用时,不会将这段时间内发生的命令操作放入操作系统的Page Cache(这段时间Redis还在接受客户端的各种写操作命令)。
auto-aof-rewrite-percentage : Comme mentionné ci-dessus, dans un environnement de production, il est impossible pour les techniciens d'utiliser la commande "
BGREWRITEAOF" pour réécrire les fichiers AOF à tout moment et n'importe où. Nous devons donc plus souvent nous appuyer sur la stratégie de réécriture automatique des fichiers AOF dans Redis. Redis propose deux paramètres pour déclencher la réécriture automatique des fichiers AOF :BGREWRITEAOF”命令去重写AOF文件。所以更多时候我们需要依靠Redis中对AOF文件的自动重写策略。Redis中对触发自动重写AOF文件的操作提供了两个设置:
auto-aof-rewrite-percentage表示如果当前AOF文件的大小超过了上次重写后AOF文件的百分之多少后,就再次开始重写AOF文件。例如该参数值的默认设置值为100,意思就是如果AOF文件的大小超过上次AOF文件重写后的1倍,就启动重写操作。
auto-aof-rewrite-min-size:设置项表示启动AOF文件重写操作的AOF文件最小大小。如果AOF文件大小低于这个值,则不会触发重写操作。注意,auto-aof-rewrite-percentage和auto-aof-rewrite-min-size只是用来控制Redis中自动对AOF文件进行重写的情况,如果是技术人员手动调用“BGREWRITEAOFauto-aof-rewrite-percentage
indique si la taille du fichier AOF actuel dépasse le pourcentage du fichier AOF après la dernière réécriture. Après cela, commencez à réécrire le fichier AOF. Fichier AOF à nouveau. Par exemple, la valeur par défaut de ce paramètre est 100, ce qui signifie que si la taille du fichier AOF dépasse 1 fois la taille de la dernière réécriture du fichier AOF, l'opération de réécriture sera lancée.
auto-aof-rewrite-min-size: L'élément de paramètre indique la taille minimale du fichier AOF pour démarrer l'opération de réécriture du fichier AOF. Si la taille du fichier AOF est inférieure à cette valeur, l'opération de réécriture ne sera pas déclenchée. Notez que auto-aof-rewrite-percentage et auto-aof-rewrite-min-size ne sont utilisés que pour contrôler la réécriture automatique des fichiers AOF dans Redis si un technicien appelle manuellement la commande "
BGREWRITEAOF". pas soumis à ces deux restrictions. 3. Compréhension approfondie de la réécriture AOFAOF enregistrera chaque commande d'écriture dans le fichier AOF au fil du temps, le fichier AOF deviendra de plus en plus gros. S'il n'est pas contrôlé, cela affectera le serveur Redis et même le système d'exploitation. De plus, plus le fichier AOF est volumineux, plus la récupération des données sera lente. Afin de résoudre le problème de l'expansion de la taille des fichiers AOF, Redis fournit un mécanisme de réécriture de fichiers AOF pour « alléger » les fichiers AOF.
Illustration expliquant la réécriture d'AOFLa réécriture d'AOF bloquera-t-elle ?
Le processus de réécriture AOF est complété par le processus en arrière-plan bgrewriteaof. Le thread principal quitte le processus enfant bgrewriteaof en arrière-plan. Le fork copiera la mémoire du thread principal vers le processus enfant bgrewriteaof, qui contient les dernières données de la base de données. Ensuite, le sous-processus bgrewriteaof peut écrire les données copiées dans les opérations une par une et les enregistrer dans le journal de réécriture sans affecter le thread principal. Par conséquent, lorsque aof est réécrit, il bloquera le thread principal lors du fork du processus.
Quand le journal AOF sera-t-il réécrit ?Il existe deux éléments de configuration pour contrôler le déclenchement de la réécriture AOF : auto-aof-rewrite-min-size : Indique la taille minimale du fichier lors de l'exécution de la réécriture AOF, la valeur par défaut est de 64 Mo.
auto-aof-rewrite-percentage: Cette valeur est calculée comme la différence entre la taille actuelle du fichier aof et la taille du fichier aof après la dernière réécriture, divisée par la taille du fichier aof après la dernière réécriture. C'est-à-dire la taille incrémentielle du fichier AOF actuel par rapport au dernier fichier AOF réécrit et le rapport de la taille du fichier AOF après la dernière réécriture.
Que se passe-t-il lorsque de nouvelles données sont écrites lors de la réécriture du journal ? Le processus de réécriture peut se résumer ainsi : "Une copie, deux logs". Lors de la sortie du processus enfant et lors de la réécriture, si de nouvelles données sont écrites, le thread principal enregistrera la commande dans deux tampons de mémoire de journal. Si la politique de réécriture AOF est configurée sur toujours, la commande sera réécrite directement dans l'ancien fichier journal et une copie de la commande sera enregistrée dans le tampon de réécriture AOF. Ces opérations n'auront aucun impact sur le nouveau fichier journal. (Ancien fichier journal : le fichier journal utilisé par le thread principal, nouveau fichier journal : le fichier journal utilisé par le processus bgrewriteaof)
Une fois que le processus enfant bgrewriteaof a terminé l'opération de réécriture du fichier journal, il demandera que le thread principal a terminé l'opération de réécriture, le thread principal ajoutera les commandes dans le tampon de réécriture AOF à la fin du nouveau fichier journal. À l'heure actuelle, dans des conditions de concurrence élevée, l'accumulation de tampon de réécriture AOF peut être très importante, ce qui entraînera un blocage. Redis a ensuite utilisé la technologie de pipeline Linux pour permettre la lecture simultanée pendant la réécriture AOF, de sorte qu'une fois la réécriture AOF terminée, seul A. une petite quantité de données restantes doit être lue. Enfin, en modifiant le nom du fichier, l'atomicité du changement de fichier est assurée.- Si un temps d'arrêt se produit lors de la réécriture du journal AOF, parce que le fichier journal n'a pas été modifié, l'ancien fichier journal sera toujours utilisé lors de la restauration des données.
- Opération récapitulative :
Le thread principal exécute le processus enfant pour réécrire le journal aof
Une fois que le processus enfant a réécrit le journal, le thread principal ajoute le tampon du journal aofRemplacez le fichier journal🎜 🎜🎜🎜Rappel chaleureux🎜 🎜🎜🎜Les concepts de processus et de threads ici sont un peu déroutants. Parce que le processus d'arrière-plan bgreweiteaof n'a qu'un seul thread opérationnel et que le thread principal est le processus opérationnel Redis, qui est également un seul thread. Ce que je veux exprimer ici, c'est qu'une fois que le processus principal Redis a créé un processus en arrière-plan, les opérations du processus en arrière-plan n'ont aucun lien avec le processus principal et ne bloqueront pas le thread principal🎜
Comment le thread principal récupère-t-il le processus enfant et copie-t-il les données de la mémoire ?
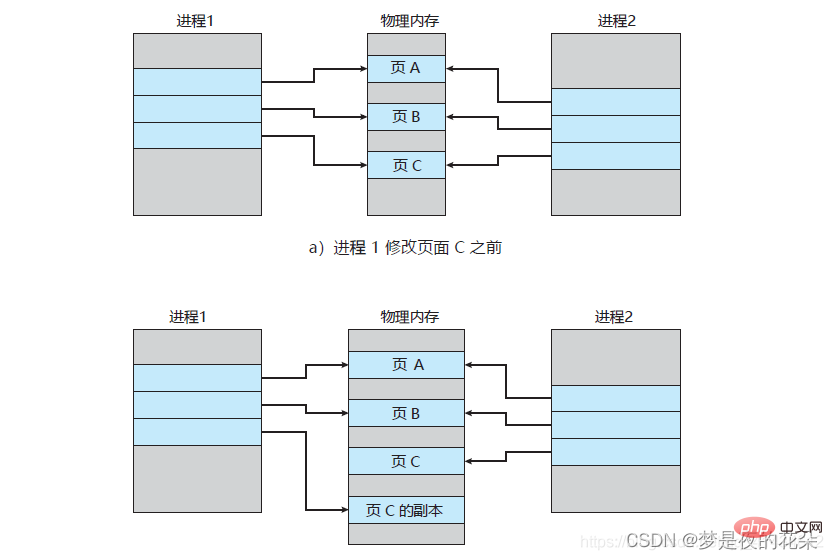
Fork utilise le mécanisme de copie en écriture fourni par le système d'exploitation pour éviter de copier une grande quantité de données mémoire à la fois et de bloquer le processus enfant. Lors du fork d'un processus enfant, le processus enfant copiera la table des pages du processus parent, c'est-à-dire la relation de mappage virtuel et réel (la table d'index de mappage entre la mémoire virtuelle et la mémoire physique), mais ne copiera pas la mémoire physique. Cette copie consommera beaucoup de ressources CPU et le thread principal sera bloqué avant la fin de la copie. Le temps de blocage dépend de la quantité de données dans la mémoire. Plus la quantité de données est grande, plus la table des pages mémoire est grande. Une fois la copie terminée, les processus parent et enfant utilisent le même espace d'adressage mémoire.Mais le processus principal peut écrire des données, et à ce moment les données dans la mémoire physique seront copiées. Comme indiqué ci-dessous (le processus 1 est considéré comme le processus principal, le processus 2 est considéré comme le processus enfant) :
Lorsque des données sont écrites sur le processus principal et que ces données se trouvent dans la page c, le système d'exploitation créera un copie de cette page ( Une copie de la page c), c'est-à-dire copie les données physiques de la page actuelle et les mappe au processus principal, tandis que le processus enfant utilise toujours la page d'origine c.Pendant tout le processus de réécriture du journal, où le fil principal sera-t-il bloqué ?
- Lors du fork d'un processus enfant, la table des pages virtuelles doit être copiée, ce qui bloquera le thread principal.
- Lorsque le processus principal écrit bigkey, le système d'exploitation créera une copie de la page et copiera les données originales, ce qui bloquera le thread principal.
- Une fois le journal de réécriture du sous-processus terminé, le thread principal peut être bloqué lorsque le processus principal ajoute le tampon de réécriture aof.
Pourquoi la réécriture AOF ne réutilise-t-elle pas le log AOF original ?
- L'écriture du même fichier entre les processus parent et enfant entraînera des problèmes de concurrence et affectera les performances du processus parent.
- Si le processus de réécriture AOF échoue, cela équivaut à contaminer le fichier AOF d'origine et ne peut pas être utilisé pour la récupération de données.
3. Méthode hybride RDB et AOF (version 4.0)
Redis 4.0 propose une méthode d'utilisation mixte des logs AOF et des instantanés mémoire. En termes simples, les instantanés de mémoire sont exécutés à une certaine fréquence, et entre deux instantanés, les journaux AOF sont utilisés pour enregistrer toutes les opérations de commande pendant cette période.
De cette façon, les instantanés n'ont pas besoin d'être exécutés très fréquemment, ce qui évite l'impact de forks fréquents sur le thread principal. De plus, le journal AOF enregistre uniquement les opérations entre deux instantanés, ce qui signifie qu'il n'est pas nécessaire d'enregistrer toutes les opérations. Par conséquent, le fichier ne sera pas trop volumineux et la surcharge de réécriture peut être évitée.
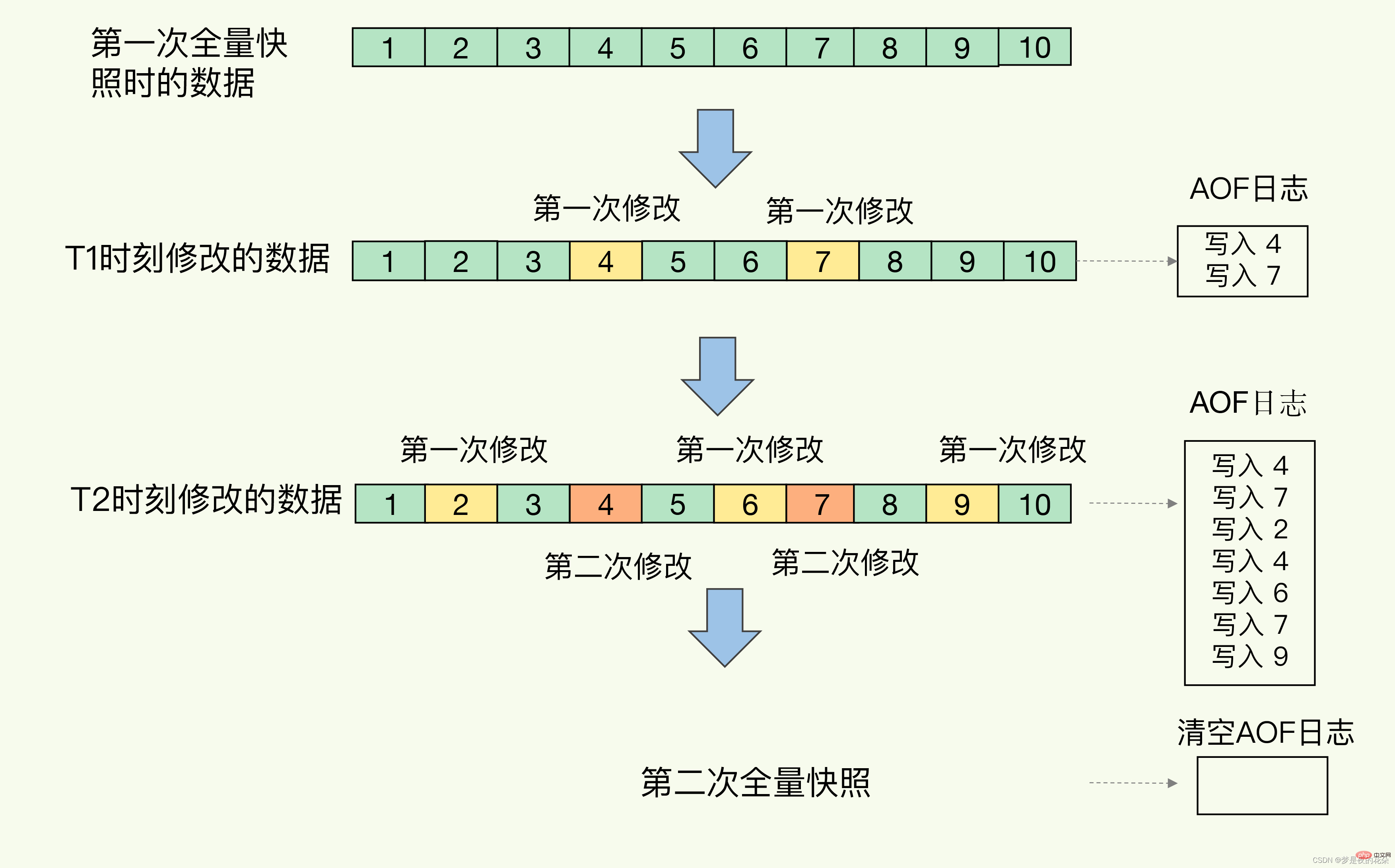
Comme le montre la figure ci-dessous, les modifications à T1 et T2 sont enregistrées dans le journal AOF Lorsque l'instantané complet est pris pour la deuxième fois, le journal AOF peut être effacé, car les modifications à ce moment ont été enregistrées dans. l'instantané, et ils seront supprimés lors de la récupération. Plus de journaux.
Cette méthode peut non seulement bénéficier des avantages d'une récupération rapide des fichiers RDB, mais également du simple avantage de l'enregistrement uniquement des commandes d'opération AOF. Elle est largement utilisée dans les environnements réels.4. Récupérer les données de la persistance
Maintenant que la sauvegarde et la persistance des données sont terminées, comment pouvons-nous récupérer les données de ces fichiers persistants ? S'il y a à la fois des fichiers RDB et des fichiers AOF sur un serveur, lequel doit être chargé ?
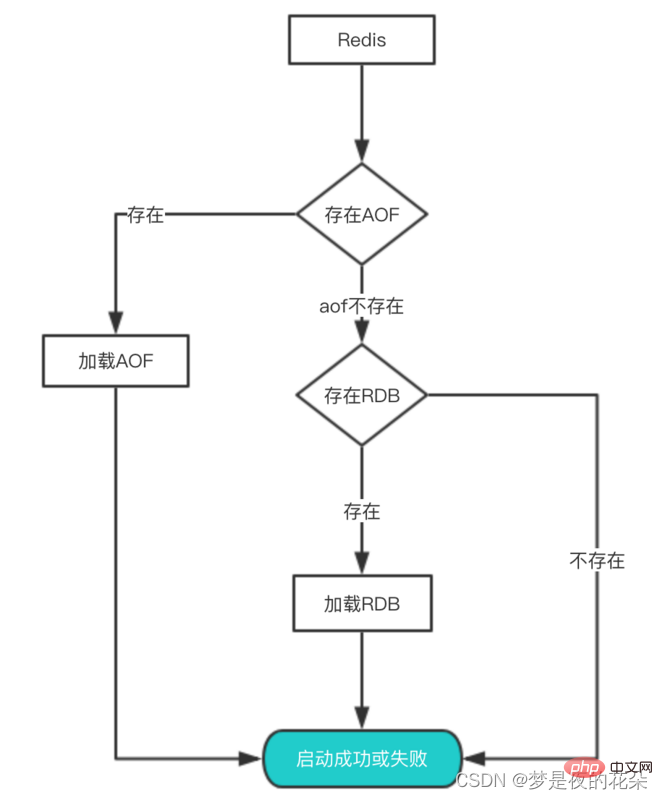
En fait, si vous souhaitez récupérer les données de ces fichiers, il vous suffit de redémarrer Redis. Nous comprenons toujours ce processus à travers le diagramme :
- Lorsque Redis redémarre, il est jugé s'il faut activer aof. Si aof est activé, alors le fichier aof sera chargé en premier.
- Si aof existe, alors le fichier aof. sera chargé. Si le chargement réussit, Redis redémarre avec succès. Si le fichier aof ne se charge pas, un journal sera imprimé pour indiquer que le démarrage a échoué. À ce moment, vous pouvez réparer le fichier aof et redémarrer
- Si. le fichier aof n'existe pas, alors redis chargera le fichier rdb à la place. Si rdb Le fichier n'existe pas, et redis démarre directement avec succès
- Si le fichier rdb existe, le fichier rdb sera chargé pour restaurer les données ; le chargement échoue, un journal sera imprimé pour indiquer que le démarrage a échoué, alors redis redémarre avec succès et le fichier rdb est utilisé pour restaurer les données
Alors pourquoi AOF est-il chargé en premier ? Étant donné que les données enregistrées par AOF sont plus complètes, grâce à l'analyse ci-dessus, nous savons qu'AOF perd jusqu'à 1 seconde de données.
Apprentissage recommandé : Tutoriel vidéo Redis
- La configuration associée de
 🎜 1. Exécutez la commande
🎜 1. Exécutez la commande 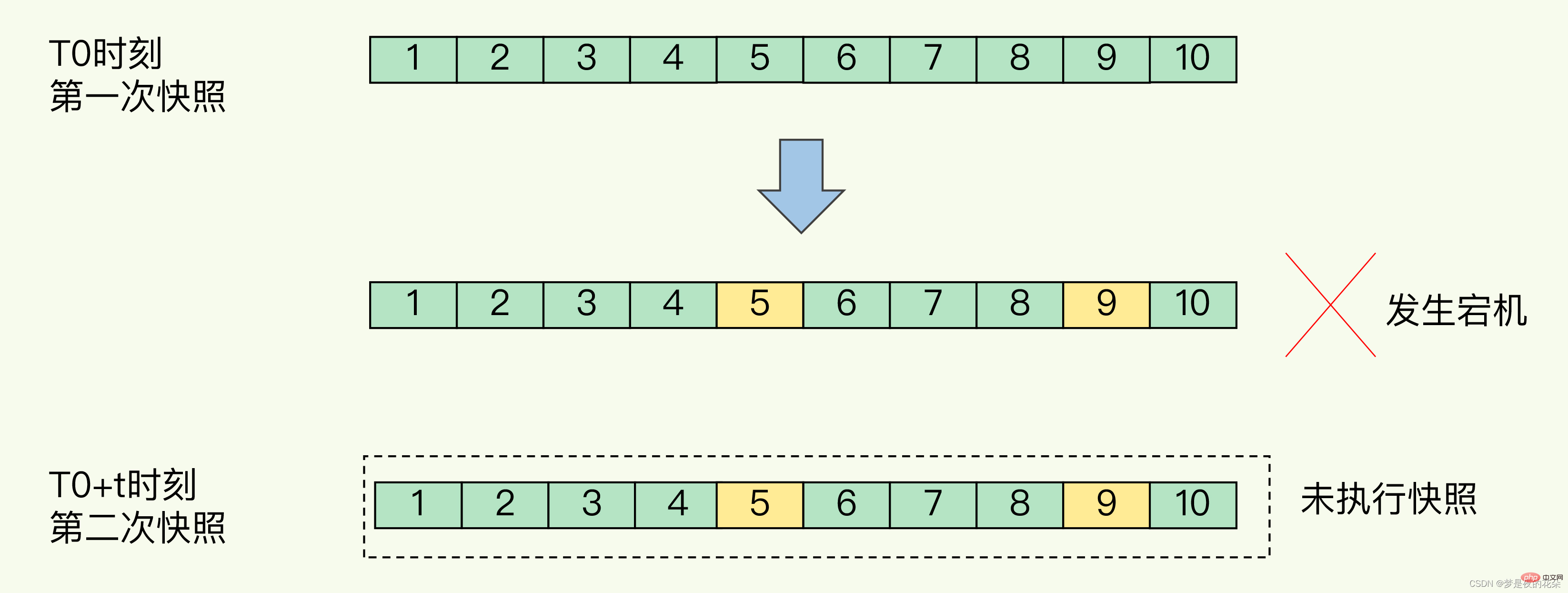
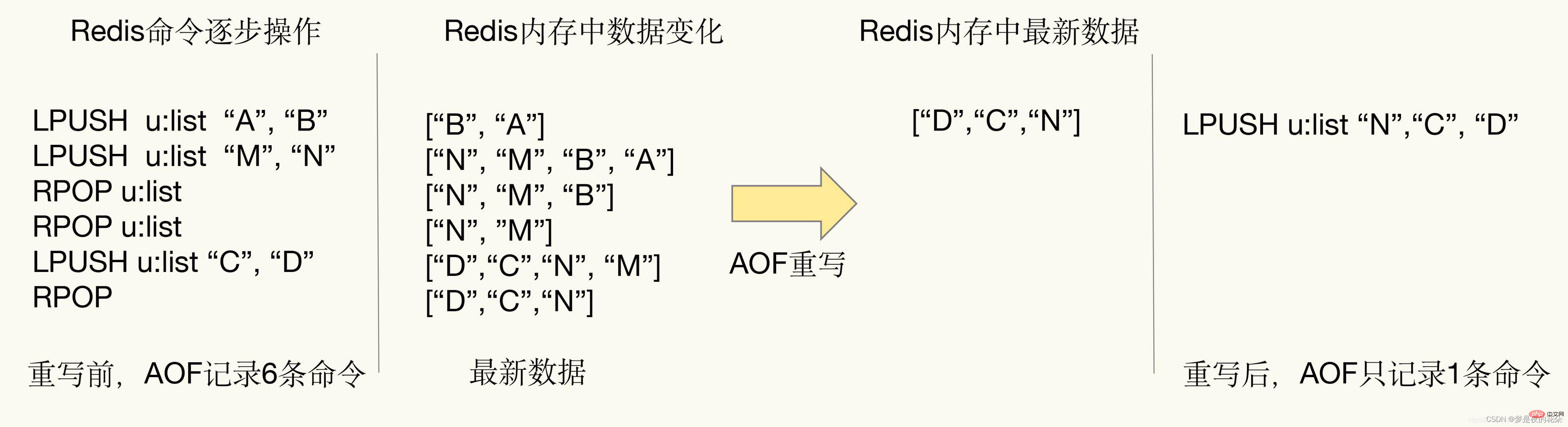 AOF enregistrera chaque commande d'écriture dans le fichier AOF au fil du temps, le fichier AOF deviendra de plus en plus gros. S'il n'est pas contrôlé, cela affectera le serveur Redis et même le système d'exploitation. De plus, plus le fichier AOF est volumineux, plus la récupération des données sera lente. Afin de résoudre le problème de l'expansion de la taille des fichiers AOF, Redis fournit un mécanisme de réécriture de fichiers AOF pour « alléger » les fichiers AOF.
AOF enregistrera chaque commande d'écriture dans le fichier AOF au fil du temps, le fichier AOF deviendra de plus en plus gros. S'il n'est pas contrôlé, cela affectera le serveur Redis et même le système d'exploitation. De plus, plus le fichier AOF est volumineux, plus la récupération des données sera lente. Afin de résoudre le problème de l'expansion de la taille des fichiers AOF, Redis fournit un mécanisme de réécriture de fichiers AOF pour « alléger » les fichiers AOF. 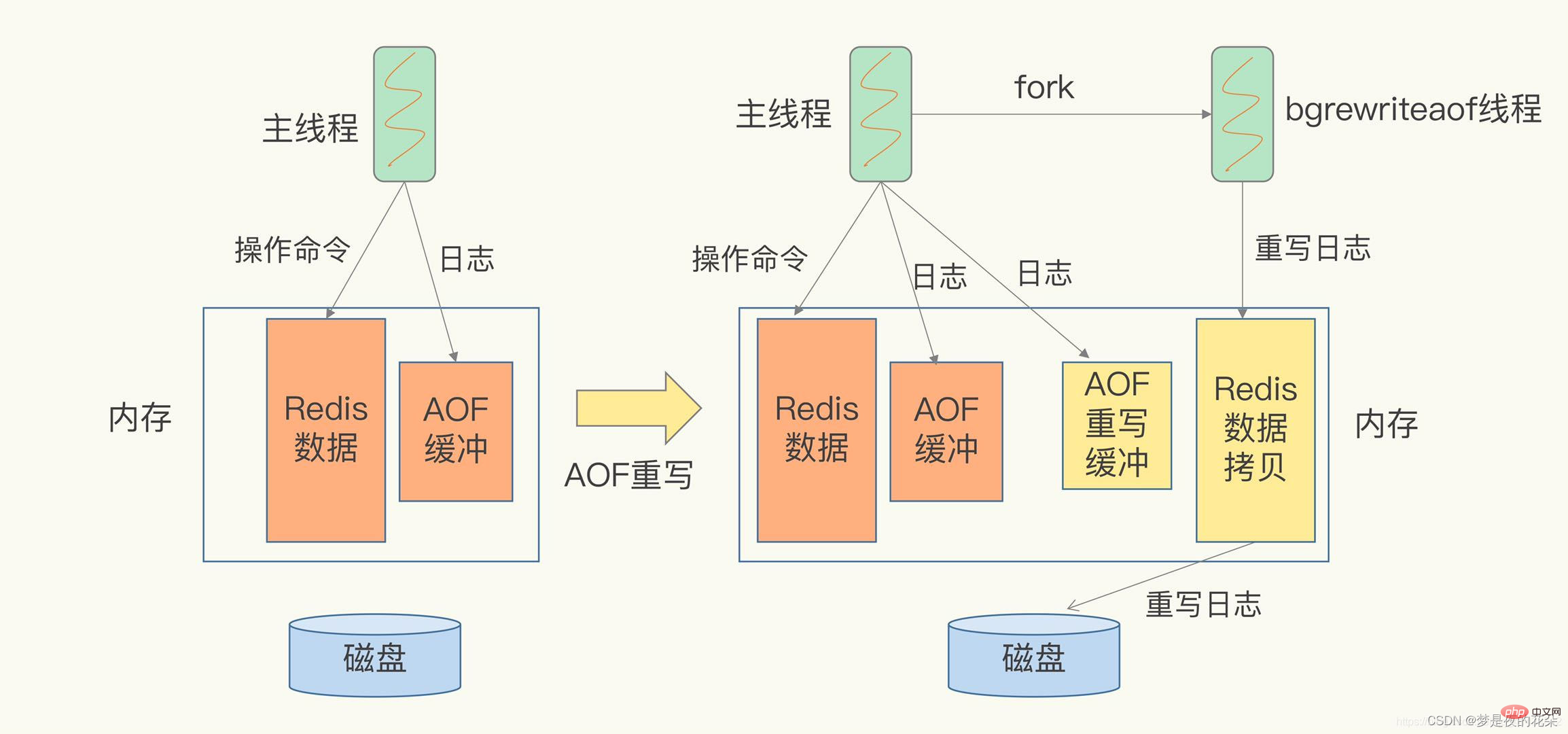
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Parlons des avantages et des fonctionnalités de Redis
- Analysons ensemble les problèmes de cohérence du cache Redis, de pénétration du cache, de panne de cache et d'avalanche de cache
- Analysez les problèmes de stockage des touches de raccourci dans Redis et discutez des solutions pour mettre en cache les exceptions
- Comment Redis implémente le blocage de file d'attente, le délai, la publication et l'abonnement
- Parlons de la problématique de la réalisation de ventes flash avec Redis