
Conception de systèmes Java à haute concurrence – Cache

- coldplay.xixiavant
- 2020-10-10 17:24:122251parcourir
La colonne
Bases de Java présente aujourd'hui le chapitre sur la mise en cache de la conception de systèmes Java à haute concurrence.

La latence des composants matériels courants est la suivante : 
À partir de ces données, vous pouvez voir que faire un adressage mémoire prend environ 100 ns et une recherche de disque prend 10 ms. On peut voir que lorsque nous utilisons la mémoire comme support de stockage de cache, les performances seront améliorées de plusieurs ordres de grandeur par rapport à une base de données qui utilise le disque comme support de stockage principal. La mémoire est donc le support le plus courant pour la mise en cache des données.
1. Cas de cache
1. TLB
La gestion de la mémoire Linux est implémentée de l'adresse virtuelle à l'adresse physique via un élément matériel appelé MMU (Memory Management Unit Converted). , mais si des calculs aussi complexes sont nécessaires pour chaque conversion, cela entraînera sans aucun doute des pertes de performances, nous utiliserons donc un composant appelé TLB (Translation Lookaside Buffer) pour mettre en cache les adresses virtuelles et le mappage des adresses physiques récemment converties. TLB est un composant de mise en cache.
2. Les courtes vidéos sur la plateforme Douyin
sont en fait réalisées à l'aide du lecteur réseau intégré. Le lecteur réseau reçoit le flux de données, télécharge les données, sépare les flux audio et vidéo, décode et autres processus, puis les transmet au périphérique pour la lecture. Certains composants de mise en cache sont généralement conçus dans le lecteur pour mettre en cache une partie des données vidéo lorsque la vidéo n'est pas ouverte. Par exemple, lorsque nous ouvrons Douyin, le serveur peut renvoyer trois informations vidéo à la fois lorsque nous lisons la première vidéo. player Nous avons mis en cache une partie des données des deuxième et troisième vidéos pour nous, afin que lorsqu'ils regardent la deuxième vidéo, nous puissions donner aux utilisateurs le sentiment de "démarrer en quelques secondes".
3. Mise en cache du protocole HTTP
Lorsque nous demandons une ressource statique pour la première fois, comme une image, en plus de renvoyer les informations sur l'image, le serveur dispose également d'un "Etag" dans le champ d’en-tête de réponse. Le navigateur mettra en cache les informations sur l'image et la valeur de ce champ. La prochaine fois que l'image sera demandée, il y aura un champ « If-None-Match » dans l'en-tête de la requête initiée par le navigateur, et la valeur « Etag » mise en cache y sera écrite et envoyée au serveur. Le serveur vérifie si les informations sur l'image ont changé. Dans le cas contraire, un code d'état 304 est renvoyé au navigateur et celui-ci continuera à utiliser les informations sur l'image mises en cache. Grâce à cette méthode de négociation de cache, la taille des données transmises sur le réseau peut être réduite, améliorant ainsi les performances d'affichage des pages. 
2. Classification du cache
1. Le cache statique
Le cache statique est très célèbre à l'ère du Web 1.0. Il génère généralement des modèles Velocity ou des fichiers HTML statiques. Pour implémenter la mise en cache statique, le déploiement d'un cache statique sur Nginx peut réduire la pression sur le serveur d'applications backend
2. Cache distribué
Le nom du cache distribué est très familier, et nous le connaissons généralement Memcached et Redis sont des exemples typiques de cache distribué. Ils ont de solides performances et peuvent dépasser les limites d'une seule machine en formant un cluster via certaines solutions distribuées. Par conséquent, dans l'architecture globale, le cache distribué joue un rôle très important
3 Cache local
Guava Cache ou Ehcache, etc., ils sont déployés dans le même processus que l'application Avantages. Il ne nécessite pas de planification inter-réseaux et est extrêmement rapide, il peut donc être utilisé pour bloquer les requêtes chaudes dans un court laps de temps.
3. Stratégie de lecture et d'écriture du cache
1. La stratégie Cache Aside
ne met pas à jour le cache lors de la mise à jour des données, mais supprime les données dans le cache et lit les données. Lorsque, après avoir découvert qu'il n'y a aucune donnée dans le cache, les données sont lues dans la base de données et mises à jour dans le cache. 
Cette stratégie est la stratégie la plus courante que nous utilisons pour mettre en cache, la stratégie Cache Aside (également appelée stratégie de contournement du cache), les données de cette stratégie sont basées sur les données de la base de données et les données dans le cache est chargé à la demande.
La stratégie Cache Aside est la stratégie de mise en cache la plus couramment utilisée dans notre développement quotidien. Cependant, nous devons également apprendre à changer en fonction de la situation lors de son utilisation. Le plus gros problème avec Cache Aside est que lorsque les écritures sont fréquentes, les données du cache seront fréquemment effacées, ce qui aura un certain impact sur le taux de réussite du cache. Si votre entreprise a des exigences strictes en matière de taux de réussite du cache, vous pouvez envisager deux solutions :
Une approche consiste à mettre à jour le cache lors de la mise à jour des données, mais à ajouter un verrou distribué avant de mettre à jour le cache, car de cette manière, un seul thread est autorisé à mettre à jour le cache en même temps et les problèmes de concurrence ne se produiront pas. Bien sûr, cela aura un certain impact sur les performances d'écriture (recommandé).
Une autre approche consiste à mettre à jour le cache lors de la mise à jour des données, mais ajoutez simplement un délai d'expiration plus court au cache, de sorte que même s'il y a un cache En cas d'incohérence, les données mises en cache expireront rapidement et l'impact sur l'entreprise est acceptable.
2. Lecture/écriture
Le principe de base de cette stratégie est que les utilisateurs ne gèrent que le cache, et le cache communique avec la base de données pour écrire ou lire des données. La stratégie de 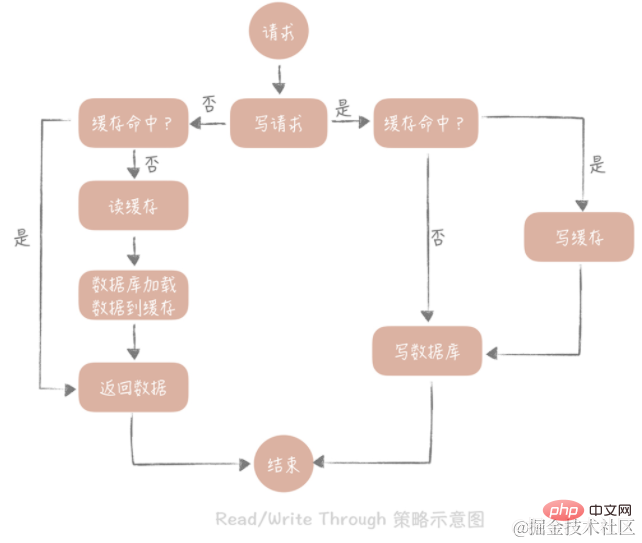
Write Through
est la suivante : d'abord demander si les données à écrire existent déjà dans le cache, et si elles existent déjà, mettre à jour le cache Les données dans le cache sont synchronisées et mises à jour dans la base de données par le composant cache. Si les données dans le cache n'existent pas, nous appelons cette situation « Write Miss ». D'une manière générale, nous pouvons choisir deux méthodes « Write Miss » : l'une est « Write Allocate (distribute by write) », qui consiste à écrire l'emplacement correspondant dans le cache, puis le composant de cache le met à jour de manière synchrone dans la base de données ; est "Pas d'allocation en écriture (ne pas allouer en écriture)", la méthode ne consiste pas à écrire dans le cache, mais à mettre à jour directement dans la base de données. Nous voyons que l'écriture dans la base de données dans la stratégie Write Through est synchrone, ce qui aura un impact plus important sur les performances, car par rapport à l'écriture du cache, la latence de l'écriture synchrone dans la base de données est beaucoup plus élevée. Mettez à jour la base de données de manière asynchrone via la stratégie Write Back.
Read Through
La stratégie est plus simple. Ses étapes sont les suivantes : demandez d'abord si les données dans le cache existent, et si elles existent, renvoyez-les directement. S'il n'existe pas, le composant cache est responsable du chargement synchrone des données de la base de données.
3. Réécrire
L'idée principale de cette stratégie est d'écrire dans le cache uniquement lors de l'écriture de données et de marquer les blocs de cache comme "sales". Les données des blocs modifiés ne seront écrites dans le stockage principal que lorsqu'elles seront réutilisées.
Dans le cas de "Write Miss", nous utilisons la méthode "Write Allocate", qui signifie écrire dans le cache tout en écrivant sur le stockage backend, de sorte que nous n'ayons besoin de mettre à jour le cache que lors des requêtes d'écriture suivantes, sans mettre à jour le backend. stockage. Notez la distinction avec la stratégie d'écriture ci-dessus. 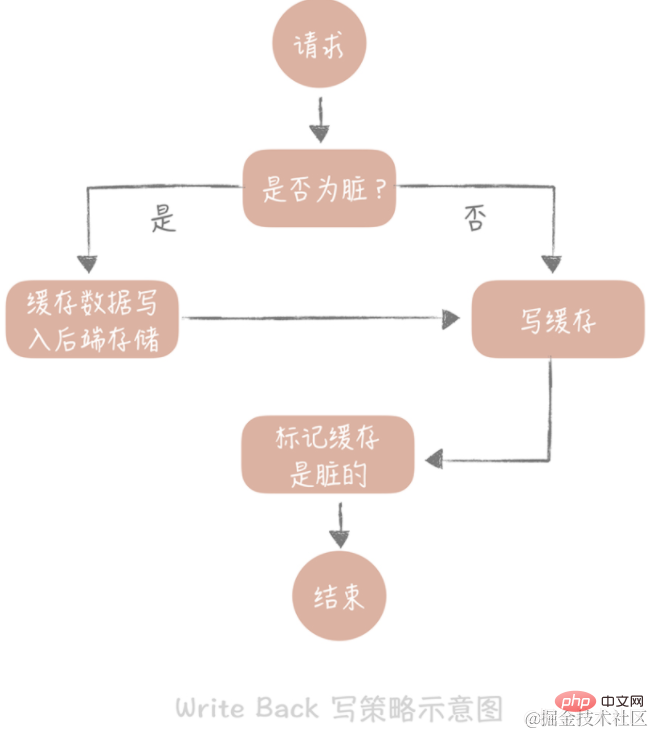
Si nous trouvons un hit de cache lors de la lecture du cache, nous renverrons directement les données du cache. Si le cache manque, il recherche un bloc de cache disponible. Si le bloc de cache est « sale », les données précédentes du bloc de cache sont écrites dans le stockage principal et les données sont chargées depuis le stockage principal vers. le cache. Si le bloc n'est pas sale, le composant de cache chargera les données du stockage back-end dans le cache. Enfin, nous configurerons le cache pour qu'il ne soit pas sale et renverrons les données. 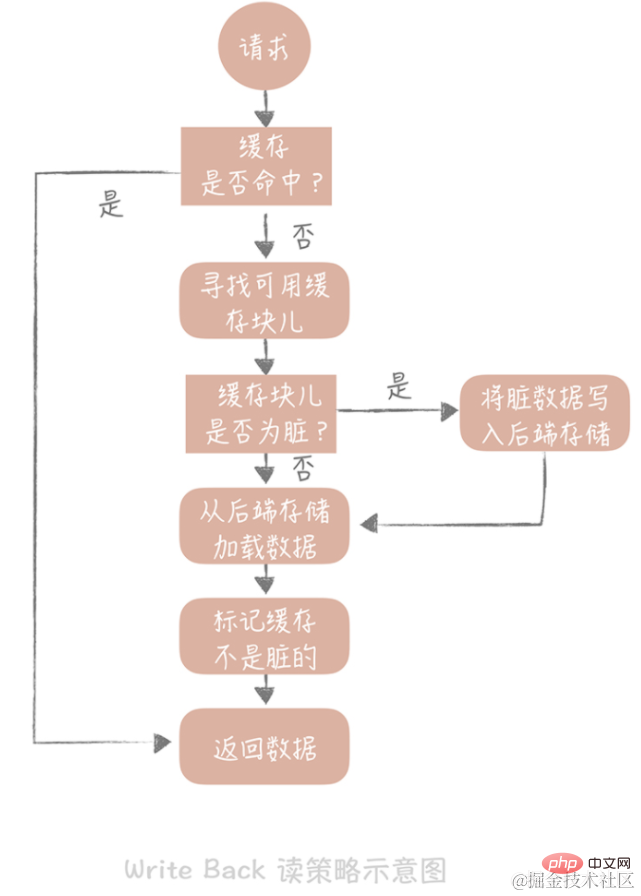
La stratégie de réécriture est principalement utilisée pour écrire des données sur le disque. Par exemple : cache de pages au niveau du système d'exploitation, vidage asynchrone des journaux, écriture asynchrone des messages dans la file d'attente des messages sur le disque, etc. L'avantage de cette stratégie en termes de performances étant incontestable, elle évite le problème d'écriture aléatoire provoqué par l'écriture directe sur le disque. Après tout, la latence des E/S aléatoires pour l'écriture en mémoire et l'écriture sur disque est différente de plusieurs ordres de grandeur.
4. Haute disponibilité du cache
Le taux de réussite du cache est un indicateur de données qui doit être surveillé par le cache. La haute disponibilité du cache peut réduire la probabilité de pénétration du cache à un certain niveau. mesure et améliorer la stabilité du système. Les solutions haute disponibilité pour la mise en cache comprennent principalement trois catégories : les solutions côté client, les solutions de couche proxy intermédiaire et les solutions côté serveur :
1. Solution côté client
Côté client. solution, vous devez faire attention à la mise en cache. Les aspects d'écriture et de lecture : Lors de l'écriture de données, les données écrites dans le cache doivent être distribuées sur plusieurs nœuds, c'est-à-dire qu'un partitionnement des données est effectué ; Lors de la lecture des données, plusieurs ensembles de caches peuvent être utilisés pour la tolérance aux pannes afin d'améliorer la disponibilité du système de cache. Concernant la lecture des données, deux stratégies, maître-esclave et multi-copie, peuvent être utilisées ici. Les deux stratégies sont proposées pour résoudre des problèmes différents. Les détails spécifiques de mise en œuvre incluent : partage de données, maître-esclave, copies multiples
partage de données
Algorithme de hachage cohérent. Dans cet algorithme, nous organisons l'intégralité de l'espace de valeur de hachage dans un anneau virtuel, puis hachons l'adresse IP ou le nom d'hôte du nœud de cache et le plaçons sur l'anneau. Lorsque nous devons déterminer à quel nœud il faut accéder à une certaine clé, nous effectuons d'abord la même valeur de hachage pour la clé, déterminons sa position sur l'anneau, puis "marchons" sur l'anneau dans le sens des aiguilles d'une montre lorsque nous rencontrons The. le premier nœud de cache est le nœud auquel accéder. 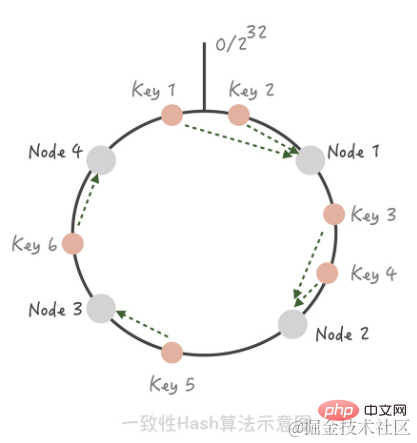
À ce stade, si vous ajoutez un nœud 5 entre le nœud 1 et le nœud 2, vous pouvez voir que la clé 3 qui a initialement touché le nœud 2 atteint désormais le nœud 5, tandis que les autres clés n'ont pas changé ; De la même manière, si nous supprimons le nœud 3 du cluster, cela n'affectera que la clé 5. Ainsi, vous voyez, lors de l'ajout et de la suppression de nœuds, seul un petit nombre de clés « dériveront » vers d'autres nœuds, tandis que les nœuds touchés par la plupart des clés resteront inchangés, garantissant ainsi que le taux de réussite ne diminuera pas de manière significative. [Astuce] Utilisez des nœuds virtuels pour résoudre le phénomène d'avalanche de cache qui se produit avec un hachage cohérent. La différence entre le partage de hachage cohérent et le partage de hachage réside dans le problème du taux de réussite du cache. Lorsque le partage de hachage est ajouté ou réduit, le cache deviendra invalide et le taux de réussite du cache diminuera.
Maître-esclave
Redis lui-même prend en charge la méthode de déploiement maître-esclave, mais Memcached ne la prend pas en charge Comment le mécanisme maître-esclave de Memcached est-il implémenté sur le. client. Configurez un ensemble d'esclaves pour chaque groupe de maîtres Lors de la mise à jour des données, les maîtres et les esclaves sont mis à jour simultanément. Lors de la lecture, les données sont d'abord lues à partir de l'esclave. Si les données ne peuvent pas être lues, elles sont lues via le maître et les données sont renvoyées vers l'esclave pour garder les données de l'esclave au chaud. Le plus grand avantage du mécanisme maître-esclave est que lorsqu'un certain esclave tombe en panne, le maître sera la sauvegarde, donc il n'y aura pas un grand nombre de requêtes pénétrant dans la base de données, ce qui améliore la haute disponibilité du système de cache.
Copies multiples
La méthode maître-esclave peut déjà résoudre les problèmes dans la plupart des scénarios, mais pour les scénarios de trafic extrêmes, un groupe d'esclaves ne peut généralement pas supporter entièrement le fardeau . Pour tout le trafic, la bande passante de la carte réseau esclave peut devenir un goulot d'étranglement. Afin de résoudre ce problème, nous envisageons d'ajouter une couche de copie avant Maître/Esclave. L'architecture globale est la suivante : 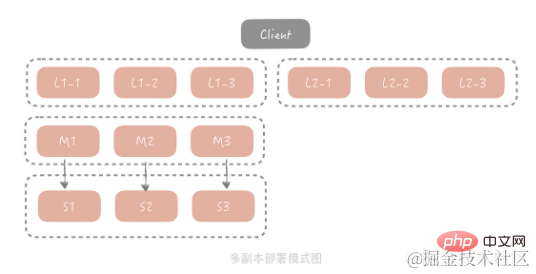
Dans cette solution, lorsque le client initie une requête de requête, la requête sera en premier. être envoyé depuis Sélectionnez un groupe de copie parmi plusieurs groupes de copie pour lancer une requête. Si la requête échoue, la requête continue vers le maître/esclave et les résultats de la requête sont renvoyés à tous les groupes de copie pour éviter l'existence de données sales dans le groupe. groupe de copie. Pour des raisons de coût, la capacité de chaque groupe de copie est inférieure à celle du maître et de l'esclave, de sorte qu'il stocke uniquement les données les plus chaudes. Dans cette architecture, le volume de requêtes du Maître et de l'Esclave sera fortement réduit. Afin d'assurer la chaleur des données qu'ils stockent, en pratique nous utiliserons le Maître et l'Esclave comme groupe de copie.
2. Couche proxy intermédiaire
Il existe également de nombreuses solutions de couche proxy intermédiaire dans l'industrie, telles que Mcrouter de Facebook, Twemproxy de Twitter et Codis de Wandoujia. Leurs principes peuvent essentiellement être résumés par une image : 
3. Solution serveur
Redis a proposé le mode Redis Sentinel dans la version 2.4 pour résoudre le problème du déploiement maître-esclave de Redis High. problème de disponibilité, il peut automatiquement promouvoir le nœud esclave en nœud maître après le raccrochement du nœud maître, garantissant ainsi la disponibilité de l'ensemble du cluster. L'architecture globale est présentée dans la figure ci-dessous : 
redis Sentinel. est également un déploiement en cluster, cela peut éviter le problème de récupération automatique après panne causée par la défaillance du nœud Sentinel. Chaque nœud Sentinel est sans état. L'adresse du maître sera configurée dans Sentinel. Sentinel surveillera l'état du maître à tout moment. Lorsqu'il s'avère que le maître ne répond pas dans l'intervalle de temps configuré, il sera considéré que le maître est mort. sélectionnera l'un des nœuds esclaves et le promouvra au rang de nœud maître, et traitera tous les autres nœuds esclaves comme des nœuds esclaves pour le nouveau maître. Lors de l'arbitrage au sein du cluster Sentinel, cela sera déterminé en fonction de la valeur configurée. Lorsque plusieurs nœuds Sentinel pensent que le maître est en panne, ils peuvent effectuer une opération de basculement maître-esclave. Autrement dit, le cluster doit parvenir à un consensus sur ce point. l'état du nœud de cache.
[Astuce] La connexion entre le client ci-dessus et le cluster sentinelle est une ligne pointillée, car les requêtes d'écriture et de lecture pour le cache ne passeront pas par le nœud Sentinel.
5. Pénétration du cache
1. Pareto
Le modèle d'accès aux données des systèmes Internet suit généralement le « principe 80/20 ». Le « principe 80/20 », également connu sous le nom de principe de Pareto, est une théorie économique proposée par l'économiste italien Pareto. En termes simples, cela signifie que dans un ensemble de choses, la partie la plus importante ne représente généralement que 20 %, tandis que les 80 % restants ne sont pas si importants. En appliquant cela au domaine de l’accès aux données, nous accéderons fréquemment à 20 % des données chaudes, tandis que les 80 % restants ne seront pas fréquemment consultés. Étant donné que la capacité du cache est limitée et que la plupart des accès ne demanderont que 20 % des données du hotspot, en théorie, nous n'avons besoin que de stocker 20 % des données du hotspot dans l'espace de cache limité pour protéger efficacement le fragile système back-end. peut renoncer à la mise en cache des 80 % restants des données non chaudes. Cette petite pénétration du cache est donc inévitable, mais elle ne nuit pas au système.
2. Renvoyer une valeur nulle
Lorsque nous interrogeons une valeur nulle dans la base de données ou qu'une exception se produit, nous pouvons renvoyer une valeur nulle au cache. Cependant, comme la valeur nulle ne constitue pas des données commerciales précises et occupera de l'espace de cache, nous ajouterons un délai d'expiration relativement court à la valeur nulle afin que la valeur nulle puisse expirer rapidement et être éliminée dans un court laps de temps. Bien que le renvoi de valeurs nulles puisse bloquer un grand nombre de requêtes pénétrantes, s'il y a un grand nombre de valeurs nulles mises en cache, cela gaspillera également de l'espace de stockage du cache. Si l'espace de cache est plein, certaines informations utilisateur qui ont été mises en cache. sera également éliminé. Au contraire, cela entraînera une diminution du taux de réussite du cache. Par conséquent, je vous suggère d'évaluer si la capacité du cache peut prendre en charge cette solution lors de son utilisation. Si un grand nombre de nœuds de cache sont nécessaires pour le prendre en charge, le problème ne peut pas être résolu en plantant des valeurs nulles. Dans ce cas, vous pouvez envisager d'utiliser un filtre Bloom.
3. Filtre Bloom
En 1970, Bloom a proposé un algorithme de filtre Bloom pour déterminer si un élément est dans un ensemble. Cet algorithme se compose d'un tableau binaire et d'un algorithme de hachage. Son idée de base est la suivante : nous calculons la valeur de hachage correspondante pour chaque valeur de l'ensemble selon l'algorithme de hachage fourni, puis modulons la valeur de hachage à la longueur du tableau pour obtenir la valeur d'index qui doit être incluse dans le tableau, et ajoutez la valeur d'index à cette position du tableau. La valeur est passée de 0 à 1. Pour juger si un élément existe dans cet ensemble, il suffit de calculer la valeur d'index de l'élément selon le même algorithme. Si la valeur de cette position est 1, on considère que l'élément est dans l'ensemble, sinon il l'est. considéré comme ne faisant pas partie de l'ensemble. 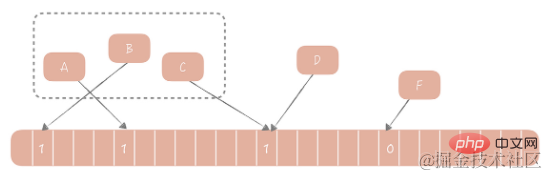
Comment utiliser le filtre Bloom pour résoudre la pénétration du cache ?
Prenez le tableau qui stocke les informations utilisateur comme exemple pour expliquer. Nous initialisons d'abord un grand tableau, disons un tableau d'une longueur de 2 milliards, puis nous choisissons un algorithme de hachage, puis nous calculons la valeur de hachage de tous les ID utilisateur existants et les mappons sur ce grand tableau, mappant la valeur de la position. défini sur 1 et les autres valeurs sont définies sur 0. En plus d'écrire dans la base de données, l'utilisateur nouvellement enregistré doit également mettre à jour la valeur de la position correspondante dans le tableau de filtres Bloom selon le même algorithme. Ensuite, lorsque nous devons interroger les informations d'un certain utilisateur, nous demandons d'abord si l'ID existe dans le filtre Bloom. S'il n'existe pas, nous renvoyons directement une valeur nulle sans continuer à interroger la base de données et le cache, ce qui peut réduire considérablement. exceptions. Pénétration du cache causée par les requêtes. 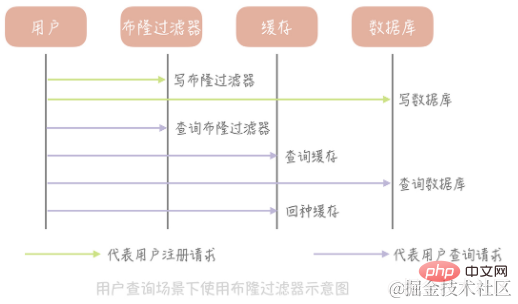
Avantages du filtre Bloom :
(1) Haute performance. Qu'il s'agisse d'une opération d'écriture ou d'une opération de lecture, la complexité temporelle est O(1) et est une valeur constante
(2) pour gagner de la place. Par exemple, un tableau de 2 milliards nécessite 2000000000/8/1024/1024 = 238 Mo d'espace. Si un tableau est utilisé pour le stockage, en supposant que chaque ID utilisateur occupe 4 octets d'espace, le stockage de 2 milliards d'utilisateurs nécessite 2000000000 * 4/1024. / 1024 = 7600M d'espace, 32 fois celui du filtre Bloom.
Inconvénients du filtre Bloom :
(1) Il a une certaine probabilité d'erreur lorsqu'il juge si un élément est dans l'ensemble. Par exemple, il classera les éléments qui. ne sont pas dans l'ensemble. Les éléments sont jugés comme étant dans l'ensemble.
Cause : La faille de l'algorithme de hachage lui-même.
Solution : utilisez plusieurs algorithmes de hachage pour calculer plusieurs valeurs de hachage pour l'élément. Ce n'est que lorsque les valeurs du tableau correspondant à toutes les valeurs de hachage sont 1 que l'élément sera considéré comme étant dans. l'ensemble.
(2) La suppression d'éléments n'est pas prise en charge. Le défaut selon lequel les filtres Bloom ne prennent pas en charge la suppression d'éléments est également lié à la collision de hachage. Par exemple, si deux éléments A et B sont tous deux des éléments de la collection et ont la même valeur de hachage, ils seront mappés à la même position dans le tableau. À ce stade, nous supprimons A et la valeur de la position correspondante dans le tableau passe également de 1 à 0. Ensuite, lorsque nous jugeons B et constatons que la valeur est 0, nous jugerons également que B est un élément qui n'est pas dans l'ensemble, et nous obtiendrons une mauvaise conclusion.
Solution : Au lieu d'avoir simplement des valeurs 0 et 1 dans le tableau, je stockerais un décompte. Par exemple, si A et B atteignent l'index d'un tableau en même temps, alors la valeur de cette position est 2. Si A est supprimé, la valeur passe de 2 à 1. Le tableau de cette solution ne stocke plus des bits, mais des valeurs, ce qui va augmenter la consommation d'espace.
4. Effet pile de chiens
Par exemple, s'il y a un élément de cache très chaud, une fois qu'il échoue, un grand nombre de requêtes pénétreront dans la base de données, ce qui entraînera des problèmes instantanés et énormes. pression sur la base de données, nous appelons ce scénario "l'effet chien-pile". L'idée pour résoudre l'effet dog stub est de minimiser la concurrence après la pénétration du cache. La solution est relativement simple :
(1) Contrôler dans le code pour démarrer un thread d'arrière-plan après l'expiration d'un certain élément de cache chaud, et la pénétration Accédez à la base de données et chargez les données dans le cache Avant que le cache ne soit chargé, toutes les demandes d'accès à ce cache ne pénétreront plus et reviendront directement.
(2) En définissant un verrou distribué dans Memcached ou Redis, seule la demande d'obtention du verrou peut pénétrer dans la base de données
6. CDN
1. accélération des ressources
Il existe un grand nombre de demandes de ressources statiques dans notre système : pour les applications mobiles, ces ressources statiques sont principalement des images, des vidéos et des informations multimédias en streaming pour les sites Web, elles incluent des fichiers JavaScript, des fichiers CSS, fichiers HTML statiques, etc. Ils ont un grand nombre de requêtes de lecture, nécessitent des vitesses d'accès élevées et occupent une bande passante élevée. À ce stade, il y aura des problèmes de vitesses d'accès lentes et de bande passante complète, affectant les requêtes dynamiques. Vous devez ensuite réfléchir à la manière de cibler ces requêtes statiques. ressources. La lecture est accélérée.
2. CDN
Le point clé de l'accès aux ressources statiques est l'accès à proximité, c'est-à-dire que les utilisateurs de Pékin accèdent aux données à Pékin et les utilisateurs de Hangzhou accèdent aux données à Hangzhou uniquement de cette manière. peut-on atteindre des performances optimales. Nous envisageons d'ajouter une couche spéciale de cache à la couche supérieure du serveur d'entreprise pour gérer la plupart des accès aux ressources statiques. Les nœuds de ce cache spécial doivent être répartis dans tout le pays, afin que les utilisateurs puissent choisir le nœud le plus proche auquel accéder. Le taux de réussite du cache doit également être garanti dans une certaine mesure et le nombre de demandes d'accès au site d'origine du stockage des ressources (demandes de retour à l'origine) doit être minimisé. Cette couche de mise en cache est CDN.
CDN (Content Delivery Network/Content Distribution Network, réseau de distribution de contenu). En termes simples, CDN distribue des ressources statiques à des serveurs situés dans des salles informatiques situées dans plusieurs emplacements géographiques. Par conséquent, il peut bien résoudre le problème de l'accès aux données à proximité et accélérer la vitesse d'accès aux ressources statiques.
3. Construire un système CDN
Quels sont les deux points à prendre en compte lors de la création d'un système CDN :
(1) Comment mapper les requêtes des utilisateurs au CDN nodes
Vous pensez peut-être que c'est très simple. Il vous suffit de communiquer à l'utilisateur l'adresse IP du nœud CDN, puis de demander le service CDN déployé sur cette adresse IP. Cependant, ce n'est pas le cas. Vous devez remplacer l'adresse IP par le nom de domaine correspondant. Alors comment faire ça ? Cela nécessite de s'appuyer sur le DNS pour nous aider à résoudre le problème du mappage des noms de domaine. DNS (Domain Name System) est en réalité une base de données distribuée qui stocke la correspondance entre les noms de domaine et les adresses IP. Il existe généralement deux types de résultats de résolution de nom de domaine, l'un est appelé « Enregistrement A », qui renvoie l'adresse IP correspondant au nom de domaine, l'autre est « Enregistrement CNAME », qui renvoie un autre nom de domaine, c'est-à-dire le nom de domaine ; résolution du nom de domaine actuel Pour passer à la résolution d'un autre nom de domaine.
Par exemple : par exemple, si le nom de domaine de premier niveau de votre entreprise s'appelle exemple.com, vous pouvez alors définir le nom de domaine de votre service d'imagerie comme "img.exemple.com", puis analyser le nom de domaine Le CNAME est configuré sur le nom de domaine fourni par le CDN. Par exemple, ucloud peut fournir un nom de domaine « 80f21f91.cdn.ucloud.com.cn ». De cette façon, l'adresse de l'image utilisée par votre système de commerce électronique peut être "img.example.com/1.jpg".
Lorsqu'un utilisateur demande cette adresse, le serveur DNS résoudra le nom de domaine en nom de domaine 80f21f91.cdn.ucloud.com.cn, puis résoudra ce nom de domaine en IP du nœud CDN, de sorte que le CDN peut être obtenu des données de ressources.
Optimisation de la résolution au niveau du nom de domaine
Parce que le processus de résolution du nom de domaine est hiérarchique et que chaque niveau dispose d'un serveur de noms de domaine dédié responsable de la résolution, donc le nom de domaine Le processus de résolution est possible. Il nécessite plusieurs requêtes DNS sur le réseau public, dont les performances sont relativement médiocres. Une solution consiste à pré-analyser le nom de domaine qui doit être analysé au démarrage de l'APP, puis à mettre en cache les résultats analysés dans un cache LRU local. De cette façon, lorsque nous souhaitons utiliser ce nom de domaine, il nous suffit d'obtenir l'adresse IP requise directement depuis le cache. Si elle n'existe pas dans le cache, nous passerons par tout le processus de requête DNS. Dans le même temps, afin d'éviter que les données du cache ne deviennent invalides en raison de changements dans les résultats de la résolution DNS, nous pouvons démarrer un minuteur pour mettre régulièrement à jour les données dans le cache.
(2) Comment sélectionner un nœud relativement proche en fonction des informations de localisation géographique de l'utilisateur.
GSLB (Global Server Load Balance) signifie l'équilibrage de charge entre les serveurs déployés dans différentes régions. De nombreux composants d'équilibrage de charge locaux peuvent être gérés ci-dessous. Il a deux fonctions : d'une part, il s'agit d'un serveur d'équilibrage de charge, comme son nom l'indique, fait référence à la répartition homogène du trafic afin que la charge des serveurs gérés ci-dessous soit plus uniforme ; il doit également garantir que le trafic qui transite par le serveur est relativement proche de la source du trafic.
GSLB peut utiliser diverses stratégies pour garantir que les nœuds CDN et les utilisateurs renvoyés se trouvent autant que possible dans la même zone géographique. Par exemple, l'adresse IP de l'utilisateur peut être divisée en plusieurs zones en fonction de l'emplacement géographique. , puis les nœuds CDN peuvent être mappés vers une région, le nœud approprié est renvoyé en fonction de la région où se trouve l'utilisateur, il est également possible de déterminer quel nœud renvoyer en envoyant des paquets de données pour mesurer le RTT ;
Résumé : la technologie DNS est la technologie de base utilisée dans la mise en œuvre du CDN, qui peut mapper les demandes des utilisateurs aux nœuds CDN ; les résultats de la résolution DNS doivent être mis en cache localement pour réduire le temps de réponse du processus de résolution DNS ; les utilisateurs avec Renvoyer un nœud plus proche pour accélérer l'accès aux ressources statiques.
Extension
(1) Processus de résolution de nom de domaine Baidu
Au début, la demande de résolution de nom de domaine vérifiera d'abord le fichier hosts du machine locale pour voir s'il existe une adresse IP correspondant à www.baidu.com ; sinon, demandez au DNS local pour voir s'il existe un cache des résultats de résolution de nom de domaine. Si tel est le cas, renvoyez le résultat indiquant qu'il est renvoyé par un non. -DNS faisant autorité, sinon, lancez une requête itérative de DNS. Demandez d'abord le DNS racine, qui renvoie l'adresse du DNS de premier niveau (.com) ; puis demandez au DNS de premier niveau .com d'obtenir l'adresse du serveur de noms de domaine de baidu.com, puis interrogez l'adresse du serveur de noms de domaine de ; www.baidu.com à partir du serveur de noms de domaine de baidu.com, tout en renvoyant cette adresse IP, marquez le résultat comme provenant du DNS faisant autorité et écrivez-le dans le cache des résultats d'analyse DNS local, afin que la prochaine fois. vous analysez le même nom de domaine, vous n'avez pas besoin de faire une requête DNS itérative.
(2) Délai CDN
Généralement, nous écrirons des ressources statiques sur un certain nœud CDN via l'interface du fabricant du CDN, puis utiliserons le mécanisme de synchronisation interne du CDN disperse et synchronise les ressources sur chaque nœud CDN. Même si le réseau interne du CDN est optimisé, ce processus de synchronisation est retardé. Une fois que nous ne pouvons pas obtenir les données du nœud CDN sélectionné, nous devons obtenir les données du réseau source. vers le site d'origine peut s'étendre sur plusieurs réseaux fédérateurs, ce qui entraîne non seulement une perte de performances, mais consomme également la bande passante du site d'origine, ce qui entraîne des coûts de R&D plus élevés. Par conséquent, lors de l’utilisation d’un CDN, nous devons faire attention au taux de réussite du CDN et à la bande passante du site d’origine.
Recommandations d'apprentissage associées : bases de Java
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!