
Maison >base de données >Redis >Résumer et organiser les six structures de données sous-jacentes de Redis
Résumer et organiser les six structures de données sous-jacentes de Redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2022-03-18 18:07:462714parcourir
Cet article vous apporte des connaissances pertinentes sur Redis, qui présente principalement des problèmes liés à six structures de données sous-jacentes, notamment des chaînes dynamiques simples, des listes chaînées, des dictionnaires, des tables de sauts, des ensembles d'entiers et des listes compressées, j'espère, utiles à tout le monde.

Apprentissage recommandé : Tutoriel Redis
1.Redis Bien qu'il soit écrit en langage C, Redis n'utilise pas directement la représentation sous forme de chaîne traditionnelle du langage C (en utilisant des caractères nuls).
(6)总结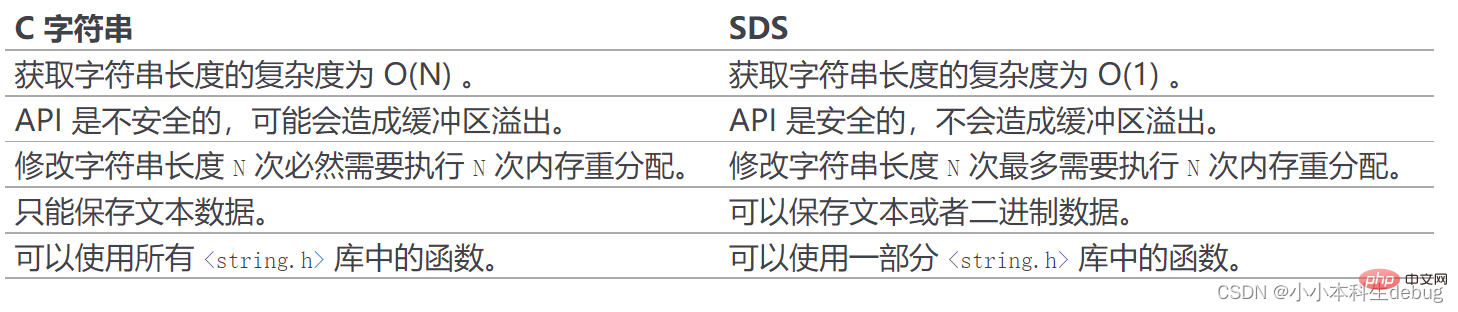
2、链表
作为一种常用数据结构,链表内置在很多高级的编程语言里面,因为Redis使用的 C 语言并没有内置这种数据结构,所以 Redis 构建了自己的链表结构。
每个链表节点使用一个 adlist.h/listNode 结构来表示:
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;} listNode;
多个 listNode 可以通过 prev 和 next 指针组成双端链表, 如图 3-1 所示。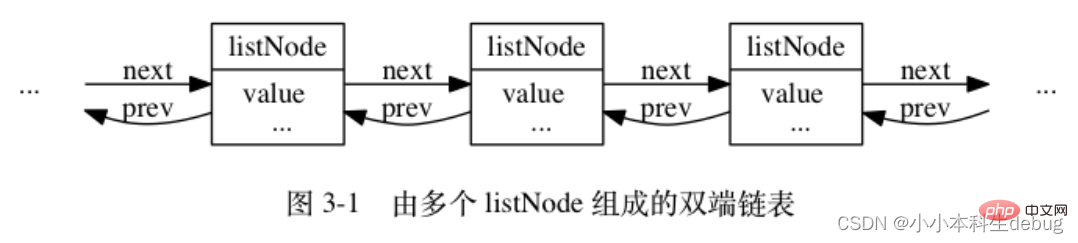
虽然仅仅使用多个 listNode 结构就可以组成链表, 但使用 adlist.h/list 来持有链表的话, 操作起来会更方便:
typedef struct list {
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);} list;
list 结构为链表提供了表头指针 head 、表尾指针 tail , 以及链表长度计数器 len , 而 dup 、 free 和 match 成员则是用于实现多态链表所需的类型特定函数:
① dup 函数用于复制链表节点所保存的值;
② free 函数用于释放链表节点所保存的值;
③ match 函数则用于对比链表节点所保存的值和另一个输入值是否相等。
图 3-2 是由一个 list 结构和三个 listNode 结构组成的链表: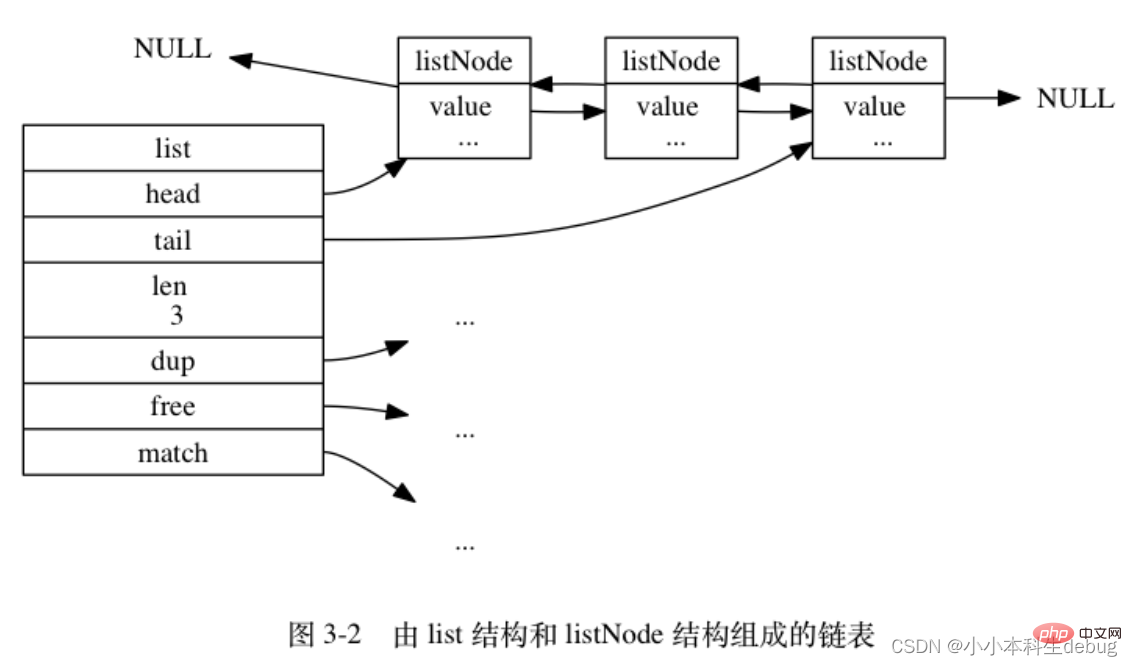
Redis 的链表实现的特性可以总结如下:
①双端: 链表节点带有 prev 和 next 指针, 获取某个节点的前置节点和后置节点的复杂度都是 O(1) 。
②无环: 表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL , 对链表的访问以 NULL 为终点。
③带表头指针和表尾指针: 通过 list 结构的 head 指针和 tail 指针, 程序获取链表的表头节点和表尾节点的复杂度为 O(1) 。
④带链表长度计数器: 程序使用 list 结构的 len 属性来对 list 持有的链表节点进行计数, 程序获取链表中节点数量的复杂度为 O(1) 。
⑤多态: 链表节点使用 void* 指针来保存节点值, 并且可以通过 list 结构的 dup 、 free 、 match 三个属性为节点值设置类型特定函数, 所以链表可以用于保存各种不同类型的值。
3、字典
字典又称为符号表或者关联数组、或映射(map),是一种用于保存键值对的抽象数据结构。字典中的每一个键 key 都是唯一的,通过 key 可以对值来进行查找或修改。C 语言中没有内置这种数据结构的实现,所以字典依然是 Redis 自己构建的。
Redis 的字典使用哈希表作为底层实现, 一个哈希表里面可以有多个哈希表节点, 而每个哈希表节点就保存了字典中的一个键值对。
哈希表
Redis 字典所使用的哈希表由 dict.h/dictht 结构定义:
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;} dictht;
图 4-1 展示了一个大小为 4 的空哈希表 (没有包含任何键值对)。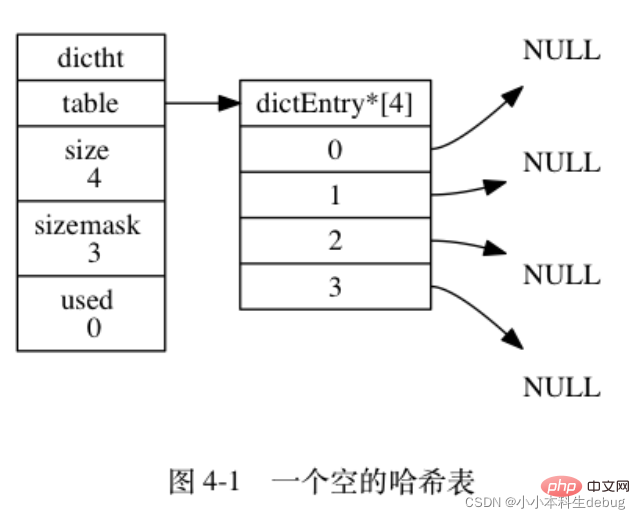
哈希表节点
哈希表节点使用 dictEntry 结构表示, 每个 dictEntry 结构都保存着一个键值对:
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;} dictEntry;
key 用来保存键,val 属性用来保存值,值可以是一个指针,也可以是uint64_t 整数,也可以是 int64_t 整数。
注意这里还有一个指向下一个哈希表节点的指针,我们知道哈希表最大的问题是存在哈希冲突,如何解决哈希冲突,有开放地址法和链地址法。这里采用的便是链地址法,通过 next 这个指针可以将多个哈希值相同的键值对连接在一起,用来解决哈希冲突。
(因为 dictEntry 节点组成的链表没有指向链表表尾的指针, 所以为了速度考虑, 程序总是将新节点添加到链表的表头位置(复杂度为 O(1)), 排在其他已有节点的前面。)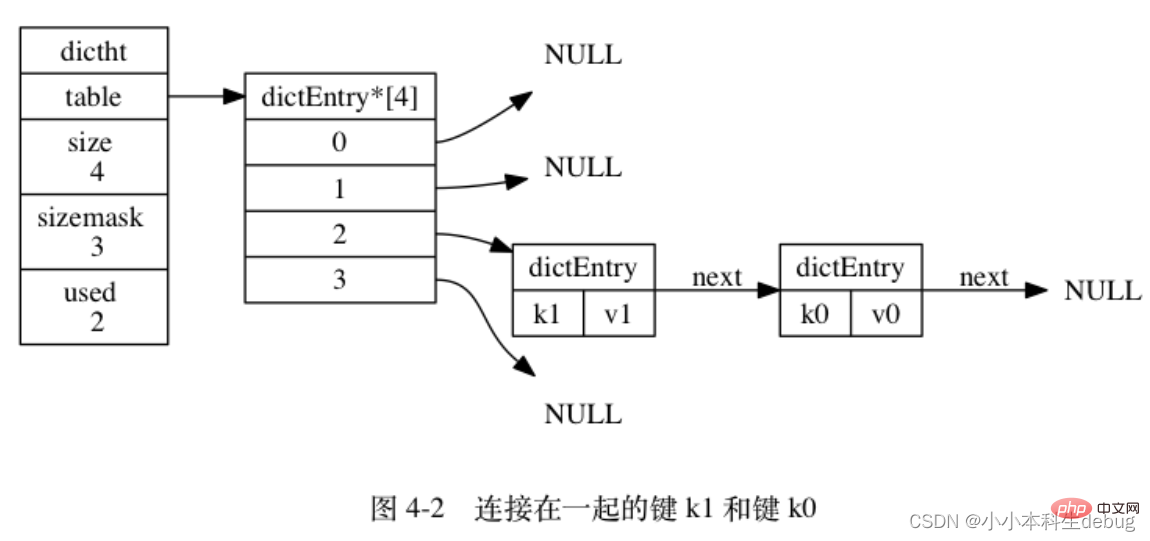
字典
Redis 中的字典由 dict.h/dict 结构表示:
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx;
/* rehashing not in progress if rehashidx == -1 */} dict;
type 属性和 privdata 属性是针对不同类型的键值对, 为创建多态字典而设置的:
● type 属性是一个指向 dictType 结构的指针, 每个 dictType 结构保存了一簇用于操作特定类型键值对的函数, Redis 会为用途不同的字典设置不同的类型特定函数。
● 而 privdata 属性则保存了需要传给那些类型特定函数的可选参数。
typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);} dictType;
ht 属性是一个包含两个项的数组, 数组中的每个项都是一个 dictht 哈希表, 一般情况下, 字典只使用 ht[0] 哈希表, ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用。
除了 ht[1] 之外, 另一个和 rehash 有关的属性就是 rehashidx : 它记录了 rehash 目前的进度, 如果目前没有在进行 rehash , 那么它的值为 -1 。
图 4-3 展示了一个普通状态下(没有进行 rehash)的字典: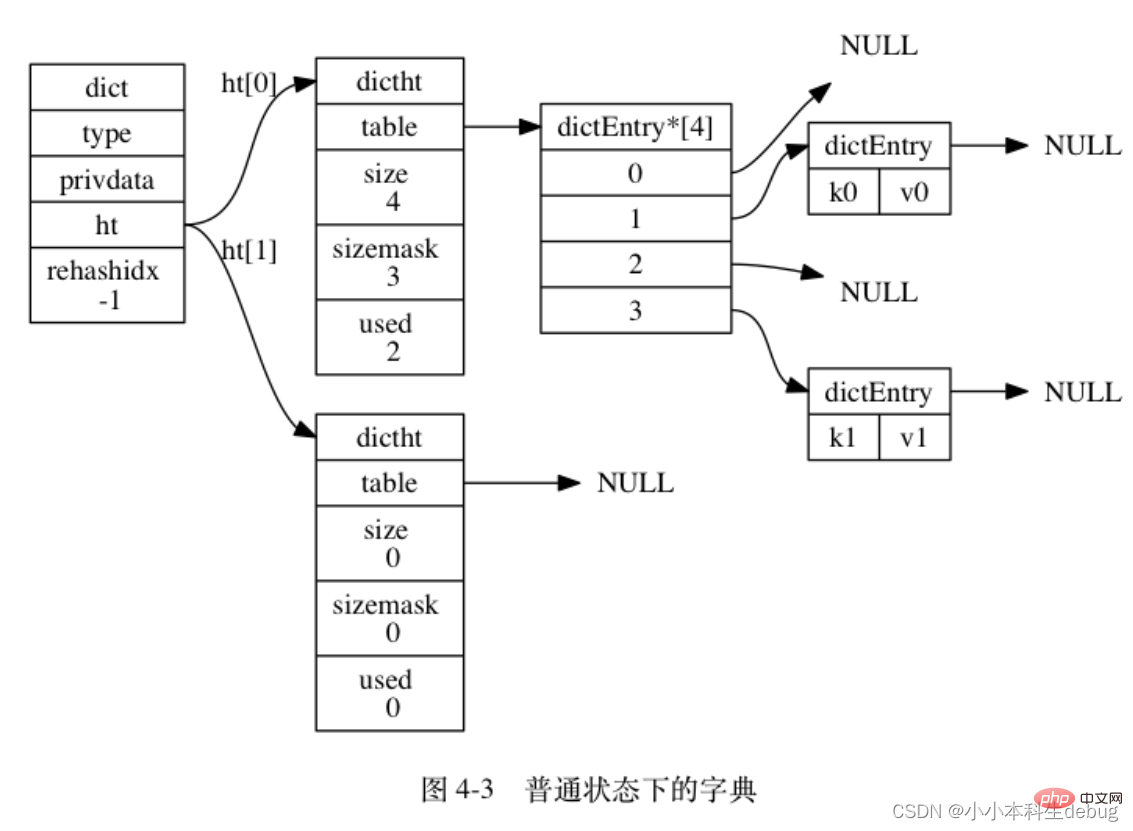
① 哈希算法:Redis计算哈希值和索引值方法如下:
# 使用字典设置的哈希函数,计算键 key 的哈希值 hash = dict->type->hashFunction(key);# 使用哈希表的 sizemask 属性和哈希值,计算出索引值 # 根据情况不同, ht[x] 可以是 ht[0] 或者 ht[1]index = hash & dict->ht[x].sizemask;
②解决哈希冲突:这个问题上面我们介绍了,方法是链地址法。通过字典里面的 *next 指针指向下一个具有相同索引值的哈希表节点。
③扩容和收缩(rehash):当哈希表保存的键值对太多或者太少时,就要通过 rerehash(重新散列)来对哈希表进行相应的扩展或者收缩。具体步骤:
1、为字典的 ht[1] 哈希表分配空间, 这个哈希表的空间大小取决于要执行的操作, 以及 ht[0] 当前包含的键值对数量 (也即是 ht[0].used 属性的值)
● 如果执行的是扩展操作, 那么 ht[1] 的大小为第一个大于等于 ht[0].used * 2n; (也就是每次扩展都是根据原哈希表已使用的空间扩大一倍创建另一个哈希表)
● 如果执行的是收缩操作, 每次收缩是根据已使用空间缩小一倍创建一个新的哈希表。
2、将保存在 ht[0] 中的所有键值对 rehash 到 ht[1] 上面: rehash 指的是重新计算键的哈希值和索引值, 然后将键值对放置到 ht[1] 哈希表的指定位置上。
3、当 ht[0] 包含的所有键值对都迁移到了 ht[1] 之后 (ht[0] 变为空表), 释放 ht[0] , 将 ht[1] 设置为 ht[0] , 并在 ht[1] 新创建一个空白哈希表, 为下一次 rehash 做准备。
④触发扩容与收缩的条件:
1、服务器目前没有执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于1。
2、服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于5。
ps:负载因子 = 哈希表已保存节点数量 / 哈希表大小。
3、另一方面, 当哈希表的负载因子小于 0.1 时, 程序自动开始对哈希表执行收缩操作。
⑤渐近式 rehash
什么叫渐进式 rehash?也就是说扩容和收缩操作不是一次性、集中式完成的,而是分多次、渐进式完成的。如果保存在Redis中的键值对只有几个几十个,那么 rehash 操作可以瞬间完成,但是如果键值对有几百万,几千万甚至几亿,那么要一次性的进行 rehash,势必会造成Redis一段时间内不能进行别的操作。所以Redis采用渐进式 rehash,这样在进行渐进式rehash期间,字典的删除查找更新等操作可能会在两个哈希表上进行,第一个哈希表没有找到,就会去第二个哈希表上进行查找。但是进行增加操作,一定是在新的哈希表上进行的。
4、跳跃表
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。
具有如下性质:
1、由很多层结构组成;
2、每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节点;
3、最底层的链表包含了所有的元素;
4、如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集);
5、链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;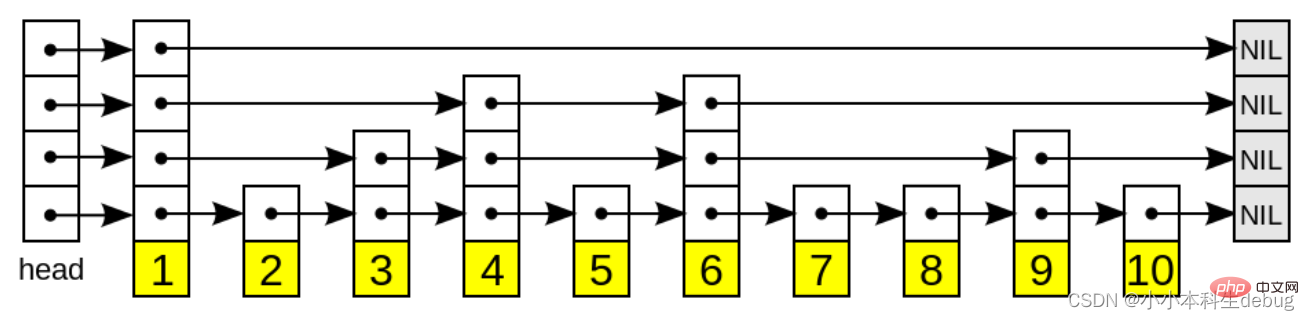
和链表、字典等数据结构被广泛地应用在 Redis 内部不同, Redis 只在两个地方用到了跳跃表, 一个是实现有序集合键, 另一个是在集群节点中用作内部数据结构, 除此之外, 跳跃表在 Redis 里面没有其他用途。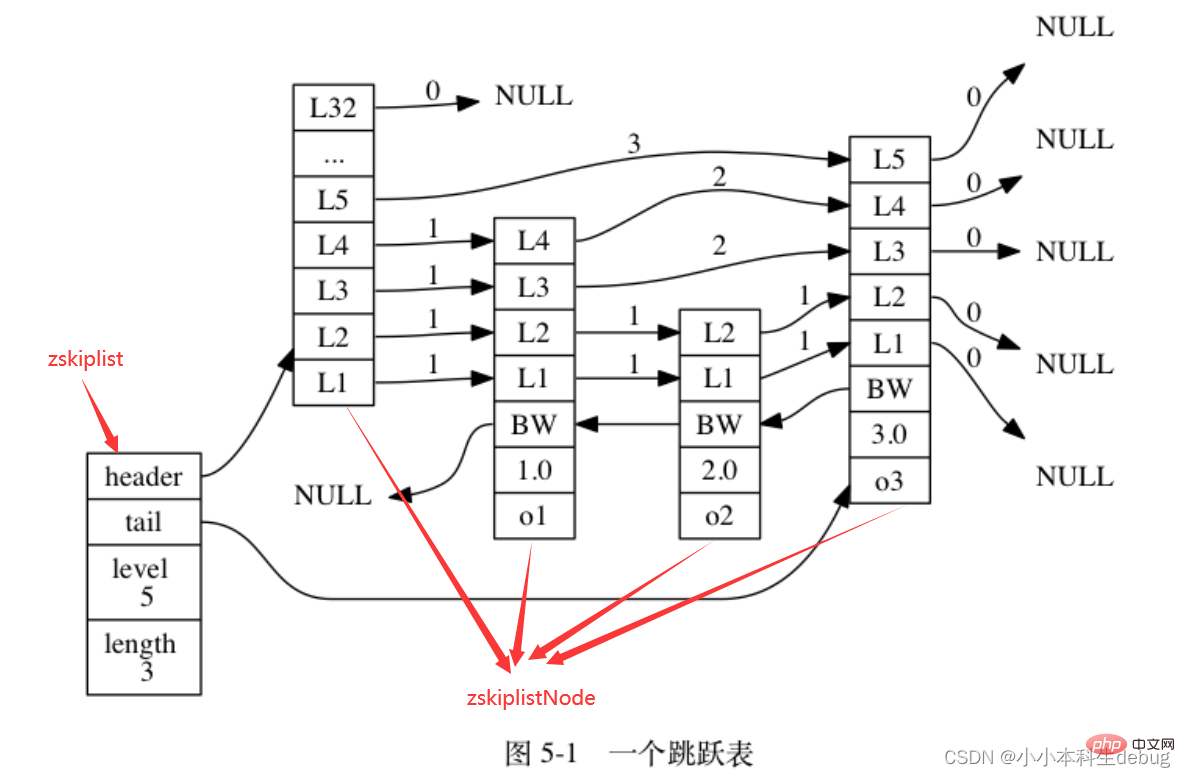
跳跃表节点(zskiplistNode)
该结构包含以下属性:
①层(level):节点中用 L1 、 L2 、 L3 等字样标记节点的各个层, L1 代表第一层, L2 代表第二层,以此类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其他节点,而跨度则记录了前进指针所指向节点和当前节点的距离。在上面的图片中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。
每次创建一个新跳跃表节点的时候, 程序都根据幂次定律 (power law,越大的数出现的概率越小) 随机生成一个介于 1 和 32 之间的值作为 level 数组的大小, 这个大小就是层的“高度”。(所以说表头节点的高度就是32)
②后退(backward)指针:节点中用 BW 字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。
③分值(score):各个节点中的 1.0 、 2.0 和 3.0 是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。
④成员对象(obj):各个节点中的 o1 、 o2 和 o3 是节点所保存的成员对象。
注意表头节点和其他节点的构造是一样的: 表头节点也有后退指针、分值和成员对象, 不过表头节点的这些属性都不会被用到, 所以图中省略了这些部分, 只显示了表头节点的各个层。
跳跃表(zskiplist)
① header :指向跳跃表的表头节点。
② tail :指向跳跃表的表尾节点。
③ level :记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)。
④ length :记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)。
5、整数集合
整数集合(intset)是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用集合作为集合键的底层实现。
整数集合(intset)是Redis用于保存整数值的集合抽象数据类型,它可以保存类型为int16_t、int32_t 或者int64_t 的整数值,并且保证集合中不会出现重复元素。
每个 intset.h/intset 结构表示一个整数集合:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];} intset;
整数集合的每个元素都是 contents 数组的一个数据项,它们按照从小到大的顺序排列,并且不包含任何重复项。
length 属性记录了 contents 数组的大小。
需要注意的是虽然 contents 数组声明为 int8_t 类型,但是实际上contents 数组并不保存任何 int8_t 类型的值,其真正类型有 encoding 来决定。
① 升级(encoding int16_t -> int32_t -> int64_t)
当我们新增的元素类型比原集合元素类型的长度要大时,需要对整数集合进行升级,才能将新元素放入整数集合中。具体步骤:
1、根据新元素类型,扩展整数集合底层数组的大小,并为新元素分配空间。
2、将底层数组现有的所有元素都转成与新元素相同类型的元素,并将转换后的元素放到正确的位置,放置过程中,维持整个元素顺序都是有序的。
3、将新元素添加到整数集合中(保证有序)。
升级能极大地节省内存。
② 降级
整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态。
6、压缩列表
压缩列表(ziplist)是列表键和哈希键的底层实现之一。
当一个列表键只包含少量列表项, 并且每个列表项要么就是小整数值, 要么就是长度比较短的字符串, 那么 Redis 就会使用压缩列表来做列表键的底层实现。
因为哈希键里面包含的所有键和值都是小整数值或者短字符串。
压缩列表是 Redis 为了节约内存而开发的, 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构。
Une liste compressée peut contenir n'importe quel nombre de nœuds (entrée), et chaque nœud peut stocker un tableau d'octets ou une valeur entière. 
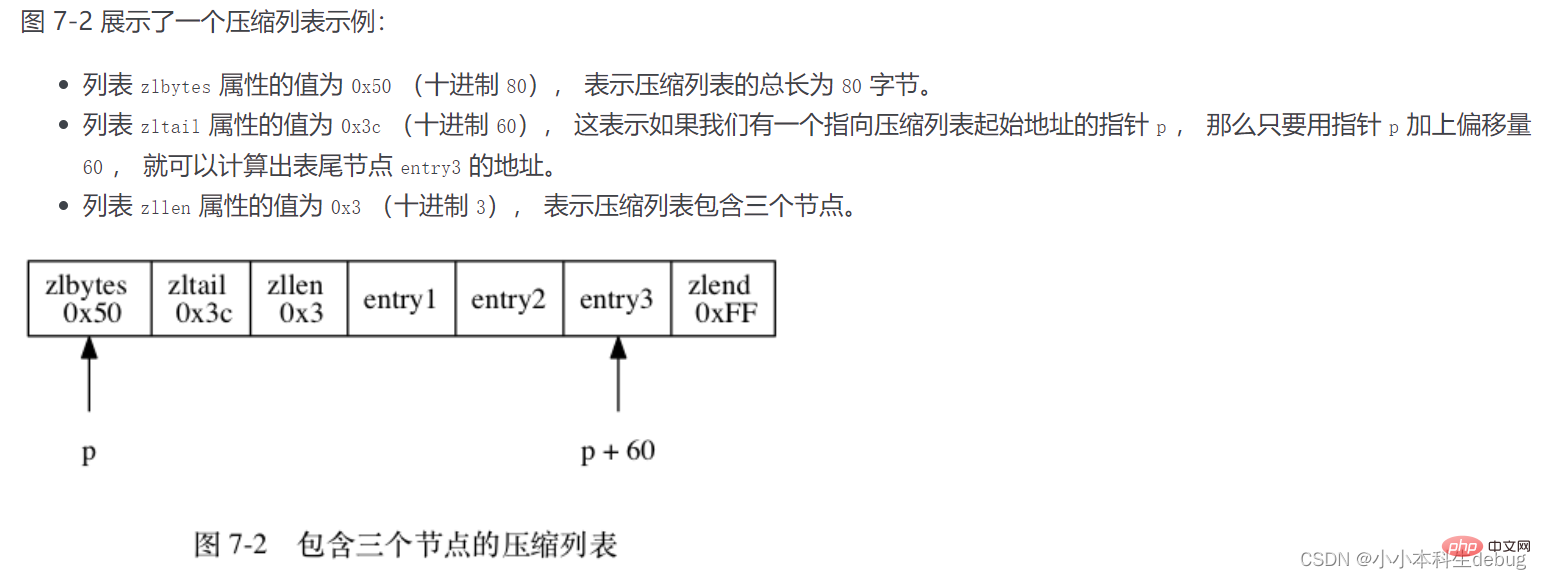
Chaque nœud de liste de compression est composé de trois parties : previous_entry_length, encoding et content
① previous_entry_ength : enregistre la longueur de l'octet précédent dans la liste de compression. La longueur de previous_entry_ength peut être de 1 ou 5 octets. Si la longueur du nœud précédent est inférieure à 254, le nœud n'a besoin que d'un octet pour représenter la longueur du nœud précédent. Si la longueur du nœud précédent est supérieure ou égale à 254, le premier octet de l'attribut est 254, et les quatre octets suivants représentent la longueur du nœud précédent du nœud actuel. En utilisant ce principe, la position de départ du nœud précédent est obtenue en soustrayant la longueur du nœud précédent de la position actuelle du nœud. La liste compressée peut être parcourue de la queue à la tête. Cela réduit efficacement le gaspillage de mémoire.
② encodage : l'encodage d'un nœud enregistre le type de contenu et la longueur du contenu du nœud. Il existe deux types d'encodage, l'un est un tableau d'octets et l'autre est un entier. La longueur de la zone d'encodage est de 1 octet, 2. octets ou 5 octets de long. 
③ contenu : La zone de contenu est utilisée pour enregistrer le contenu du nœud. Le type et la longueur du contenu du nœud sont déterminés par l'encodage. 
Problème de mise à jour de la chaîne
Dans le pire des cas, la mise à jour de la chaîne nécessite N opérations de réallocation d'espace sur la liste compressée, et la complexité dans le pire des cas de chaque réallocation d'espace est O(N), donc le coût minimum de la mise à jour de la chaîne est La mauvaise complexité est O(N^2).
Il convient de noter que bien que la complexité des mises à jour en chaîne soit élevée, le risque qu'elles provoquent réellement des problèmes de performances est très faible
Apprentissage recommandé : Tutoriel d'apprentissage Redis
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Explication détaillée des principes de persistance des techniques classiques de Redis
- Analyse détaillée de la façon d'optimiser Redis lorsque la mémoire est pleine
- Que dois-je faire si les caches à double écriture de Redis et MySQL sont incohérents ? Partage de solutions
- Analysons ensemble le mode sentinelle Redis
- Comment assurer la cohérence entre le cache Redis et la base de données