
Maison >Applet WeChat >Développement de mini-programmes >Développement 24 heures sur 24 du mini programme Onmyoji
Développement 24 heures sur 24 du mini programme Onmyoji
- 巴扎黑original
- 2017-04-01 15:26:122444parcourir
0. Préface
Tous ceux qui jouent à Onmyoji savent que le sceau sera rafraîchi deux fois par jour à 5h et 18h. La chose la plus ennuyeuse à chaque fois que vous accomplissez une tâche est de trouver les copies correspondantes de divers monstres et des indices mystérieux. Onmyoji fournit NetEase Genie pour certaines requêtes de données, mais l'expérience est trop touchante, c'est pourquoi la plupart des gens choisissent d'utiliser les moteurs de recherche pour rechercher la distribution de monstres et des indices mystérieux.
Il est très gênant d'utiliser les moteurs de recherche à chaque fois, l'auteur a donc décidé d'écrire un petit programme pour interroger la distribution d'Onmyoji monstres. Efforcez-vous d'obtenir une expérience plus rapide en utilisant le raccourci, en laissant plus de temps pour la nourriture pour chien et le contrôle de l'âme.
Il se trouve que j'avais deux jours le week-end dernier, alors j'ai commencé à écrire immédiatement.
1. Conception et design (3 heures)1.1 Conception
La fonction principale du mini programme à réaliser est la fonction de requête, donc la page d'accueil doit être aussi concise qu'un moteur de recherche, et un champ de recherche est absolument nécessaire
La page d'accueil contient ; recherche populaire et met en cache la recherche shikigami la plus populaire ;
La recherche prend en charge la correspondance complète ou la correspondance d'un seul mot
-
Cliquez sur le résultat de la recherche pour sauter ; directement à la page de détails du Shikigami ; 53. Shikigami La page de détails doit inclure l'illustration, le nom, la rareté et les lieux obsédants du shikigami, et les lieux obsédants sont triés du plus grand nombre au plus petit nombre de monstres ; 🎜>
Ajouter la fonction de rapport des erreurs de données et de faire des suggestions - Prend en charge l'historique de recherche personnel des utilisateurs
- Le nom de ; il a finalement été décidé que le mini-programme s'appellerait Shikigami Hunter (en fait, compte tenu des fonctions du mini-programme). Cela a été pensé une fois le développement final terminé) ; 🎜>1.2 Conception
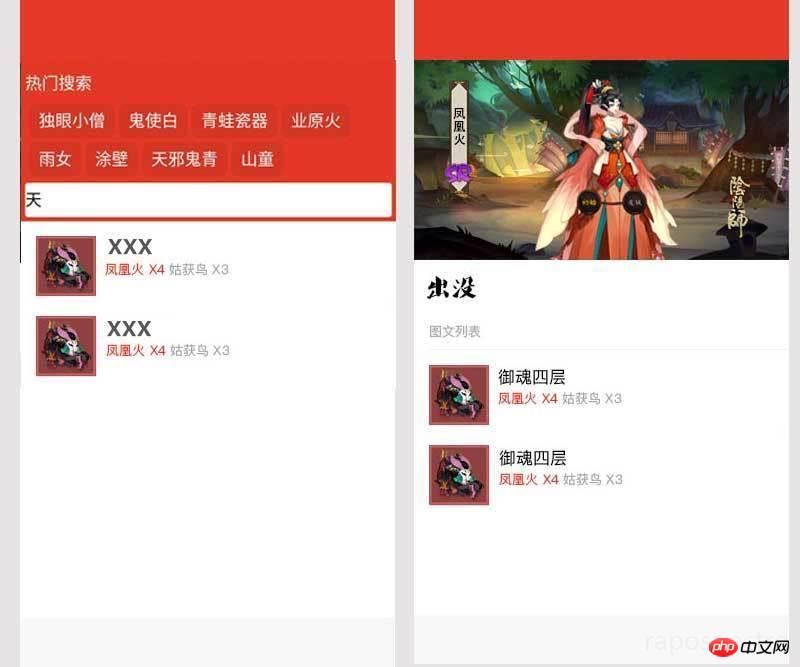 Eh bien, la page d'accueil et la page de détails les plus importantes sont conçues, et vous pouvez ensuite commencer à réfléchir à la façon de le faire !
Eh bien, la page d'accueil et la page de détails les plus importantes sont conçues, et vous pouvez ensuite commencer à réfléchir à la façon de le faire !
1.3 Architecture techniqueLe front-end est sans aucun doute l'applet WeChat
Le backend utilise Django pour fournir des services API Restful
- La recherche la plus populaire actuelle utilise Redis comme serveur de cache pour la mise en cache ; >
Les enregistrements de recherche personnels utilisent le stockage local fourni par l'applet WeChat
Les informations de distribution Shikigami sont explorées et nettoyées à l'aide d'un robot d'exploration, formatées en json et vérifiées manuellement avant d'être stockées dans la base de données ;
Les images et icônes de Shikigami sont directement explorées à partir des informations officielles ;
-
Créez vos propres images et icônes de shikigami qui ne peuvent pas être explorées. ;
Le mini programme nécessite une connexion HTTPS, ce que j'ai déjà fait, vous pouvez le voir directement ici
Guide de déploiement gratuit HTTPS-
À ce stade, une fois les préparatifs pour le développement officiel en place, nous pouvons commencer le développement officiel
2. Développement de services API (5 heures)
L'auteur a souvent fait du développement de services API Django auparavant, j'ai donc une solution relativement complète, vous pouvez vous référer icidjango-simple-serializer
La raison pour laquelle cela a pris 5 heures est qu'il a fallu près de 4 heures pour ajouter la prise en charge de django-simple-serializer pour la fonctionnalité through dans Django ManyToManyField.
En bref, la fonctionnalité through vous permet d'ajouter des champs ou attributs supplémentaires à la table intermédiaire d'une relation plusieurs-à-plusieurs, tels que : des copies monstres et plusieurs-à- de nombreuses relations entre les monstres Vous devez ajouter un nombre de champs qui stocke le nombre de monstres correspondants dans chaque copie.
Après avoir passé le support, la construction de l'API sera très rapide. Il y a principalement cinq API : <.>
- Interface de recherche
- Interface de détails Shikigami;
- Interface de copie Shikigami Interface de recherche populaire
- Interface de commentaires
Après avoir écrit l'interface, ajoutez quelques données fictives pour les tests
Développement front-end (8 heures)
C'est l'avant qui a pris le plus de temps.
D'une part, l'auteur est vraiment un ingénieur back-end, et le front-end est à moitié décent. En revanche, le mini-programme comporte quelques pièges. Bien sûr, le plus important est d'ajuster l'effet d'interface à tout moment, ce qui prend beaucoup de temps.
L'expérience globale de l'écriture de petits programmes est exactement la même que celle de l'écriture de vue.js, sauf que certaines balises html ne peuvent pas être utilisées. , mais doit être écrit selon les composants officiellement fournis par le mini-programme. Une chose que je pense ici est que l'idée de conception des composants du mini-programme lui-même devrait être basée sur React et la syntaxe devrait être basée sur vue. js.
Enfin, une fois le développement front-end terminé, il est principalement divisé en ces pages :
- Page d'accueil (page de recherche) ;
- Page de détails Shikigami
- Mon page (principalement pour afficher l'historique de recherche et la clause de non-responsabilité, etc.) ;
- Interface de commentaires
- Interface de déclaration (Pourquoi avez-vous besoin de cette interface ; ? Parce que toutes les images et certaines ressources sont toutes directement extraites des ressources officielles d'Onmyoji, il faut donc préciser ici qu'elles sont uniquement destinées à un usage à but non lucratif et que tous les droits d'auteur désordonnés appartiennent toujours à Onmyoji).
Hé, la vilaine belle-fille rencontrera ses beaux-parents tôt ou tard, donc je dois mettre le schéma final de l'interface ici Pour WeChat, je n'entrerai pas ici dans les détails de l'introduction et des bases des mini-programmes. Je pense que les développeurs qui sont actuellement intéressés par les mini-programmes WeChat n'auront aucun problème à écrire une démo simple. à eux seuls, je parlerai principalement de mes pièges rencontrés lors du développement :
Attribut background-image 3.1 
dans Lors de la rédaction de la page de détails de Shikigami, vous devez utiliser l'attribut background-image pour définir l'image d'arrière-plan à deux endroits. Tout s'affiche normalement dans les outils de développement WeChat, mais une fois débogué sur une vraie machine. , elle ne peut pas être affichée. Finalement, l'image d'arrière-plan de l'applet est trouvée. La vraie machine ne prend pas en charge le référencement des ressources locales :
Utiliser des images réseau : Compte tenu de la taille de l'image de fond, l'auteur a abandonné cette solution
utilise base64 pour encoder l'image ;
Normalement, l'image d'arrière-plan en CSS prend en charge la base64. Cette solution équivaut à encoder directement l'image avec la section A en base64. du code base64 est stocké, et vous pouvez l'utiliser comme ceci lorsque vous l'utilisez :
[CSS] Vue en texte brut Copier le code
background-image: url(data:image/image-format;base64,XXXX);
image-format est le format de l'image elle-même, et xxxx est l'encodage de l'image après base64. Cette méthode est en fait une manière déguisée de référencer des ressources locales. L'avantage est qu'elle peut réduire le nombre de demandes d'images, mais l'inconvénient est qu'elle augmentera la taille du fichier CSS et le rendra moins beau.
En fin de compte, l'auteur a choisi la deuxième méthode principalement parce que la taille de l'image et l'augmentation de wxss étaient dans les limites acceptables gamme.
Modèle 3.2
Le mini programme prend en charge les modèles, mais veuillez noter que les modèles ont leur propre Scope, seules les données transmises dans data peuvent être utilisées.
De plus, lors de la transmission des données, les données pertinentes doivent être déconstruites et transmises. À l'intérieur du modèle, elles sont directement as {{ xxxx }} Accès sous la forme de {{ item.xxx }} en boucle
A propos de la déconstruction : [ XML ] Vue en texte brut Copier le code
Trois. >
Généralement, les modèles seront placés dans des fichiers de modèles séparés pour que d'autres fichiers puissent les appeler, au lieu d'être écrits directement dans wxml normal. Par exemple, le catalogue de l'auteur ressemble probablement à ceci :
<template is="xxx" data="{{...object}}"/>
[JavaScript] Vue en texte brut Copier le code
Concernant les autres fichiers modèle d'appel, utilisez simplement l'importation directement :
├── app.js ├── app.json ├── app.wxss ├── pages │ ├── feedback │ ├── index │ ├── my │ ├── onmyoji │ ├── statement │ └── template │ ├── template.js │ ├── template.json │ ├── template.wxml │ └── template.wxss ├── static └── utils
[XML] Vue en texte brut Copiez le code
Ensuite, là où vous en avez besoin citez le modèle : [XML ] Afficher le texte brut Copier le code
<template is="xxx" data="{{...object}}"/>
这里遇到另一个问题,template 对应的样式写在 template 对应的 wxss 中并没有作用,需要写在调用 template 的文件的 wxss 中,比如 index 需要使用 template 则需要将对应的 css 写在 my/my.wxss 中。
4. 爬取图片资源 ( 2小时 )
式神的图标及形象图基本上阴阳师官网都有,这里自己做也不现实,所以果断写爬虫爬下来然后存到自己的 cdn 。
大图和小图都在 http://yys.163.com/shishen/index.html 这里可以找到。 一开始考虑爬取网页然后 beautiful soup 提取数据,后面发现式神数据竟然是异步加载的,那就更简单了,分析网页得到 https://g37simulator.webapp.163.com/get_heroid_list 直接返回了式神信息的 json 信息,所以很容易写个爬虫就可以搞定了:
[Python] 纯文本查看 复制代码
# coding: utf-8
import json
import requests
import urllib
from xpinyin import Pinyin
url = "https://g37simulator.webapp.163.com/get_heroid_list?callback=jQuery11130959811888616583_1487429691764&rarity=0&page=1&per_page=200&_=1487429691765"
result = requests.get(url).content.replace('jQuery11130959811888616583_1487429691764(', '').replace(')', '')
json_data = json.loads(result)
hellspawn_list = json_data['data']
p = Pinyin()
for k, v in hellspawn_list.iteritems():
file_name = p.get_pinyin(v.get('name'), '')
print 'id: {0} name: {1}'.format(k, v.get('name'))
big_url = "https://yys.res.netease.com/pc/zt/20161108171335/data/shishen_big/{0}.png".format(k)
urllib.urlretrieve(big_url, filename='big/{0}@big.png'.format(file_name))
avatar_url = "https://yys.res.netease.com/pc/gw/20160929201016/data/shishen/{0}.png".format(k)
urllib.urlretrieve(avatar_url, filename='icon/{0}@icon.png'.format(file_name))然而,爬完数据后发现一个问题,网易官方的图片都是无码高清大图,对于笔者这种穷 ds 大图放在 cdn 上两天就得破产,所以需要批量将图片转成既不太大又能看的过去。嗯,这里就可以用到 ps 的批处理能力了。
打开 ps ,然后选择爬到的一张图片;
选择菜单栏上的“窗口”然后选择“动作;
在“动作”选项下,新建一个动作;
点击圆形录制按钮开始录制动作;
按正常处理图片等顺序将一张图片存为 web 格式;
点击方形停止按钮停止录制动作;
选择菜单栏上的 文件-自动-批处理-选择之前录制的动作-配置好输入文件夹和输出文件夹;
点击确定就可以啦;
等批处理结束,期间刷个御魂啥的应该就好了,然后将得到的所有图片上传到静态资源服务器,图片这里就处理完啦。
5. 式神数据爬取 ( 4小时 )
式神分布数据网上比较杂并且数据很多有偏差,所以斟酌再三决定采用半人工半自动的方式,爬到的数据输出为 json:
[JavaScript]
{
"scene_name": "探索第一章",
"team_list": [{
"name": "天邪鬼绿1",
"index": 1,
"monsters": [{
"name": "天邪鬼绿",
"count": 1
},{
"name": "提灯小僧",
"count": 2
}]
},{
"name": "天邪鬼绿2",
"index": 2,
"monsters": [{
"name": "天邪鬼绿",
"count": 1
},{
"name": "提灯小僧",
"count": 2
}]
},{
"name": "提灯小僧1",
"index": 3,
"monsters": [{
"name": "天邪鬼绿",
"count": 2
},{
"name": "提灯小僧",
"count": 1
}]
},{
"name": "提灯小僧2",
"index": 4,
"monsters": [{
"name": "灯笼鬼",
"count": 2
},{
"name": "提灯小僧",
"count": 1
}]
},{
"name": "首领",
"index": 5,
"monsters": [{
"name": "九命猫",
"count": 3
}]
}]
}然后再人工检查一遍,当然还是会有遗漏,所以数据报错的功能就很重要啦。
这一部分实际写代码的时间可能只有半个多小时,剩下时间一直在检查数据;
一切检查结束后写个脚本直接将 json 导入到数据库中,检查无误后用 fabric 发布到线上服务器进行测试;
6. 测试 ( 2小时 )
最后一步基本上就是在手机上体验查错,修改一些效果,关闭调试模式准备提交审核;
C'est déjà dimanche, oh non, il devrait être une heure lundi matin :
Je dois dire que la vitesse de révision de l'équipe du mini programme est très rapide, lundi après-midi Il a passé l'examen puis a été mis en ligne de manière décisive.
Dernier rendu :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- WeChat Mini Program Exercices simples de mise en page, de logique et de style
- Explication détaillée et exemples de l'applet WeChat wx.request (méthode d'appel d'interface)
- Programme WeChat Mini - Explication détaillée de la connexion WeChat, du paiement WeChat et des modèles de messages
- Applet WeChat (compte d'application) exemple d'application simple et explication détaillée de l'exemple
- Explication détaillée de l'applet WeChat pour la boucle