Parlons de l'algorithme LRU
consiste à filtrer les données selon le principe le moins récemment utilisé. Les données les moins fréquemment utilisées seront filtrées, tandis que les données récemment fréquemment utilisées resteront dans le cache.
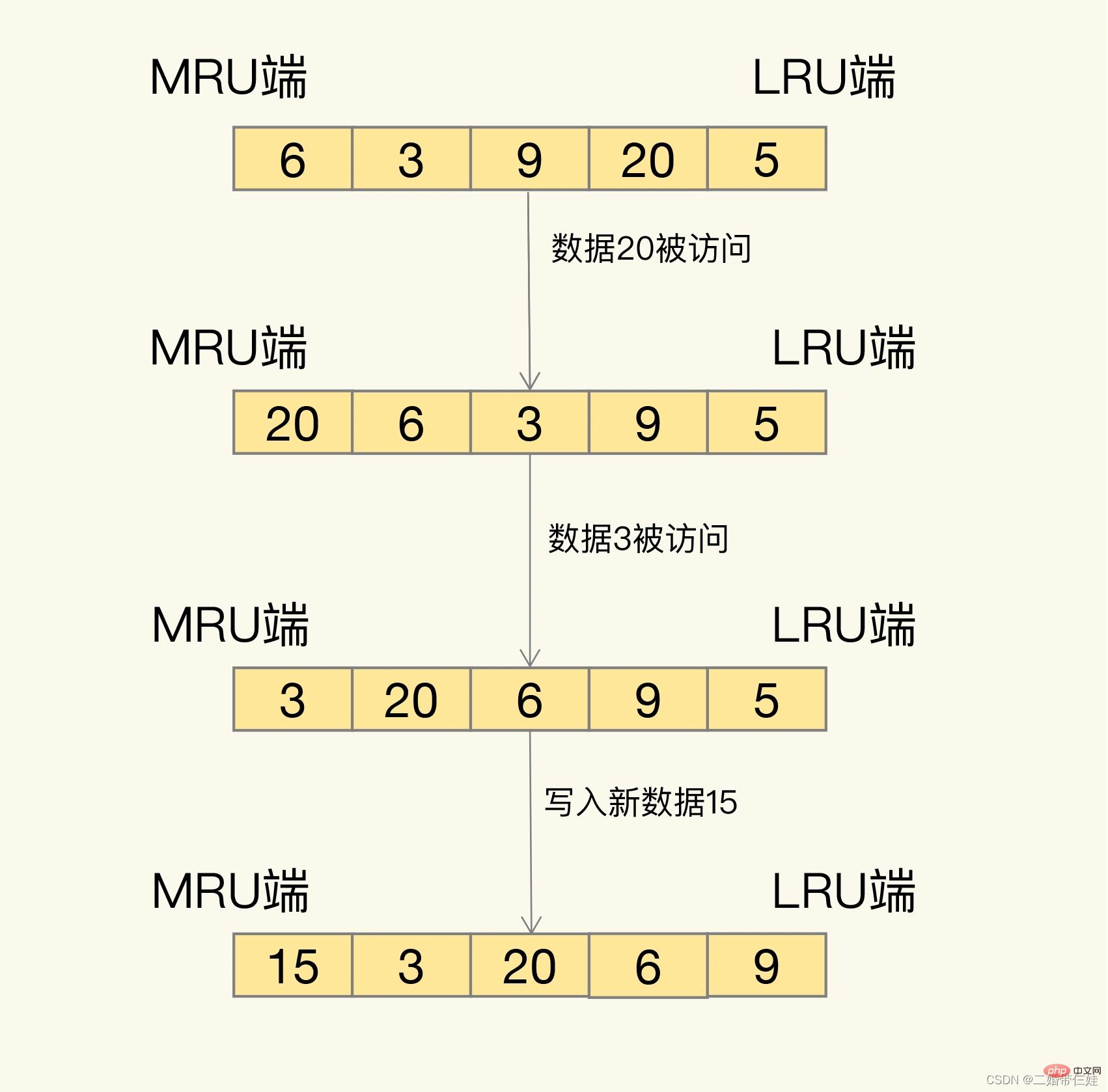
Alors, comment êtes-vous dépisté exactement ? LRU organisera toutes les données dans une liste chaînée. La tête et la queue de la liste chaînée représentent respectivement la fin MRU et la fin LRU, représentant les données les plus récemment utilisées et les données les plus récemment utilisées les moins couramment.

L'idée derrière l'algorithme LRU est très simple : il croit que les données qui viennent d'être consultées seront certainement consultées à nouveau, donc elles sont placées du côté MRU les données qui n'ont pas été consultées depuis longtemps le seront certainement ; ne sera plus accessible. Alors laissez-le revenir progressivement du côté LRU, et lorsque le cache est plein, supprimez-le d'abord.
Problème : Lorsque l'algorithme LRU est réellement implémenté, il doit utiliser une liste chaînée pour gérer toutes les données mises en cache, ce qui entraînera une surcharge d'espace supplémentaire. De plus, lors de l'accès aux données, les données doivent être déplacées vers le MRU sur la liste chaînée. Si une grande quantité de données est accédée, de nombreuses opérations de déplacement de liste chaînée se produiront, ce qui prendra beaucoup de temps et réduira les performances du cache Redis. .
Solution :
Dans Redis, l'algorithme LRU a été simplifié pour réduire l'impact de l'expulsion des données sur les performances du cache. Plus précisément, Redis enregistre par défaut l'horodatage d'accès le plus récent de chaque donnée (enregistré par le champ lru dans la structure de données de paire clé-valeur RedisObject). Ensuite, lorsque Redis déterminera les données à éliminer, il sélectionnera au hasard N éléments de données pour la première fois et les utilisera comme ensemble candidat. Ensuite, Redis comparera les champs lru de ces N données et éliminera du cache les données avec la plus petite valeur de champ lru.
Lorsque les données doivent être à nouveau éliminées, Redis doit sélectionner les données dans l'ensemble candidat créé lors de la première élimination. Le critère de sélection ici est le suivant : la valeur du champ lru des données pouvant entrer dans l'ensemble candidat doit être inférieure à la plus petite valeur lru de l'ensemble candidat. Lorsque de nouvelles données entrent dans l'ensemble de données candidats, si le nombre de données dans l'ensemble de données candidats atteint maxmemory-samples, Redis éliminera les données avec la plus petite valeur de champ lru dans l'ensemble de données candidats.
Suggestions d'utilisation :
- Utilisez d'abord la stratégie allkeys-lru. De cette façon, vous pouvez profiter pleinement des avantages de LRU, un algorithme de mise en cache classique, pour conserver dans le cache les données les plus récemment consultées et améliorer les performances d'accès aux applications. S'il existe une distinction évidente entre les données chaudes et froides dans vos données d'entreprise, je vous recommande d'utiliser la stratégie allkeys-lru.
- Si la fréquence d'accès aux données dans les applications métiers n'est pas très différente et qu'il n'y a pas de distinction évidente entre les données chaudes et froides, il est recommandé d'utiliser la stratégie tous touches aléatoires et de sélectionner aléatoirement les données éliminées.
- Si votre entreprise a besoin de données épinglées, telles que des actualités et des vidéos épinglées, vous pouvez utiliser la stratégie volatile-lru et ne pas définir de délai d'expiration pour ces données épinglées. De cette façon, les données qui doivent être épinglées ne seront jamais supprimées et les autres données seront filtrées selon les règles LRU à leur expiration.
Comment gérer les données éliminées ?
Une fois les données éliminées sélectionnées, si les données sont des données propres, nous les supprimerons directement ; si les données sont des données sales, nous devons les réécrire dans la base de données.
Alors, comment juger si une donnée est propre ou sale ?
- La différence entre les données propres et les données sales est de savoir si elles ont été modifiées par rapport à la valeur lors de leur lecture initiale à partir de la base de données principale. Les données propres n'ont pas été modifiées, donc les données de la base de données principale sont également la dernière valeur. Lors du remplacement, il peut être supprimé directement.
- Les données sales sont des données qui ont été modifiées et ne sont plus cohérentes avec les données stockées dans la base de données back-end. À ce stade, si les données sales ne sont pas réécrites dans la base de données, la dernière valeur de ces données sera perdue, ce qui affectera l'utilisation normale de l'application.
Même si les données éliminées sont des données sales, Redis ne les réécrira pas dans la base de données. Par conséquent, lorsque nous utilisons le cache Redis, si les données sont modifiées, elles doivent être réécrites dans la base de données lorsque les données sont modifiées. Sinon, lorsque les données sales seront éliminées, elles seront supprimées par Redis et il n'y aura aucune donnée la plus récente dans la base de données.
Comment Redis optimise-t-il la mémoire ?
1. Contrôler le nombre de clés : lorsque vous utilisez Redis pour stocker une grande quantité de données, il y a généralement un grand nombre de clés, et trop de clés consommeront également beaucoup de mémoire. Redis est essentiellement un serveur de structures de données, qui nous fournit une variété de structures de données, telles que des structures de hachage, de liste, d'ensemble, de zset et autres. Ne vous méprenez pas lorsque vous utilisez Redis. Utilisez largement des API telles que get/set et utilisez Redis comme Memcached. Pour stocker le même contenu de données, l'utilisation de la structure de données Redis pour réduire le nombre de clés externes peut également économiser beaucoup de mémoire.
2. Réduisez les objets clé-valeur. Le moyen le plus direct de réduire l'utilisation de la mémoire Redis est de réduire la longueur des clés et des valeurs.
- Longueur de la clé : lors de la conception des clés, lorsque l'entreprise est entièrement décrite, plus la valeur de la clé est courte, mieux c'est.
- Longueur de la valeur : la réduction des objets de valeur est plus compliquée. Une exigence courante consiste à sérialiser les objets métier dans des tableaux binaires et à les placer dans Redis. Tout d'abord, les objets métier doivent être rationalisés en termes d'activité et les attributs inutiles doivent être supprimés pour éviter de stocker des données invalides. Deuxièmement, en termes de sélection de l'outil de sérialisation, un outil de sérialisation plus efficace doit être sélectionné pour réduire la taille du tableau d'octets.
3. Optimisation du codage. Redis fournit des types externes tels que chaîne, liste, hachage, set, zet, etc., mais Redis a en interne le concept d'encodage pour différents types. Ce qu'on appelle l'encodage fait référence à la structure de données sous-jacente spécifique utilisée pour l'implémentation. Différents encodages affecteront directement l’utilisation de la mémoire et l’efficacité de lecture et d’écriture des données.
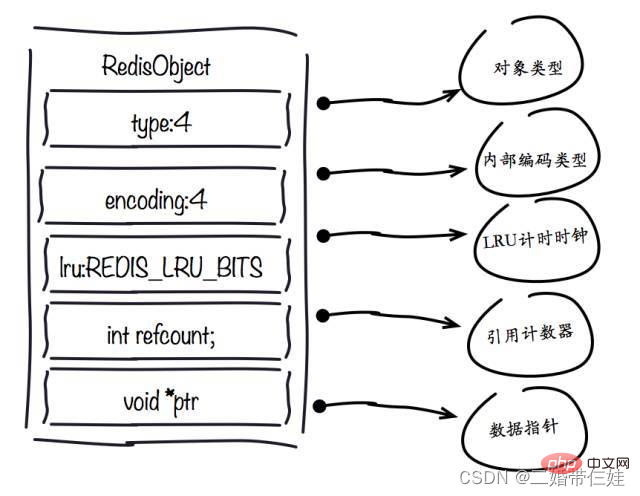
- 1. objet redisObject
champ de type :
Utilisez des données de type collection, car généralement de nombreuses petites valeurs-clés peuvent être stockées ensemble de manière plus compacte. Utilisez autant que possible les tables de hachage (ce qui signifie que le nombre stocké dans une table de hachage est petit) utilisent très peu de mémoire, vous devez donc autant que possible résumer votre modèle de données dans une table de hachage. Par exemple, s'il existe un objet utilisateur dans votre système Web, ne définissez pas de clé distincte pour le nom, le prénom, l'adresse e-mail et le mot de passe de l'utilisateur. Stockez plutôt toutes les informations de l'utilisateur dans une table de hachage.
champ d'encodage :
Il existe des différences évidentes dans l'utilisation de la mémoire en utilisant différents encodages
champ lru :
Conseil de développement : vous pouvez utiliser la commande scan + object ralenti pour interroger par lots quelles clés n'ont pas été accédées pendant une longue période. Recherchez les clés de nettoyage qui n'ont pas été utilisées depuis longtemps pour réduire l'utilisation de la mémoire.
refcount field :
Lorsque l'objet est un entier et que la plage est [0-9999], Redis peut utiliser des objets partagés pour économiser de la mémoire.
ptr field :
Conseil de développement : dans les scénarios d'écriture simultanée élevée, il est recommandé que la longueur de la chaîne soit contrôlée dans les 39 octets si les conditions le permettent, afin de réduire le nombre d'allocations de mémoire pour créer redisObject et améliorer les performances.
- 2. Réduire les objets clé-valeur
Le moyen le plus direct de réduire l'utilisation de la mémoire Redis est de réduire la longueur des clés et des valeurs.
Vous pouvez utiliser un algorithme de compression général pour compresser json et xml avant de les stocker dans Redis, réduisant ainsi l'utilisation de la mémoire
- 3. Pool d'objets partagés
Le pool d'objets partagés fait référence au pool d'objets entiers [0-9999. ] maintenu en interne par Redis. La création d'un grand nombre de redisObjects de type entier implique une surcharge de mémoire. La structure interne de chaque redisObject occupe au moins 16 octets, ce qui dépasse même la consommation d'espace de l'entier lui-même. Par conséquent, la mémoire Redis conserve un pool d'objets entiers [0-9999] pour économiser de la mémoire. En plus des objets de valeur entière, d'autres types tels que les éléments internes list, hash, set et zset peuvent également utiliser des pools d'objets entiers. Par conséquent, en développement, dans le but de répondre aux exigences, essayez d'utiliser des objets entiers pour économiser de la mémoire.
Lorsque maxmemory est défini et que les stratégies d'élimination liées à LRU sont activées telles que : volatile-lru, allkeys-lru, Redis interdit l'utilisation de pools d'objets partagés.
Pourquoi le pool d'objets est-il invalide après avoir activé maxmemory et la stratégie d'élimination LRU ?
L'algorithme LRU doit obtenir le dernier temps d'accès de l'objet afin d'éliminer les données non visitées les plus longues ? est stocké dans le champ lru de l'objet redisObject. Le partage d'objet signifie que plusieurs références partagent le même redisObject. À ce moment, le champ lru sera également partagé, ce qui rendra impossible l'obtention du dernier temps d'accès de chaque objet. Si maxmemory n'est pas défini, Redis ne déclenchera pas le recyclage de la mémoire jusqu'à ce que la mémoire soit épuisée, afin que le pool d'objets partagés puisse fonctionner normalement.
En résumé, le pool d'objets partagés est en conflit avec la stratégie maxmemory+LRU, vous devez donc faire attention lorsque vous l'utilisez.
Pourquoi uniquement un pool d'objets entiers ?
Tout d'abord, le pool d'objets entiers a la probabilité de réutilisation la plus élevée. Deuxièmement, une opération clé du partage d'objets est de juger de l'égalité. La raison pour laquelle Redis n'a qu'un pool d'objets entiers est que la complexité temporelle de l'algorithme de comparaison d'entiers est élevée. O(1), et seulement 10 000 sont conservés pour éviter le gaspillage du pool d’objets. Si l'égalité des chaînes est jugée, la complexité temporelle devient O(n), en particulier les chaînes longues consomment plus de performances (les nombres à virgule flottante sont stockés en interne dans Redis à l'aide de chaînes). Pour les structures de données plus complexes telles que le hachage, la liste, etc., le jugement d'égalité nécessite O(n2). Pour Redis monothread, une telle surcharge est évidemment déraisonnable, donc Redis ne conserve qu'un pool d'objets partagés entier.
- 4. Optimisation des chaînes
Redis n'utilise pas le type chaîne du langage C natif mais implémente sa propre structure de chaîne, avec une chaîne dynamique simple interne, appelée SDS.
Structure de chaîne :
- Caractéristiques :
O(1) acquisition de la complexité temporelle : longueur de chaîne, longueur utilisée, longueur inutilisée.
Peut être utilisé pour enregistrer des tableaux d'octets et prend en charge le stockage sécurisé de données binaires.
Implémente en interne un mécanisme de pré-allocation d'espace pour réduire le nombre de réallocations de mémoire.
Mécanisme de suppression paresseuse, l'espace après la réduction de la chaîne n'est pas libéré et est réservé comme espace pré-alloué.
Mécanisme de pré-allocation :
- Conseils de développement : essayez de réduire les opérations fréquentes de modification de chaînes telles que append et setrange, utilisez plutôt directement set pour modifier les chaînes afin de réduire le gaspillage de mémoire et la fragmentation de la mémoire causée par la pré-allocation.
String reconstruction : Une méthode d'encodage secondaire basée sur le type de hachage.
- Comment utiliser l'encodage secondaire ?
La longueur d'identification utilisée dans la méthode d'encodage secondaire est particulière.
Cela implique un problème : lorsque la structure sous-jacente du type Hash est plus petite que la valeur définie, une liste compressée est utilisée, et lorsqu'elle est plus grande que la valeur définie, une table de hachage est utilisée.
Une fois converti d'une liste compressée en table de hachage, le type de hachage sera toujours enregistré dans la table de hachage et ne sera pas reconverti en liste compressée.
En termes d'économie d'espace mémoire, les tables de hachage ne sont pas aussi efficaces que les listes compressées. Afin d'utiliser pleinement la disposition compacte de la mémoire de la liste compressée, il est généralement nécessaire de contrôler le nombre d'éléments stockés dans le hachage.
- 5. Optimisation de l'encodage
Le type de hachage codé par ziplist économise encore beaucoup de mémoire que l'ensemble codé par hashtable.
- 6. Contrôlez le nombre de clés
Conseil de développement : après avoir utilisé ziplist+hash pour optimiser les clés, si vous souhaitez utiliser la fonction de suppression du délai d'attente, les développeurs peuvent stocker le temps d'écriture de chaque objet, puis utiliser hscan via les tâches planifiées Utilisez la commande pour analyser les données, rechercher les éléments de données de délai d'attente dans le hachage et les supprimer.
Lorsque Redis manque de mémoire, la première considération est de ne pas ajouter de machines pour une expansion horizontale. Vous devriez d'abord essayer d'optimiser la mémoire. Lorsque vous rencontrez un goulot d’étranglement, envisagez une expansion horizontale. Même pour les solutions de clustering, l'optimisation au niveau vertical est tout aussi importante pour éviter un gaspillage inutile de ressources et des coûts de gestion après le clustering.
Apprentissage recommandé : Tutoriel Redis