
Maison >base de données >tutoriel mysql >Analysons ensemble les principes du workflow de transactions MySQL
Analysons ensemble les principes du workflow de transactions MySQL

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-06-01 11:52:252062parcourir
Cet article vous apporte des connaissances pertinentes sur mysql, qui introduit principalement des problèmes liés aux principes du flux de travail des transactions, y compris l'atomicité des transactions est obtenue via le journal d'annulation et la persistance des transactions est obtenue via refaire. implémentation du journal et ainsi de suite. J'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
- L'atomicité des transactions est obtenue grâce au journal d'annulation
- La durabilité des transactions est obtenue grâce au journal redo
- L'isolation des transactions est obtenue grâce à (lecture du verrouillage en écriture + MVCC) pour atteindre
- Et la cohérence ultime des transactions entre grands patrons est obtenue grâce à l'atomicité, à la persistance et à l'isolement ! ! !
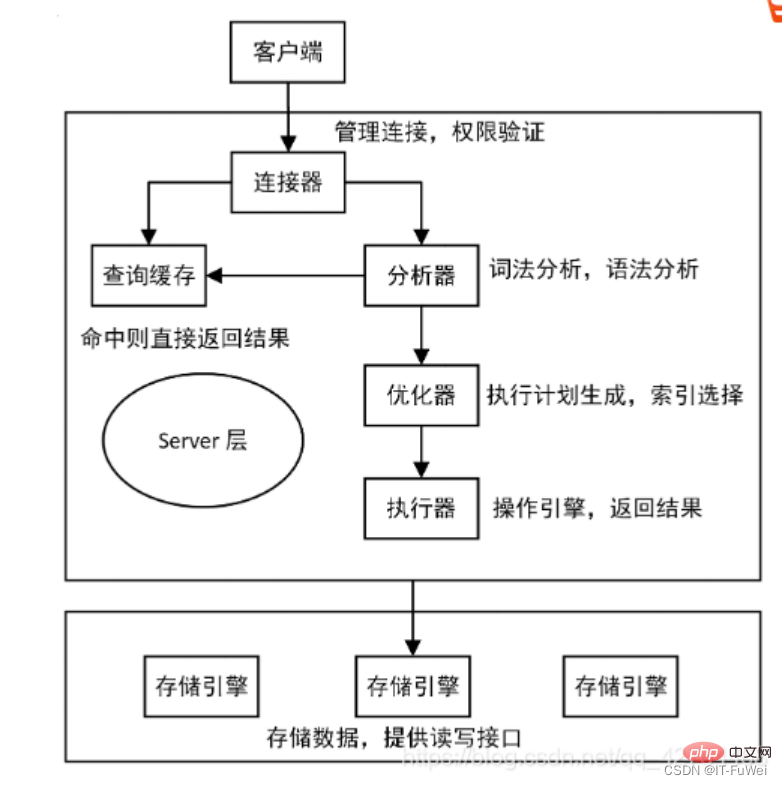
1. redo log atteint la persistance
Question 1 : Pourquoi avez-vous besoin de refaire un journal ?
InnoDB est le moteur de stockage de MySQL Les données sont stockées sur le disque, mais si des E/S disque sont nécessaires à chaque fois pour lire et écrire des données, l'efficacité sera très faible. À cette fin, InnoDB fournit un cache (Buffer Pool) comme tampon pour accéder à la base de données : lors de la lecture des données de la base de données, elles seront d'abord lues depuis le Buffer Pool. S'il n'y a pas de pool de tampons, elles seront lues depuis le Buffer Pool. disque et placés dans le pool de tampons ; lors de l'écriture des données dans la base de données, elles seront d'abord écrites dans le pool de tampons et les données modifiées dans le pool de tampons seront régulièrement actualisées sur le disque.
L'utilisation de Buffer Pool améliore considérablement l'efficacité de la lecture et de l'écriture des données, mais elle entraîne également de nouveaux problèmes : si MySQL tombe en panne et que les données modifiées dans le Buffer Pool n'ont pas été vidées sur le disque, cela entraînera une perte de données. La durabilité des transactions n’est pas garantie.
Question 2 : Comment le redo log assure-t-il la pérennité des transactions ?
Le journal redo peut être simplement divisé en deux parties suivantes :
La première est le tampon de journalisation en mémoire (tampon de journalisation), qui est volatile et en mémoire
La seconde est le tampon de journalisation log (fichier redo log), est persistant et est enregistré sur le disque
Ici, nous détaillerons le moment de l'écriture de Redo :
Une fois la modification de la page de données terminée et avant que la page sale ne soit vidée du disque , le journal redo est écrit. Notez que les données sont modifiées en premier et que le journal est écrit plus tard
Le journal de rétablissement est réécrit sur le disque avant la page de données
Les modifications de l'index clusterisé, de l'index secondaire et de la page d'annulation doivent toutes être enregistrées dans le Refaire le journal
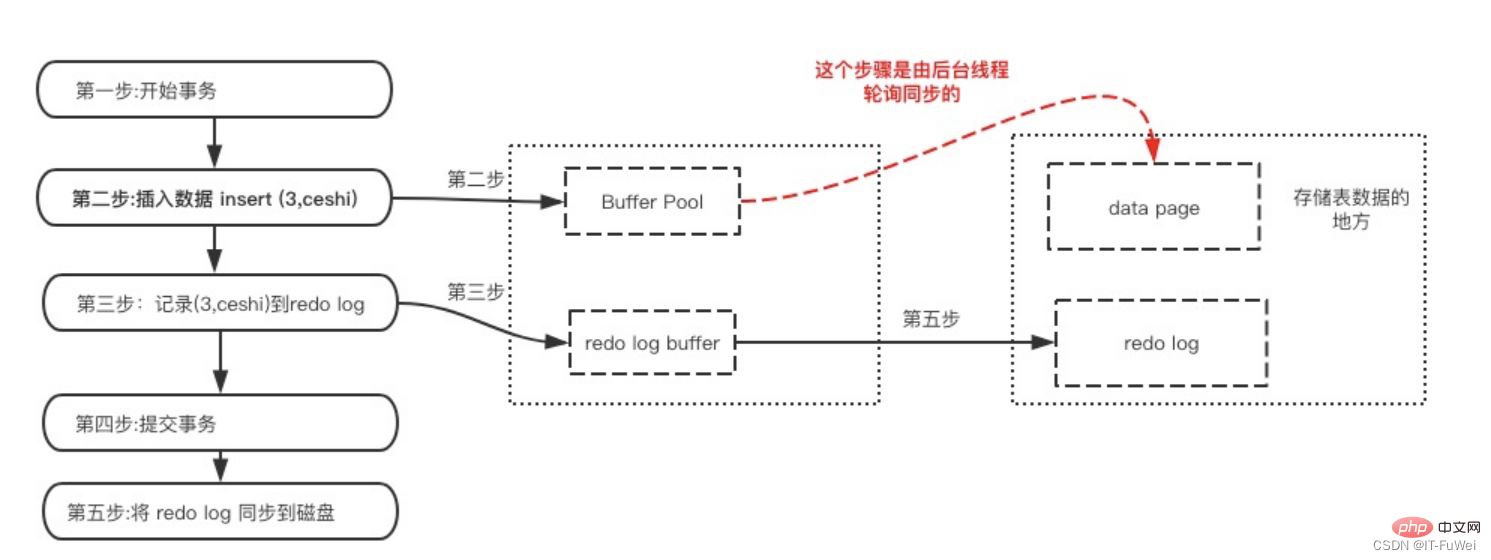
dans MySQL, si chaque opération de mise à jour doit être écrite sur le disque et que le disque doit trouver l'enregistrement correspondant avant la mise à jour, le coût d'E/S et le coût de recherche de l'ensemble du processus seront très élevés. Afin de résoudre ce problème, les concepteurs de MySQL ont utilisé le redo log pour améliorer l'efficacité des mises à jour.
Lorsqu'une transaction est validée, le tampon de journalisation est d'abord écrit dans le fichier de journalisation pour des raisons de persistance, et il n'est terminé que lorsque l'opération de validation de la transaction est terminée. Cette approche est également appelée Write-Ahead Log (persistance pré-journalisation). Avant de conserver une page de données, la page de journal correspondante est conservée en mémoire.
Plus précisément, lorsqu'un enregistrement doit être mis à jour, le moteur InnoDB écrira d'abord l'enregistrement dans le journal redo (tampon redo log) et mettra à jour la mémoire (pool de tampons). À ce moment, la mise à jour est terminée. Dans le même temps, le moteur InnoDB mettra à jour cet enregistrement d'opération sur le disque (vidage des pages sales) au moment approprié (par exemple lorsque le système est inactif).
Plusieurs pages peuvent être modifiées en une seule transaction. Le journal Write-Ahead peut garantir la cohérence d'une seule page de données, mais ne peut pas garantir la durabilité de la transaction. génère tout Le journal des mini-transactions doit être vidé sur le disque. Si une fois le vidage du journal terminé, la base de données se bloque avant que les pages du pool de mémoire tampon ne soient vidées sur le périphérique de stockage persistant, alors lorsque la base de données est redémarrée, l'intégrité de la base de données est compromise. les données peuvent être assurées via le journal.
Question 3 : Quel est le processus de réécriture des logs ?
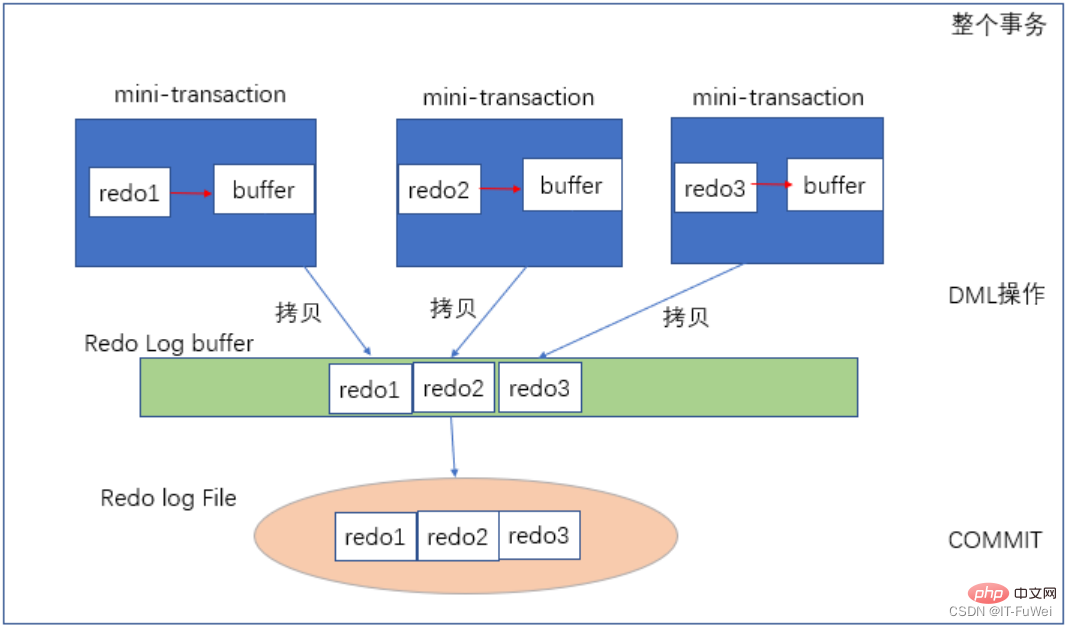
La figure ci-dessus montre le processus d'écriture du redo log. Chaque mini-transaction correspond à chaque opération DML, comme une instruction de mise à jour, qui est garantie par une mini-transaction. Une fois les données modifiées, redo1 est d'abord généré. est Écrire dans le tampon privé de la mini-transaction Une fois l'instruction de mise à jour terminée, copiez redo1 du tampon privé vers le tampon de journal public. Lorsque la totalité de la transaction externe est validée, le tampon de journalisation est vidé dans le fichier de journalisation. (Le journal de rétablissement est écrit de manière séquentielle, et la lecture et l'écriture séquentielles du disque sont beaucoup plus rapides que la lecture et l'écriture aléatoires)
Question 4 : L'emplacement final du disque après l'écriture des données est-il mis à jour à partir du journal de rétablissement ? Qu'en est-il de la mise à jour à partir du pool de mémoire tampon ?
En fait, le journal redo n'enregistre pas les données complètes de la page de données, il n'a donc pas la possibilité de mettre à jour la page de données du disque par lui-même, et il n'y a aucune situation où les données sont mises à jour par le redo log est enfin placé sur le disque.
① Une fois la page de données modifiée, elle est incohérente avec la page de données sur le disque, appelée page sale. Les données finales sont écrites sur le disque en écrivant les pages de données de la mémoire sur le disque. Ce processus n'a rien à voir avec le redo log.
② Dans un scénario de récupération après crash, si InnoDB détermine qu'une page de données peut avoir perdu des mises à jour lors de la récupération après crash, il la lira en mémoire, puis laissera le journal de rétablissement mettre à jour le contenu de la mémoire. Une fois la mise à jour terminée, la page mémoire devient une page sale et revient à l'état de la première situation
Question 5 : Qu'est-ce que le tampon de journalisation ? Dois-je d'abord modifier la mémoire ou écrire d'abord le fichier de journalisation ?
Pendant le processus de mise à jour d'une transaction, le journal doit être écrit plusieurs fois. Par exemple, la transaction suivante :
Copybegin;
INSERT INTO T1 VALUES ('1', '1');
INSERT INTO T2 VALUES ('1', '1');
commit;
This La transaction nécessite Insérer des enregistrements dans deux tables. Pendant le processus d'insertion des données, les journaux générés doivent d'abord être enregistrés, mais ils ne peuvent pas être écrits directement dans le fichier de journalisation avant d'être validés.
Le tampon de redo log est donc nécessaire. Il s'agit d'un morceau de mémoire utilisé pour stocker les redo logs en premier. En d'autres termes, lorsque la première insertion est exécutée, la mémoire de données est modifiée et le tampon redo log est également écrit dans le journal.
Cependant, l'écriture réelle du journal dans le fichier redo log est effectuée lorsque l'instruction de validation est exécutée.
redo log buffer n'est essentiellement qu'un tableau d'octets, mais afin de maintenir ce tampon, de nombreuses autres métadonnées doivent être définies, qui sont toutes encapsulées dans la structure log_t.
Question 6 : Les journaux de rétablissement sont-ils écrits sur le disque de manière séquentielle ?
redo log écrit les fichiers de manière séquentielle. Lorsque tous les fichiers sont pleins, il revient à la position de départ correspondante du premier fichier pour l'écrasement. Après la soumission de chaque transaction, les journaux d'opération correspondants sont écrits. le fichier de journalisation et sont ajoutés à la fin du fichier. Il s'agit d'une E/S séquentielle
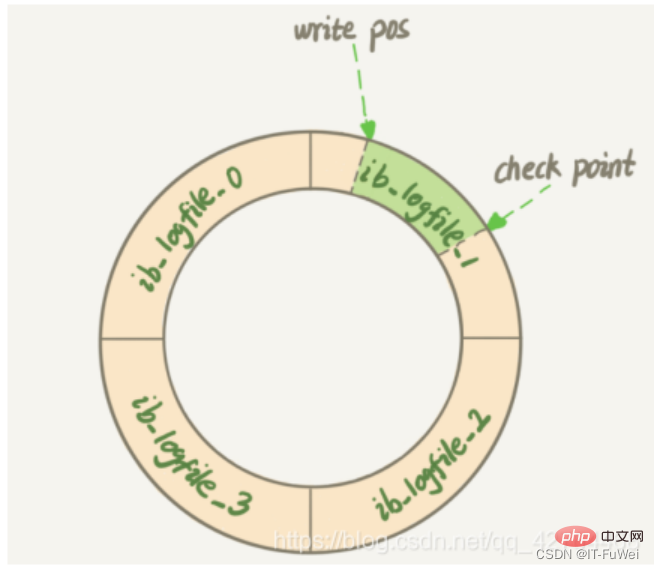
L'image montre un ensemble de journaux de journalisation de 4 fichiers, et le point de contrôle doit actuellement être effacé. Avant d'effacer l'enregistrement, les données correspondantes doivent être écrites sur le disque (mettre à jour la page mémoire et attendre que la page sale soit vidée). La partie entre la position d'écriture et le point de contrôle peut être utilisée pour enregistrer de nouvelles opérations. Si la position d'écriture et le point de contrôle se rencontrent, cela signifie que le journal redo est plein à ce moment-là, la base de données arrête d'exécuter l'instruction de mise à jour de la base de données et synchronise à la place le journal redo. le disque. La partie entre le point de contrôle et la position d'écriture attend que le disque soit écrit (mettez d'abord à jour la page mémoire, puis attendez que la page sale soit vidée).
Avec le journal redo, lorsque la base de données redémarre anormalement, elle peut être restaurée sur la base du journal redo, qui est sécurisé en cas de crash.
redo log est utilisé pour garantir des capacités de sécurité en cas de crash. Lorsque le paramètre innodb_flush_log_at_trx_commit est défini sur 1, cela signifie que le journal redo de chaque transaction est directement conservé sur le disque. Il est recommandé de définir ce paramètre sur 1 pour garantir que les données ne seront pas perdues après un redémarrage anormal de MySQL
2. Le journal Bin
MySQL comprend en fait deux parties : l'une est la couche serveur, qui exécute principalement les fonctions de couche MySQL. il y a aussi la couche moteur, qui est responsable des questions spécifiques liées au stockage. Le redo log dont nous avons parlé ci-dessus est un log unique au moteur InnoDB, et la couche Serveur possède également son propre log, appelé binlog (archive log)
Pourquoi y a-t-il deux logs ?
Parce qu'il n'y avait pas de moteur InnoDB dans MySQL au début. Le propre moteur de MySQL est MyISAM, mais MyISAM n'a pas de fonctionnalités de sécurité contre les pannes et les journaux binlog ne peuvent être utilisés qu'à des fins d'archivage. InnoDB a été introduit dans MySQL sous la forme d'un plug-in par une autre société. Étant donné que le fait de s'appuyer uniquement sur binlog n'a pas de capacités de sécurité contre les crashs, InnoDB utilise un autre système de journalisation, à savoir le redo log, pour obtenir des capacités de sécurité contre les crashs.
Ces deux journaux présentent les trois différences suivantes.
① redo log est unique au moteur InnoDB ; binlog est implémenté par la couche serveur de MySQL et peut être utilisé par tous les moteurs.
② redo log est un journal physique, qui enregistre « quelles modifications ont été apportées sur une certaine page de données » ; binlog est un journal logique, qui enregistre la logique originale de cette instruction, telle que « donner le champ c de la ligne avec ID=2" Ajouter 1".
③ Le redo log est écrit en boucle, et l'espace sera toujours utilisé ; le binlog peut être écrit en plus ; "Ajouter l'écriture" signifie qu'une fois que le fichier binlog atteint une certaine taille, il passera au suivant et n'écrasera pas le journal précédent.
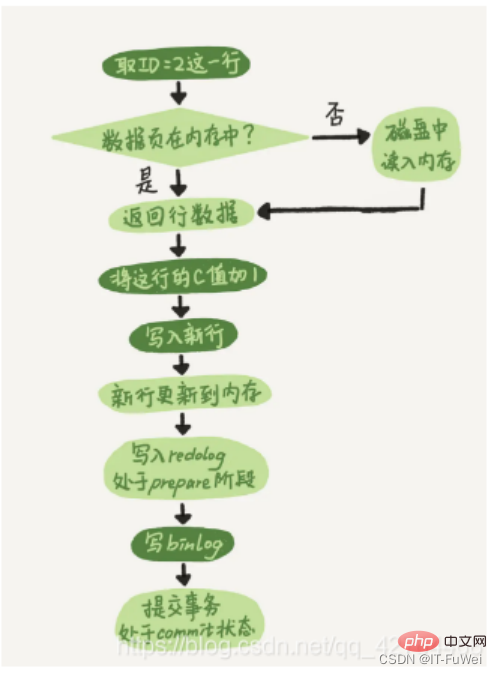
Avec une compréhension conceptuelle de ces deux journaux, examinons les processus internes de l'exécuteur et du moteur InnoDB lors de l'exécution de cette instruction de mise à jour.
① L'exécuteur cherche d'abord le moteur pour obtenir la ligne ID=2. L'ID est la clé primaire et le moteur utilise directement la recherche arborescente pour trouver cette ligne. Si la page de données où se trouve la ligne ID=2 est déjà dans la mémoire, elle sera renvoyée directement à l'exécuteur sinon, elle devra être lue dans la mémoire à partir du disque puis restituée ;
② L'exécuteur récupère les données de ligne données par le moteur, ajoute 1 à cette valeur, par exemple, c'était N avant, mais maintenant c'est N+1, obtient une nouvelle ligne de données, puis appelle l'interface du moteur pour écrire cette nouvelle ligne de données.
③ Le moteur met à jour cette nouvelle ligne de données dans la mémoire (InnoDB Buffer Pool) et enregistre l'opération de mise à jour dans le journal redo. À ce moment, le journal redo est à l'état de préparation. Informez ensuite l'exécuteur testamentaire que l'exécution est terminée et que la transaction peut être soumise à tout moment.
④ L'exécuteur génère le binlog de cette opération et écrit le binlog sur le disque.
⑤ L'exécuteur appelle l'interface de transaction de validation du moteur, et le moteur modifie le journal redo qui vient d'être écrit à l'état de validation, et la mise à jour est terminée
L'écriture du journal redo est divisée en deux étapes : préparer et commit, c'est un commit en deux phases (2PC)
Question 1 : Quel est le principe du commit en deux phases ?
MySQL utilise une validation en deux phases pour résoudre principalement le problème de cohérence des données du binlog et du redo log.
Description du principe de validation en deux phases :
① le redo log est écrit sur le disque et la transaction InnoDB entre dans l'état de préparation.
② Si la préparation précédente réussit et que le binlog est écrit sur le disque, continuez à conserver le journal des transactions dans le binlog. Si la persistance réussit, la transaction InnoDB entrera dans l'état de validation.
redo log et binlog ont un champ de données commun appelé XID. Lors d'une récupération après incident, les journaux de rétablissement seront analysés dans l'ordre :
① Si vous rencontrez un journal de rétablissement avec à la fois préparation et validation, soumettez-le directement
② Si vous rencontrez un journal de rétablissement avec uniquement parepare et sans validation, soumettez-le directement ; . Prenez le XID et allez dans binlog pour trouver la transaction correspondante.
Binlog n'a pas d'enregistrement, transaction d'annulation
binlog a un enregistrement, transaction de validation
Question 2 : Pourquoi une « validation en deux phases » est-elle nécessaire ?
Si la validation en deux phases n'est pas utilisée, supposez que la valeur du champ c dans la ligne actuelle avec ID=2 est 0, et supposez qu'après l'écriture du premier journal lors de l'exécution de l'instruction de mise à jour , le deuxième journal est toujours Si un crash se produit avant la fin de l'écriture, que se passera-t-il ?
**Écrivez d'abord le redo log, puis le binlog. **Supposons que le processus MySQL redémarre anormalement lorsque le redo log est terminé mais avant la fin du binlog. Comme nous l'avons dit précédemment, une fois le journal redo écrit, même si le système tombe en panne, les données peuvent toujours être restaurées, donc la valeur de c dans cette ligne après la récupération est 1.
Mais comme le binlog s'est écrasé avant d'être terminé, cette déclaration n'a pas été enregistrée dans le binlog pour le moment. Par conséquent, lorsque le journal sera sauvegardé ultérieurement, cette instruction ne sera pas incluse dans le journal binaire enregistré.
Ensuite, vous constaterez que si vous devez utiliser ce binlog pour restaurer la bibliothèque temporaire, en raison de la perte du binlog de cette instruction, la bibliothèque temporaire manquera cette mise à jour. La valeur de c dans la ligne restaurée est 0, qui est la même que la bibliothèque d'origine. Les valeurs sont différentes.
**Écrivez d'abord le journal binlog, puis refaites le journal. ** S'il y a un crash après l'écriture du binlog, puisque le journal redo n'a pas encore été écrit, la transaction sera invalide après la récupération sur crash, donc la valeur de c dans cette ligne est 0. Mais le journal "Changer c de 0 à 1" a été enregistré dans le binlog. Par conséquent, lorsque binlog est utilisé pour restaurer ultérieurement, une transaction supplémentaire sera générée. La valeur de c dans la ligne restaurée est 1, ce qui est différent de la valeur dans la base de données d'origine.
Vous pouvez constater que si la « validation en deux phases » n'est pas utilisée, l'état de la base de données peut être incohérent avec l'état de la bibliothèque restaurée à l'aide de son journal.
En termes simples, le redo log et le binlog peuvent être utilisés pour représenter l'état de validation d'une transaction, et la validation en deux phases consiste à maintenir les deux états logiquement cohérents.
3. Le journal d'annulation atteint l'atomicité
Le journal d'annulation a deux fonctions : fournir une restauration et un contrôle multi-version (MVCC)
Lorsque les données sont modifiées, non seulement la restauration est enregistrée, et enregistre également l'annulation correspondante. Le journal d'annulation enregistre principalement les modifications logiques des données. Afin d'annuler les opérations précédentes lorsqu'une erreur se produit, il est nécessaire d'enregistrer toutes les opérations précédentes, puis d'annuler lorsqu'une erreur se produit.
undo log restaure logiquement uniquement la base de données à son état d'origine. Lors du rollback, il fait en fait le travail inverse. Par exemple, un INSERT correspond à un DELETE, et pour chaque UPDATE, il correspond à un UPDATE opposé. ligne avant modification. Le journal d'annulation est utilisé pour les opérations d'annulation de transaction afin de garantir l'atomicité de la transaction.
La clé pour parvenir à l'atomicité est de pouvoir annuler toutes les instructions SQL exécutées avec succès lorsque la transaction est annulée. InnoDB implémente le rollback en s'appuyant sur le journal d'annulation : lorsqu'une transaction modifie la base de données, InnoDB génère le journal d'annulation correspondant. Si l'exécution de la transaction échoue ou si le rollback est appelé, provoquant l'annulation de la transaction, les informations contenues dans le journal d'annulation peuvent. être utilisé pour Les données sont restaurées telles qu'elles étaient avant la modification.
Dans le moteur de stockage InnoDB, le journal d'annulation est divisé en :
insérer le journal d'annulation
mettre à jour le journal d'annulation
insérer le journal d'annulation fait référence au journal d'annulation généré lors de l'opération d'insertion, car l'enregistrement de l'opération d'insertion n'est visible que à la transaction elle-même, non visible par les autres transactions. Par conséquent, le journal d'annulation peut être supprimé directement après la soumission de la transaction et aucune opération de purge n'est requise.
Le journal d'annulation de mise à jour enregistre le journal d'annulation généré par les opérations de suppression et de mise à jour. Le journal d'annulation peut devoir fournir un mécanisme MVCC, il ne peut donc pas être supprimé lorsque la transaction est validée. Lors de la soumission, placez-le dans la liste du journal d'annulation et attendez que le thread de purge effectue la suppression finale.
Supplément : Les deux fonctions principales du fil de purge sont : nettoyer la page d'annulation et effacer les lignes de données avec l'indicateur Delete_Bit dans la page. Dans InnoDB, l'opération Supprimer dans une transaction ne supprime pas réellement la ligne de données, mais une opération Supprimer Marquer qui marque le Delete_Bit sur l'enregistrement sans supprimer l'enregistrement. Il s'agit d'une sorte de "fausse suppression", qui est simplement marquée. Le vrai travail de suppression doit être effectué par le thread de purge en arrière-plan.
Innodb utilise l'arbre B+ comme structure de données d'index, et l'index où se trouve la clé primaire est ClusterIndex (index cluster), et le contenu des données correspondant est stocké dans les nœuds feuilles dans ClusterIndex. Une table ne peut avoir qu'une seule clé primaire, il ne peut donc y avoir qu'un seul index clusterisé. Si la table ne définit pas de clé primaire, le premier index unique non NULL est sélectionné comme index clusterisé. S'il n'y en a pas, un index masqué. La colonne id est générée en tant qu'index clusterisé.
Les index autres que l'index de cluster sont des index secondaires (index auxiliaire). Les nœuds feuilles de l'index auxiliaire stockent les valeurs des nœuds feuilles de l'index clusterisé.
En plus du rowid que nous venons de mentionner, les enregistrements de ligne InnoDB incluent également trx_id et db_roll_ptr représente l'identifiant de la transaction récemment modifiée, et db_roll_ptr pointe vers le journal d'annulation dans le segment d'annulation.
Lorsqu'une nouvelle transaction est ajoutée, l'identifiant de la transaction sera augmenté et trx_id peut indiquer l'ordre dans lequel les transactions sont démarrées.
Le journal d'annulation est divisé en deux types : Insérer et Mettre à jour. La suppression peut être considérée comme une mise à jour spéciale, c'est-à-dire la modification de la marque de suppression sur l'enregistrement.
Le journal d'annulation de mise à jour enregistre les informations de données précédentes, grâce auxquelles l'état de la version précédente peut être restauré.
Lors de l'exécution d'une opération d'insertion, le journal d'annulation d'insertion généré peut être supprimé une fois la transaction validée, car les autres transactions n'ont pas besoin de ce journal d'annulation.
Lors de la suppression et de la modification des opérations, le journal d'annulation correspondant sera généré et le db_roll_ptr dans l'enregistrement de données actuel pointera vers le nouveau journal d'annulation
4 MVCC réalise l'isolement
MVCC (MultiVersion Concurrency Control) est appelé. contrôle de concurrence multiversion.
Le MVCC d'InnoDB est implémenté en enregistrant deux colonnes cachées derrière chaque ligne d'enregistrements. Parmi ces deux colonnes, l'une enregistre l'heure de création de la ligne et l'autre l'heure d'expiration de la ligne. Bien entendu, ce qui est stocké n'est pas la valeur temporelle réelle, mais le numéro de version du système.
L'idée principale de mise en œuvre est de séparer la lecture et l'écriture à travers plusieurs versions de données. Cela permet une lecture déverrouillée et une lecture et une écriture parallèles.
L'implémentation de MVCC dans MySQL repose sur le journal d'annulation et la vue de lecture
- undo log : le journal d'annulation enregistre plusieurs versions d'une certaine ligne de données.
- vue de lecture : utilisée pour déterminer la visibilité de la version actuelle des données
InnoDB utilise une vue de lecture cohérente lors de l'implémentation de MVCC, c'est-à-dire une lecture cohérente view , utilisé pour prendre en charge la mise en œuvre des niveaux d'isolement RC (Read Comended, Read Comended) et RR (Repeatable Read, Repeatable Read).
Sous le niveau d'isolement de lecture répétable, la transaction "prend un instantané" lorsqu'elle démarre.
L'instantané MVCC de MySQL ne copie pas les informations de la base de données à chaque fois qu'une transaction arrive, mais est implémenté en fonction du numéro de version du système enregistré derrière chaque ligne d'informations dans la table de données. Comme le montre la figure ci-dessous, plusieurs versions d'une ligne d'informations coexistent, et chaque transaction peut lire des versions différentes

InnoDB, chaque transaction a un identifiant de transaction unique, c'est ce qu'on appelle l'identifiant de transaction . Il est appliqué au système de transaction InnoDB au début de la transaction et est strictement incrémenté dans l'ordre d'application.
Et chaque ligne de données a également plusieurs versions. Chaque fois qu'une transaction met à jour les données, une nouvelle version des données est générée et l'identifiant de la transaction est attribué à la ligne trx_id de cette version des données. Dans le même temps, l'ancienne version des données doit être conservée et dans la nouvelle version des données, certaines informations peuvent être obtenues directement.
Une ligne d'enregistrements dans la table de données peut en fait avoir plusieurs versions (lignes), et chaque version a sa propre ligne trx_id. Il s'agit de l'état après qu'un enregistrement a été continuellement mis à jour par plusieurs transactions.
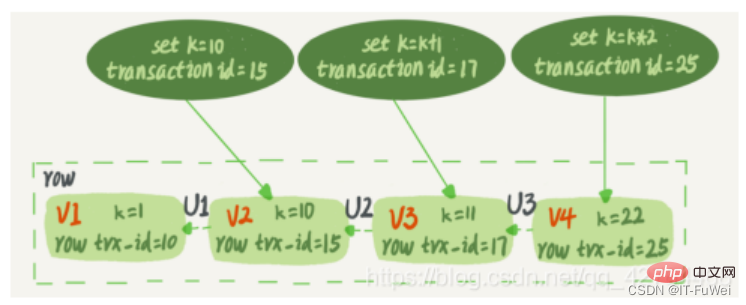
Dans la zone en pointillés de l'image se trouvent 4 versions de la même ligne de données. La dernière version est la V4 et la valeur de k est 22. Elle a été mise à jour par la transaction avec l'identifiant de transaction 25, donc. sa ligne trx_id également 25.
La mise à jour de l'instruction générera-t-elle un journal d'annulation (journal de restauration) ? Alors, où est le journal d'annulation ?
En fait, les trois flèches en pointillés de la figure 2 représentent le journal d'annulation ; V1, V2 et V3 n'existent pas physiquement, mais sont calculés en fonction de la version actuelle et du journal d'annulation à chaque fois qu'ils sont nécessaires. Par exemple, lorsque V2 est nécessaire, il est calculé en exécutant U3 et U2 séquentiellement via V4.
Selon la définition de la lecture répétable, lorsqu'une transaction est démarrée, tous les résultats de la transaction soumise peuvent être vus. Mais ensuite, pendant l’exécution de cette transaction, les mises à jour des autres transactions ne lui sont pas visibles. Par conséquent, une transaction doit uniquement déclarer lorsqu'elle est démarrée : « En fonction du moment où je la démarre, si une version de données est générée avant que je la démarre, elle sera reconnue ; si elle est générée après que je l'ai démarrée, je ne le ferai pas. je le reconnais." , je dois en retrouver la version précédente". Bien sûr, si la « version précédente » n’est pas non plus visible, il faut continuer à regarder vers l’avant. De plus, si les données sont mises à jour par la transaction elle-même, elle doit quand même les reconnaître.
5. Technologie de verrouillage MySQL
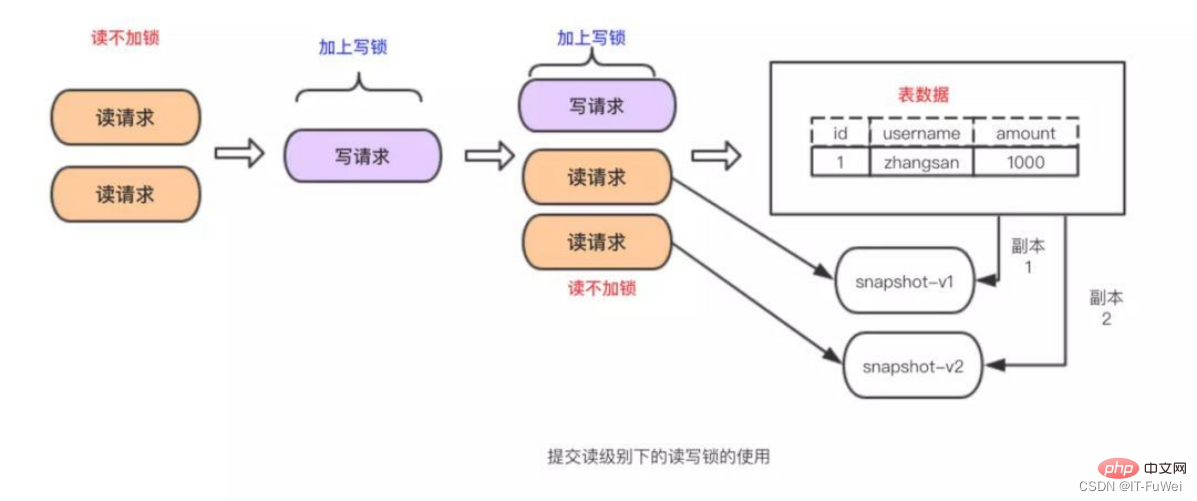
Lorsqu'il y a plusieurs demandes de lecture des données dans la table, aucune action ne peut être entreprise, mais lorsqu'il y a des demandes de lecture et des demandes de modification parmi les multiples demandes, il doit y avoir une mesure pour faites-le. Sinon, des incohérences risquent de se produire. Il est très simple que les verrous en lecture-écriture résolvent les problèmes ci-dessus. Il vous suffit d'utiliser une combinaison de deux verrous pour contrôler les demandes de lecture et d'écriture.
Ces deux verrous sont appelés :
Verrou partagé (verrou partagé). , également connu sous le nom de « Verrou de lecture », le verrou de lecture peut être partagé, ou plusieurs demandes de lecture peuvent partager un verrou pour lire des données sans provoquer de blocage.
Verrou exclusif(verrouillage exclusif), également appelé "verrouillage en écriture". Le verrouillage en écriture exclura toutes les autres demandes d'acquisition du verrou et se bloquera jusqu'à ce que l'écriture soit terminée et que le verrou soit libéré.
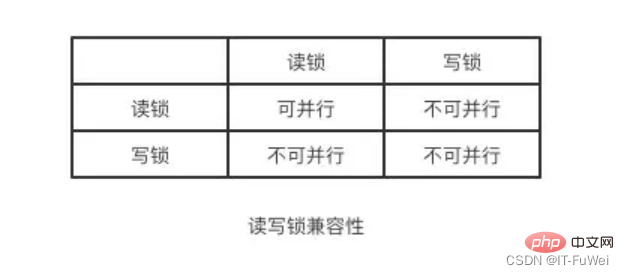
: Grâce aux verrous en lecture-écriture, la lecture et la lecture peuvent être effectuées en parallèle, mais l'écriture et la lecture ne peuvent pas être effectuées en parallèle. L'isolation des transactions est obtenue sur la base de verrous en lecture-écriture ! ! !
Apprentissage recommandé : Tutoriel vidéo mysql
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!