
Maison >Périphériques technologiques >IA >KDD 2024|L'équipe de Hong Kong Rhubarb Chao analyse en profondeur la « limite inconnue » des grands modèles dans le domaine de l'apprentissage automatique des graphes
KDD 2024|L'équipe de Hong Kong Rhubarb Chao analyse en profondeur la « limite inconnue » des grands modèles dans le domaine de l'apprentissage automatique des graphes

- PHPzoriginal
- 2024-07-22 16:54:341178parcourir

AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。送信メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
この記事の主な著者は香港大学のデータ インテリジェンス研究室の出身です。著者のうち、第1著者のRen Xubinと第2著者のTang Jiabinはともに香港大学データサイエンス学部の博士課程1年生で、指導教員はData Intelligence Lab@HKUのHuang Chao教授です。香港大学のデータ インテリジェンス研究室は、人工知能とデータ マイニングに関連する研究に特化しており、大規模言語モデル、グラフ ニューラル ネットワーク、情報検索、推奨システム、時空間データ マイニングなどの分野をカバーしています。これまでの研究には、一般的なグラフ大規模言語モデル GraphGPT、HiGPT、スマートシティ大規模言語モデル UrbanGPT、解釈可能な大規模言語モデル推奨アルゴリズム XRec などが含まれます。
今日の情報爆発の時代において、膨大なデータの海から深いつながりをどのように探索すればよいでしょうか?
これに関して、香港大学、ノートルダム大学、その他の機関の専門家や学者が、グラフ学習と大規模言語モデルの分野に関する最新のレビューで答えを明らかにしてくれました。
グラフは、現実世界のさまざまな関係を表す基本的なデータ構造として、その重要性は自明です。これまでの研究では、グラフ ニューラル ネットワークがグラフ関連のタスクで素晴らしい結果を達成したことが証明されています。しかし、グラフ データのアプリケーション シナリオが複雑になるにつれて、グラフ機械学習のボトルネック問題がますます顕著になってきています。近年、自然言語処理の分野では大規模言語モデルが注目を集めており、その優れた言語理解力と要約能力が注目を集めています。このため、大規模な言語モデルをグラフ学習テクノロジと統合して、グラフ学習タスクのパフォーマンスを向上させることが、業界で新たな研究のホットスポットとなっています。
このレビューでは、モデルの汎化能力、堅牢性、複雑なグラフデータを理解する能力など、グラフ学習の現在の分野における主要な技術的課題の詳細な分析を提供し、大規模モデルの将来のブレークスルーを期待しています。 「未知のフロンティア」という意味での可能性。

論文アドレス: https://arxiv.org/abs/2405.08011
プロジェクトアドレス: https://github.com/HKUDS/Awesome-LLM4Graph-Papers
HKU Data Intelligenceラボ: https://sites.google.com/view/chaoh/home
このレビューでは、グラフ学習に適用される最新の LLM を詳細にレビューし、フレームワーク設計に基づいた新しい分類方法を提案します。既存の技術を体系的に分類しています。これは 4 つの異なるアルゴリズム設計アイデアの詳細な分析を提供します。1 つはグラフ ニューラル ネットワークをプレフィックスとして使用し、2 つ目は大規模言語モデルをプレフィックスとして使用し、3 つ目は大規模言語モデルとグラフを統合するもので、4 つ目は大規模言語モデルのみを使用します。各カテゴリーについて、私たちは核となる技術的手法に焦点を当てています。さらに、このレビューはさまざまなフレームワークの長所とその限界についての洞察を提供し、将来の研究の潜在的な方向性を特定します。
香港大学データインテリジェンス研究所のHuang Chao教授率いる研究チームは、KDD 2024カンファレンスで、グラフ学習分野の大規模モデルが直面する「未知の境界」について徹底的に議論する予定です。
1 基礎知識
コンピュータサイエンスの分野において、グラフ(Graph)は重要な非線形データ構造であり、ノードセット(V)とエッジセット(E)から構成されます。各エッジはノードのペアを接続し、有向 (明確な始点と終点を持つ) または無向 (方向が指定されていない) の場合があります。特に注目すべき点は、テキスト属性グラフ (TAG) がグラフの特殊な形式として、文などのシリアル化されたテキスト機能を各ノードに割り当てることです。この機能は、大規模な言語モデルの時代には特に重要です。不可欠。テキスト属性グラフは、ノード セット V、エッジ セット E、およびテキスト特徴セット T から構成されるトリプレットとして正規に表すことができます。つまり、G * = (V, E, T) です。
グラフ ニューラル ネットワーク (GNN) は、グラフ構造データ用に設計された深層学習フレームワークです。隣接するノードからの情報を集約することにより、ノードの埋め込み表現を更新します。具体的には、GNN の各層は、現在のノードの埋め込みステータスと周囲のノードの埋め込み情報を包括的に考慮して次の層のノード埋め込みを生成する特定の関数を通じてノード埋め込み h を更新します。
大規模言語モデル (LLM) は強力な回帰モデルです。最近の研究では、数十億のパラメーターを含む言語モデルが、翻訳、要約生成、命令の実行などのさまざまな自然言語タスクの解決に優れたパフォーマンスを発揮することが示されているため、大規模言語モデルと呼ばれています。現在、最先端の LLM のほとんどは、情報をトークン シーケンスに効率的に統合するクエリ キー値 (QKV) メカニズムを採用した Transformer ブロックに基づいて構築されています。アプリケーションの方向性と注目するトレーニング方法に応じて、言語モデルは 2 つの主要なタイプに分類できます:
マスク言語モデリング (MLM) は、LLM の事前トレーニング ターゲットとして人気があります。これには、シーケンス内の特定のトークンを選択的にマスクし、周囲のコンテキストに基づいてこれらのマスクされたトークンを予測するようにモデルをトレーニングすることが含まれます。正確な予測を達成するために、モデルはマスクされた単語要素の文脈環境を包括的に考慮します。
因果言語モデリング (CLM) は、LLM のもう 1 つの主流の事前トレーニング目標です。モデルは、シーケンス内の前のトークンに基づいて次のトークンを予測する必要があります。このプロセスでは、モデルは現在の単語要素の前のコンテキストにのみ依存して正確な予測を行います。
2 グラフ学習と大規模言語モデル
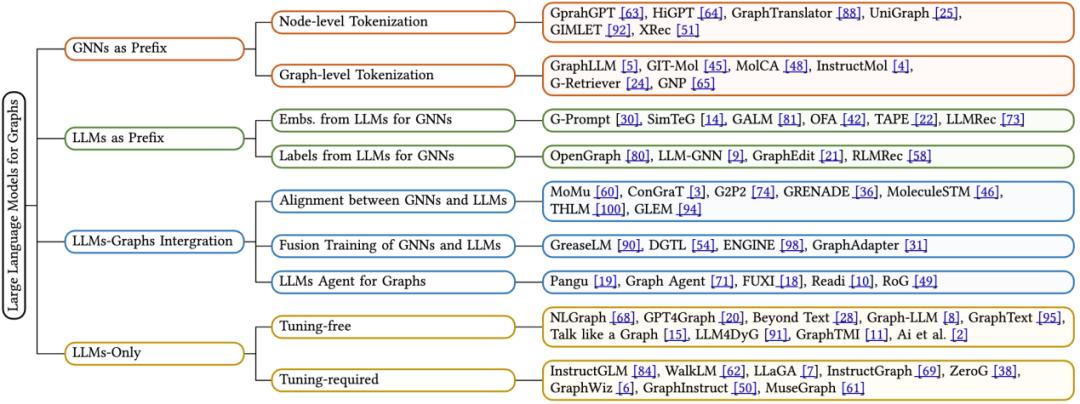
このレビュー記事では、著者はモデルの推論プロセス、つまり、グラフ データ、テキスト データ、および大規模言語モデル (LLM) の処理に依存しています。 ) インタラクティブな手法、新しい分類手法を提案します。具体的には、次の 4 つの主要なタイプのモデル アーキテクチャ設計を要約します。
プレフィックスとしての GNN: このカテゴリでは、グラフ ニューラル ネットワーク (GNN) が主要なコンポーネントとして機能し、グラフ データの処理を担当し、LLM に次の機能を提供します。後続の推論のための構造認識タグ (ノードレベル、エッジレベル、またはグラフレベルのタグなど)。
LLM をプレフィックスとして使用: このカテゴリでは、LLM は最初にテキスト情報を伴うグラフ データを処理し、その後、グラフ ニューラル ネットワークのトレーニング用にノードの埋め込みまたは生成されたラベルを提供します。
LLM とグラフの統合 (LLM とグラフの統合): このカテゴリのメソッドは、融合トレーニングや GNN との調整などを通じて、LLM とグラフ データの間のより深い統合を実現することを目指しています。さらに、グラフ情報と対話するために、LLM ベースのエージェントが構築されました。
LLM のみ (LLM のみを使用): このカテゴリは、LLM による推論を容易にするために、グラフ構造化データをトークン シーケンスに埋め込む実用的なヒントとテクニックを設計します。同時に、いくつかのメソッドには、モデルの処理能力をさらに強化するためにマルチモーダル マーカーも組み込まれています。
2.1 プレフィックスとしての GNN
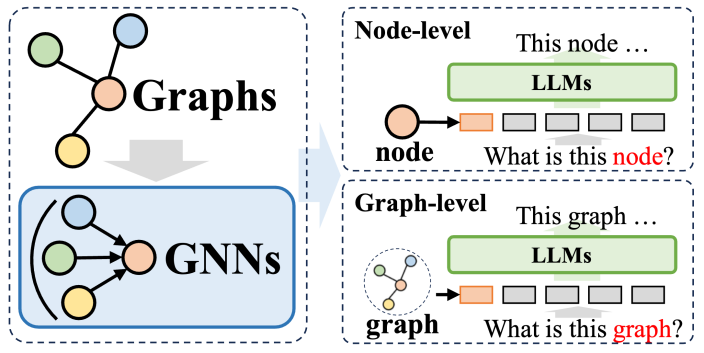
グラフニューラルネットワーク (GNN) がプレフィックスとして使用されるメソッドシステムでは、GNN は構造エンコーダーの役割を果たし、大規模言語モデル (LLM) のパフォーマンスを大幅に向上させます。グラフ構造に関するデータ解析機能により、さまざまな下流タスクに利益をもたらします。これらの方法では、GNN は主にエンコーダとして機能し、複雑なグラフ データを豊富な構造情報を含むグラフ トークン シーケンスに変換し、これらのシーケンスが自然言語処理プロセスと一致する LLM に入力されます。
これらの方法は、おおまかに 2 つのカテゴリに分類できます。1 つ目はノードレベルのトークン化です。つまり、グラフ構造内の各ノードが個別に LLM に入力されます。このアプローチの目的は、LLM がきめ細かいノードレベルの構造情報を深く理解し、異なるノード間の相関関係と差異を正確に識別できるようにすることです。 2 つ目は、グラフ レベルのトークン化です。これは、特定のプーリング テクノロジを使用してグラフ全体を固定長のトークン シーケンスに圧縮し、グラフ構造の全体的な高レベルのセマンティクスを取得することを目的としています。
ノードレベルのトークン化の場合、ノード分類やリンク予測など、ノードレベルの微細構造情報のモデリングを必要とするグラフ学習タスクに特に適しています。これらのタスクでは、モデルは異なるノード間の微妙な意味の違いを区別できる必要があります。従来のグラフ ニューラル ネットワークは、隣接するノードの情報に基づいて各ノードの一意の表現を生成し、これに基づいて下流の分類または予測を実行します。ノードレベルのトークン化方法では、各ノードの固有の構造特性を最大限に保持できるため、ダウンストリーム タスクの実行に大きなメリットがあります。
一方、グラフレベルのトークン化は、ノードデータからグローバル情報を抽出する必要があるグラフレベルのタスクに適応することです。プレフィックスとしての GNN のフレームワークの下で、さまざまなプーリング操作を通じて、グラフ レベルのトークン化により、多くのノード表現を 1 つの統一されたグラフ表現に合成できます。これにより、グラフのグローバル セマンティクスが取り込まれるだけでなく、さまざまなダウンストリーム タスクのパフォーマンスもさらに向上します。 . 実行効果。
プレフィックスとしての 2.2 LLM
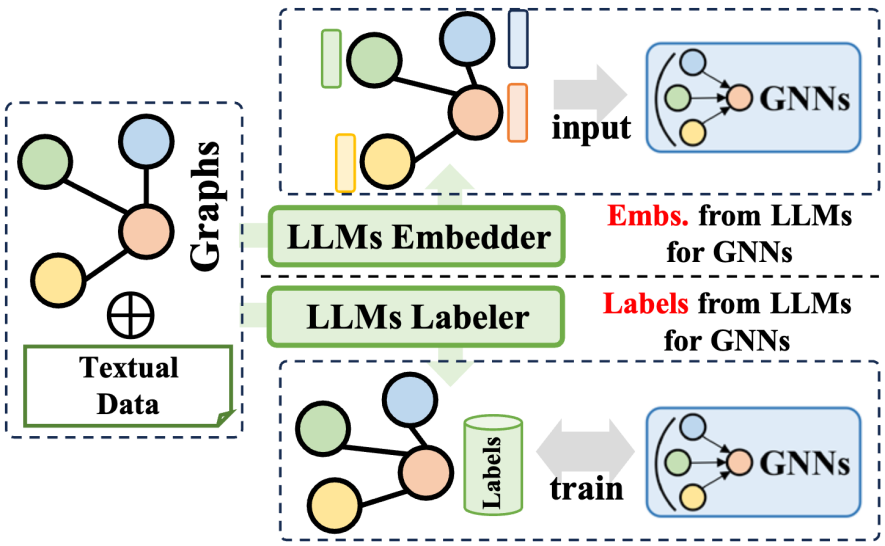
La méthode de préfixe des grands modèles de langage (LLM) utilise les informations riches générées par les grands modèles de langage pour optimiser le processus de formation des réseaux de neurones graphiques (GNN). Ces informations couvrent diverses données telles que le contenu textuel, les balises ou les intégrations générées par les LLM. Selon la manière dont ces informations sont appliquées, les technologies associées peuvent être divisées en deux grandes catégories : l'une consiste à utiliser les intégrations générées par les LLM pour aider à la formation des GNN ; l'autre consiste à intégrer les étiquettes générées par les LLM dans le processus de formation des GNN ; .
En termes d'utilisation des intégrations de LLM, le processus d'inférence des GNN implique le transfert et l'agrégation des intégrations de nœuds. Cependant, la qualité et la diversité des intégrations initiales de nœuds varient considérablement selon les domaines, comme les intégrations basées sur l'ID dans les systèmes de recommandation ou les intégrations de modèles de sacs de mots dans les réseaux de citations, et peuvent manquer de clarté et de richesse. Ce manque de qualité d'intégration limite parfois les performances des GNN. De plus, l’absence d’une conception universelle d’intégration de nœuds affecte également la capacité de généralisation des GNN lorsqu’ils traitent différents ensembles de nœuds. Heureusement, en tirant parti des capacités supérieures des grands modèles de langage en matière de synthèse et de modélisation du langage, nous pouvons générer des intégrations significatives et efficaces pour les GNN, améliorant ainsi leurs performances de formation.
En termes d'intégration des labels LLM, une autre stratégie consiste à utiliser ces labels comme signaux de supervision pour améliorer l'effet de formation des GNN. Il convient de noter que les étiquettes supervisées ici ne se limitent pas aux étiquettes de classification traditionnelles, mais incluent également des intégrations, des graphiques et d'autres formulaires. Les informations générées par les LLM ne sont pas directement utilisées comme données d'entrée pour les GNN, mais constituent un signal de supervision d'optimisation plus raffiné, aidant ainsi les GNN à obtenir de meilleures performances sur diverses tâches liées aux graphes.
2.3 Intégration LLM-Graphiques
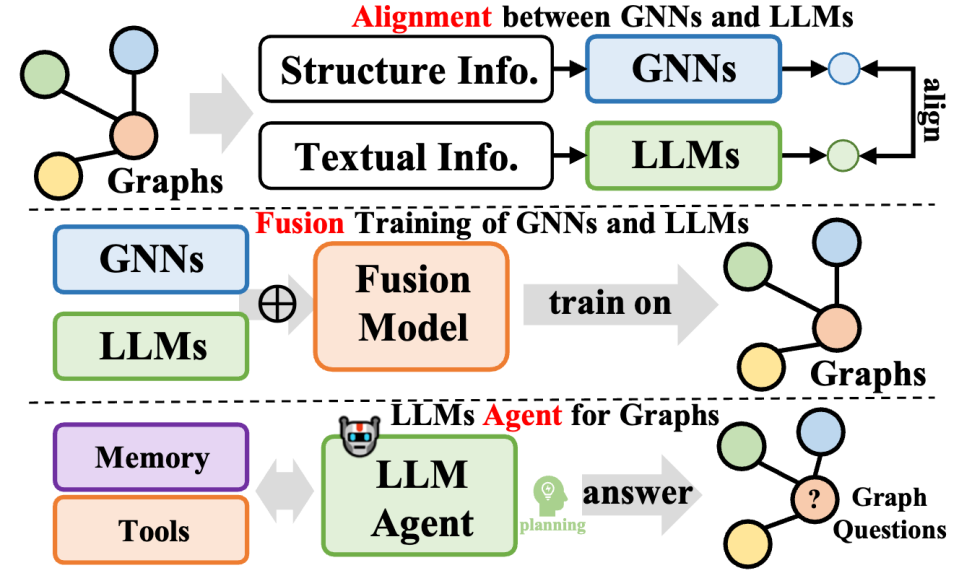
Ce type de méthode intègre davantage de grands modèles de langage et des données graphiques, couvre diverses méthodologies et améliore non seulement les capacités des grands modèles de langage (LLM) dans les tâches de traitement de graphiques, mais dans le même temps, l'apprentissage des paramètres des réseaux de neurones graphiques (GNN) est également optimisé. Ces méthodes peuvent être résumées en trois types : l'une est la fusion des GNN et des LLM, visant à réaliser une intégration profonde et un entraînement conjoint entre les modèles ; l'autre est l'alignement entre les GNN et les LLM, en se concentrant sur la représentation ou le niveau de tâche des deux modèles. La troisième consiste à créer des agents autonomes basés sur des LLM pour planifier et exécuter des tâches liées aux graphes.
En termes de fusion des GNN et des LLM, les GNN se concentrent généralement sur le traitement des données structurées, tandis que les LLM sont efficaces dans le traitement des données textuelles, ce qui se traduit par des espaces de fonctionnalités différents pour les deux. Pour résoudre ce problème et promouvoir le gain commun des deux modalités de données sur l'apprentissage des GNN et des LLM, certaines méthodes adoptent des techniques telles que l'apprentissage contrastif ou la formation itérative par maximisation des attentes (EM) pour aligner les espaces de fonctionnalités des deux modèles. Cette approche améliore la précision de la modélisation des informations graphiques et textuelles, améliorant ainsi les performances dans diverses tâches.
Concernant l'alignement des GNN avec les LLM, bien que l'alignement de la représentation permette une optimisation conjointe et un alignement au niveau de l'intégration des deux modèles, ils sont toujours indépendants pendant la phase d'inférence. Pour parvenir à une intégration plus étroite entre les LLM et les GNN, certaines recherches se concentrent sur la conception d'une fusion plus approfondie de l'architecture des modules, par exemple en combinant des couches de transformateur dans les LLM avec des couches neuronales graphiques dans les GNN. En formant conjointement les GNN et les LLM, il est possible d'apporter des gains bidirectionnels aux deux modules dans les tâches graphiques.
Enfin, en termes d'agents graphiques basés sur LLM, avec l'aide des excellentes capacités des LLM en matière de compréhension des instructions et d'auto-planification pour résoudre des problèmes, la nouvelle direction de recherche consiste à construire des agents autonomes basés sur des LLM pour traiter ou rechercher. -tâches liées. Généralement, un tel agent comprend trois modules : mémoire, perception et action, formant un cycle d'observation, de rappel de mémoire et d'action pour résoudre des tâches spécifiques. Dans le domaine de la théorie des graphes, les agents basés sur les LLM peuvent interagir directement avec les données graphiques et effectuer des tâches telles que la classification des nœuds et la prédiction des liens.
2.4 LLM uniquement
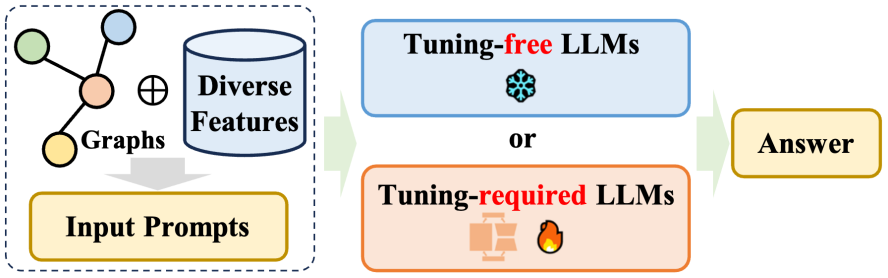
微調整不要のアプローチ: グラフ データの固有の構造特性を考慮すると、2 つの重要な課題が生じます。1 つ目は、自然言語形式でグラフを効果的に構築すること、2 つ目は、大規模言語モデル (LLM) が正確に理解できるかどうかを判断することです。言語形式はグラフ構造を表します。これらの問題に対処するために、研究者のグループは、純粋なテキスト空間でグラフをモデル化および推論するためのチューニング不要の手法を開発し、それによって構造的理解を強化するための事前トレーニング済み LLM の可能性を探りました。
微調整が必要な手法: グラフの構造情報を平文で表現することには限界があるため、グラフを入力する際にノードトークン列や自然言語トークン列としてグラフを利用する方法が最近の主流となっています。大規模言語モデル (LLM) の調整。前述のプレフィックス方式としての GNN とは異なり、調整が必要な唯一の LLM 方式は、グラフ エンコーダーを放棄し、代わりにグラフ構造を反映する特定のテキスト記述を使用し、プロンプト内で慎重に設計されたプロンプトを使用します。これは、さまざまなダウンストリームに関連します。ミッションでは期待できるパフォーマンスが達成されました。
3 将来の研究の方向性
このレビューでは、グラフの分野における大規模言語モデルのいくつかの未解決の問題と潜在的な将来の研究方向性についても説明します:
マルチモーダル グラフと大規模言語モデル (LLM) の融合。 最近の研究では、大規模な言語モデルが、画像やビデオなどのマルチモーダル データの処理と理解において並外れた能力を実証していることが示されています。この進歩により、LLM を複数のモーダル フィーチャを含むマルチモーダル マップ データと組み合わせる新たな機会が提供されます。このようなグラフデータを処理できるマルチモーダルLLMを開発することで、文字、視覚、聴覚などの複数のデータを総合的に考慮してグラフ構造をより正確かつ網羅的に推論することが可能になります。
効率を向上させ、コンピューティングコストを削減します。 現在、LLM のトレーニングと推論フェーズにかかる高い計算コストが開発の大きなボトルネックとなっており、数百万のノードを含む大規模なグラフ データを処理する能力が制限されています。 LLM をグラフ ニューラル ネットワーク (GNN) と組み合わせようとすると、2 つの強力なモデルが融合するため、この課題はさらに深刻になります。したがって、LLM と GNN のトレーニングの計算コストを削減するための効果的な戦略を発見して実装することが急務となっています。これにより、現在の制限が緩和されるだけでなく、グラフ関連のタスクにおける LLM の適用範囲がさらに拡大されます。これにより、データ サイエンスにおける実際的な価値と影響力が向上します。
多様なグラフタスクに対処します。 現在の調査方法は、リンク予測やノード分類などの従来のグラフ関連タスクに主に焦点を当てています。ただし、LLM の強力な機能を考慮すると、グラフ生成、グラフ理解、グラフベースの質問応答など、より複雑で生成的なタスクの処理における LLM の可能性をさらに探る必要があります。これらの複雑なタスクをカバーするために LLM ベースの手法を拡張することで、さまざまな分野で LLM を適用するための新たな機会が無数に開かれます。たとえば、創薬の分野では、LLM は新しい分子構造の生成を容易にすることができ、ソーシャル ネットワーク分析の分野では、LLM はナレッジ グラフ構築の分野で複雑な関係パターンに対する深い洞察を提供できます。より包括的で文脈的に正確な知識ベース。
ユーザーフレンドリーなグラフエージェントを構築します。 現在、グラフ関連タスク用に設計された LLM ベースのエージェントのほとんどは、単一タスク用にカスタマイズされています。これらのエージェントは通常、シングルショット モードで動作し、問題を一度に解決するように設計されています。ただし、理想的な LLM ベースのエージェントは、ユーザーが使いやすく、ユーザーが提示する多様な自由形式の質問に応じて、グラフ データ内の回答を動的に検索できる必要があります。この目標を達成するには、柔軟性と堅牢性を兼ね備え、ユーザーとの反復的な対話が可能で、複雑なグラフ データの処理に熟達して正確で関連性の高い回答を提供するエージェントを開発する必要があります。これには、エージェントが高い適応性を備えているだけでなく、強力な堅牢性を実証する必要もあります。
4 概要
このレビューでは、グラフ データ用にカスタマイズされた大規模言語モデル (LLM) について詳細な議論を行い、モデルベースの推論フレームワークに基づいて、さまざまなモデルを 4 つのタイプに注意深く分類する分類方法を提案しました。 . ユニークなフレームデザイン。各設計には、独自の強みと制限があります。それだけでなく、このレビューではこれらの機能について包括的に説明し、グラフ データ処理タスクを扱う際の各フレームワークの可能性と課題を深く調査しています。この研究作業は、グラフ関連の問題を解決するために大規模な言語モデルを探索および適用することに熱心な研究者に参考リソースを提供することを目的としており、最終的にはこの研究を通じて、言語モデルのアプリケーションのより深い理解を促進することが期待されています。 LLMとグラフデータ、さらにはこの分野に技術革新とブレークスルーを生み出します。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI