La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Les auteurs de cet article proviennent de l'Université du Zhejiang, du Laboratoire d'intelligence artificielle de Shanghai, de l'Université chinoise de Hong Kong, de l'Université de Sydney et de l'Université d'Oxford. Liste des auteurs : Wu Yixuan, Wang Yizhou, Tang Shixiang, Wu Wenhao, He Tong, Wanli Ouyang, Philip Torr, Jian Wu. Parmi eux, le co-premier auteur Wu Yixuan est doctorant à l'Université du Zhejiang et Wang Yizhou est assistant de recherche scientifique au Laboratoire d'intelligence artificielle de Shanghai. L'auteur correspondant Tang Shixiang est chercheur postdoctoral à l'Université chinoise de Hong Kong.
Les modèles multimodaux de langage étendu (MLLM) ont montré des capacités impressionnantes dans différentes tâches, malgré cela, le potentiel de ces modèles dans les tâches de détection est encore sous-estimé. Lorsque des coordonnées précises sont requises dans des tâches complexes de détection d'objets, les hallucinations des MLLM leur font souvent manquer des objets cibles ou donnent des cadres de délimitation inexacts. Afin de permettre la détection des MLLM, les travaux existants nécessitent non seulement de collecter de grandes quantités d'ensembles de données d'instructions de haute qualité, mais également d'affiner les modèles open source. Bien que chronophage et exigeant en main-d'œuvre, il ne parvient pas non plus à tirer parti des capacités de compréhension visuelle plus puissantes des modèles fermés. À cette fin, l'Université du Zhejiang, en collaboration avec le Laboratoire d'intelligence artificielle de Shanghai et l'Université d'Oxford, a proposé DetToolChain, un nouveau paradigme d'invite qui libère les capacités de détection des grands modèles de langage multimodaux. Les grands modèles multimodaux peuvent apprendre à détecter avec précision sans formation. Des recherches pertinentes ont été incluses dans ECCV 2024. Afin de résoudre les problèmes de MLLM dans les tâches de détection, DetToolChain part de trois points : (1) Concevoir des invites visuelles pour la détection, qui sont plus directes et efficaces pour MLLM que les invites textuelles traditionnelles, ( 2) décomposer les tâches de détection détaillées en tâches petites et simples, (3) utiliser une chaîne de pensée pour optimiser progressivement les résultats de détection et éviter autant que possible l'illusion de grands modèles multimodaux. Correspondant aux informations ci-dessus, DetToolChain contient deux conceptions clés : (1) Un ensemble complet d'invites de traitement visuel (invites de traitement visuel), qui sont dessinées directement dans l'image et peuvent réduire considérablement l'écart entre les informations visuelles et différence d'informations textuelles. (2) Un ensemble complet de raisonnements de détection incite à améliorer la compréhension spatiale de la cible de détection et à déterminer progressivement l'emplacement précis final de la cible grâce à une chaîne d'outils de détection adaptative à l'échantillon. En combinant DetToolChain avec MLLM, tels que GPT-4V et Gemini, diverses tâches de détection peuvent être prises en charge sans réglage d'instructions, notamment la détection de vocabulaire ouvert, la détection de cible de description, la compréhension d'expression référentielle et la détection de cible orientée. 
- Titre de l'article : DetToolChain : Un nouveau paradigme d'incitation pour libérer la capacité de détection du MLLM
- Lien de l'article : https://arxiv.org/abs/2403.12488
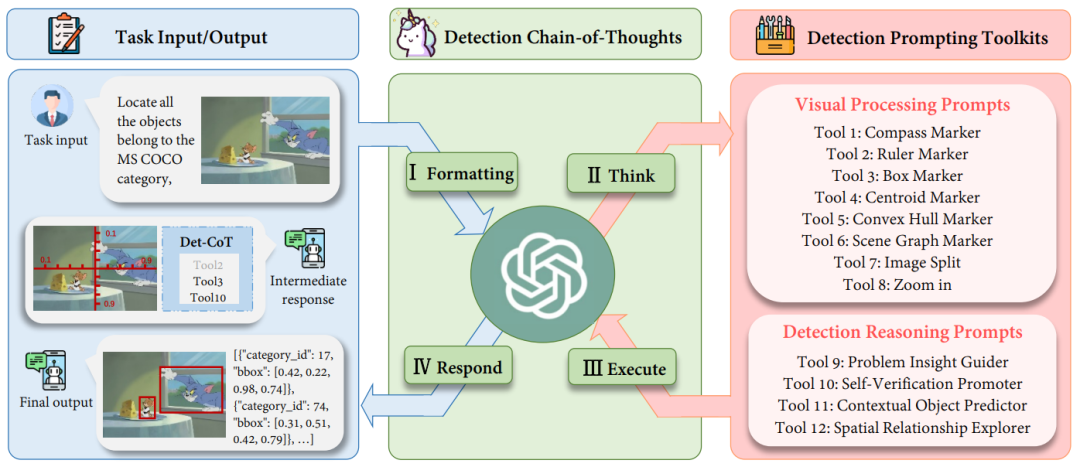
Qu'est-ce que DetToolChain ?
I. Formatage : convertissez le format d'entrée d'origine de la tâche en un modèle d'instruction approprié comme entrée dans le MLLM ; II Réfléchissez : décomposez une détection complexe spécifique. tâche en sous-tâches plus simples et sélectionnez des conseils efficaces dans la boîte à outils de conseils de détection (invites) ; III. Exécuter : exécuter de manière itérative des invites spécifiques (invites) dans l'ordre
IV Répondre : utiliser les propres capacités de raisonnement de MLLM pour superviser l'ensemble du processus de détection ; et renvoie la réponse finale (réponse finale).
Boîte à outils d'invite de détection : invites de traitement visuel
Figure 2 : Diagramme schématique des invites de traitement visuel. Nous avons conçu (1) un amplificateur régional, (2) une norme de mesure spatiale, (3) un analyseur d'images de scène pour améliorer les capacités de détection des MLLM sous différentes perspectives. Comme le montre la figure 2, (1) l'amplificateur régional vise à améliorer la visibilité des MLLM sur les régions d'intérêt (ROI), notamment en recadrant l'image originale dans différentes sous-régions, en se concentrant sur les sous-régions. où se trouve la zone cible. De plus, la fonction de zoom permet une observation fine de sous-zones spécifiques de l'image. (2) La norme de mesure spatiale fournit une référence plus claire pour la détection de cibles en superposant une règle et un compas avec des échelles linéaires sur l'image originale, comme le montre la figure 2 (2). Les règles et boussoles auxiliaires permettent aux MLLM de produire des coordonnées et des angles précis à l'aide de références de translation et de rotation superposées à l'image. Essentiellement, cette ligne auxiliaire simplifie la tâche de détection, permettant aux MLLM de lire les coordonnées des objets au lieu de les prédire directement. (3) Scene Image Parser marque la position ou la relation prévue de l'objet et utilise des informations spatiales et contextuelles pour comprendre la relation spatiale de l'image. Scene Image Parser peut être divisé en deux catégories : Premièrement, pour un seul objet cible , nous étiquetons l'objet prédit avec un centroïde, une coque convexe et un cadre de délimitation avec le nom de l'étiquette et l'index de la boîte. Ces marqueurs représentent les informations de position des objets dans différents formats, permettant à MLLM de détecter divers objets de formes et d'arrière-plans différents, en particulier les objets aux formes irrégulières ou aux occlusions importantes. Par exemple, le marqueur de coque convexe marque les points limites d'un objet et les relie en une coque convexe pour améliorer les performances de détection d'objets de forme très irrégulière. Deuxièmement, pour les multi-objectifs, nous connectons les centres de différents objets via des marqueurs de graphique de scène pour mettre en évidence la relation entre les objets dans l'image. Sur la base du graphique de scène, MLLM peut exploiter ses capacités de raisonnement contextuel pour optimiser les cadres de délimitation prédits et éviter les hallucinations. Par exemple, comme le montre la figure 2 (3), Jerry veut manger du fromage, leurs cadres de délimitation doivent donc être très proches. Boîte à outils d'invites de raisonnement de détection : Invites de raisonnement de détection
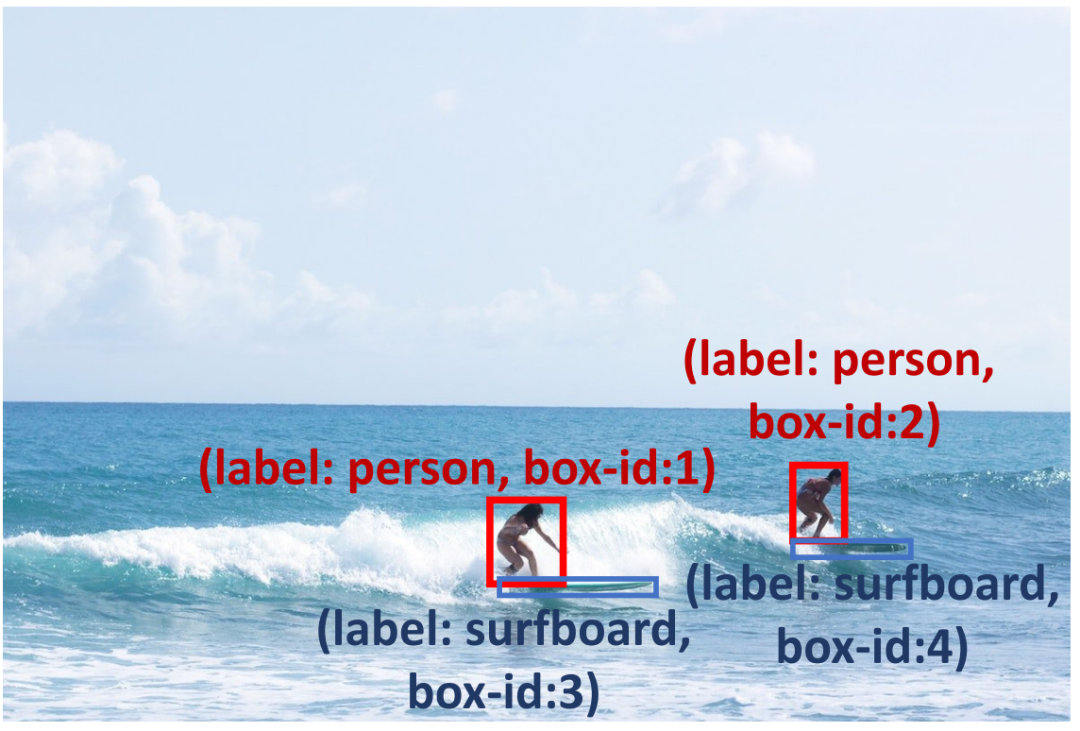
Pour améliorer la fiabilité de la boîte de prédiction, nous avons effectué des invites de raisonnement de détection (indiquées dans le tableau 1) pour vérifier les résultats de la prédiction et diagnostiquer d'éventuels problèmes potentiels. . Tout d’abord, nous proposons Problem Insight Guider, qui met en évidence les problèmes difficiles et fournit des suggestions de détection efficaces et des exemples similaires pour les images de requête. Par exemple, pour la figure 3, le Problem Insight Guider définit la requête comme un problème de détection de petits objets et suggère de le résoudre en zoomant sur la zone de la planche de surf. Deuxièmement, pour tirer parti des capacités spatiales et contextuelles inhérentes aux MLLM, nous concevons un explorateur de relations spatiales et un prédicteur d'objets contextuels pour garantir que les résultats de détection sont conformes au bon sens. Comme le montre la figure 3, une planche de surf peut coexister avec l'océan (connaissance contextuelle), et il devrait y avoir une planche de surf près des pieds du surfeur (connaissance spatiale). De plus, nous appliquons le promoteur d'auto-vérification pour améliorer la cohérence des réponses sur plusieurs tours. Pour améliorer encore les capacités de raisonnement des MLLM, nous adoptons des méthodes d'invite largement utilisées, telles que le débat et l'auto-débogage. Veuillez consulter le texte original pour une description détaillée.
Les indices d'inférence de détection peuvent aider les MLLM à résoudre des problèmes de détection de petits objets, par exemple en faisant preuve de bon sens pour localiser une planche de surf sous les pieds d'une personne et en encourageant le modèle à détecter les planches de surf dans l'océan.
Expérience : vous pouvez surpasser la méthode de réglage fin sans entraînementComme le montre le tableau 2, nous avons évalué notre méthode sur la détection de vocabulaire ouvert ( OVD) , testant les résultats AP50 sur 17 nouvelles classes, 48 classes de base et toutes les classes du benchmark COCO OVD. Les résultats montrent que les performances de GPT-4V et de Gemini sont considérablement améliorées grâce à notre DetToolChain. Untuk menunjukkan keberkesanan kaedah kami dalam pemahaman ungkapan rujukan, kami membandingkan kaedah kami dengan kaedah sifar tangkapan lain pada dataset RefCOCO, RefCOCO+ dan RefCOCOg (Jadual 5). Pada RefCOCO, DetToolChain meningkatkan prestasi garis dasar GPT-4V masing-masing sebanyak 44.53%, 46.11% dan 24.85% pada val, ujian-A dan ujian-B, menunjukkan pemahaman dan prestasi ekspresi rujukan unggul DetToolChain di bawah prestasi Penentududukan sifar.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Déclaration:Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn