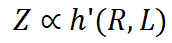La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Ce travail a été réalisé par l'équipe du chercheur IEEE Chen Enhong du Laboratoire national clé d'intelligence cognitive de l'Université des sciences et technologies de La Chine et le laboratoire Noah's Ark de Huawei. L'équipe du professeur Chen Enhong est profondément impliquée dans les domaines de l'exploration de données et de l'apprentissage automatique, et a publié de nombreux articles dans des revues et conférences de premier plan. Les articles de Google Scholar ont été cités plus de 20 000 fois. Le Noah's Ark Laboratory est le laboratoire de Huawei engagé dans la recherche fondamentale sur l'intelligence artificielle. Il adhère au concept d'importance égale accordée à la recherche théorique et à l'innovation applicative, et s'engage à promouvoir l'innovation et le développement technologiques dans le domaine de l'intelligence artificielle. Les données sont la pierre angulaire du succès des grands modèles de langage (LLM), mais toutes les données ne sont pas bénéfiques à l'apprentissage de modèles. Intuitivement, les échantillons de haute qualité devraient avoir une meilleure efficacité dans l’enseignement du LLM. Par conséquent, les méthodes existantes se concentrent généralement sur une sélection de données basée sur la qualité. Cependant, la plupart de ces méthodes évaluent indépendamment différents échantillons de données, ignorant les effets combinatoires complexes entre les échantillons. Comme le montre la figure 1, même si chaque échantillon est de qualité parfaite, leur combinaison peut toujours être sous-optimale en raison de la redondance ou de l'incohérence des informations mutuelles. Bien que le sous-ensemble basé sur la qualité soit constitué des trois échantillons de qualité, les connaissances qu’ils codent sont en réalité redondantes et contradictoires. En revanche, un autre sous-ensemble de données composé de plusieurs échantillons de qualité relativement inférieure mais diversifiés peut être plus informatif pour l’enseignement du LLM. Par conséquent, la sélection de données basée sur la qualité n’est pas entièrement alignée sur l’objectif de maximiser la capture des connaissances LLM. Et cet article vise à révéler la relation intrinsèque entre les performances LLM et la sélection des données. Inspirés par la nature de la compression des informations LLM, nous avons découvert une loi d'entropie, qui relie les performances du LLM au taux de compression des données et à la perte des étapes précédentes de formation du modèle, qui reflètent respectivement le degré de redondance des informations de l'ensemble de données et l'effet inhérent. de LLM sur l'ensemble de données. Le degré de maîtrise des connaissances. Grâce à la dérivation théorique et à l'évaluation empirique, nous constatons que les performances du modèle sont inversement liées au taux de compression des données d'entraînement, ce qui entraîne généralement une perte d'entraînement plus faible. Sur la base des résultats de la loi d'entropie, nous proposons une méthode de sélection de données très efficace et générale pour la formation LLM, nommée ZIP, qui vise à sélectionner préférentiellement des sous-ensembles de données à faible taux de compression. ZIP sélectionne avidement diverses données en plusieurs étapes, obtenant finalement un sous-ensemble de données avec une bonne diversité. 
- Équipe : équipe de Chen Enhong au National Key Laboratory of Cognitive Intelligence, Université des sciences et technologies de Chine, Huawei Noah's Ark Laboratory
- Lien papier : https://arxiv.org/pdf/2407.06645
- Lien du code : https://github.com/USTC-StarTeam/ZIP
O Figure 1 Loi tENTropie
Nous analysons l'analyse théorique de la relation entre la compression des données et les performances du LLM. Intuitivement, l'exactitude et la diversité des données d'entraînement affecteront les performances du modèle final. Dans le même temps, les performances du LLM peuvent être sous-optimales si les données présentent de graves conflits inhérents ou si le modèle comprend mal les informations codées dans les données. Sur la base de ces hypothèses, nous désignons les performances de LLM par Z , qui devraient être affectées par :
Taux de compression des données R : Intuitivement, les ensembles de données avec des taux de compression inférieurs indiquent une densité d'informations plus élevée.
Perte d'entraînement L : Indique si les données sont difficiles à mémoriser pour le modèle. Dans le même modèle de base, une perte de formation élevée est généralement due à la présence de bruit ou d'informations incohérentes dans l'ensemble de données.
- Cohérence des données C : La cohérence des données se reflète par l'entropie de la probabilité du prochain jeton compte tenu de la situation précédente. Une plus grande cohérence des données entraîne généralement une réduction des pertes de formation.
- Qualité moyenne des données Q : reflète la qualité moyenne des données au niveau de l'échantillon, qui peut être mesurée à travers divers aspects objectifs et subjectifs.
- Étant donné une certaine quantité de données d'entraînement, les performances du modèle peuvent être estimées par les facteurs ci-dessus :
où f est une fonction implicite. Étant donné un modèle de base spécifique, l'échelle de L dépend généralement de R et C et peut être exprimée comme suit :
Puisqu'un ensemble de données avec une plus grande homogénéité ou une meilleure cohérence des données est plus facile à apprendre par le modèle, L Il est attendu être monotone en R et C. Par conséquent, nous pouvons réécrire la formule ci-dessus comme suit :
où g' est une fonction inverse. En combinant les trois équations ci-dessus, nous obtenons :
où h est une autre fonction implicite. Si la méthode de sélection des données ne modifie pas de manière significative la qualité moyenne des données Q, nous pouvons traiter approximativement la variable Q comme une constante. Par conséquent, la performance finale peut être grossièrement exprimée comme suit : Cela signifie que les performances du modèle sont liées au taux de compression des données et à la perte d'entraînement. Nous appelons cette relation Loi d’entropie. Sur la base de la loi d'entropie, nous proposons deux inférences :
- Si C est considéré comme une constante, la perte d'entraînement est directement affectée par le taux de compression. Par conséquent, les performances du modèle sont contrôlées par le taux de compression : si le taux de compression des données R est plus élevé, alors Z est généralement moins bon, ce qui sera vérifié dans nos expériences.
- Sous le même taux de compression, une perte d'entraînement plus élevée signifie une cohérence des données moindre. Par conséquent, les connaissances effectives acquises par le modèle peuvent être plus limitées. Cela peut être utilisé pour prédire les performances de LLM sur différentes données avec un taux de compression et une qualité d'échantillon similaires. Nous montrerons plus loin l’application pratique de ce raisonnement.
ZIP : algorithme de sélection de données très léger Sous la direction de la loi d'entropie, nous avons proposé ZIP, une méthode de sélection de données, pour sélectionner des échantillons de données via le taux de compression des données, dans le but de maximiser la quantité d'informations efficaces avec un budget de données de formation limité. Pour des raisons d’efficacité, nous adoptons un paradigme glouton itératif à plusieurs étapes pour obtenir efficacement des solutions approximatives avec des taux de compression relativement faibles. À chaque itération, nous utilisons d'abord une étape de sélection globale pour sélectionner un pool d'échantillons candidats avec un faible taux de compression afin de trouver des échantillons avec une densité d'informations élevée. Nous utilisons ensuite une étape de sélection locale à gros grains pour sélectionner un ensemble d'échantillons plus petits présentant la plus faible redondance avec les échantillons sélectionnés. Enfin, nous utilisons une étape de sélection locale fine pour minimiser la similarité entre les échantillons à ajouter. Le processus ci-dessus se poursuit jusqu'à ce que suffisamment de données soient obtenues. L'algorithme spécifique est le suivant :
En comparant différents algorithmes de sélection de données SFT, le modèle formé sur la base des données de sélection ZIP présente des avantages en termes de performances et est également supérieur en efficacité. Les résultats spécifiques sont présentés dans le tableau ci-dessous :
Grâce aux caractéristiques indépendantes du modèle et insensibles au contenu de ZIP, il peut également être appliqué à la sélection de données lors de l'étape d'alignement des préférences. Les données sélectionnées par ZIP présentent également de grands avantages. Les résultats spécifiques sont présentés dans le tableau ci-dessous :
2. Vérification expérimentale de la loi d'entropieSur la base de l'expérience de sélection de données SFT, nous nous sommes basés sur l'effet du modèle, le taux de compression des données et la perte. du modèle dans les étapes précédentes de formation, respectivement. Plusieurs courbes de relation ont été ajustées. Les résultats sont présentés dans les figures 2 et 3, à partir desquelles nous pouvons observer l'étroite corrélation entre les trois facteurs. Tout d'abord, les données à faible taux de compression conduisent généralement à de meilleurs résultats de modèle, car le processus d'apprentissage des LLM est fortement lié à la compression des informations. Nous pouvons considérer le LLM comme un compresseur de données, donc les données avec un taux de compression plus faible signifient plus de données. connaissances et donc plus précieux pour le compresseur. Dans le même temps, on peut observer que des taux de compression plus faibles s'accompagnent généralement de pertes de formation plus élevées, car les données difficiles à compresser contiennent plus de connaissances, ce qui pose de plus grands défis à LLM pour absorber les connaissances qu'elles contiennent.
Figure 3 Llama-3-8B Nous fournissons une loi d'entropie pour guider la mise à jour incrémentielle des données de formation LLM dans des scénarios d'application réels. Dans ce scénario de tâche, la quantité de données d'entraînement reste relativement stable et seule une petite partie des données est modifiée. Les résultats sont présentés dans la figure 4, où à sont 5 versions de données qui sont progressivement mises à jour de manière incrémentale. En raison d'exigences de confidentialité, seule la relation relative des effets du modèle sous différents taux de compression est fournie. Selon les prédictions de la loi d'entropie, en supposant que la qualité des données ne diminue pas de manière significative après chaque mise à jour incrémentielle, on peut s'attendre à ce que les performances du modèle s'améliorent à mesure que le taux de compression des données diminue. Cette prédiction est cohérente avec les résultats pour les versions de données à dans la figure. Cependant, la version des données montre une augmentation inhabituelle de la perte et du taux de compression des données, ce qui indique le potentiel de dégradation des performances du modèle en raison d'une cohérence réduite des données d'entraînement. Cette prédiction a été confirmée par une évaluation ultérieure des performances du modèle. Par conséquent, la loi de l'entropie peut servir de principe directeur pour la formation LLM, prédisant le risque potentiel d'échec de la formation LLM sans former le modèle sur l'ensemble de données complet jusqu'à la convergence. Ceci est particulièrement important compte tenu du coût élevé de la formation des LLM. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!