
Maison >interface Web >js tutoriel >Maîtriser complètement le mécanisme de fonctionnement et les principes de JavaScript
Maîtriser complètement le mécanisme de fonctionnement et les principes de JavaScript

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-04-25 17:05:203300parcourir
Cet article vous apporte des connaissances pertinentes sur javascript. Il présente principalement les problèmes liés au mécanisme de fonctionnement et aux principes de JavaScript, y compris les moteurs d'analyse et d'autres contenus. J'espère qu'il sera utile à tout le monde.

[Recommandations associées : tutoriel vidéo javascript, front-end web]
J'écris du js depuis plus de deux ans et je n'ai jamais compris son mécanisme de fonctionnement et ses principes. Aujourd'hui, j'ai spécialement mis. réunissant les théories et les principes des maîtres. Mon résumé est enregistré ci-dessous :
Qu'est-ce qu'un moteur d'analyse JavaScript
En termes simples, un moteur d'analyse JavaScript est un programme qui peut "lire" le code JavaScript et donner avec précision les résultats de. l'exécution du code.
Par exemple, lorsque vous écrivez un morceau de code comme var a = 1 + 1;, le moteur JavaScript fait pour comprendre (analyser) votre code et changer la valeur de a en 2.
Ceux qui ont étudié les principes de la compilation savent que pour les langages statiques(tels que Java, C++, C), celui qui gère les choses ci-dessus s'appelle un compilateur (Compiler), et par conséquent pour les langages dynamiques comme JavaScript, cela s'appelle un interprète (Interpreter) ). La différence entre les deux peut être résumée en une phrase : le compilateur compile le code source dans un autre type de code (tel que le code machine ou le bytecode), tandis que l'interpréteur analyse et génère directement les résultats de l'exécution du code. Par exemple, la console de Firebug est un interpréteur JavaScript.
Cependant, il est difficile de définir maintenant si le moteur JavaScript est un interpréteur ou un compilateur, car, par exemple, le V8 (le moteur JS de Chrome) en fait, afin d'améliorer les performances d'exécution de JS, va d'abord compiler JS en natif code machine, puis exécutez le code machine (c'est beaucoup plus rapide).
Quelle est la relation entre le moteur d'analyse JavaScript et ECMAScript ?
Le moteur JavaScript est un programme, et le code JavaScript que nous écrivons est également un programme. Comment faire comprendre le programme ? Cela nécessite de définir des règles. Par exemple, la var a = 1 + 1 ; mentionnée précédemment, cela signifie :
La var à gauche représente une déclaration, qui déclare la variable a
Le + à droite représente l'addition de 1 et 1
Le milieu Le le signe égal indique qu'il s'agit d'une instruction d'affectation
Le point-virgule final indique la fin de cette instruction
Ce sont les règles Avec elles, il existe une norme de mesure. Le moteur JavaScript peut analyser le code JavaScript selon cette norme. Ensuite, l'ECMAScript définit ici ces règles. Parmi eux, le document ECMAScript 262 définit un ensemble complet de standards pour le langage JavaScript. Ceux-ci incluent :
var, if, else, break, continue, etc. sont des mots-clés JavaScript
abstract, int, long, etc. sont des mots réservés JavaScript
Comment compter comme un nombre, comment compter comme une chaîne, etc.
Définit l'opérateur ( +, -, >, définit la syntaxe de JavaScript
définit les algorithmes de traitement standard pour les expressions, les instructions, etc., comme comment gérer ==
⋯⋯
La norme Le moteur JavaScript utilisera Pour implémenter cet ensemble de documents, notez que les normes sont mises en avant ici, car il existe également des implémentations qui ne suivent pas les normes, comme le moteur JS d'IE. C'est pourquoi JavaScript présente des problèmes de compatibilité. Quant à savoir pourquoi le moteur JS d'IE n'est pas implémenté conformément aux normes, il s'agit de la guerre des navigateurs, je n'entrerai pas dans les détails ici.
Donc, en termes simples, ECMAScript définit le standard du langage, et le moteur JavaScript l'implémente en fonction de celui-ci. C'est la relation entre les deux.
Quelle est la relation entre le moteur d'analyse JavaScript et le navigateur
En termes simples, le moteur JavaScript est l'un des composants du navigateur ? Parce que le navigateur doit faire beaucoup d'autres choses, comme l'analyse des pages, le rendu des pages, la gestion des cookies, les enregistrements d'historique, etc. Eh bien, puisqu'il s'agit d'un composant, les moteurs JavaScript sont généralement développés par les développeurs de navigateurs eux-mêmes. Par exemple : Chakra de IE9, TraceMonkey de Firefox, V8 de Chrome, etc.
On peut également constater que différents navigateurs utilisent différents moteurs JavaScript. Donc, tout ce que nous pouvons dire, c'est de quel moteur JavaScript il faut mieux comprendre.
Pourquoi JavaScript est monothread
Une caractéristique majeure du langage JavaScript est qu'il est monothread, c'est-à-dire qu'il ne peut faire qu'une seule chose à la fois. Alors pourquoi JavaScript ne peut-il pas avoir plusieurs threads ? Cela peut améliorer l’efficacité.
JavaScript est monothread, selon son objectif. En tant que langage de script de navigateur, l'objectif principal de JavaScript est d'interagir avec les utilisateurs et de manipuler le DOM. Cela détermine qu'il ne peut être qu'un seul thread, sinon cela entraînera des problèmes de synchronisation très complexes. Par exemple, supposons que JavaScript ait deux threads en même temps. Un thread ajoute du contenu à un certain nœud DOM et l'autre thread supprime le nœud. Dans ce cas, quel thread le navigateur doit-il utiliser ?
Ainsi, afin d'éviter toute complexité, JavaScript est monothread depuis sa naissance. Cela est devenu la fonctionnalité principale de ce langage et ne changera pas à l'avenir.
Afin de profiter de la puissance de calcul des CPU multicœurs, HTML5 propose le standard Web Worker, qui permet aux scripts JavaScript de créer plusieurs threads, mais les threads enfants sont entièrement contrôlés par le thread principal et ne doivent pas faire fonctionner le DOM. . Par conséquent, cette nouvelle norme ne modifie pas la nature monothread de JavaScript.
Distinguer les processus et les threads
Un processus est la plus petite unité d'allocation de ressources CPU, et un processus peut contenir plusieurs threads. Les navigateurs sont multi-processus et chaque fenêtre de navigateur ouverte est un processus.
Le thread est la plus petite unité de planification du processeur. L'espace mémoire du programme est partagé entre les threads du même processus.
Vous pouvez considérer le processus comme un entrepôt, et le fil conducteur est un camion qui peut être transporté. Chaque entrepôt a ses propres camions pour desservir l'entrepôt (chaque entrepôt peut être tiré par plusieurs véhicules en même temps). temps, mais chaque entrepôt peut tirer des marchandises en même temps. Un véhicule ne peut faire qu'une seule chose à la fois, c'est-à-dire transporter cette marchandise.
Point central :
Un processus est la plus petite unité d'allocation de ressources CPU (la plus petite unité qui peut posséder des ressources et s'exécuter de manière indépendante)
Le thread est la plus petite unité de planification du CPU (un thread est un programme basé sur un process) Unité en cours d'exécution, il peut y avoir plusieurs threads dans un seul processus)
Différents processus peuvent également communiquer, mais le coût est plus élevé.
Les navigateurs sont multi-processus
Après avoir compris la différence entre les processus et les threads, ayons une certaine compréhension des navigateurs : (Regardons d'abord la compréhension simplifiée)
Les navigateurs sont multi-processus
La raison pour laquelle les navigateurs sont Il peut s'exécuter car le système alloue des ressources (cpu, mémoire) à son processus, pour faire simple, chaque fois qu'une page à onglet est ouverte, cela équivaut à créer un processus de navigateur indépendant.
Prenons Chrome comme exemple. Il comporte plusieurs pages à onglet et vous pouvez voir plusieurs processus dans le gestionnaire de tâches de Chrome (chaque page à onglet a un processus indépendant et un processus principal sous Windows, cela peut également être vu dans le gestionnaire de tâches). .
Remarque : le navigateur doit également disposer de son propre mécanisme d'optimisation. Parfois, après avoir ouvert plusieurs pages à onglets, vous pouvez voir dans le gestionnaire de tâches Chrome que certains processus sont fusionnés (de sorte que chaque étiquette d'onglet ne correspond pas à un processus). être absolu)
Quels processus le navigateur contient-il ?
Après avoir su que le navigateur est un multi-processus, regardons quels processus il contient : (Pour simplifier la compréhension, seuls les processus principaux sont répertoriés)
( 1) Processus du navigateur : Il n'y a qu'un seul processus principal du navigateur (responsable de la coordination et du contrôle). Rôle :
Responsable de l'affichage de l'interface du navigateur et de l'interaction avec les utilisateurs. Tels que l'avant, l'arrière, etc.- Responsable de la gestion de chaque page, de la création et de la destruction d'autres processus
- Dessine le Bitmap dans la mémoire obtenue par le processus Renderer vers l'interface utilisateur
- Gestion des ressources réseau, des téléchargements, etc.
- (2) Processus de plug-in tiers : Chaque type de plug-in correspond à un processus, qui n'est créé que lorsque le plug-in est utilisé
(4) Processus de rendu du navigateur (noyau du navigateur, processus de rendu, multithread en interne) : par défaut, chaque page à onglets a un processus et ne s'affecte pas les uns les autres. Les principales fonctions sont : le rendu des pages, l'exécution de scripts, le traitement des événements, etc.
Améliorer la mémoire : ouvrir une page web dans le navigateur équivaut à démarrer un nouveau processus (le processus a ses propres multi-threads)
Bien sûr, le navigateur parfois Fusionner plusieurs processus (par exemple, après avoir ouvert plusieurs onglets vides, vous constaterez que plusieurs onglets vides ont été fusionnés en un seul processus)
Avantages des navigateurs multi-processus
Par rapport aux navigateurs à processus unique, les multi-processus sont comme suit Avantages :
Évitez le crash d'une seule page affectant l'ensemble du navigateur- Évitez les crashs de plug-ins tiers affectant l'ensemble du navigateur
- Plusieurs processus exploitent pleinement les avantages multicœurs
- Utilisez facilement le modèle sandbox pour isoler le plug-in et d'autres processus pour améliorer la stabilité du navigateur
- Compréhension simple :
Si le navigateur est un processus unique, le crash d'une certaine page à onglet affectera l'ensemble du navigateur, la mauvaise expérience sera de la même manière, s'il s'agit d'un processus unique, le crash du plug-in affectera également l'ensemble du navigateur .
Bien sûr, la consommation de mémoire et d'autres ressources sera également plus importante, ce qui signifie que l'espace est échangé contre du temps. Quelle que soit la taille de la mémoire, ce n'est pas suffisant pour Chrome. Le problème de fuite de mémoire a maintenant été légèrement amélioré. Il ne s'agit que d'une amélioration, qui entraînera également une augmentation de la consommation d'énergie.
Noyau du navigateur (processus de rendu)
Voici le point clé. Nous pouvons voir qu'il y a tellement de processus mentionnés ci-dessus. Alors, pour les opérations frontales ordinaires, quelle est l'exigence finale ? La réponse est le processus de rendu.
On peut comprendre que le rendu de la page, l'exécution de JS et la boucle d'événements sont tous effectués au sein de ce processus. Ensuite, concentrez-vous sur l'analyse de ce processus
Veuillez garder à l'esprit que le processus de rendu du navigateur est multithread (le moteur JS est monothread)Jetons ensuite un œil aux threads qu'il contient (listez quelques principaux résidents fils de discussion ):
1. Le fil de rendu GUI
- est responsable du rendu de l'interface du navigateur, de l'analyse HTML, CSS, de la construction de l'arborescence DOM et de l'arborescence RenderObject (simplement comprise comme l'arborescence de styles formée par CSS, l'un des cœurs de Flutter), de la mise en page et du dessin. , etc.
- Lorsque l'interface doit être repeinte (Repaint) ou qu'une redistribution est provoquée par une certaine opération, ce fil sera exécuté
- Notez que le fil de rendu de l'interface graphique et le fil du moteur JS s'excluent mutuellement lors de l'exécution du moteur JS. , le thread GUI sera suspendu (gelé) et les mises à jour de l'interface graphique seront enregistrées dans une file d'attente et exécutées immédiatement lorsque le moteur JS est inactif.
2. Le thread du moteur JS
- est également appelé noyau JS et est responsable du traitement des programmes de script Javascript. (Par exemple, le moteur V8)
- Le thread du moteur JS est responsable de l'analyse des scripts Javascript et de l'exécution du code.
- Le moteur JS attend l'arrivée des tâches dans la file d'attente des tâches, puis les traite à tout moment. Il n'y a qu'un seul thread JS exécutant le programme JS dans une page à onglets (processus de rendu).
- Notez également que le Fil de rendu de l'interface graphique et fil du moteur JS Ils s'excluent mutuellement, donc si le temps d'exécution de JS est trop long, le rendu de la page sera incohérent, provoquant le blocage du rendu et du chargement de la page.
3. Le fil de déclenchement d'événement
- appartient au navigateur plutôt qu'au moteur JS et est utilisé pour contrôler la boucle d'événement (il est compréhensible que le moteur JS lui-même soit trop occupé et ait besoin que le navigateur ouvre un autre fil pour assist)
- Lorsque le moteur JS Lorsqu'un bloc de code tel que setTimeOut doit être exécuté (il peut également provenir d'autres threads du noyau du navigateur, comme les clics de souris, les requêtes asynchrones Ajax, etc.), la tâche correspondante sera ajouté au fil de l'événement. Et sera responsable du tri
- Lorsque l'événement correspondant remplit les conditions de déclenchement et est déclenché, le thread ajoutera l'événement à la fin de la file d'attente en attente et attendra son traitement par le moteur JS
- Notez qu'en raison du seul- relation threadée de JS, ces événements en attente Tous les événements de la file d'attente doivent être mis en file d'attente pour attendre leur traitement par le moteur JS (il sera exécuté lorsque le moteur JS sera inactif)
- On peut simplement comprendre qu'il est responsable de la gestion d'un un tas d'événements et une "file d'attente d'événements". Seules les tâches dans la file d'attente d'événements Le moteur JS s'exécutera lorsqu'il est inactif, et ce qu'il doit faire est de l'ajouter à la file d'attente d'événements lorsqu'un événement est déclenché. Par exemple, cliquez avec la souris.
4. Fil de déclenchement du timing
- Le fil où se trouvent les légendaires setInterval et setTimeout
- Le compteur de timing du navigateur n'est pas compté par le moteur JavaScript (car le moteur JavaScript est monothread, s'il est dans un bloc bloqué (état du thread, cela affectera la précision du timing)
- Par conséquent, un thread séparé est utilisé pour chronométrer et déclencher le timing. Une fois le timing terminé, il est ajouté à la file d'attente des événements (correspondant à "lorsque l'événement atteint le timing". conditions de déclenchement et est déclenché" du thread de déclenchement d'événement), et attend que le moteur JS devienne inactif.
- Notez que le W3C stipule dans la norme HTML que l'intervalle de temps inférieur à 4 ms dans setTimeout est compté pour 4 ms.
5. Fil de requête http asynchrone
- Dans XMLHttpRequest, une nouvelle demande de fil est ouverte via le navigateur après la connexion
- Lorsqu'un changement de statut est détecté, si une fonction de rappel est définie, le fil asynchrone générera un statut change event, qui Ce rappel est ensuite placé dans la file d'attente des événements. Puis exécuté par le moteur JavaScript.
Le processus de communication entre le processus du navigateur et le noyau du navigateur (processus de rendu)
En voyant cela, tout d'abord, vous devez avoir une certaine compréhension des processus et des threads du navigateur. Ensuite, parlons du navigateur du navigateur. Une fois que vous avez compris comment le processus (processus de contrôle) communique avec le noyau, vous pouvez relier cette partie des connaissances entre elles pour avoir un concept complet du début à la fin.
Si vous ouvrez le gestionnaire de tâches puis ouvrez un navigateur, vous pouvez voir : deux processus apparaissent dans le gestionnaire de tâches (l'un est le processus de contrôle principal, l'autre est le processus de rendu qui ouvre la page Onglet), et puis ici Sous En principe, examinons l'ensemble du processus : (C'est beaucoup simplifié)
- Lorsque le processus du navigateur reçoit une demande de l'utilisateur, il doit d'abord obtenir le contenu de la page (comme le téléchargement de ressources via le réseau), puis transmet la tâche à Render (noyau) via l'interface RendererHost. L'interface Renderer du processus
- Renderer reçoit le message, l'explique brièvement, le transmet au thread de rendu, puis commence le rendu
- Le thread de rendu reçoit le demande, charge la page Web et restitue la page Web, ce qui peut nécessiter le processus du navigateur pour obtenir des ressources et le processus GPU pour aider au rendu
- Bien sûr, il peut y avoir des threads JS pour faire fonctionner le DOM (cela peut provoquer une redistribution et un redessin)
- Enfin, le processus de rendu transmet les résultats au processus du navigateur
- Le processus du navigateur reçoit les résultats et dessine les résultats
Voici une image simple : (très simplifiée) 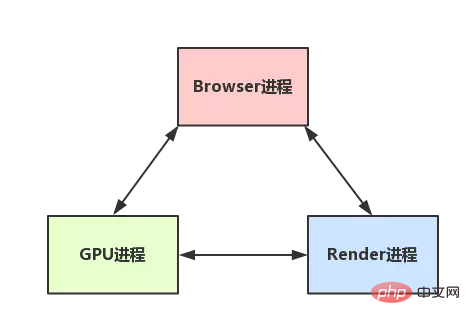
La relation entre les threads dans le noyau du navigateur
À ce stade, nous avons une idée globale du fonctionnement du navigateur. Ensuite, commencez par trier simplement quelques concepts
.Le thread de rendu GUI et le thread du moteur JS s'excluent mutuellement
Puisque JavaScript peut manipuler le DOM, si vous modifiez les attributs de ces éléments lors du rendu de l'interface (c'est-à-dire que le thread JS et le thread UI s'exécutent en même temps ), alors les données d'élément obtenues avant et après le thread de rendu peuvent être incohérentes.
Ainsi, afin d'éviter des résultats de rendu inattendus, le navigateur définit le thread de rendu de l'interface graphique et le moteur JS pour qu'ils aient une relation mutuellement exclusive. Lorsque le moteur JS est exécuté, le thread de rendu de l'interface graphique sera suspendu et les mises à jour de l'interface graphique seront enregistrées dans. une file d'attente jusqu'à ce que le thread du moteur JS soit exécuté immédiatement lorsqu'il est inactif.
JS bloque le chargement de la page
De la relation mutuellement exclusive ci-dessus, on peut déduire que JS bloquera la page si son exécution prend trop de temps.
Par exemple, en supposant que le moteur JS effectue une énorme quantité de calculs, même si l'interface graphique est mise à jour à ce moment-là, elle sera enregistrée dans la file d'attente et attendra son exécution lorsque le moteur JS sera inactif. Ensuite, en raison de l'énorme quantité de calculs, le moteur JS est susceptible de rester inactif pendant très, très longtemps, et naturellement il semblera extrêmement énorme.
Alors, essayez d'éviter que l'exécution de JS ne prenne trop de temps, ce qui entraînerait un rendu incohérent de la page, donnant l'impression que le rendu et le chargement de la page sont bloqués.
Pour résoudre ce problème, en plus de placer le calcul sur le backend, s'il ne peut être évité et que l'énorme calcul est lié à l'interface utilisateur, alors mon idée est d'utiliser setTimeout pour diviser la tâche et donner du temps libre dans le milieu pour le moteur JS Allez vous occuper de l'interface utilisateur pour que la page ne reste pas bloquée directement.
Si vous décidez directement de la version HTML5+ minimale requise, vous pouvez jeter un œil au WebWorker ci-dessous.
WebWorker, multi-threading de JS
Comme mentionné dans l'article précédent, le moteur JS est mono-thread, et si le temps d'exécution du JS est trop long, il bloquera la page. Alors, JS est-il vraiment impuissant. contre les calculs gourmands en CPU ?
Ainsi, les Web Workers ont ensuite été pris en charge en HTML5. L'explication officielle de
MDN est la suivante :
Web Worker fournit un moyen simple d'exécuter des scripts dans un fil d'arrière-plan pour le contenu Web.
Les threads peuvent effectuer des tâches sans interférer avec l'interface utilisateur. Un travailleur est un objet créé à l'aide d'un constructeur (Worker()) qui exécute un fichier JavaScript nommé (ce fichier contient le code qui sera exécuté dans le thread de travail).
Les travailleurs fonctionnent dans un autre contexte global, différent de la fenêtre actuelle.
Par conséquent, utiliser le raccourci de fenêtre pour obtenir la portée globale actuelle (au lieu de soi) renverra une erreur au sein d'un Worker
Comprenez-le de cette façon :
Lors de la création d'un Worker, le moteur JS s'applique au navigateur pour ouvrir un thread enfant (fil enfant Il est ouvert par le navigateur, entièrement contrôlé par le thread principal, et ne peut pas faire fonctionner le DOM)
Le thread du moteur JS et le thread de travail communiquent d'une manière spécifique (API postMessage, qui nécessite la sérialisation des objets pour interagir avec le fil pour des données spécifiques)
Donc, si le travail prend beaucoup de temps, veuillez ouvrir un fil de travail séparé, afin que, peu importe à quel point cela soit bouleversant, cela n'affectera pas le fil principal du moteur JS. résultat à calculer et communiquer le résultat au thread principal. Parfait !
Et notez que le moteur JS est monothread, et l'essence de celui-ci n'a pas changé. Worker peut être compris comme un plug-in ouvert par le navigateur. pour le moteur JS, spécifiquement utilisé pour résoudre des problèmes informatiques à grande échelle.
Autres, l'explication détaillée de Worker dépasse le cadre de cet article, je n'entrerai donc pas dans les détails.
WebWorker et SharedWorker
Maintenant que nous sommes ici, mentionnons à nouveau SharedWorker (pour éviter de confondre ces deux concepts plus tard)
WebWorker n'appartient qu'à une certaine page et n'interagira pas avec le processus de rendu (navigateur) des autres pages Processus du noyau) partage
Chrome crée donc un nouveau fil dans le processus de rendu (chaque page d'onglet est un processus de rendu) pour exécuter le programme JavaScript dans le Worker.
SharedWorker est partagé par toutes les pages du navigateur et ne peut pas être implémenté de la même manière que Worker car il n'est pas affilié à un processus de rendu et peut être partagé par plusieurs processus de rendu
Par conséquent, le navigateur Chrome crée un processus distinct pour SharedWorker. run Pour les programmes JavaScript, il n'existe qu'un seul processus SharedWorker pour chaque même JavaScript dans le navigateur, quel que soit le nombre de fois qu'il est créé.
Après avoir vu cela, cela devrait être facile à comprendre. Il s'agit essentiellement de la différence entre les processus et les threads. SharedWorker est géré par un processus indépendant et WebWorker n'est qu'un thread sous le processus Render.
Processus de rendu du navigateur
Processus de rendu du navigateur supplémentaire (version simple)
Afin de simplifier la compréhension, le travail préliminaire est directement omis :
Le navigateur saisit l'url, le processus principal du navigateur prend le relais, ouvre un fil de téléchargement, puis effectuez une requête http (en omettant la requête DNS, l'adressage IP, etc.), puis attendez la réponse, obtenez le contenu, puis transférez le contenu vers le processus de rendu via l'interface RendererHost
Le processus de rendu du navigateur commence
Après le Le noyau du navigateur récupère le contenu. Le rendu peut être grossièrement divisé en les étapes suivantes :
Analyser le HTML et construire l'arborescence DOM
Analyser le CSS et construire l'arbre de rendu (analyser le code CSS dans une structure de données en forme d'arbre, puis le combiner avec DOM pour le fusionner dans l'arbre de rendu)
Arbre de rendu de mise en page (Mise en page/redistribution), responsable du calcul la taille et la position de chaque élément
Dessinez l'arbre de rendu (paint) et dessinez les informations sur les pixels de la page
Le navigateur enverra les informations de chaque couche au GPU, et le GPU composera chaque couche et l'affichera à l'écran.
Toutes les étapes détaillées ont été omises. Après le rendu, c'est l'événement de chargement, puis c'est votre propre traitement logique JS.
Étant donné que certaines étapes détaillées ont été omises, permettez-moi de mentionner certains détails qui pourraient nécessiter une attention particulière. 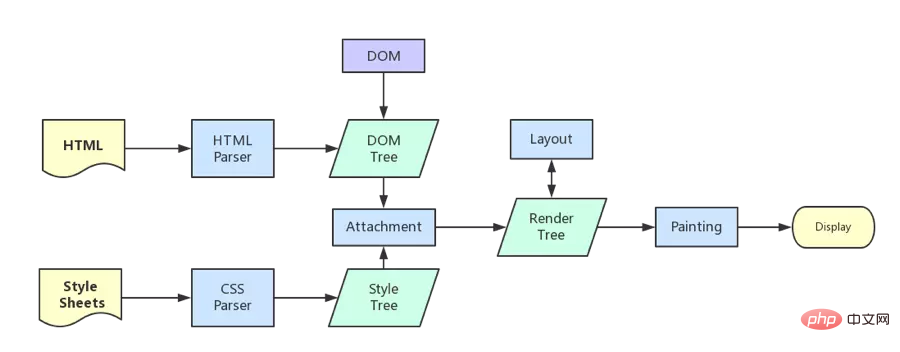
La séquence de l'événement Load et de l'événement DOMContentLoaded
Comme mentionné ci-dessus, l'événement Load sera déclenché une fois le rendu terminé, pouvez-vous donc distinguer la séquence de l'événement Load et de l'événement DOMContentLoaded ?
C'est très simple, il suffit de connaître leurs définitions :
Lorsque l'événement DOMContentLoaded est déclenché, uniquement lorsque le DOM est chargé, hors feuilles de style, images, scripts asynchrones, etc.
Lorsque l'événement onload est déclenché, tous les DOM, feuilles de style, scripts et images de la page ont été chargés, c'est-à-dire qu'ils ont été rendus. L'ordre est donc : DOMContentLoaded -> l'arbre dom ? Rendu
Le chargement du CSS ne bloquera pas l'analyse de l'arbre DOM (le DOM est construit comme d'habitude lors du chargement asynchrone)
- mais il bloquera le rendu de l'arbre de rendu (vous devez attendre que le CSS soit chargé lors du rendu, car l'arbre de rendu nécessite des informations CSS)
- Cela peut également être un mécanisme d'optimisation du navigateur. Parce que lorsque vous chargez du CSS, vous pouvez modifier le style du nœud DOM ci-dessous. Si le chargement du CSS ne bloque pas le rendu de l'arbre de rendu, alors une fois le CSS chargé, l'arbre de rendu devra peut-être être redessiné ou redistribué, ce qui pose quelques problèmes. Il n’y a pas de perte nécessaire.
attribut d'opacité/animation de transition (le calque composite ne sera créé que lors de l'exécution de l'animation, et l'élément reviendra au état précédent après que l'animation n'a pas démarré ou terminé)
attribut will-chang (relativement éloigné), généralement utilisé en conjonction avec opacity et translation. Sa fonction est d'indiquer au navigateur à l'avance que des modifications doivent être apportées, afin que le navigateur commence à faire un travail d'optimisation (il est préférable de le publier après utilisation) Des éléments tels que la vidéo, l'iframe, le canevas, le webgl, etc.
D'autres, comme le plug-in flash précédent
La différence entre accélération absolue et matérielle
Vous pouvez voir que bien que l'absolu puisse être séparé du flux de documents ordinaire, il ne peut pas être séparé de la couche composite par défaut. Par conséquent, même si les informations en valeur absolue changent, cela ne modifiera pas l'arborescence de rendu dans le flux de documents ordinaire. Cependant, lorsque le navigateur dessine finalement, la totalité du calque composite est dessiné, donc les modifications dans les informations en valeur absolue affecteront toujours le dessin. de la totalité de la couche composite. (Le navigateur le redessinera. S'il y a beaucoup de contenu dans la couche composite, les informations de dessin apportées par l'absolu changeront trop et la consommation de ressources sera très importante)
Le rôle des calques composites
Généralement, après avoir activé l'accélération matérielle, un élément deviendra un calque composite, qui peut être indépendant du flux de documents ordinaire. Après modification, il peut éviter de redessiner la page entière et améliorer les performances, mais. essayez de ne pas utiliser de couches composites en grande quantité, sinon en raison d'une consommation excessive de ressources, la page deviendra lente
Veuillez utiliser l'index lors de l'utilisation de l'accélération matérielle
Lorsque vous utilisez l'accélération matérielle, utilisez l'index autant que possible pour empêcher le navigateur de créer rendu de couche composite pour les éléments suivants par défaut
Spécifique Le principe est le suivant : dans le webkit CSS3, si cet élément a une accélération matérielle ajoutée et que le niveau d'index est relativement faible, alors les autres éléments derrière cet élément (niveau supérieur à cet élément, ou identique et ayant les mêmes attributs relatifs ou absolus), il deviendra un rendu de couche composite par défaut. S'il n'est pas géré correctement, cela affectera grandement les performances. Pour le comprendre simplement, il peut en fait être considéré comme implicite. concept de synthèse : si a est une couche composite et que b est au-dessus de a , alors b sera également implicitement converti en une couche composite, ce qui nécessite une attention particulière.
Parlez du mécanisme de fonctionnement de JS depuis EventLoopJusqu'à présent, c'est déjà après le rendu initial de la page du navigateur, une analyse du mécanisme de fonctionnement du moteur JS.
Notez que nous ne parlerons pas de concepts tels que le contexte exécutable, le VO, la chaîne de scop, etc. (ceux-ci peuvent être organisés dans un autre article). Nous parlons principalement ici de la façon dont le code JS est exécuté en conjonction avec Event Loop.
Le prérequis pour lire cette partie est que vous sachiez déjà que le moteur JS est mono-thread, et plusieurs concepts évoqués ci-dessus seront utilisés ici :
Fil du moteur JS- Fil de déclenchement d'événement
- Fil de déclenchement temporisé Ensuite comprendre Un concept :
- En plus du thread principal, le thread déclencheur d'événements gère une file d'attente de tâches, tant comme la tâche asynchrone l'a fait. Pour connaître les résultats en cours d'exécution, placez un événement dans la file d'attente des tâches.
- Une fois que toutes les tâches synchrones de la pile d'exécution ont été exécutées (le moteur JS est inactif à ce moment-là), le système lira la file d'attente des tâches, ajoutera des tâches asynchrones exécutables à la pile exécutable et lancera l'exécution.
- Regardez l'image :
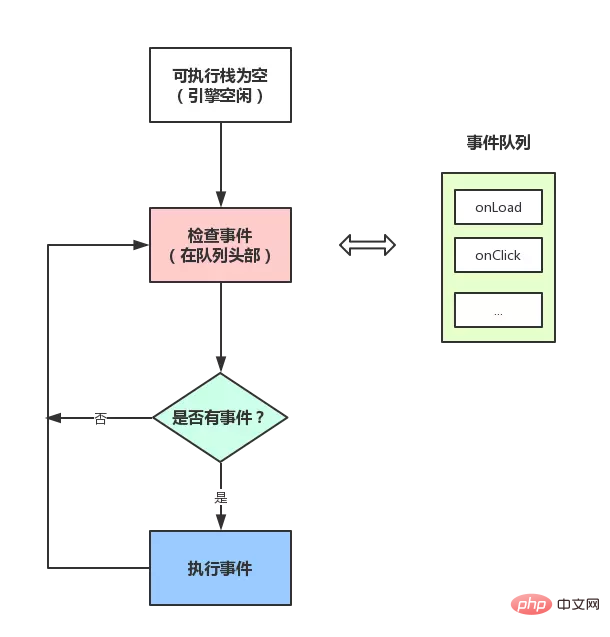 En voyant cela, vous devriez être capable de comprendre : Pourquoi les événements poussés par setTimeout ne sont-ils parfois pas exécutés à temps ? Étant donné que le thread principal n'est peut-être pas encore inactif et qu'il exécute un autre code lorsqu'il est inséré dans la liste d'événements, il y aura donc naturellement des erreurs.
En voyant cela, vous devriez être capable de comprendre : Pourquoi les événements poussés par setTimeout ne sont-ils parfois pas exécutés à temps ? Étant donné que le thread principal n'est peut-être pas encore inactif et qu'il exécute un autre code lorsqu'il est inséré dans la liste d'événements, il y aura donc naturellement des erreurs.
Le mécanisme de boucle d'événements est encore complété
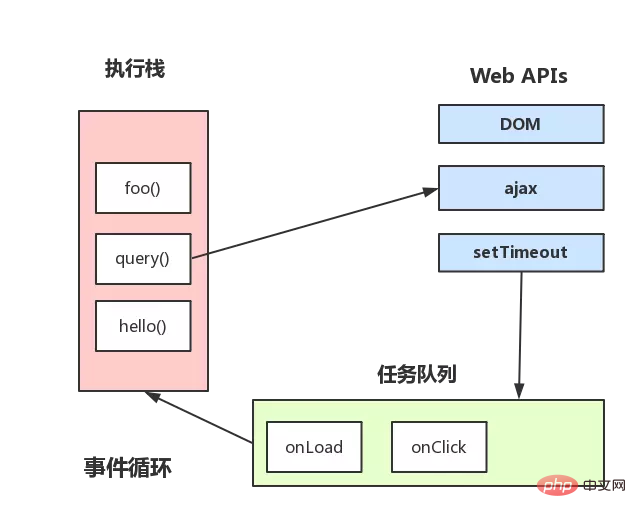 L'image ci-dessus décrit grossièrement :
L'image ci-dessus décrit grossièrement :
- Une fois le code de la pile exécuté, les événements de la file d'attente des événements seront lus pour exécuter ces rappels, et ainsi de suite
- Notez que vous devez toujours attendre la pile. Les événements dans la file d'attente des événements ne seront lus qu'après l'exécution du code
Parlons du minuteur séparément
Le cœur du mécanisme de boucle d'événements ci-dessus est : le thread du moteur JS et le fil de déclenchement de l'événement
Mais il y a des choses cachées dans les détails de l'événement, comme comment attendre une heure spécifique avant de l'ajouter à la file d'attente des événements après avoir appelé setTimeout ?
Est-il détecté par le moteur JS ? Bien sûr que non. Il est contrôlé par le thread du timer (car le moteur JS lui-même est trop occupé et n'a pas le temps de faire autre chose)
Pourquoi avons-nous besoin d'un thread de timer séparé ? Étant donné que le moteur JavaScript est monothread, s'il est dans un état de thread bloqué, cela affectera la précision du timing, il est donc nécessaire d'ouvrir un thread séparé pour le timing.
Quand le fil du minuteur sera-t-il utilisé ? Lors de l'utilisation de setTimeout ou setInterval, le thread du minuteur doit chronométrer, et une fois le temps écoulé, l'événement spécifique sera poussé dans la file d'attente des événements.
setTimeout au lieu de setInterval
Il y a une différence entre utiliser setTimeout pour simuler un timing régulier et utiliser setInterval directement.
Parce que chaque fois que setTimeout est exécuté, il sera exécuté, puis il continuera à setTimeout après une période d'exécution. Il y aura des erreurs au milieu (l'erreur est liée au temps d'exécution du code)
Et setInterval est. un intervalle précis à chaque fois. Un événement est poussé pendant un certain temps, mais l'heure d'exécution réelle de l'événement peut ne pas être exacte. Il est également possible que l'événement suivant survienne avant la fin de l'événement.
Et setInterval a quelques problèmes fatals :
Effet cumulatif, si le code setInterval n'a pas terminé son exécution avant d'être à nouveau ajouté à la file d'attente, le code du minuteur s'exécutera plusieurs fois en continu sans intervalle. Même s'ils sont exécutés à intervalles normaux, le temps d'exécution de plusieurs codes setInterval peut être plus court que prévu (car l'exécution du code prend un certain temps. Par exemple, les navigateurs tels que iOS webview ou Safari ont une fonctionnalité qui n'en a pas). exécuter lors du défilement. Pour JS, si vous utilisez setInterval, vous constaterez qu'il sera exécuté plusieurs fois une fois le défilement terminé. Parce que le défilement n'exécute pas le rappel d'accumulation JS, si le temps d'exécution du rappel est trop long, il le fera. provoquer des problèmes de blocage et des erreurs inconnues dans le conteneur (cette section sera ajoutée plus tard que setInterval a sa propre optimisation et n'ajoutera pas de rappels à plusieurs reprises)
Et lorsque le navigateur est réduit et affiché, setInterval n'exécute pas le programme. mettra la fonction de rappel de setInterval dans la file d'attente, en attendant que le navigateur. Lorsque la fenêtre sera rouverte, tout sera exécuté en un instant
Ainsi, compte tenu de tant de problèmes, la meilleure solution actuellement est généralement considérée comme : utilisez setTimeout pour simuler setInterval, ou utilisez directement requestAnimationFrame lors d'occasions spéciales
Boucle d'événements avancée : macrotâche et microtâche
Le mécanisme de boucle d'événements JS a été réglé ci-dessus. Il est suffisant dans ES5, mais maintenant que ES6 est répandu, vous rencontrerez toujours certains problèmes, par exemple. question suivante :console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');Hmm, l'ordre d'exécution correct est comme ceci :
script start script end promise1 promise2 setTimeoutPourquoi ? Parce qu'il y a un nouveau concept dans Promise : microtâcheOu, plus loin, JS est divisé en deux types de tâches : macrotâche et microtâche Dans ECMAScript, la microtâche est appelée tâches, et la macrotâche peut être appelée tâche. Quelles sont leurs définitions ? la différence ? Pour faire simple, cela peut se comprendre comme suit : 1. macrotâche (aussi appelée macro tâche) On peut comprendre que le code exécuté par la pile d'exécution à chaque fois est une macro tâche (incluant à chaque fois un rappel d'événement est obtenu à partir de la file d'attente des événements et placé pour s'exécuter dans la pile d'exécution)
- Chaque tâche exécutera cette tâche du début à la fin et n'exécutera pas d'autres tâches
- Afin de permettre l'exécution des tâches internes JS et des tâches DOM de manière ordonnée, le navigateur l'exécutera en une seule tâche. Après la fin, avant le début de l'exécution de la tâche suivante, restituez la page (tâche -> rendu-> tâche -> ...)
- C'est-à-dire après la tâche en cours, avant la tâche suivante et avant le rendu
- . donc sa vitesse de réponse sera plus rapide que setTimeout (setTimeout est une tâche), car il n'est pas nécessaire d'attendre le rendu
- En d'autres termes, après l'exécution d'une certaine macrotâche, toutes les microtâches générées lors de son exécution seront exécutées (avant le rendu )
- macrotâche : bloc de code principal, setTimeout, setInterval, etc. (chaque événement dans la file d'attente des événements est une macrotâche)
- microtâche : promesse, processus .nextTick, etc.
Donc , pour résumer le mécanisme de fonctionnement :
- Exécuter une macro-tâche (si elle n'est pas sur la pile, la récupérer dans la file d'attente des événements)
- Si une microtâche est rencontrée lors de l'exécution, l'ajouter à la file d'attente des tâches de la microtâche
- Macro Une fois la tâche exécutée, toutes les microtâches de la file d'attente de microtâches actuelle sont exécutées immédiatement (exécutées dans l'ordre)
- Une fois la tâche macro actuelle exécutée, le rendu commence à être vérifié, puis le thread GUI prend en charge le rendu
- Une fois le rendu terminé, le thread JS continue de prendre le relais et démarre. Une macrotâche (obtenue à partir de la file d'attente des événements)
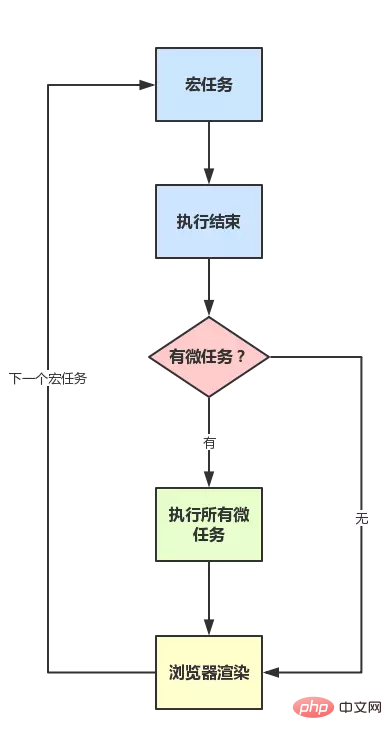
polyfill, généralement Il est simulé via setTimeout, il est donc sous forme de macrotâche
A noter que certains navigateurs ont des résultats d'exécution différents (car ils peut exécuter une microtâche comme une macrotâche), mais par souci de simplicité, les scénarios sous certains navigateurs non standard ne sont pas décrits ici (mais rappelez-vous, certains navigateurs peuvent ne pas être standard)
.
补充:使用MutationObserver实现microtask
MutationObserver可以用来实现microtask (它属于microtask,优先级小于Promise, 一般是Promise不支持时才会这样做)
它是HTML5中的新特性,作用是:监听一个DOM变动, 当DOM对象树发生任何变动时,Mutation Observer会得到通知
像以前的Vue源码中就是利用它来模拟nextTick的, 具体原理是,创建一个TextNode并监听内容变化, 然后要nextTick的时候去改一下这个节点的文本内容, 如下:
var counter = 1
var observer = new MutationObserver(nextTickHandler)
var textNode = document.createTextNode(String(counter))
observer.observe(textNode, {
characterData: true
})
timerFunc = () => {
counter = (counter + 1) % 2
textNode.data = String(counter)
}
不过,现在的Vue(2.5+)的nextTick实现移除了MutationObserver的方式(据说是兼容性原因), 取而代之的是使用MessageChannel (当然,默认情况仍然是Promise,不支持才兼容的)。
MessageChannel属于宏任务,优先级是:MessageChannel->setTimeout, 所以Vue(2.5+)内部的nextTick与2.4及之前的实现是不一样的,需要注意下。
【相关推荐:javascript视频教程、web前端】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Pourquoi JavaScript doit être encapsulé
- Vous amener à comprendre les événements du clavier et de la souris en JavaScript
- Analysons les références faibles et les références fortes en JavaScript
- Compréhension approfondie du DOM et du BOM en JavaScript
- Analyse détaillée JavaScript des requêtes réseau et des ressources distantes