
Maison >base de données >Redis >Parlons des trois problèmes de mise en cache de Redis
Parlons des trois problèmes de mise en cache de Redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-03-31 12:01:083494parcourir
Cet article vous apporte des connaissances pertinentes sur Redis Il présente principalement trois types de problèmes de cache, à savoir la pénétration du cache, la panne du cache et l'avalanche de cache.

Apprentissage recommandé : Tutoriel d'apprentissage Redis
1. Application du cache Redis
Dans nos scénarios commerciaux réels, Redis est généralement utilisé en conjonction avec d'autres bases de données pour réduire la pression de base de données de bout en bout, par exemple, utilisée en conjonction avec la base de données relationnelle MySQL.
Redis mettra en cache les données fréquemment interrogées dans MySQL, telles que les données chaudes, de sorte que lorsque les utilisateurs viennent visiter, ils n'ont pas besoin d'interroger dans MySQL, mais obtiennent directement les données mises en cache dans Redis, réduisant ainsi la pression de lecture sur la base de données principale. Si
les données interrogées par l'utilisateur ne sont pas disponibles dans Redis, alors la demande de requête de l'utilisateur sera transférée vers la base de données MySQLLorsque MySQL renvoie les données au client, il mettra également en cache les données dans Redis, afin que l'utilisateur puisse à nouveau accéder aux données Lors de la lecture, vous pouvez obtenir des données directement depuis Redis. L'organigramme est le suivant :
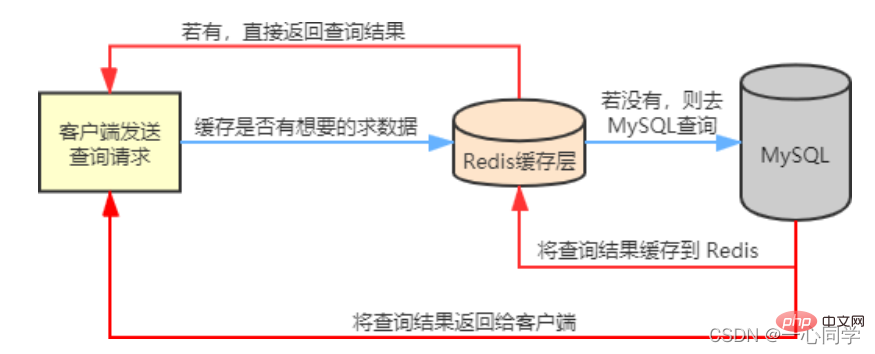
Bien sûr, lorsque nous utilisonsLorsque MySQL renvoie un objet vide, Redis met l'objet en cache et définit un délai d'expiration pour celui-ci. Lorsque l'utilisateur lance à nouveau la même requête, unRedis comme base de données de cache, la navigation n'est pas toujours fluide. Nous rencontrerons trois problèmes de mise en cache courants :
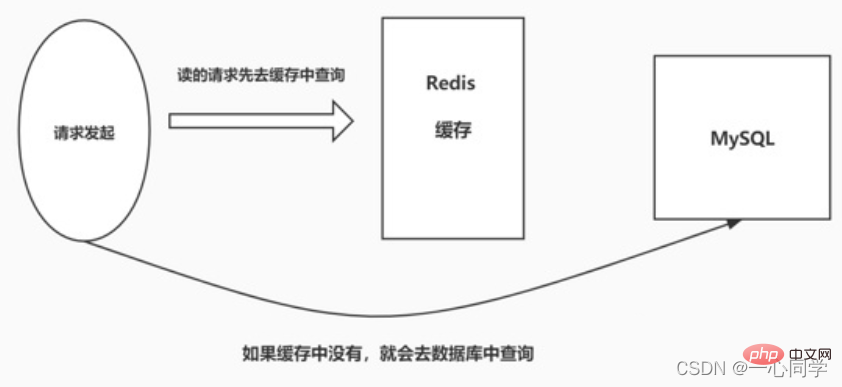
. Pénétration du cache
- Pénétration du cache signifie Lorsque l'utilisateur interroge certaines données , les données n'existent pas dans Redis, c'est-à-dire que le cache ne fonctionne pas. À ce moment-là, la demande de requête sera transférée à la base de données de la couche de persistance MySQL. Il s'avère que les données n'existent pas dans MySQL, et MySQL peut le faire. renvoie uniquement un objet vide, indiquant que la requête a échoué. S'il y a trop de requêtes de ce type, ou si les utilisateurs utilisent de telles requêtes pour mener des attaques malveillantes, cela mettra beaucoup de pression sur la base de données MySQL et même s'effondrera. Ce phénomène est appelé pénétration du cache.
- Solution 2.2
- Cache les objets vides
objet vide
sera obtenu du cache. La demande de l'utilisateur est bloquée dans la couche cache, protégeant ainsi la base de données principale. Cependant, cette approche présente également quelques problèmes. Bien que la requête ne puisse pas entrer dans MSQL, cette stratégie occupera de l'espace dans le cache Redis.Filtre Bloom
Bloom est plus efficace et plus pratique.
Le schéma de processus est le suivant :Préchauffage du cache : fait référence au chargement des données pertinentes dans le système de cache Redis à l'avance au démarrage du système. Cela évite de charger des données lorsque l'utilisateur le demande.
2.3 Comparaison des solutions
Les deux solutions peuvent résoudre le problème de pénétration du cache , mais leurs scénarios d'utilisation sont différents :
Cache les objets vides : Nombre de clés adaptées aux données vides Scénarios avec des données limitées et forte probabilité de demandes de clés répétées.
Filtre Bloom : convient aux scénarios dans lesquels les clés des données vides sont différentes et la probabilité de demandes de clés répétées est faible.
3. Panne du cache
3.1 Introduction
Modifier l'heure d'expirationPanne du cache signifie que les données interrogées par l'utilisateur n'existent pas dans le cache, mais existent dans la base de données backend. La raison de ce phénomène est . généralement, cela est dû à l'expiration de la clé dans le cache. Par exemple, une clé de données rapide reçoit tout le temps un grand nombre d'accès simultanés. Si la clé échoue soudainement à un certain moment, un grand nombre de requêtes simultanées entreront dans la base de données principale, provoquant une augmentation instantanée de sa pression. Ce phénomène est appelé rupture de cache.
Solution 3.2
Distributed LockDéfinissez les données du point d'accès pour qu'elles n'expirent jamais.
adopte la méthode de
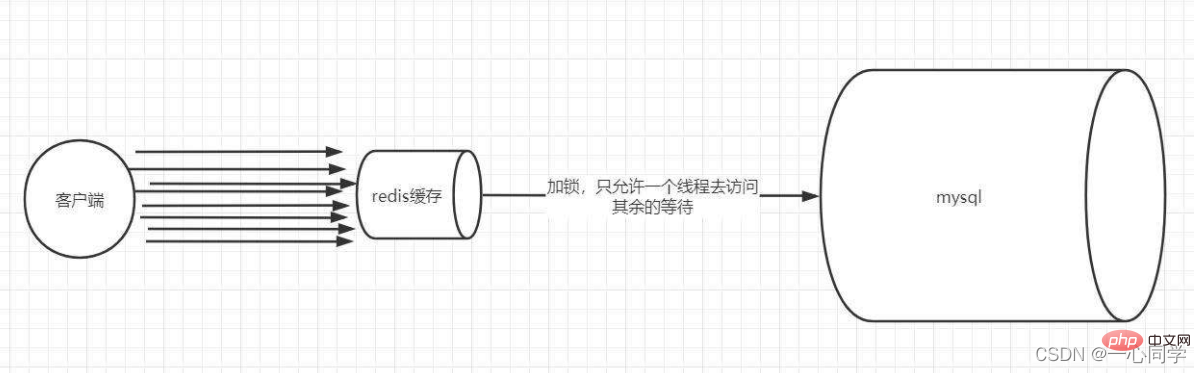
Distributed Lock pour repenser l'utilisation du cache Le processus est le suivant :
- Lock : Lorsque nous interrogeons par clé Quand. Les données sont générées, le cache est d'abord interrogé. S'il n'y a pas de cache, il est verrouillé via un verrou distribué. Le premier processus à acquérir le verrou entre dans la base de données principale pour interroger et les résultats de la requête sont mis en mémoire tampon dans Redis.
- Déverrouillage : Lorsque d'autres processus constatent que le verrou est occupé par un certain processus, ils entrent en état d'attente. Après le déverrouillage, d'autres processus accèdent à leur tour à la clé mise en cache.
 3.3 Comparaison des solutions
3.3 Comparaison des solutions
N'expire jamais : Étant donné que cette solution ne fixe pas de délai d'expiration réel, il n'y a en fait aucune série de dangers causés par les clés de hotspot, mais il y aura une situation d'incohérence des données, et la complexité du code augmentera.
Verrouillage Mutex : L'idée de cette solution est relativement simple, mais il existe certains dangers cachés. S'il y a un problème dans le processus de création du cache ou si cela prend beaucoup de temps, il peut y avoir un risque. blocage et blocage du pool de threads, mais cette méthode peut mieux réduire la charge de stockage back-end et obtenir une meilleure cohérence. 4. Avalanche de cache
4.1 Introduction
Avalanche de cache signifie qu'un grand nombre de clés dans le cache expirent en même temps et que la quantité d'accès aux données est très importante à ce moment-là, ce qui conduit à une augmentation soudaine de la pression de la base de données back-end, ou même à un blocage. Ce phénomène est appelé avalanche de cache. Cela diffère de la panne du cache. La panne du cache se produit lorsqu'une certaine touche de raccourci expire soudainement lorsque le degré de concurrence est particulièrement important, tandis que l'avalanche du cache se produit lorsqu'un grand nombre de clés expirent en même temps, elles ne sont donc pas du même ordre. d'ampleur du tout.
4.2 Solution
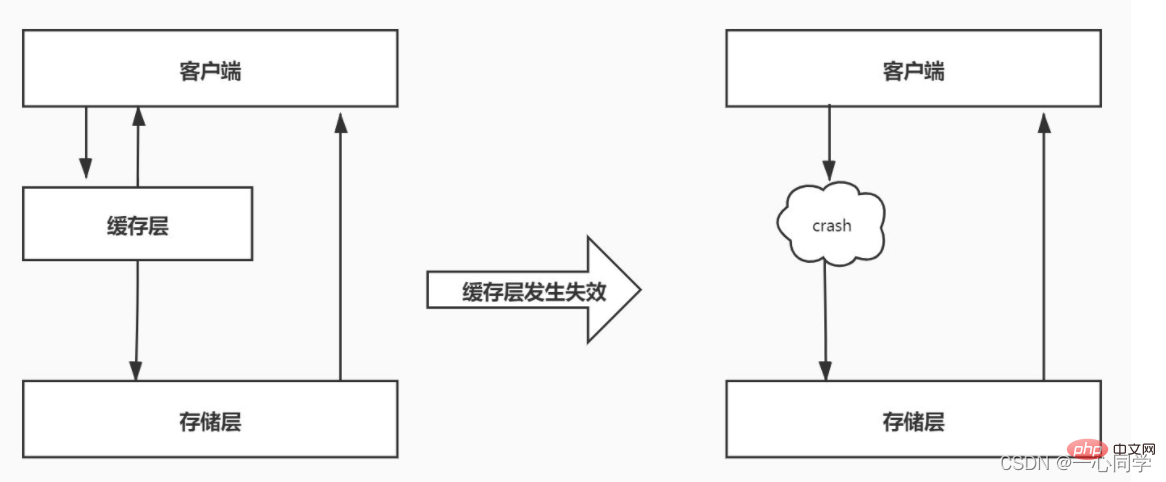 Gestion de l'expiration
Gestion de l'expiration
L'avalanche et la panne du cache sont similaires, vous pouvez donc également utiliser la méthode de les données du point d'accès n'expirent jamais
pour réduire les lots importants, les clés expirent en même temps temps. De plus,définissez un délai d'expiration aléatoire pour la cléafin d'éviter l'expiration centralisée des clés. redis haute disponibilité
Un Redis peut raccrocher à cause d'une avalanche, vous pouvez alors ajouter quelques Redis supplémentaires et construire un cluster
Si l'un raccroche, les autres peuvent continuer à travailler. .Apprentissage recommandé : Tutoriel d'apprentissage Redis
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Analyse détaillée de la façon d'optimiser Redis lorsque la mémoire est pleine
- Que dois-je faire si les caches à double écriture de Redis et MySQL sont incohérents ? Partage de solutions
- Analysons ensemble le mode sentinelle Redis
- Comment assurer la cohérence entre le cache Redis et la base de données
- Résumer et organiser les six structures de données sous-jacentes de Redis