

 développement back-endTutoriel PythonFondements de l'ingénierie des données : un guide pratique
développement back-endTutoriel PythonFondements de l'ingénierie des données : un guide pratique
Un guide pratique pour créer un pipeline ETL d'ingénierie de données. Ce guide fournit une approche pratique pour comprendre et mettre en œuvre les principes fondamentaux de l'ingénierie des données, couvrant le stockage, le traitement, l'automatisation et la surveillance.
Qu'est-ce que l'ingénierie des données ?
L'ingénierie des données se concentre sur l'organisation, le traitement et l'automatisation des flux de travail de données pour transformer les données brutes en informations précieuses pour l'analyse et la prise de décision. Ce guide couvre :
- Stockage des données : Définir où et comment les données sont stockées.
- Traitement des données : Techniques de nettoyage et de transformation des données brutes.
- Automatisation du flux de travail : Mise en œuvre d'une exécution transparente et efficace du flux de travail.
- Surveillance du système : Assurer la fiabilité et le bon fonctionnement de l'ensemble du pipeline de données.
Explorons chaque étape !
Configuration de votre environnement de développement
Avant de commencer, assurez-vous d'avoir les éléments suivants :
-
Configuration de l'environnement :
- Un système basé sur Unix (macOS) ou un sous-système Windows pour Linux (WSL).
- Python 3.11 (ou version ultérieure) installé.
- Base de données PostgreSQL installée et exécutée localement.
-
Prérequis :
- Maîtrise de base de la ligne de commande.
- Connaissances fondamentales en programmation Python.
- Privilèges administratifs pour l'installation et la configuration du logiciel.
-
Aperçu architectural :


Le diagramme illustre l'interaction entre les composants du pipeline. Cette conception modulaire exploite les atouts de chaque outil : Airflow pour l'orchestration des flux de travail, Spark pour le traitement des données distribuées et PostgreSQL pour le stockage de données structurées.
-
Installation des outils nécessaires :
- PostgreSQL :
brew update brew install postgresql
- PySpark :
brew install apache-spark
- Flux d'air :
python -m venv airflow_env source airflow_env/bin/activate # macOS/Linux pip install "apache-airflow[postgres]==" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.10.4/constraints-3.11.txt" airflow db migrate
- PostgreSQL :
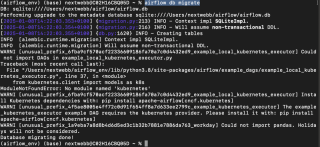
Une fois l'environnement préparé, examinons chaque composant.
1. Stockage de données : bases de données et systèmes de fichiers
Le stockage des données est la base de tout pipeline d'ingénierie de données. Nous considérerons deux catégories principales :
-
Bases de données : Stockage de données efficacement organisé avec des fonctionnalités telles que la recherche, la réplication et l'indexation. Les exemples incluent :
- Bases de données SQL : Pour les données structurées (par exemple, PostgreSQL, MySQL).
- Bases de données NoSQL : Pour les données sans schéma (par exemple, MongoDB, Redis).
- Systèmes de fichiers : Convient aux données non structurées, offrant moins de fonctionnalités que les bases de données.
Configuration de PostgreSQL
- Démarrez le service PostgreSQL :
brew update brew install postgresql

- Créez une base de données, connectez-vous et créez une table :
brew install apache-spark
- Insérer des exemples de données :
python -m venv airflow_env source airflow_env/bin/activate # macOS/Linux pip install "apache-airflow[postgres]==" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.10.4/constraints-3.11.txt" airflow db migrate
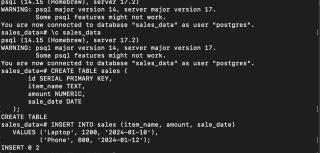
Vos données sont désormais stockées en toute sécurité dans PostgreSQL.
2. Traitement des données : PySpark et informatique distribuée
Les frameworks de traitement des données transforment les données brutes en informations exploitables. Apache Spark, avec ses capacités informatiques distribuées, est un choix populaire.
-
Modes de traitement :
- Traitement par lots : Traite les données par lots de taille fixe.
- Traitement du flux : Traite les données en temps réel.
- Outils courants : Apache Spark, Flink, Kafka, Hive.
Traitement des données avec PySpark
- Installer Java et PySpark :
brew services start postgresql
- Charger des données à partir d'un fichier CSV :
Créez un fichier sales.csv avec les données suivantes :
CREATE DATABASE sales_data;
\c sales_data
CREATE TABLE sales (
id SERIAL PRIMARY KEY,
item_name TEXT,
amount NUMERIC,
sale_date DATE
);
Utilisez le script Python suivant pour charger et traiter les données :
INSERT INTO sales (item_name, amount, sale_date)
VALUES ('Laptop', 1200, '2024-01-10'),
('Phone', 800, '2024-01-12');

- Filtrer les ventes de grande valeur :
brew install openjdk@11 && brew install apache-spark


-
Configurer le pilote Postgres DB : Téléchargez le pilote PostgreSQL JDBC si nécessaire et mettez à jour le chemin dans le script ci-dessous.
-
Enregistrer les données traitées dans PostgreSQL :
brew update brew install postgresql


Le traitement des données avec Spark est terminé.
3. Automatisation du flux de travail : flux d'air
L'automatisation rationalise la gestion des flux de travail grâce à la planification et à la définition des dépendances. Des outils comme Airflow, Oozie et Luigi facilitent cela.
Automatisation de l'ETL avec Airflow
- Initialiser le flux d'air :
brew install apache-spark


- Créer un workflow (DAG) :
python -m venv airflow_env source airflow_env/bin/activate # macOS/Linux pip install "apache-airflow[postgres]==" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.10.4/constraints-3.11.txt" airflow db migrate
Ce DAG s'exécute quotidiennement, exécute le script PySpark et comprend une étape de vérification. Des alertes par e-mail sont envoyées en cas d'échec.
-
Surveillez le flux de travail : Placez le fichier DAG dans le répertoire
dags/d'Airflow, redémarrez les services Airflow et surveillez via l'interface utilisateur d'Airflow àhttp://localhost:8080.
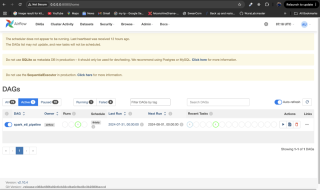
4. Surveillance du système
La surveillance garantit la fiabilité du pipeline. Les alertes d'Airflow ou l'intégration avec des outils comme Grafana et Prometheus sont des stratégies de surveillance efficaces. Utilisez l'interface utilisateur d'Airflow pour vérifier les statuts et les journaux des tâches.
Conclusion
Vous avez appris à configurer le stockage des données, à traiter les données à l'aide de PySpark, à automatiser les flux de travail avec Airflow et à surveiller votre système. L’ingénierie des données est un domaine crucial et ce guide fournit une base solide pour une exploration plus approfondie. N'oubliez pas de consulter les références fournies pour des informations plus détaillées.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Python: jeux, GUIS, et plusApr 13, 2025 am 12:14 AM
Python: jeux, GUIS, et plusApr 13, 2025 am 12:14 AMPython excelle dans les jeux et le développement de l'interface graphique. 1) Le développement de jeux utilise Pygame, fournissant des fonctions de dessin, audio et d'autres fonctions, qui conviennent à la création de jeux 2D. 2) Le développement de l'interface graphique peut choisir Tkinter ou Pyqt. Tkinter est simple et facile à utiliser, PYQT a des fonctions riches et convient au développement professionnel.
 Python vs C: applications et cas d'utilisation comparésApr 12, 2025 am 12:01 AM
Python vs C: applications et cas d'utilisation comparésApr 12, 2025 am 12:01 AMPython convient à la science des données, au développement Web et aux tâches d'automatisation, tandis que C convient à la programmation système, au développement de jeux et aux systèmes intégrés. Python est connu pour sa simplicité et son écosystème puissant, tandis que C est connu pour ses capacités de contrôle élevées et sous-jacentes.
 Le plan Python de 2 heures: une approche réalisteApr 11, 2025 am 12:04 AM
Le plan Python de 2 heures: une approche réalisteApr 11, 2025 am 12:04 AMVous pouvez apprendre les concepts de programmation de base et les compétences de Python dans les 2 heures. 1. Apprenez les variables et les types de données, 2. Flux de contrôle maître (instructions et boucles conditionnelles), 3. Comprenez la définition et l'utilisation des fonctions, 4. Démarrez rapidement avec la programmation Python via des exemples simples et des extraits de code.
 Python: Explorer ses applications principalesApr 10, 2025 am 09:41 AM
Python: Explorer ses applications principalesApr 10, 2025 am 09:41 AMPython est largement utilisé dans les domaines du développement Web, de la science des données, de l'apprentissage automatique, de l'automatisation et des scripts. 1) Dans le développement Web, les cadres Django et Flask simplifient le processus de développement. 2) Dans les domaines de la science des données et de l'apprentissage automatique, les bibliothèques Numpy, Pandas, Scikit-Learn et Tensorflow fournissent un fort soutien. 3) En termes d'automatisation et de script, Python convient aux tâches telles que les tests automatisés et la gestion du système.
 Combien de python pouvez-vous apprendre en 2 heures?Apr 09, 2025 pm 04:33 PM
Combien de python pouvez-vous apprendre en 2 heures?Apr 09, 2025 pm 04:33 PMVous pouvez apprendre les bases de Python dans les deux heures. 1. Apprenez les variables et les types de données, 2. Structures de contrôle maître telles que si les instructions et les boucles, 3. Comprenez la définition et l'utilisation des fonctions. Ceux-ci vous aideront à commencer à écrire des programmes Python simples.
 Comment enseigner les bases de la programmation novice en informatique dans le projet et les méthodes axées sur les problèmes dans les 10 heures?Apr 02, 2025 am 07:18 AM
Comment enseigner les bases de la programmation novice en informatique dans le projet et les méthodes axées sur les problèmes dans les 10 heures?Apr 02, 2025 am 07:18 AMComment enseigner les bases de la programmation novice en informatique dans les 10 heures? Si vous n'avez que 10 heures pour enseigner à l'informatique novice des connaissances en programmation, que choisissez-vous d'enseigner ...
 Comment éviter d'être détecté par le navigateur lors de l'utilisation de Fiddler partout pour la lecture de l'homme au milieu?Apr 02, 2025 am 07:15 AM
Comment éviter d'être détecté par le navigateur lors de l'utilisation de Fiddler partout pour la lecture de l'homme au milieu?Apr 02, 2025 am 07:15 AMComment éviter d'être détecté lors de l'utilisation de FiddlereVerywhere pour les lectures d'homme dans le milieu lorsque vous utilisez FiddlereVerywhere ...
 Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?Apr 02, 2025 am 07:12 AM
Que dois-je faire si le module '__builtin__' n'est pas trouvé lors du chargement du fichier de cornichon dans Python 3.6?Apr 02, 2025 am 07:12 AMChargement des fichiers de cornichons dans Python 3.6 Rapport de l'environnement Erreur: modulenotFoundError: NomoduLenamed ...


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

Adaptateur de serveur SAP NetWeaver pour Eclipse
Intégrez Eclipse au serveur d'applications SAP NetWeaver.

PhpStorm version Mac
Le dernier (2018.2.1) outil de développement intégré PHP professionnel

Dreamweaver CS6
Outils de développement Web visuel

mPDF
mPDF est une bibliothèque PHP qui peut générer des fichiers PDF à partir de HTML encodé en UTF-8. L'auteur original, Ian Back, a écrit mPDF pour générer des fichiers PDF « à la volée » depuis son site Web et gérer différentes langues. Il est plus lent et produit des fichiers plus volumineux lors de l'utilisation de polices Unicode que les scripts originaux comme HTML2FPDF, mais prend en charge les styles CSS, etc. et présente de nombreuses améliorations. Prend en charge presque toutes les langues, y compris RTL (arabe et hébreu) et CJK (chinois, japonais et coréen). Prend en charge les éléments imbriqués au niveau du bloc (tels que P, DIV),

