
Maison >base de données >tutoriel mysql >Organiser et résumer cinq solutions MySQL haute disponibilité courantes
Organiser et résumer cinq solutions MySQL haute disponibilité courantes

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-05-31 11:56:183002parcourir
Cet article vous apporte des connaissances pertinentes sur mysql, qui présente principalement les problèmes liés aux solutions à haute disponibilité courantes. Nous discutons ici uniquement des avantages et des inconvénients des solutions à haute disponibilité couramment utilisées et de la sélection des solutions à haute disponibilité. jetez un œil, j’espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo MySQL
1 Présentation
Lorsque nous considérons l'architecture à haute disponibilité de la base de données MySQL, nous devons principalement considérer les aspects suivants :
- Si la base de données est en panne. ou inattendu En cas d'interruptions et d'autres pannes, la disponibilité de la base de données peut être restaurée le plus rapidement possible et les temps d'arrêt peuvent être réduits autant que possible pour garantir que l'activité ne sera pas interrompue en raison de pannes de base de données.
- Les données des nœuds non principaux utilisés pour des fonctions telles que la sauvegarde et les répliques en lecture seule doivent être cohérentes avec les données du nœud principal en temps réel ou éventuellement.
- Lorsqu'un changement de base de données se produit dans l'entreprise, le contenu de la base de données avant et après le changement doit être cohérent, et l'entreprise ne sera pas affectée en raison de données manquantes ou de données incohérentes.
Nous ne discuterons pas ici en détail de la classification de la haute disponibilité. Nous discuterons uniquement des avantages et des inconvénients des solutions de haute disponibilité couramment utilisées et de la sélection de solutions de haute disponibilité.
2. Solution haute disponibilité
2.1. Réplication semi-synchrone maître-esclave ou maître-maître
Utilisez une base de données à deux nœuds pour créer une réplication semi-synchrone unidirectionnelle ou bidirectionnelle. Dans les versions postérieures à la 5.7, l'introduction d'une série de nouvelles fonctionnalités telles que la réplication sans perte et la réplication logique multithread rend la réplication semi-synchrone native de MySQL plus fiable.
L'architecture commune est la suivante : 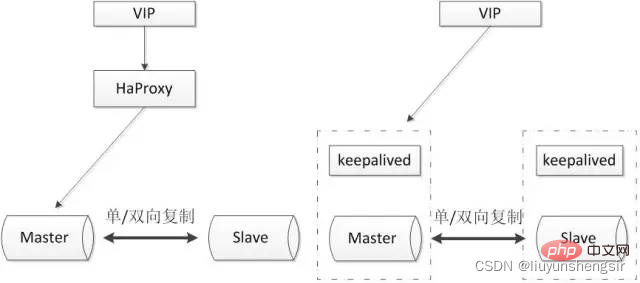
Elle est généralement utilisée avec des logiciels tiers tels que proxy et keepalived. Elle peut être utilisée pour surveiller la santé de la base de données et exécuter une série de commandes de gestion. Si la base de données principale tombe en panne, elle peut toujours être utilisée après le passage à la base de données de secours.
Avantages :
- L'architecture est relativement simple, utilisant la réplication semi-synchrone native comme base pour la synchronisation des données ;
- Double nœud, il n'y a pas de problème de sélection de maître une fois l'hôte en panne, il suffit de basculer directement
- ; Double nœud, nécessitant moins de ressources, déploiement simple ;
Inconvénients :
- repose entièrement sur la réplication semi-synchrone si la réplication semi-synchrone se dégrade en réplication asynchrone, la cohérence des données ne peut pas être garantie ; donné aux mécanismes de haute disponibilité de haproxy et keepalived.
- 2.2. Optimisation de la réplication semi-synchrone
Le mécanisme de réplication semi-synchrone est fiable. Si la réplication semi-synchrone est toujours effective, les données peuvent être considérées comme cohérentes. Cependant, pour des raisons objectives telles que les fluctuations du réseau, l'expiration des délais de réplication semi-synchrone et le passage à la réplication asynchrone, la cohérence des données ne peut pas être garantie. Par conséquent, assurer autant que possible une réplication semi-synchrone peut améliorer la cohérence des données.
Cette solution utilise également une architecture à double nœud, mais dispose d'optimisations fonctionnelles basées sur la réplication semi-synchrone d'origine, rendant le mécanisme de réplication semi-synchrone plus fiable.
Les plans d'optimisation auxquels vous pouvez vous référer sont les suivants :
2.2.1. Réplication double canal La réplication semi-synchrone est déconnectée après un délai d'attente. Lorsque la réplication est à nouveau établie, deux canaux sont établis. en même temps. Un canal de copie semi-synchrone commence la copie à partir de la position actuelle pour garantir que l'esclave connaît la progression de l'exécution actuelle de l'hôte. Un autre canal de réplication asynchrone commence à rattraper les données en retard de l'esclave. Lorsque le canal de réplication asynchrone rattrape la position de départ de la réplication semi-synchrone, la réplication semi-synchrone reprend. 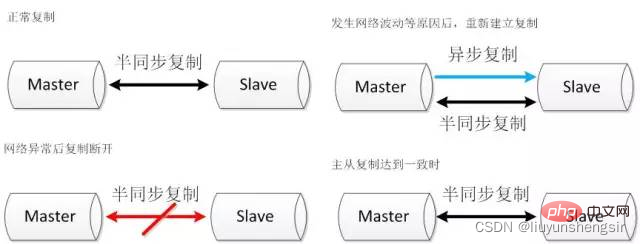
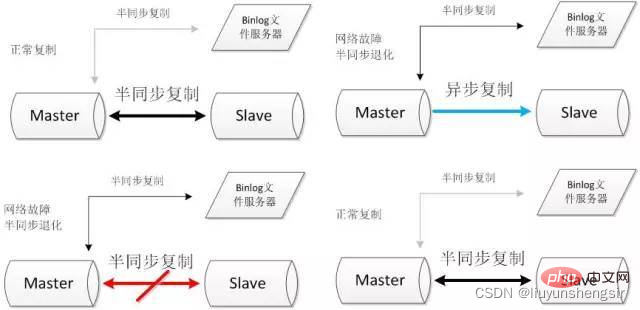 Construisez deux canaux de réplication semi-synchrone Le canal semi-synchrone connectant le serveur de fichiers n'est pas activé dans des circonstances normales lorsque la réplication semi-synchrone maître-esclave se dégrade. en raison de problèmes de réseau, démarrez un canal de réplication semi-synchrone vers le serveur de fichiers. Une fois la réplication semi-synchrone maître-esclave reprise, fermez le canal de réplication semi-synchrone avec le serveur de fichiers.
Construisez deux canaux de réplication semi-synchrone Le canal semi-synchrone connectant le serveur de fichiers n'est pas activé dans des circonstances normales lorsque la réplication semi-synchrone maître-esclave se dégrade. en raison de problèmes de réseau, démarrez un canal de réplication semi-synchrone vers le serveur de fichiers. Une fois la réplication semi-synchrone maître-esclave reprise, fermez le canal de réplication semi-synchrone avec le serveur de fichiers.
Avantages :
Nœuds doubles, moins de besoins en ressources, déploiement simple ;
Architecture simple, pas de problème de sélection du maître, il suffit de changer directement ; Par rapport à la réplication native, la réplication semi-synchrone optimisée peut mieux garantir la cohérence des données.
Inconvénients :
Besoin de modifier le code source du noyau ou d'utiliser le protocole de communication mysql. Vous devez avoir une certaine compréhension du code source et être capable de faire un certain degré de développement secondaire.
S'appuie toujours sur une réplication semi-synchrone, ce qui ne résout pas fondamentalement le problème de cohérence des données.
2.3. Optimisation de l'architecture haute disponibilité
Étendez la base de données à deux nœuds à une base de données multi-nœuds ou à un cluster de bases de données multi-nœuds. Vous pouvez choisir un cluster avec un maître et deux esclaves, un maître et plusieurs esclaves, ou plusieurs maîtres et plusieurs esclaves selon vos besoins.
En raison de la réplication semi-synchrone, il existe une caractéristique selon laquelle la réplication semi-synchrone est considérée comme réussie lorsqu'une réponse réussie d'un esclave est reçue. Par conséquent, la fiabilité de la réplication semi-synchrone multi-esclave est meilleure que la fiabilité de la réplication semi-synchrone. réplication semi-synchrone esclave. Et la probabilité que plusieurs nœuds tombent en panne en même temps est inférieure à la probabilité qu'un seul nœud tombe en panne. Par conséquent, dans une certaine mesure, l'architecture multi-nœuds peut être considérée comme ayant une disponibilité plus élevée que l'architecture à deux nœuds.
Cependant, en raison du grand nombre de bases de données, un logiciel de gestion de bases de données est nécessaire pour assurer la maintenabilité de la base de données. Vous pouvez choisir MMM, MHA ou différentes versions de proxy, etc. Les solutions courantes sont les suivantes :
2.3.1. MHA + cluster multi-nœuds
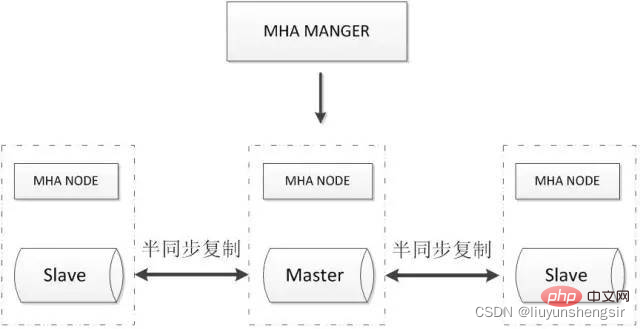
MHA Manager détectera régulièrement le nœud maître dans le cluster. Lorsque le maître échoue, il peut automatiquement promouvoir l'esclave avec la dernière version. données vers le nouveau maître, puis redirigez tous les autres esclaves vers le nouveau maître. L'ensemble du processus de basculement est totalement transparent pour l'application.
MHA Node s'exécute sur chaque serveur MySQL. Sa fonction principale est de traiter les journaux binaires pendant le basculement pour garantir que le basculement minimise la perte de données.
MHA peut également être étendu aux clusters multi-nœuds suivants : 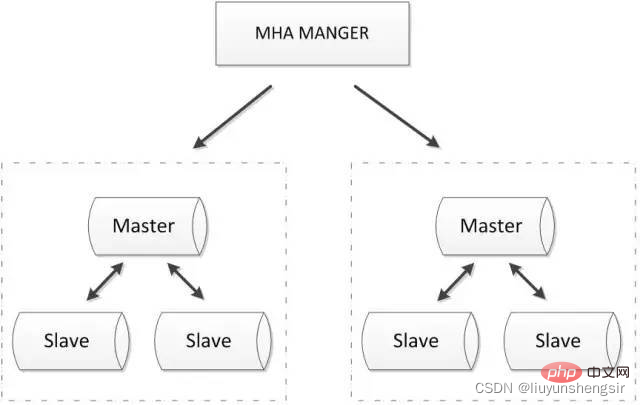
Avantages :
peut détecter et transférer automatiquement les défauts
Bonne évolutivité, le nombre et la structure des nœuds MySQL peuvent être étendus selon les besoins ; réplication MySQL à deux nœuds, MySQL à trois nœuds/multi-nœuds a une probabilité plus faible d'être indisponible
La logique est plus complexe et après une panne Il est plus difficile de dépanner et de localiser les problèmes ;
La cohérence des données est toujours garantie par la réplication semi-synchrone native, et il existe toujours un risque d'incohérence des données
Un phénomène de split-brain peut survenir en raison des partitions réseau ;
Zookeeper utilise des algorithmes distribués pour garantir la cohérence des données du cluster. L'utilisation de zookeeper peut garantir efficacement la haute disponibilité du proxy et mieux éviter les partitions réseau.
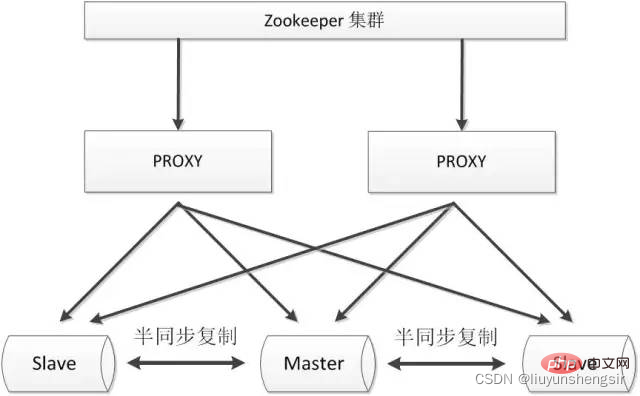 Avantages :
Avantages :
garantit mieux la haute disponibilité de l'ensemble du système, y compris le proxy, MySQL ;
Bonne évolutivité et peut être étendu à des clusters à grande échelle
Inconvénients :
La cohérence des données dépend toujours de MySQL natif ; réplication semi-synchrone ;
Avec l'introduction de zk, la logique de l'ensemble du système devient plus complexe ;
2.4. Stockage partagé
Le stockage partagé réalise le découplage des serveurs de base de données et des périphériques de stockage, et la synchronisation des données entre différentes bases de données n'est pas possible. plus Il s'appuie sur la fonction de réplication native de MySQL, mais utilise la synchronisation des données sur disque pour garantir la cohérence des données.
2.4.1. Stockage partagé SANLe concept du SAN est de permettre une connexion réseau directe à haut débit (par rapport au LAN) entre les périphériques de stockage et les processeurs (serveurs), à travers lequel les données peuvent être centralisées. Les architectures couramment utilisées sont les suivantes :
Lors de l'utilisation du stockage partagé, le serveur MySQL peut monter le système de fichiers et fonctionner normalement. Si la base de données principale tombe en panne, la base de données de secours peut monter le même système de fichiers pour garantir que la base de données principale tombe en panne. et la base de données de secours utilisent les mêmes données. 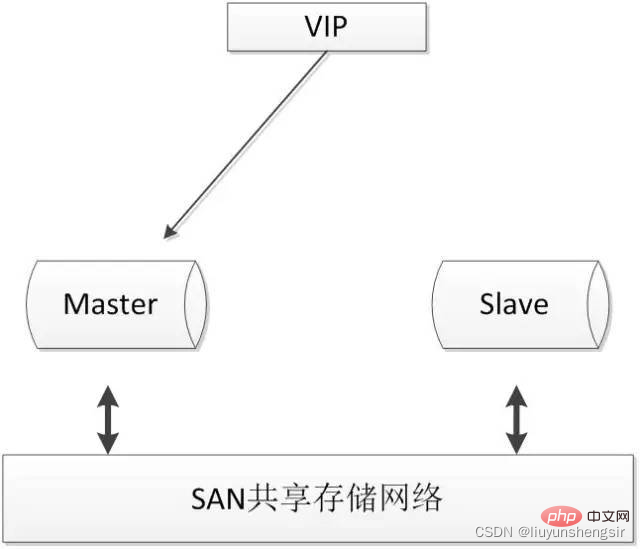
Avantages :
Seulement deux nœuds, déploiement simple, logique de commutation simple ;
Très bonne garantie d'une forte cohérence des données Aucune incohérence des données ne se produira en raison d'erreurs logiques dans MySQL ;
Inconvénients :
Obligatoire ; disponibilité du stockage partagé ;
Cher ;DRBD est une solution de stockage de réplication de blocs basée sur un logiciel, principalement utilisée pour les disques, les partitions, les volumes logiques, etc. mise en miroir. Lorsque l'utilisateur écrit des données sur le disque local, les données seront également envoyées sur le disque d'un autre hôte du réseau. De cette manière, l'hôte local (nœud principal) et l'hôte distant (nœud de secours) peuvent. assurer la synchronisation en temps réel. L'architecture couramment utilisée est la suivante :
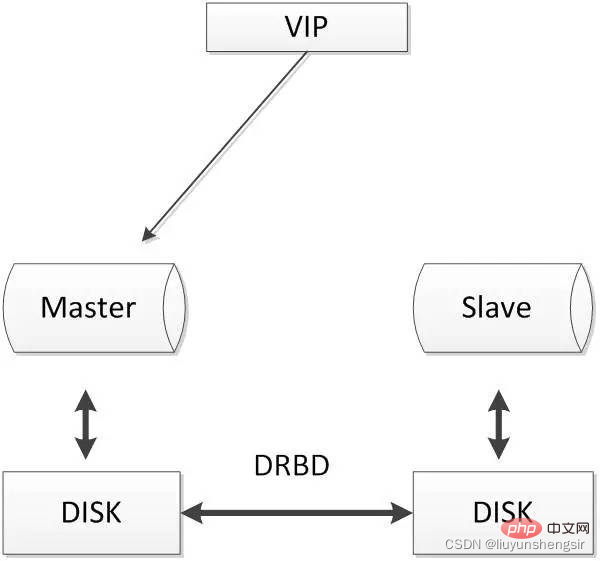 Lorsqu'il y a un problème avec l'hôte local, les mêmes données sont toujours conservées sur l'hôte distant et peuvent continuer à être utilisées, garantissant ainsi la sécurité des données.
Lorsqu'il y a un problème avec l'hôte local, les mêmes données sont toujours conservées sur l'hôte distant et peuvent continuer à être utilisées, garantissant ainsi la sécurité des données.
DRBD est une technologie de réplication synchrone de niveau rapide implémentée par le module du noyau Linux, qui peut obtenir le même effet de stockage partagé que SAN.
Avantages :
Seulement deux nœuds, déploiement simple, logique de commutation simple ;
Par rapport au réseau de stockage SAN, prix basGarantir une forte cohérence des données
Inconvénients :
A un plus grand impact sur les performances io ; la bibliothèque esclave ne fournit pas d'opérations de lecture ;
2.5 Protocole distribué
2.5.1. Cluster MySQL
Le cluster MySQL est la solution officielle de déploiement de cluster. Il utilise le moteur de stockage NDB pour sauvegarder les données redondantes en temps réel afin d'obtenir une haute disponibilité et une cohérence des données de la base de données. 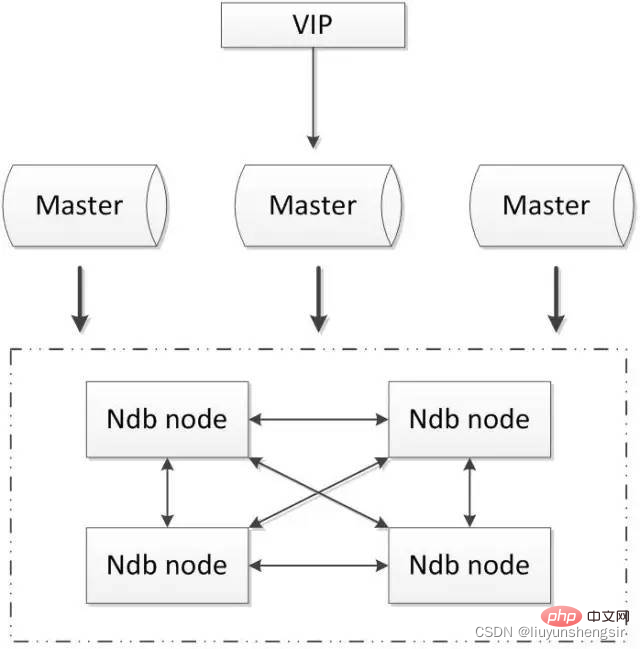
Avantages :
Tous utilisent des composants officiels et ne s'appuient pas sur des logiciels tiers ;
Peut atteindre une forte cohérence des données ;
Inconvénients :
Peu utilisé en Chine
La configuration est complexe et nécessite l'utilisation ; de stockage NDB Le moteur est quelque peu différent du moteur MySQL classique ;
Au moins trois nœuds
2.5.2 Galera
Le cluster haute disponibilité MySQL basé sur Galera est une solution de cluster MySQL pour la synchronisation des données multi-maîtres. . Il est simple à utiliser et n'a pas de point de défaillance unique, haute disponibilité. Les architectures courantes sont les suivantes :
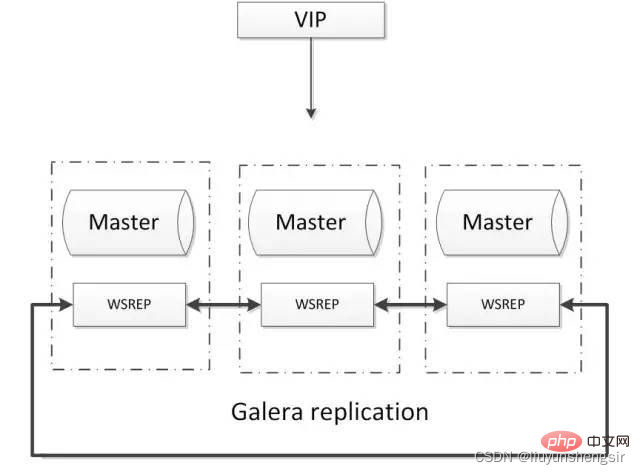
Avantages :
Écriture multi-maître, réplication sans délai, garantissant une forte cohérence des données
Il existe une communauté mature et les sociétés Internet l'utilisent à grande échelle ; basculement, ajout et suppression automatiques de nœuds ;
Prend uniquement en charge le moteur de stockage innodb
Au moins trois nœuds ;
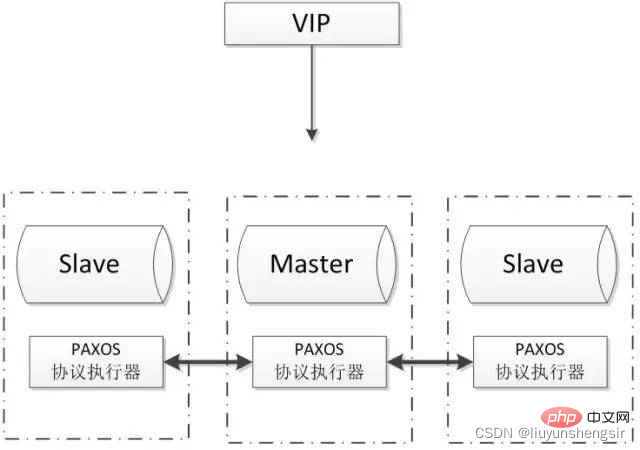 Avantages :
Avantages :
Possède une base théorique mature ;
Basculement automatique, ajout et suppression automatiques de nœuds ;
Prend uniquement en charge le moteur de stockage innodb
À mesure que les exigences des utilisateurs en matière de cohérence des données continuent d'augmenter, de plus en plus de méthodes sont essayées pour résoudre le problème de la cohérence des données distribuées, telles que l'optimisation de. MySQL lui-même, l'optimisation de l'architecture du cluster MySQL, l'introduction de Paxos, Raft, l'algorithme 2PC, etc.
La méthode d'utilisation d'algorithmes distribués pour résoudre le problème de la cohérence des données des bases de données MySQL est de plus en plus acceptée par les gens. Une série de produits matures tels que PhxSQL, MariaDB Galera Cluster, Percona XtraDB Cluster, etc. populaire. Utilisé à grande échelle.
Avec l'AG officielle de MySQL Group Replication, l'utilisation de protocoles distribués pour résoudre les problèmes de cohérence des données est devenue une tendance dominante. On s'attend à ce que de plus en plus d'excellentes solutions soient proposées et que le problème de haute disponibilité de MySQL puisse être mieux résolu.
Apprentissage recommandé :
Tutoriel vidéo mysqlCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!