
Maison >base de données >tutoriel mysql >15 problèmes d'optimisation Mysql sélectionnés et résumés
15 problèmes d'optimisation Mysql sélectionnés et résumés

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-06-13 18:07:012170parcourir
Cet article vous apporte des connaissances pertinentes sur mysql, qui présente principalement les problèmes liés à l'optimisation SQL, notamment comment dépanner les instructions SQL pendant le processus de développement, comment résoudre les problèmes SQL dans l'environnement de production, etc., Jetons un coup d'œil à ensemble, j'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
Comment dépanner SQL pendant le processus de développement ?
Idées de dépannage
Pour la plupart des programmeurs, le dépannage SQL pendant le processus de développement est fondamentalement vide. Cependant, avec l'évolution de l'industrie, de plus en plus d'attention et de professionnalisme sont accordés au processus de développement. L'un d'eux consiste à résoudre autant que possible les problèmes SQL pendant le processus de développement afin d'éviter d'exposer les problèmes SQL pendant la production. Alors, comment effectuer facilement un dépannage SQL du programme pendant le processus de développement ?
L'idée est toujours d'utiliser le journal lent de Mysql pour réaliser :
-
Tout d'abord, pendant le processus de développement, vous devez également activer la requête lente de la base de données Mysql
SET GLOBAL slow_query_log='on';
-
Deuxièmement, définir le temps minimum pour SQL lent
Remarque : ici, l'unité de temps est de s secondes mais comporte 6 décimales, elle peut donc exprimer une intensité temporelle subtile. Généralement, le temps d'exécution SQL d'une seule table est inférieur à 20 ms. est que pendant le processus de développement, si l'instruction SQL que vous exécutez dépasse 20 ms, vous devez y prêter attention.
SET GLOBAL long_query_time=0.02;
-
Pour la commodité de fonctionnement, le SQL lent peut être enregistré dans une table au lieu d'un fichier
SET GLOBAL log_output='TABLE';
Enfin, le SQL lent enregistré peut être interrogé via la table mysql.slow_log
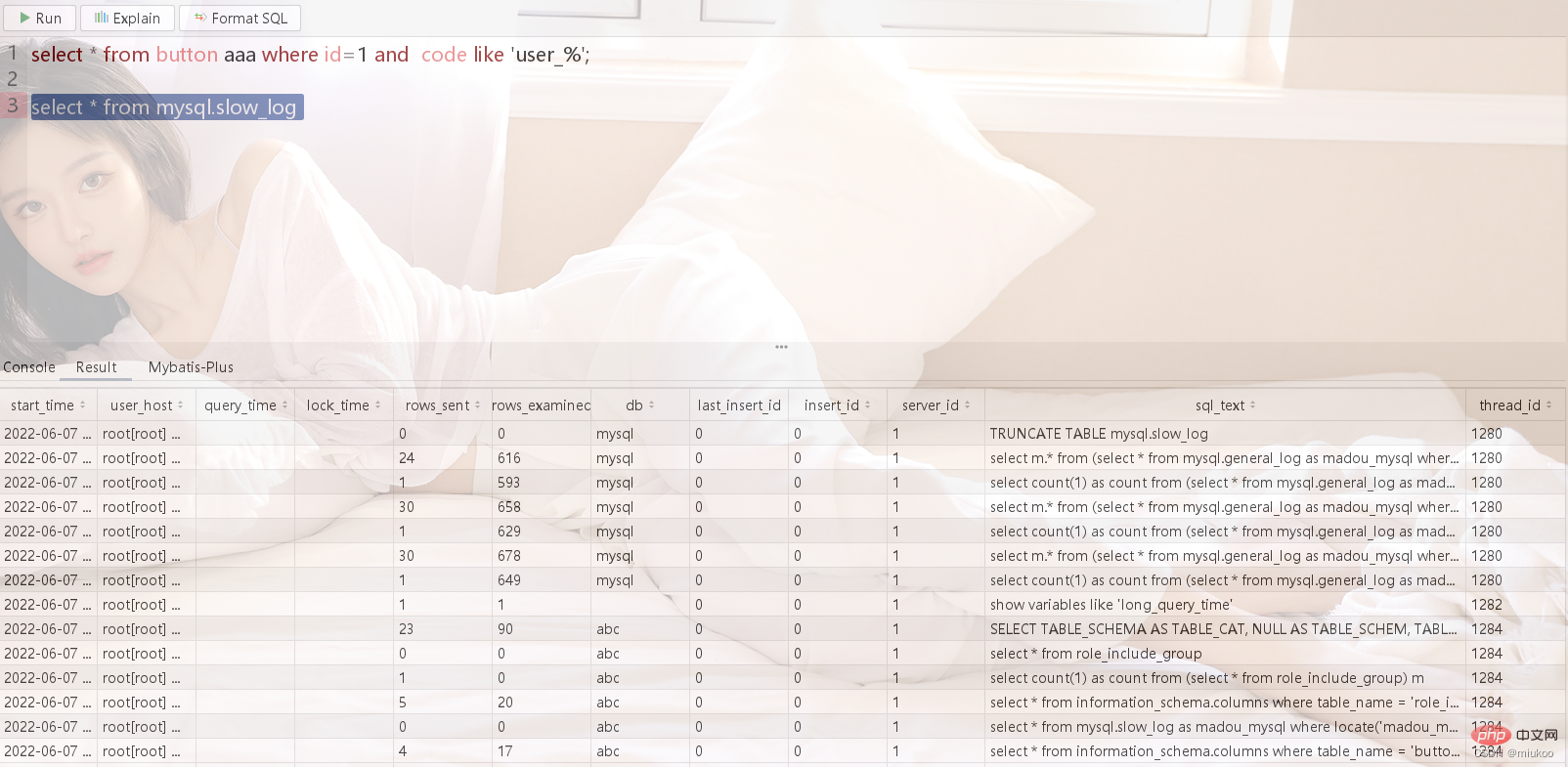
Utiliser les outils
Dans le logiciel développé pour vous par Brother Yong, il fournit également une interface graphique pour vous aider à mettre en œuvre rapidement les fonctions ci-dessus en un seul clic.
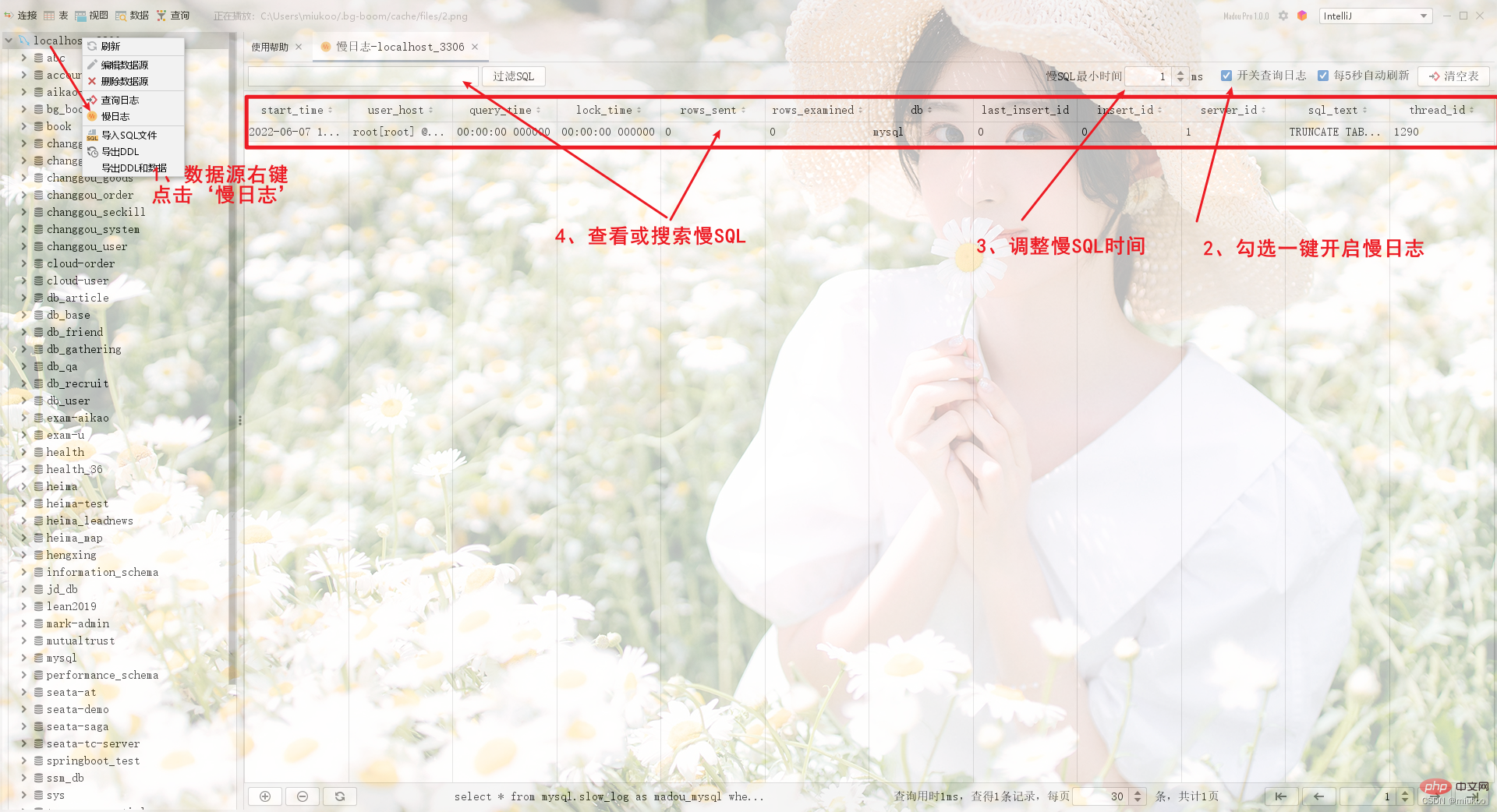
Comment résoudre les problèmes SQL dans un environnement de production ?
Idées de dépannage
Le dépannage des problèmes SQL générés est un peu plus compliqué, mais l'idée générale est de dépanner via SQL lent. Les idées spécifiques sont les suivantes :
-
Activez d'abord la requête lente de la base de données Mysql
SET GLOBAL slow_query_log='on';
. -
Deuxièmement, définissez les paramètres Le temps minimum de SQL lent
SET GLOBAL long_query_time=0.02;
-
Mettez généralement le SQL lent dans le fichier lors de la génération
SET GLOBAL log_output='FILE';
Téléchargez le fichier journal SQL lent en local
-
Fermez enfin la requête lente de la base de données Mysql
Faites attention à : Il est préférable d'ouvrir SQL lent pendant la production et de le fermer après utilisation pour éviter que la journalisation n'affecte les performances de l'entreprise
SET GLOBAL slow_query_log='off';
Comment régler SQL ?
Le réglage SQL intègre plusieurs aspects des connaissances De manière générale, il est courant d'optimiser sous deux aspects : la structure des tables et l'index des tables.
Optimisation de la structure des tables
1. Utilisation raisonnable des classes et longueurs de champs
Un exemple à comprendre : pour un champ de genre, le stockage tinyint(1) occupe 1 octet, et le stockage int(1) occupe 4 octets, s'il y en a. Il y a 1 million d'enregistrements, alors la taille du fichier de la table stockée dans int est d'environ 2,8 Mo plus grande que celle de la table stockée dans tinyint. Par conséquent, lors de la lecture de la table stockée dans le type int, le fichier est plus gros et la vitesse de lecture est plus lente. que celui de lire tinyint. C'est en fait l'essence même de la raison pour laquelle devrait être utilisé de manière rationnelle : il s'agit de réduire la taille des fichiers stockés afin d'offrir des performances de lecture .
Bien sûr, certains amis peuvent dire que 2,8 millions n'affectent pas la situation globale, ils peuvent donc être ignorés. Frère Yong aimerait ajouter quelque chose à cette idée : supposons qu'une table comporte 10 champs et que votre système ait un total de 30 tables. Examinons ensuite la taille du fichier supplémentaire. (2,8Mx10x30=840M, il faudra plusieurs secondes pour télécharger 840M avec Thunder Super. Ce temps est considéré comme très lent sur l'ordinateur...)
2. Utilisation raisonnable de la conception redondante
2.1. table
Il existe une table temporaire spéciale et légère dans Mysql, qui est automatiquement créée et supprimée par Mysql. Les tables temporaires sont principalement utilisées lors de l'exécution de SQL pour stocker les résultats intermédiaires de certaines opérations. Ce processus est automatiquement complété par MySQL et les utilisateurs ne peuvent pas intervenir manuellement, et cette table interne est invisible pour les utilisateurs.
Les tables temporaires internes sont très importantes dans le processus d'optimisation des instructions SQL. De nombreuses opérations dans MySQL reposent sur des tables temporaires internes pour les opérations d'optimisation. Cependant, l'utilisation de tables temporaires internes nécessite le coût de création de tables et d'accès aux données intermédiaires. Par conséquent, lors de l'écriture d'instructions SQL, vous devez essayer d'éviter d'utiliser des tables temporaires. Donc, dans ces scénarios, Mysql utilisera-t-il des tables temporaires en interne ?
Dans une requête associée à plusieurs tables (JOIN), la colonne utilisée par order by ou group by n'est pas une colonne de la première table
Lorsque la colonne de group by n'est pas une colonne d'index
Distinct et group by sont utilisés ensemble
L'instruction order by utilise le mot-clé distinct
group by columns sont des colonnes d'index, mais lorsque la quantité de données est trop importante
2.2. vérifier si elle est utilisée. Table temporaire interne ?
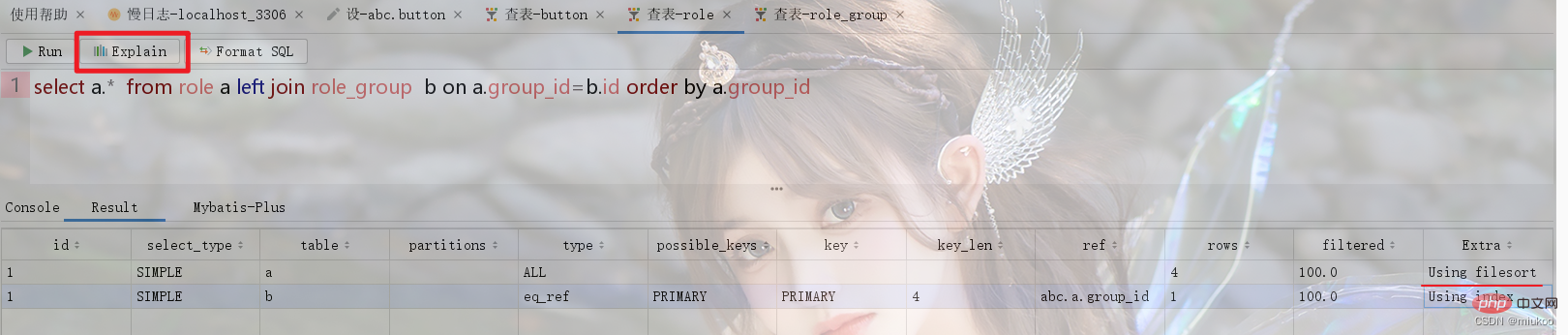
Utilisez le mot-clé Explain ou le bouton de fonction de l'outil pour visualiser le processus d'exécution de SQL Si le mot-clé Using Temporary apparaît dans la colonne Extra du résultat, cela signifie que votre instruction SQL utilise une table temporaire lors de l'exécution.
Comme le montre la figure ci-dessous, la table de rôles et le groupe de rôles Role_Group ont une relation plusieurs-à-un. Lors de l'exécution de requêtes associées, la table temporaire sera utilisée pour le tri en utilisant l'identifiant de role_group (voir la figure 1 ci-dessous). Si l'identifiant du rôle est utilisé pour le tri, alors les tables temporaires ne seront pas utilisées (voir Figure 2).
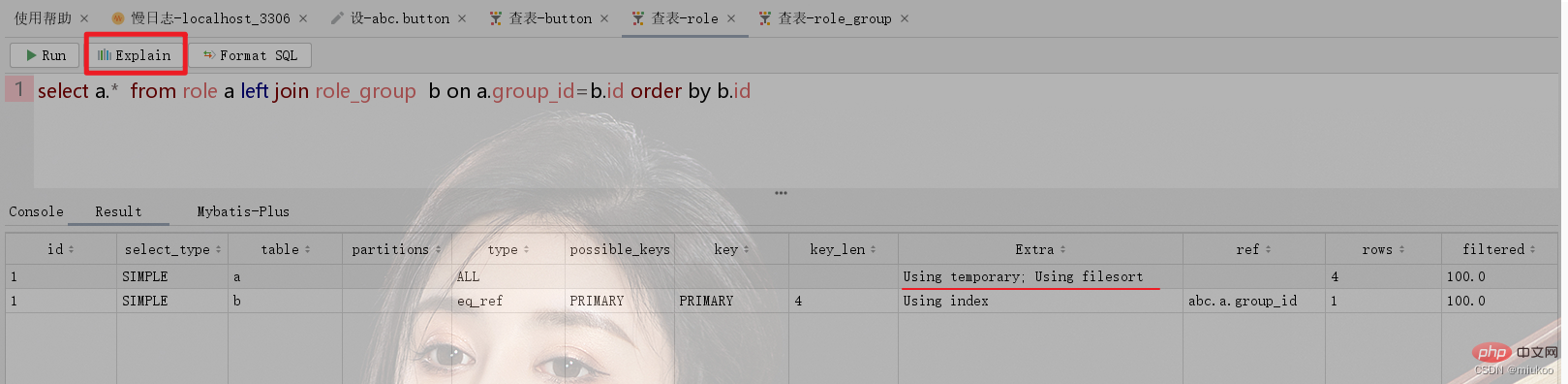
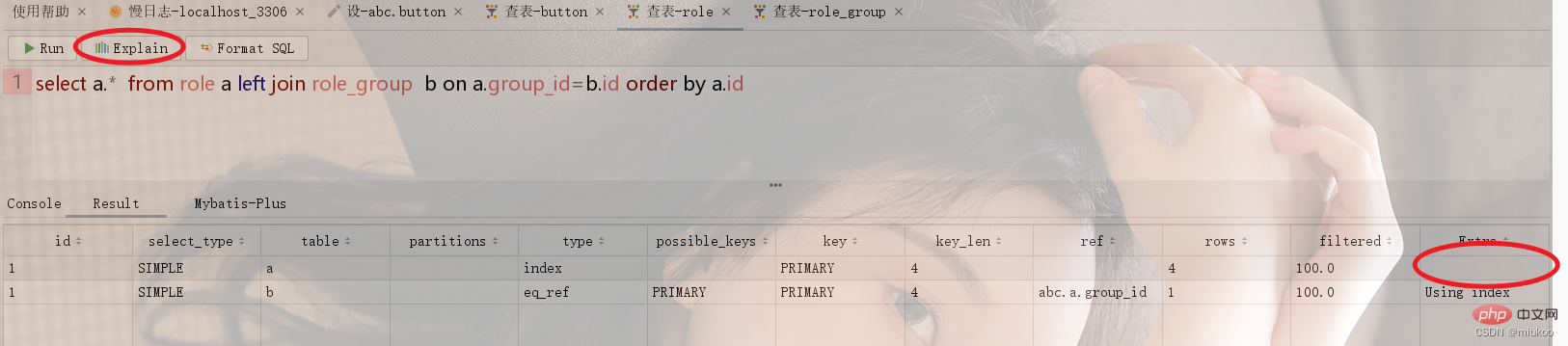
2.3. Comment résoudre le problème de la non-utilisation des tables temporaires internes ?
Il existe deux solutions à ce problème. L'une consiste à ajuster l'instruction SQL pour éviter d'utiliser des tables temporaires, et l'autre consiste à stocker de manière redondante dans la table. Par exemple, dans l'exemple de la figure 1 en 2.2, si vous devez trier par l'identifiant de role_group, vous pouvez trier par group_id dans la table des rôles, et cette colonne est la valeur de la colonne id dans la table role_group qui est redondante. stockés.
3. Utilisation raisonnable des sous-bases de données et des sous-tables
Les sous-bases de données et les sous-tables ne sont pas seulement utilisées pour l'optimisation en grande quantité, mais les sous-tables verticales peuvent également être utilisées pour le réglage SQL. (Je n'expliquerai pas ici les sous-tableaux verticaux et horizontaux. Si vous êtes intéressé, envoyez-moi un message privé)
Par exemple : la conception générale d'un tableau d'articles n'inclura pas le large champ du contenu de l'article.

Le grand champ du contenu de l'article est placé dans un tableau séparé

Pourquoi le tableau des articles adopte-t-il la conception ci-dessus au lieu de fusionner les champs en un seul tableau ?
Calculons d'abord un problème mathématique. Supposons qu'un article mesure 1 Mo, dont le contenu de l'article est de 824 Ko et les champs restants sont de 200 Ko. Il y a un total de 1 million d'articles de ce type, alors :
Option. 1, si une table est utilisée pour le stockage, alors la taille de la table est de 100 W * 1 M = 100 WM
Option 2, si une table de stockage verticale est utilisée, la table de base est de 200 Ko x 100 W et la table de contenu est de 824 Ko x 100 W
Nous avoir respectivement deux listes d'articles et les détails de l'article sur la page d'accueil pour interroger le contenu pertinent directement à partir de la base de données, puis :
Plan 1, la liste d'articles et les détails de l'article seront interrogés à partir des données 100WM
Plan 2, la liste des articles sera interrogée à partir de 200 Ko x 100 W, les détails des articles seront interrogés à partir de 824 Ko x 100 W (actuellement, vous devrez peut-être également interroger à partir de 200 Ko x 100 W)
Cela dit, je pense que tout le monde devrait avoir une réponse claire en tête ! La division verticale des tables permet d'interroger différentes quantités de données dans différents scénarios commerciaux. Souvent, cette quantité de données est inférieure à la quantité totale de données de la table, ce qui est plus flexible et efficace que l'interrogation à partir d'une quantité fixe grande ou petite.
Optimisation des index de table
1. Ajoutez raisonnablement des colonnes d'index
La plupart des gens comprennent les index comme suit : « Les index peuvent accélérer les requêtes », mais frère Yong doit ajouter la seconde moitié de cette phrase « Les index peuvent accélérer les requêtes ». requêtes ou ralentir l'insertion ou la modification de données ».
Si une table a 5 index, alors vous pouvez simplement considérer un index comme une table, alors il y aura 1 table + 6 tables d'index = équivalent à 6 tables, alors quand ces 6 tables peuvent-elles fonctionner ? Calculons-le :
opération d'insertion, une fois les données insérées, vous devez insérer les données d'index dans 5 tables d'index
opération de suppression, une fois les données supprimées, vous devez supprimer les index dans 5 tables d'index
-
opération de mise à jour
Si les données de la colonne d'index sont modifiées, les données doivent d'abord être modifiées, et l'index de la table d'index doit également être modifié
Si les données de la colonne d'index ne sont pas modifiées , seule la table de données doit être modifiée
-
opération de sélection
Si l'index de requête est atteint, interrogez d'abord l'index, puis vérifiez la table de données
Si l'index de requête n'est pas atteint, vérifiez directement la table de données
Grâce aux calculs ci-dessus, vous le ferez Miraculeusement, nous avons découvert que plus nous avons d'index, cela aura un impact sur les opérations d'insertion, de suppression et de mise à jour, et cela aura un impact négatif . Par conséquent, il est possible d'évaluer que l'impact de l'index est inférieur au bénéfice de la requête, puis de l'ajouter au lieu de l'ajouter aveuglément . 复合索引指的是包括有多个列的索引,它能有效的减少表的索引个数,平衡了多个字段需要多个索引直接的性能平衡,但是再使用复合索引的时候,需要注意索引列个数和顺序的问题。 先说列个数的问题,指的是一个复合索引中包括的列字段太多影响性能的问题,主要是对update操作的性能影响,如下红字: 如果修改了索引列的数据,则先修改数据,还需要修改索引表中的索引,如果索引列个数越多则修改该索引的概率越大 如果没有修改索引列的数据,则只修改数据表 再说复合索引中列顺序的问题,是指索引的最左匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配,这个比较容易理解,就不多做阐述。 索引无法存储null值,当使用is null或is not nulli时会全表扫描 like查询以"%"开头 对于复合索引,查询条件中没有给出索引中第一列的值时 mysql内部评估全表扫描比索引快时 or、!=、<>、in、not in等查询也可能引起索引失效 表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型为 字段允许适当冗余,以提高查询性能,但必须考虑数据一致。e.g. 商品类目名称使用频率高,字段长度短,名称基本一成不变,可在相关联的表中冗余存储类目名称, 避免关联查询 。冗余字段遵循: 不是频繁修改的字段; 不是 varchar 超长字段,更不能是 text 字段。 在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度即可。 页面搜索严禁左模糊或者全模糊,如果需要请通过搜索引擎来解决。 说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。 如果有 order by 的场景,请注意利用索引的有序性。order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现 file_sort 的情况,影响查询性能。 正例:where a=? and b=? order by c; 索引: a_b_c。 反例:索引中有范围查找,那么索引有序性无法利用,如 WHERE a>10 ORDER BY b; 索引 a_b 无法排序。 利用延迟关联或者子查询优化超多分页场景。 说明:MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后返回放弃前 offset 的行,返回 N 行。当 offset 特别大的时候,效率会非常的低下,要么控制返回的总页数,要么对超过阈值的页数进行 SQL 改写。 建组合索引的时候,区分度最高的在最左边。 SQL 性能优化的目标,至少要达到 range 级别,要求是 ref 级别,最好是 consts。 不要使用 count(列名) 或 count(常量) 来替代 count(),count() 是 SQL92 定义的标准统计行数的语句,跟数据库无关,跟 NULL 和非 NULL 无关。 说明:count(*) 会统计值为 NULL 的行,而 count(列名) 不会统计此列为 NULL 值的行。 当某一列的值全为 NULL 时, 使用 Les clés étrangères et les cascades ne sont pas autorisées. Tous les concepts de clés étrangères doivent être résolus au niveau de la couche application. Explication : Prenons l'exemple de la relation entre les étudiants et les notes. Le student_id de la table student est la clé primaire, et le student_id de la table des notes est la clé étrangère. Si le student_id dans la table des étudiants est mis à jour et le student_id dans la table des notes est mis à jour en même temps, il s'agit d'une mise à jour en cascade. Les clés étrangères et les mises à jour en cascade conviennent à une faible concurrence sur une seule machine, mais ne conviennent pas aux clusters distribués et à haute concurrence ; les mises à jour en cascade sont fortement bloquantes et risquent de provoquer des tempêtes de mises à jour de la base de données qui affectent la vitesse d'insertion de la base de données ; . L'utilisation de procédures stockées est interdite. Les procédures stockées sont difficiles à déboguer et à étendre, et elles ne sont pas portables. Les opérations POJO 类的布尔属性不能加 is,而数据库字段必须加 is_,要求在 resultMap 中进行字段与属性的映射。 Les attributs booléens de la classe POJO ne peuvent pas être ajoutés avec is, mais les champs de la base de données doivent être ajoutés avec is_, ce qui nécessite un mappage des champs et des attributs dans resultMap. 2、合理的调配复合索引列个数和顺序
那些情况索引会失效?
表设计有那些规范?
建表规约
unsigned tinyint。 说明:任何字段如果为非负数,则必须是 unsigned。
索引规约
SQL 语句
count(distinct column) 计算该列除 NULL 外的不重复行数。注意,count(distinct column1,column2) 如果其中一列全为 NULL,那么即使另一列用不同的值,也返回为 0。count(column) 的返回结果为 0,但 sum(column) 的返回结果为 NULL,因此使用 sum() 时需注意 NPE 问题。 可以使用如下方式来避免 sum 的 NPE 问题。SELECT IF(ISNULL(SUM(g), 0, SUM(g))) FROM table;
ISNULL() 来判断是否为 NULL 值。 说明:NULL 与任何值的直接比较都为 NULL。in doivent être évitées si possible. Si cela ne peut être évité, vous devez évaluer soigneusement le nombre d'éléments de collecte après l'entrée et le contrôler dans la limite de 1 000. in 操作能避免则避免。若实在避免不了,需要仔细评估 in 后面的集合元素数量,控制在 1000 个之内。ORM 映射
sql.xml 配置参数使用:#{}, #param#,不要使用 ${},此种方式容易出现 SQL 注入。@TransactionalMappage ORM
sql.xml Les paramètres de configuration utilisent : #{}, #param#, n'utilisez pas ${}, cette méthode est sujette à l'injection SQL. 🎜🎜🎜🎜@Transactional N'abusez pas des transactions. Les transactions affectent le QPS de la base de données. De plus, lorsque des transactions sont utilisées, divers aspects des solutions de restauration doivent être pris en compte, notamment la restauration du cache, la restauration du moteur de recherche, la compensation des messages, la correction statistique, etc. 🎜🎜🎜🎜Apprentissage recommandé : 🎜Tutoriel vidéo mysql🎜🎜
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment modifier l'encodage MySQL dans Ubuntu
- Explication détaillée des bases de MySQL : modèle de données et langage SQL
- Analysons ensemble les principes du workflow de transactions MySQL
- Exemples graphiques analysant la gestion des utilisateurs MySQL
- Résumer et organiser les spécifications de conception de base de données MySQL