


Créer un lac de données cloud natif pour l'analyse NBA à l'aide d'AWS est désormais plus simple que jamais, grâce à la suite complète de services d'AWS. Ce guide montre la création d'un lac de données NBA à l'aide d'Amazon S3, AWS Glue et Amazon Athena, en automatisant la configuration avec un script Python pour un stockage, des requêtes et une analyse efficaces des données.
Comprendre les lacs de données
Un lac de données est un référentiel centralisé permettant de stocker des données structurées et non structurées à n'importe quelle échelle. Les données sont stockées dans leur format brut, traitées selon les besoins et utilisées à des fins d'analyse, de reporting ou d'apprentissage automatique. AWS propose des outils robustes pour la création et la gestion efficaces de lacs de données.
Présentation du lac de données NBA
Ce projet utilise un script Python (setup_nba_data_lake.py) pour automatiser :
- Amazon S3 : Crée un compartiment pour stocker les données NBA brutes et traitées.
- AWS Glue : Établit une base de données et une table externe pour la gestion des métadonnées et des schémas.
- Amazon Athena : Configure l'exécution de requêtes pour l'analyse directe des données à partir de S3.
Cette architecture facilite l'intégration transparente des données NBA en temps réel de SportsData.io pour des analyses et des rapports avancés.
Services AWS utilisés
1. Amazon S3 (service de stockage simple) :
- Fonction : Stockage d'objets évolutif ; la fondation du lac de données, stockant les données NBA brutes et traitées.
-
Implémentation : Crée le bucket
sports-analytics-data-lake. Les données sont organisées en dossiers (par exemple,raw-datapour les fichiers JSON non traités commenba_player_data.json). S3 garantit une haute disponibilité, une durabilité et une rentabilité. - Avantages : Évolutivité, rentabilité, intégration transparente avec AWS Glue et Athena.
2. Colle AWS :
- Fonction : Service ETL (Extract, Transform, Load) entièrement géré ; gère les métadonnées et le schéma des données dans S3.
-
Implémentation : Crée une base de données Glue et une table externe (
nba_players) définissant le schéma de données JSON dans S3. Collez les métadonnées des catalogues, permettant les requêtes Athena. - Avantages : Gestion automatisée des schémas, capacités ETL, rentabilité.
3. Amazon Athéna :
- Fonction : Service de requête interactif pour analyser les données S3 à l'aide du SQL standard.
-
Mise en œuvre : Lit les métadonnées d'AWS Glue. Les utilisateurs exécutent des requêtes SQL directement sur les données S3 JSON sans serveur de base de données. (Exemple de requête :
SELECT FirstName, LastName, Position FROM nba_players WHERE Position = 'PG';) - Avantages : Architecture sans serveur, rapidité, tarification à l'utilisation.
Créer le lac de données NBA
Prérequis :
- Clé API SportsData.io : Obtenez une clé API gratuite de SportsData.io pour accéder aux données NBA.
- Compte AWS : Un compte AWS avec des autorisations suffisantes pour S3, Glue et Athena.
- Autorisations IAM : L'utilisateur ou le rôle nécessite des autorisations pour S3 (CreateBucket, PutObject, ListBucket), Glue (CreateDatabase, CreateTable) et Athena (StartQueryExecution, GetQueryResults).
Étapes :
1. Accédez à AWS CloudShell : Connectez-vous à AWS Management Console et ouvrez CloudShell.
2. Créez et configurez le script Python :
- Exécutez
nano setup_nba_data_lake.pydans CloudShell.
- Copiez le script Python (à partir du dépôt GitHub), en remplaçant l'espace réservé
api_keypar votre clé API SportsData.io :SPORTS_DATA_API_KEY=your_sportsdata_api_keyNBA_ENDPOINT=https://api.sportsdata.io/v3/nba/scores/json/Players
- Enregistrez et quittez (Ctrl X, Y, Entrée).


3. Exécutez le script : Exécutez python3 setup_nba_data_lake.py.
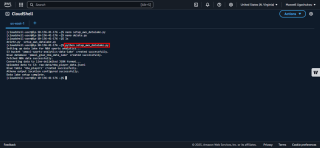
Le script crée le compartiment S3, télécharge des exemples de données, configure la base de données et la table Glue et configure Athena.
4. Vérification des ressources :
-
Amazon S3 : Vérifiez le compartiment
sports-analytics-data-lakeet le dossierraw-datacontenantnba_player_data.json.



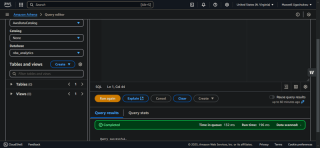
- Amazon Athena : Exécutez l'exemple de requête et vérifiez les résultats.

Résultats d'apprentissage :
Ce projet offre une expérience pratique dans la conception d'architecture cloud, les meilleures pratiques de stockage de données, la gestion des métadonnées, l'analyse basée sur SQL, l'intégration d'API, l'automatisation Python et la sécurité IAM.
Améliorations futures :
L'ingestion automatisée des données (AWS Lambda), la transformation des données (AWS Glue), les analyses avancées (AWS QuickSight) et les mises à jour en temps réel (AWS Kinesis) sont des améliorations futures potentielles. Ce projet met en valeur la puissance de l'architecture sans serveur pour créer des lacs de données efficaces et évolutifs.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Python et temps: tirer le meilleur parti de votre temps d'étudeApr 14, 2025 am 12:02 AM
Python et temps: tirer le meilleur parti de votre temps d'étudeApr 14, 2025 am 12:02 AMPour maximiser l'efficacité de l'apprentissage de Python dans un temps limité, vous pouvez utiliser les modules DateTime, Time et Schedule de Python. 1. Le module DateTime est utilisé pour enregistrer et planifier le temps d'apprentissage. 2. Le module de temps aide à définir l'étude et le temps de repos. 3. Le module de planification organise automatiquement des tâches d'apprentissage hebdomadaires.
 Python: jeux, GUIS, et plusApr 13, 2025 am 12:14 AM
Python: jeux, GUIS, et plusApr 13, 2025 am 12:14 AMPython excelle dans les jeux et le développement de l'interface graphique. 1) Le développement de jeux utilise Pygame, fournissant des fonctions de dessin, audio et d'autres fonctions, qui conviennent à la création de jeux 2D. 2) Le développement de l'interface graphique peut choisir Tkinter ou Pyqt. Tkinter est simple et facile à utiliser, PYQT a des fonctions riches et convient au développement professionnel.
 Python vs C: applications et cas d'utilisation comparésApr 12, 2025 am 12:01 AM
Python vs C: applications et cas d'utilisation comparésApr 12, 2025 am 12:01 AMPython convient à la science des données, au développement Web et aux tâches d'automatisation, tandis que C convient à la programmation système, au développement de jeux et aux systèmes intégrés. Python est connu pour sa simplicité et son écosystème puissant, tandis que C est connu pour ses capacités de contrôle élevées et sous-jacentes.
 Le plan Python de 2 heures: une approche réalisteApr 11, 2025 am 12:04 AM
Le plan Python de 2 heures: une approche réalisteApr 11, 2025 am 12:04 AMVous pouvez apprendre les concepts de programmation de base et les compétences de Python dans les 2 heures. 1. Apprenez les variables et les types de données, 2. Flux de contrôle maître (instructions et boucles conditionnelles), 3. Comprenez la définition et l'utilisation des fonctions, 4. Démarrez rapidement avec la programmation Python via des exemples simples et des extraits de code.
 Python: Explorer ses applications principalesApr 10, 2025 am 09:41 AM
Python: Explorer ses applications principalesApr 10, 2025 am 09:41 AMPython est largement utilisé dans les domaines du développement Web, de la science des données, de l'apprentissage automatique, de l'automatisation et des scripts. 1) Dans le développement Web, les cadres Django et Flask simplifient le processus de développement. 2) Dans les domaines de la science des données et de l'apprentissage automatique, les bibliothèques Numpy, Pandas, Scikit-Learn et Tensorflow fournissent un fort soutien. 3) En termes d'automatisation et de script, Python convient aux tâches telles que les tests automatisés et la gestion du système.
 Combien de python pouvez-vous apprendre en 2 heures?Apr 09, 2025 pm 04:33 PM
Combien de python pouvez-vous apprendre en 2 heures?Apr 09, 2025 pm 04:33 PMVous pouvez apprendre les bases de Python dans les deux heures. 1. Apprenez les variables et les types de données, 2. Structures de contrôle maître telles que si les instructions et les boucles, 3. Comprenez la définition et l'utilisation des fonctions. Ceux-ci vous aideront à commencer à écrire des programmes Python simples.
 Comment enseigner les bases de la programmation novice en informatique dans le projet et les méthodes axées sur les problèmes dans les 10 heures?Apr 02, 2025 am 07:18 AM
Comment enseigner les bases de la programmation novice en informatique dans le projet et les méthodes axées sur les problèmes dans les 10 heures?Apr 02, 2025 am 07:18 AMComment enseigner les bases de la programmation novice en informatique dans les 10 heures? Si vous n'avez que 10 heures pour enseigner à l'informatique novice des connaissances en programmation, que choisissez-vous d'enseigner ...
 Comment éviter d'être détecté par le navigateur lors de l'utilisation de Fiddler partout pour la lecture de l'homme au milieu?Apr 02, 2025 am 07:15 AM
Comment éviter d'être détecté par le navigateur lors de l'utilisation de Fiddler partout pour la lecture de l'homme au milieu?Apr 02, 2025 am 07:15 AMComment éviter d'être détecté lors de l'utilisation de FiddlereVerywhere pour les lectures d'homme dans le milieu lorsque vous utilisez FiddlereVerywhere ...


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Dreamweaver CS6
Outils de développement Web visuel

VSCode Windows 64 bits Télécharger
Un éditeur IDE gratuit et puissant lancé par Microsoft

Dreamweaver Mac
Outils de développement Web visuel

MinGW - GNU minimaliste pour Windows
Ce projet est en cours de migration vers osdn.net/projects/mingw, vous pouvez continuer à nous suivre là-bas. MinGW : un port Windows natif de GNU Compiler Collection (GCC), des bibliothèques d'importation et des fichiers d'en-tête librement distribuables pour la création d'applications Windows natives ; inclut des extensions du runtime MSVC pour prendre en charge la fonctionnalité C99. Tous les logiciels MinGW peuvent fonctionner sur les plates-formes Windows 64 bits.

Adaptateur de serveur SAP NetWeaver pour Eclipse
Intégrez Eclipse au serveur d'applications SAP NetWeaver.

