
Parlons de la covariance et de la contravariance de Kotlin depuis Java

- coldplay.xixiavant
- 2020-10-13 11:14:232107parcourir
La colonne
Java Basics Tutorial présente la covariance et la contravariance de Kotlin aujourd'hui.

Préface
Afin de mieux comprendre la covariance et la contravariance en Kotlin et Java, examinons d'abord quelques connaissances de base.
Affectation ordinaire
En Java, les instructions d'affectation courantes sont les suivantes :
A a = b;复制代码
Les conditions que l'instruction d'affectation doit remplir sont : le côté gauche est soit la classe parent du côté droit, ou c'est le même que le côté droit Même type. Autrement dit, le type de A doit être « plus grand » que le type de B, comme Object o = new String("s"); . Pour plus de commodité, il est appelé ci-après A > ;
En plus des instructions d'affectation les plus courantes mentionnées ci-dessus, il existe deux autres instructions d'affectation :
Assignation des paramètres de fonction
public void fun(A a) {}// 调用处赋值B b = new B();
fun(b);复制代码Lors de l'appel de la méthode fun(b), Attribuez le paramètre passé dans le paramètre réel B b au paramètre formel A a, qui se présente sous la forme de A a = b. De même, le type de paramètre formel doit être supérieur au paramètre réel, c'est-à-dire A >
Affectation de la valeur de retour de la fonction
public A fun() {
B b = new B(); return b;
}
复制代码Le type de valeur de retour de fonction reçoit la valeur du type de retour réel B b équivaut à attribuer une valeur au type de valeur de retour de fonction. A a, c'est-à-dire affectation B b Étant donné A a, c'est-à-dire A a = b, alors la relation de type A >
Ainsi, quel que soit le type de mission, elle doit satisfaire le type gauche > Le type droit, c'est-à-dire A >
Covariance et contravariance en Java
Avec les connaissances de base précédentes, la covariance et la contravariance peuvent être facilement expliquées.
Si la classe A > classe B, trans(A) et trans(B) obtenus après changement de trans satisfont toujours trans(A) > trans(B), alors cela s'appelle changement de consensus .
La contravariation est tout le contraire. Si la classe A > la classe B, les trans(A) et trans(B) obtenus après un changement trans satisfont trans(A) > Inversion.
Par exemple, tout le monde sait que les tableaux Java sont covariants. Si A > B, alors A[] > Par exemple :
Integer[] nums = new Integer[]{};
Object[] o = nums; // 可以赋值,因为数组的协变特性所以由 Object > Integer 得到 Object[] > Integer[]复制代码Mais les génériques de Java ne satisfont pas à la covariance, comme suit :
List<Integer> l = new ArrayList<>(); List<Object> o = l;// 这里会报错,不能编译复制代码
Le code ci-dessus signale une erreur car, bien que Object > Integer, les génériques ne satisfont pas à la covariance , donc. List<object></object> > List<integer></integer> n'est pas satisfait puisque la condition selon laquelle le côté gauche est supérieur au côté droit n'est pas satisfaite, nous savons d'après la préface que List
Comment implémenter la covariance et la contravariance avec les génériques en Java
Nous savons d'après ce qui précède que les génériques en Java ne prennent pas en charge la variation de type, mais cela produira un très étrange Des doutes sont également mentionnés dans de nombreux articles sur les génériques :
Si B est une sous-classe de A, alors List devrait être une sous-classe de List! C'est une idée très naturelle !
Mais malheureusement, pour diverses raisons, Java ne le prend pas en charge. Cependant, Java n'efface pas complètement les caractéristiques variables des génériques. Java fournit étend T> et pour que les génériques aient des caractéristiques de covariance et de contravariance.
extends T> et super T>
extends T> sont appelés caractères génériques de limite supérieure, et Utilisez des caractères génériques de limite supérieure pour rendre les génériques covariants et utilisez des caractères génériques de limite inférieure pour rendre les génériques contravariants.
Par exemple, dans l'exemple précédent
List<Integer> l = new ArrayList<>(); List<Object> o = l;// 这里会报错,不能编译复制代码
Si vous utilisez le caractère générique de limite supérieure,
List<Integer> l = new ArrayList<>(); List<? extends Object> o = l;// 可以通过编译复制代码
De cette façon, le type de List plus grand que le type de List
De même, le caractère générique de limite inférieure super T> peut réaliser une inversion, comme :
public List<? super Integer> fun(){
List<Object> l = new ArrayList<>(); return l;
}复制代码Comment le code ci-dessus peut-il réaliser une inversion ? Tout d'abord, Object > Integer de plus, nous savons d'après la préface que le type de valeur de retour de la fonction doit être supérieur au type de valeur de retour réel, ici c'est List super Integer> List<object></object>, ce qui est exactement le contraire. de l'objet > En d'autres termes, après le changement générique, la relation de type entre Objet et Entier est inversée. Il s'agit d'une contravariance, et ce qui implémente la contravariance est le caractère générique de limite inférieure .
Comme le montre ce qui précède, la limite supérieure de extends T> est T, ce qui signifie que les types généralement mentionnés par , donc T est supérieur à étend T> La limite inférieure dans super T> est T, c'est-à-dire que les types généralement mentionnés par super T> sont la classe parent de T ou T elle-même, donc T.
虽然 Java 使用通配符解决了泛型的协变与逆变的问题,但是由于很多讲到泛型的文章都晦涩难懂,曾经让我一度感慨这 tm 到底是什么玩意?直到我在 stackoverflow 上发现了通俗易懂的解释(是的,前文大部分内容都来自于 stackoverflow 中大神的解释),才终于了然。其实只要抓住赋值语句左边类型必须大于右边类型这个关键点一切就都很好懂了。
PECS
PECS 准则即 Producer Extends Consumer Super,生产者使用上界通配符,消费者使用下界通配符。直接看这句话可能会让人很疑惑,所以我们追本溯源来看看为什么会有这句话。
首先,我们写一个简单的泛型类:
public class Container<T> { private T item; public void set(T t) {
item = t;
} public T get() { return item;
}
}复制代码然后写出如下代码:
Container<Object> c = new Container<String>(); // (1)编译报错Container<? extends Object> c = new Container<String>(); // (2)编译通过c.set("sss"); // (3)编译报错Object o = c.get();// (4)编译通过复制代码代码 (1),Container<object> c = new Container<string>(); </string></object> 编译报错,因为泛型是不型变的,所以 Container
代码 (2),加了上界通配符以后,支持泛型协变,Container
既然代码 (2) 通过编译,那代码 (3) 为什么会报错呢?因为代码 (3) 尝试把 String 类型赋值给 extends Object> 类型。显然,编译器只知道 extends Object> 是 Obejct 的某一个子类型,但是具体是哪一个并不知道,也许并不是 String 类型,所以不能直接将 String 类型赋值给它。
从上面可以看出,对于使用了 extends T> 的类型,是不能写入元素的,不然就会像代码 (3) 处一样编译报错。
但是可以读取元素,比如代码 (4) 。并且该类型只能读取元素,这就是所谓的“生产者”,即只能从中读取元素的就是生产者,生产者就使用 extends T> 通配符。
消费者同理,代码如下:
Container<String> c = new Container<Object>(); // (1)编译报错Container<? super String> c = new Container<Object>(); // (2)编译通过
c.set("sss");// (3) 编译通过
String s = c.get();// (4) 编译报错复制代码代码 (1) 编译报错,因为泛型不支持逆变。而且就算不懂泛型,这个代码的形式一眼看起来也是错的。
代码 (2) 编译通过,因为加了 super T> 通配符后,泛型逆变。
代码 (3) 编译通过,它把 String 类型赋值给 super String>, super String> 泛指 String 的父类或 String,所以这是可以通过编译的。
代码 (4) 编译报错,因为它尝试把 super String> 赋值给 String,而 super String> 大于 String,所以不能赋值。事实上,编译器完全不知道该用什么类型去接受 c.get() 的返回值,因为在编译器眼里 super String> 是一个泛指的类型,所有 String 的父类和 String 本身都有可能。
同样从上面代码可以看出,对于使用了 super T> 的类型,是不能读取元素的,不然就会像代码 (4) 处一样编译报错。但是可以写入元素,比如代码 (3)。该类型只能写入元素,这就是所谓的“消费者”,即只能写入元素的就是消费者,消费者就使用 super T> 通配符。
综上,这就是 PECS 原则。
kotlin 中的协变与逆变
kotlin 抛弃了 Java 中的通配符,转而使用了声明处型变与类型投影。
声明处型变
首先让我们回头看看 Container 的定义:
public class Container<T> { private T item; public void set(T t) {
item = t;
} public T get() { return item;
}
}复制代码在某些情况下,我们只会使用 Container extends T> 或者 Container super T> ,意味着我们只使用 Container 作为生产者或者 Container 作为消费者。
既然如此,那我们为什么要在定义 Container 这个类的时候要把 get 和 set 都定义好呢?试想一下,如果一个类只有消费者的作用,那定义 get 方法完全是多余的。
反过来说,如果一个泛型类只有生产者方法,比如下面这个例子(来自 kotlin 官方文档):
// Javainterface Source<T> {
T nextT(); // 只有生产者方法}// Javavoid demo(Source<String> strs) {
Source<Object> objects = strs; // !!!在 Java 中不允许,要使用上界通配符 <? extends Object>
// ……}复制代码在 Source<object> </object> 类型的变量中存储 Source<string> </string> 实例的引用是极为安全的——因为没有消费者-方法可以调用。然而 Java 依然不让我们直接赋值,需要使用上界通配符。
但是这是毫无意义的,使用通配符只是把类型变得更复杂,并没有带来额外的价值,因为能调用的方法还是只有生产者方法。但 Java 编译器只认死理。
所以,如果我们能在使用之前确定一个类是生产者还是消费者,那在定义类的时候直接声明它的角色岂不美哉?
这就是 kotlin 的声明处型变,直接在类声明的时候,定义它的型变行为。
比如:
class Container<out T> { // (1)
private var item: T? = null
fun get(): T? = item
}
val c: Container<Any> = Container<String>()// (2)编译通过,因为 T 是一个 out-参数复制代码(1) 处直接使用
同样的,对于消费者来说,
class Container<in T> { // (1)
private var item: T? = null
fun set(t: T) {
item = t
}
}val c: Container<String> = Container<Any>() // (2) 编译通过,因为 T 是一个 in-参数复制代码代码 (1) 处使用 Container super String> c = new Container<object>(); </object>。
这就是声明处型变,在类声明的时候使用 out 和 in 关键字,在使用时可以直接写出泛型型变的代码。
而 Java 在使用时必须借助通配符才能实现泛型型变,这是使用处型变。
类型投影
有时一个类既可以作生产者又可以作消费者,这种情况下,我们不能直接在 T 前面加 in 或者 out 关键字。比如:
class Container<T> { private var item: T? = null
fun set(t: T?) {
item = t
} fun get(): T? = item
}复制代码考虑这个函数:
fun copy(from: Container<Any>, to: Container<Any>) {
to.set(from.get())
}复制代码当我们实际使用该函数时:
val from = Container<int>()val to = Container<any>() copy(from, to) // 报错,from 是 Container<int> 类型,而 to 是 Container<any> 类型复制代码</any></int></any></int>
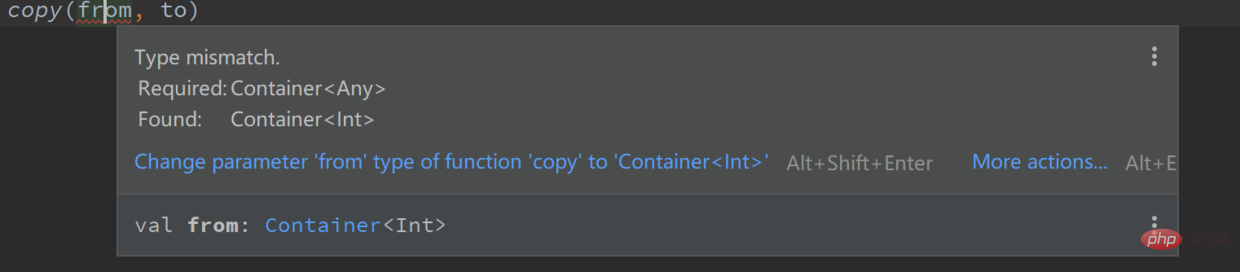
这样使用的话,编译器报错,因为我们把两个不一样的类型做了赋值。用 kotlin 官方文档的话说,copy 函数在”干坏事“, 它尝试写一个 Any 类型的值给 from, 而我们用 Int 类型来接收这个值,如果编译器不报错,那么运行时将会抛出一个 ClassCastException 异常。
所以应该怎么办?直接防止 from 被写入就可以了!
将 copy 函数改为如下所示:
fun copy(from: Container<out Any>, to: Container<Any>) { // 给 from 的类型加了 out
to.set(from.get())
}val from = Container<Int>()val to = Container<Any>()
copy(from, to) // 不会再报错了复制代码这就是类型投影:from 是一个类受限制的(投影的)Container 类,我们只能把它当作生产者来使用,它只能调用 get() 方法。
同理,如果 from 的泛型是用 in 来修饰的话,则 from 只能被当作消费者使用,它只能调用 set() 方法,上述代码就会报错:
fun copy(from: Container<in Any>, to: Container<Any>) { // 给 from 的类型加了 in
to.set(from.get())
}val from = Container<Int>()val to = Container<Any>()
copy(from, to) // 报错复制代码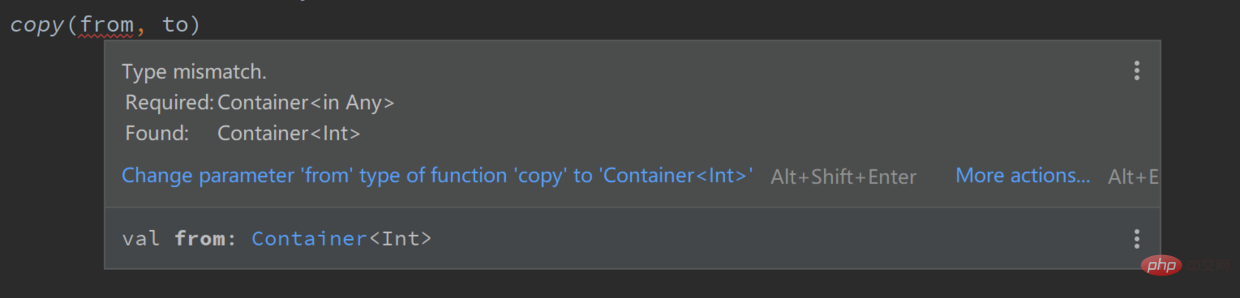
其实从上面可以看到,类型投影和 Java 的通配符很相似,也是一种使用时型变。
为什么要这么设计?
为什么 Java 的数组是默认型变的,而泛型默认不型变呢?其实 kolin 的泛型默认也是不型变的,只是使用 out 和 in 关键字让它看起来像泛型型变。
为什么这么设计呢?为什么不默认泛型可型变呢?
在 stackoverflow 上找到了答案,参考:stackoverflow.com/questions/1…
Java 和 C# 早期都是没有泛型特性的。
但是为了支持程序的多态性,于是将数组设计成了协变的。因为数组的很多方法应该可以适用于所有类型元素的数组。
比如下面两个方法:
boolean equalArrays (Object[] a1, Object[] a2);void shuffleArray(Object[] a);复制代码第一个是比较数组是否相等;第二个是打乱数组顺序。
语言的设计者们希望这些方法对于任何类型元素的数组都可以调用,比如我可以调用 shuffleArray(String[] s) 来把字符串数组的顺序打乱。
出于这样的考虑,在 Java 和 C# 中,数组设计成了协变的。
然而,对于泛型来说,却有以下问题:
// Illegal code - because otherwise life would be BadList<dog> dogs = new List<dog>(); List<animal> animals = dogs; // Awooga awoogaanimals.add(new Cat());// (1)Dog dog = dogs.get(0); //(2) This should be safe, right?复制代码</animal></dog></dog>如果上述代码可以通过编译,即 List
可以赋值给 List ,List 是协变的。接下来往 List 中 add 一个 Cat(),如代码 (1) 处。这样就有可能造成代码 (2) 处的接收者 Dog dog和dogs.get(0)的类型不匹配的问题。会引发运行时的异常。所以 Java 在编译期就要阻止这种行为,把泛型设计为默认不型变的。
Résumé
1. Les génériques Java ne sont pas modifiables par défaut, donc List
2. Les génériques Kotlin ne sont pas variables par défaut. Cependant, l'utilisation des mots-clés out et in pour modifier le type lors de la déclaration de classe peut obtenir l'effet d'un changement de type direct au point d'utilisation. Mais cela limitera la classe à être soit un producteur, soit un consommateur une fois déclarée.
L'utilisation de la projection de type peut éviter que la classe soit restreinte lors de sa déclaration, mais lors de son utilisation, vous devez utiliser les mots-clés out et in pour indiquer si le rôle de la classe à ce moment est un consommateur ou un producteur . La projection de type est également une méthode d'utilisation des changements de type.
Recommandations d'apprentissage gratuites associées : Tutoriel de base Java
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Introduction détaillée aux opérateurs de base Java et au contrôle logique (avec exemples)
- Notions de base de Java : introduction à l'encapsulation, à la surcharge de méthodes et aux méthodes de construction (constructeurs)
- Une brève introduction à la réflexion de base JavaRéflexion
- Interface du didacticiel de base Java