
Maison >interface Web >js tutoriel >Conseils d'optimisation ! ! Une recrue front-end accélère l'interface de 60 %
Conseils d'optimisation ! ! Une recrue front-end accélère l'interface de 60 %

- coldplay.xixiavant
- 2020-11-11 17:28:012248parcourir
La rubrique
javascript présente des techniques destinées aux novices du front-end pour accélérer les interfaces de 60 %.

Contexte
Je n'ai pas écrit d'article depuis longtemps et je suis resté silencieux pendant plus de six mois
Malaise persistant, crises d'épilepsie intermittentes
Je viens chez mon oncle tous les jours et je passe chaque jour dans la confusion et l'anxiété
Je dois admettre que je suis en fait un déchet
En tant qu'ingénieur front-end de bas niveau
Récemment, j'ai eu affaire à une ancienne interface qui se transmet depuis plus de dix ans
Elle a hérité de toute la logique de complexité suprême
On dit qu'un seul appel peut augmenter la charge CPU de 90% chaque jour.
Spécialisé dans le traitement des insatisfactions diverses et de la maladie d'Alzheimer
Apprécions le temps chronophage de cette interface
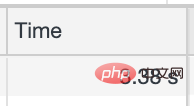
Le temps d'appel moyen est supérieur à 3s
Entraînant de sérieux chrysanthèmes sur la page
Après diverses analyses approfondies et questions/réponses avec des professionnels
La conclusion finale est : abandonnez le traitement médical
Lu Xun dans "Journal d'un fou" "J'ai dit un jour : "能打败我的,只有女人和酒精,而不是bug"
Chaque fois que je suis obscurité
Cette phrase me fait toujours voir la lumière
Donc cette fois je vais m'endurcir
J'ai décidé de créer une couche proxy de nœud
et d'optimiser il en utilisant les trois méthodes suivantes :
按需加载 -> graphQL数据缓存 -> redis轮询更新 -> schedule
Adresse du code : github
Chargement à la demande - > graphQL
Il y a un problème avec l'ancienne interface de Tianxiu à chaque fois que nous demandons. 1000 éléments de données, chaque élément de données du tableau renvoyé contient des centaines de champs. En fait, notre frontal n'en utilise que 10. Juste un champ.
Comment extraire n champs quelconques de plus d'une centaine de champs, cela utilise graphQL.
GraphQL n'a besoin que de trois étapes pour charger des données à la demande :
- Définir la racine du pool de données
- Décrire le schéma de structure des données dans le pool de données
- Personnaliser la requête de données de requête
Définir le pool de données
Nous définissons un pool de données pour la scène où Diaosi poursuit la déesse, comme suit :
// 数据池var root = { girls: [{ id: 1, name: '女神一', iphone: 12345678910, weixin: 'xixixixi', height: 175, school: '剑桥大学', wheel: [{ name: '备胎1号', money: '24万元' }, { name: '备胎2号', money: '26万元' }]
},
{ id: 2, name: '女神二', iphone: 12345678910, weixin: 'hahahahah', height: 168, school: '哈佛大学', wheel: [{ name: '备胎3号', money: '80万元' }, { name: '备胎4号', money: '200万元' }]
}]
}复制代码
Il y a toutes les données des deux déesses qu'il contient Informations, y compris le nom de la déesse, le téléphone portable, WeChat, la taille, l'école, la collecte des pneus de secours et d'autres informations.
Ensuite, nous décrirons ces structures de données.
Décrivez la structure des données dans le pool de données
const { buildSchema } = require('graphql');// 描述数据结构 schemavar schema = buildSchema(`
type Wheel {
name: String,
money: String
}
type Info {
id: Int
name: String
iphone: Int
weixin: String
height: Int
school: String
wheel: [Wheel]
}
type Query {
girls: [Info]
}
`);复制代码
Le code ci-dessus est le schéma des informations de la déesse.
Nous utilisons d'abord type Query pour définir une requête d'informations sur la déesse, qui contient beaucoup d'informations sur les filles Info Ces informations sont un tas de tableaux, elles sont donc [Info]
, y compris son nom, son téléphone portable (iphone), WeChat (weixin), sa taille (taille), son école (école) et la collection de pneus de secours (roue) type Info
const { graphql } = require('graphql');// 定义查询内容const query = `
{
girls {
name
weixin
}
}
`;// 查询数据const result = await graphql(schema, query, root)复制代码 Les résultats du filtrage sont les suivants :

const { graphql } = require('graphql');// 定义查询内容const query = `
{
girls {
name
wheel {
money
}
}
}
`;// 查询数据const result = await graphql(schema, query, root)复制代码Les résultats du filtre sont les suivants :

Vos vrais sentiments ne valent pas la peine d'être mentionnés devant des célébritésNous devons apprendre à faire ce qu'elles veulentMontrez vos clés de voiture lorsque vous montez, et montrez vos talents si vous je n'ai pas de voitureCe soir j'ai un chromosome ancestral que je veux partager avec toi Si ça marche, alors change pour un autre Allez directement à le sujet, simple et brut Cache-> redis
La deuxième méthode d'optimisation consiste à utiliser le cache redis
天秀老接口内部调用了另外三个老接口,而且是串行调用,极其耗时耗资源,秀到你头皮发麻
我们用redis来缓存天秀接口的聚合数据,下次再调用天秀接口,直接从缓存中获取数据即可,避免高耗时的复杂调用,简化后代码如下:
const redis = require("redis");const { promisify } = require("util");// 链接redis服务const client = redis.createClient(6379, '127.0.0.1');// promise化redis方法,以便用async/awaitconst getAsync = promisify(client.get).bind(client);const setAsync = promisify(client.set).bind(client);async function list() { // 先获取缓存中数据,没有缓存就去拉取天秀接口
let result = await getAsync("缓存"); if (!result) { // 拉接口
const data = await 天秀接口();
result = data; // 设置缓存数据
await setAsync("缓存", data)
} return result;
}
list();
复制代码
先通过getAsync来读取redis缓存中的数据,如果有数据,直接返回,绕过接口调用,如果没有数据,就会调用天秀接口,然后setAsync更新到缓存中,以便下次调用。因为redis存储的是字符串,所以在设置缓存的时候,需要加上JSON.stringify(data),为了便于大家理解,我就不加了,会把具体细节代码放在github中。
将数据放在redis缓存里有几个好处
可以实现多接口复用、多机共享缓存
这就是传说中的云备胎
追求一个女神的成功率是1%
同时追求100个女神,那你获取到一个女神的概率就是100%
鲁迅《狂人日记》里曾说过:“舔一个是舔狗,舔一百个你就是战狼”
你是想当舔狗还是当战狼?
来吧,缓存用起来,redis用起来
轮询更新 -> schedule
最后一个优化手段:轮询更新 -> schedule
女神的备胎用久了,会定时换一批备胎,让新鲜血液进来,发现新的快乐
缓存也一样,需要定时更新,保持与数据源的一致性,代码如下:
const schedule = require('node-schedule');// 每个小时更新一次缓存schedule.scheduleJob('* * 0 * * *', async () => { const data = await 天秀接口(); // 设置redis缓存数据
await setAsync("缓存", data)
});复制代码
天秀接口不是一个强实时性接口,数据源一周可能才会变一次
所以我们根据实际情况用轮询来设置更新缓存频率
我们用node-schedule这个库来轮询更新缓存,* * 0 * * *这个的意思就是设置每个小时的第0分钟就开始执行缓存更新逻辑,将获取到的数据更新到缓存中,这样其他接口和机器在调用缓存的时候,就能获取到最新数据,这就是共享缓存和轮询更新的好处。
早年我在当舔狗的时候,就将轮询机制发挥到淋漓尽致
每天向白名单里的女神,定时轮询发消息
无限循环云跪舔三件套:
- “啊宝贝,最近有没有想我”
- “啊宝贝早安安”
- “宝贝晚安,么么哒”
虽然女神依然看不上我
但仍然时刻准备着为女神服务
结尾
经过以上三个方法优化后
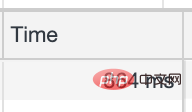
接口请求耗时从3s降到了860ms
这些代码都是从业务中简化后的逻辑
真实的业务场景远比这要复杂:分段式数据存储、主从同步 读写分离、高并发同步策略等等
每一个模块都晦涩难懂
就好像每一个女神都高不可攀
屌丝战胜了所有bug,唯独战胜不了她的心
受伤了只能在深夜里独自买醉
但每当梦到女神打开我做的页面
被极致流畅的体验惊艳到
在精神高潮中享受灵魂升华
那一刻
我觉得我又行了
(完)
相关免费学习推荐:JavaScript(视频)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!